一、Hive引擎包括:默认MR、tez、spark
在低版本的hive中,只有两种计算引擎mr, tez
在高版本的hive中,有三种计算引擎mr, spark, tez
二、Hive on Spark和Spark on Hive的区别
Hive on Spark:Hive既存储元数据又负责SQL的解析,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。
Spark on Hive : Hive只存储元数据,Spark负责SQL解析,语法是Spark SQL语法,Spark负责采用RDD执行。
注意:目前官网的Hive3.1.2和Spark3.0.0默认是不兼容的。因为Hive3.1.2支持的Spark版本是2.4.5,所以除了spark-3.0.0-bin-hadoop3.2.tgz安装包外,还需要纯净版jar包spark-3.0.0-bin-without-hadoop.tgz
jar包链接: https://pan.baidu.com/s/17P9aMotyvbBk5IR5Fw56lg 提取码: e997
三、三种引擎如何切换(计算引擎一般为mr或者spark)
1、配置mapreduce计算引擎
set hive.execution.engine=mr;
2、配置tez计算引擎
set hive.execution.engine=tez;
3、配置spark计算引擎(切换spark引擎时,服务器要安装好spark,并且hive与spark的版本要配套)
set hive.execution.engine=spark;
四、查看目前hive使用的计算引擎
set hive.execution.engine;
五、安装与hive配套的spark(前提是已经安装好Hive3.1.2、Spark3.0.0)
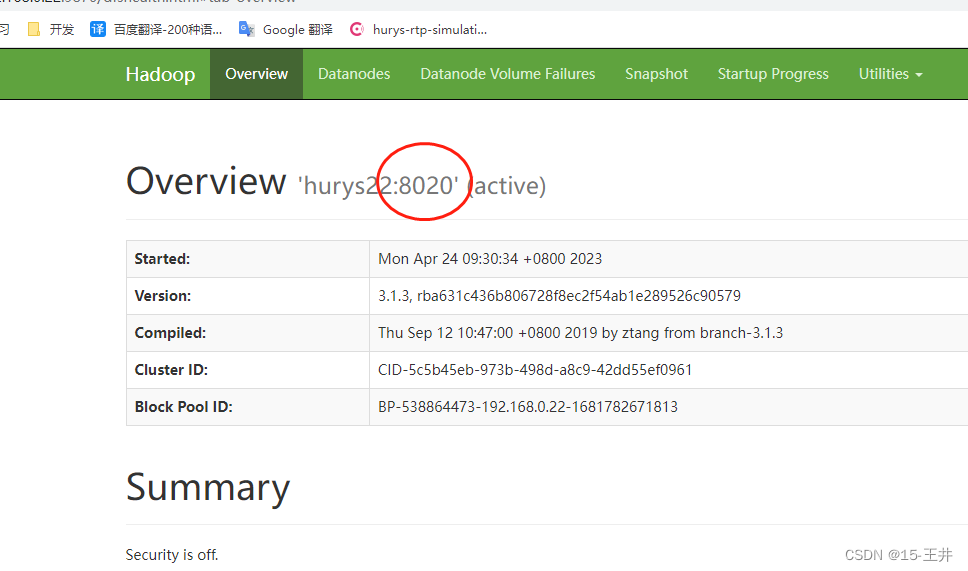
第一步,在hive中创建spark配置文件 (注意:端口号8020必须和namenode的端口号一致)
[root@hurys22 ~]# cd /opt/soft/hive312/conf/
[root@hurys22 conf]# vi spark-defaults.conf
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://192.168.0.22:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
第二步,在HDFS创建文件夹spark-history,用于存储历史日志
[root@hurys22 conf]# hdfs dfs -mkdir /spark-history
第三步,解压并向HDFS上传Spark纯净版jar包spark-3.0.0-bin-without-hadoop.tgz
1.解压spark纯净版安装包
[root@hurys22 install]# tar -zxf /opt/install/spark-3.0.0-bin-without-hadoop.tgz -C /opt/soft/
[root@hurys22 install]# cd /opt/soft/
[root@hurys22 soft]# ls
flume190 hadoop313 hbase205 hive312 kafka213 scala211 spark300 spark-3.0.0-bin-without-hadoop zepplin090
2.重命名安装目录
[root@hurys22 soft]# mv spark-3.0.0-bin-without-hadoop/ spark300without
[root@hurys22 soft]# ls
flume190 hadoop313 hbase205 hive312 kafka213 scala211 spark300 spark300without zepplin090
3.在HDFS创建文件夹spark-jars,用于存放纯净版spark安装目录里的jar包
[root@hurys22 soft]# hdfs dfs -mkdir /spark-jars
4.上传Spark纯净版安装目录里的jar包到HDFS的spark-jars文件夹中
[root@hurys22 soft]# hdfs dfs -put spark300without/jars/* /spark-jars
第四步,修改hive-site.xml文件
[root@hurys22 soft]# cd /opt/soft/hive312/conf/
[root@hurys22 conf]# ls
beeline-log4j2.properties.template hive-exec-log4j2.properties.template ivysettings.xml nohup.out
hive-default.xml.template hive-log4j2.propertie llap-cli-log4j2.properties.template parquet-logging.properties
hive-env.sh hive-site.xml llap-daemon-log4j2.properties.template spark-defaults.conf
[root@hurys22 conf]# vi hive-site.xml
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://192.168.0.22:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--Hive和Spark连接超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>10000ms</value>
</property>

第五步,Hive on Spark测试
1.登录hive
[root@hurys22 conf]# hive
2.建测试库
hive> create database test2;
OK
Time taken: 0.149 seconds
hive> show databases;
OK
default
test
test2
hive> use test2;
OK
3.建测试表
hive> create table student(id int, name string);
OK
4.插入数据
hive> insert into table student values(1,'zhangsan');
5.查看数据
hive> select * from student;
OK
1 zhangsa
6.查看目前hive使用的计算引擎
hive> set hive.execution.engine;
hive.execution.engine=spark
乐于奉献共享,帮助你我他!!!
再续 2023-04-24 14:29
在hive on spark装好后,我用mr和spark两种计算引擎处理相同的SQL,从而得到两个不同的处理时间。
如下图,总共8张表,SQL语句一样,spark计算引擎的速度比mr计算引擎的速度大概快十倍左右!!! 惊喜