原创:公众号 数据说话
【万字更新】Python基础教程:第六章_数据容器
为什么学习数据容器
思考一个问题:如果我想要在程序中,记录5名学生的信息,如姓名。
最好的方法是不是简单的定义5个字符串变量就可以了
name1="王丽红"
name2="周杰轮"
name3="林俊节"
name4="张学油"
name5="刘德滑"
尽管这种方式可以满足我们的需求,但是写起来手的略显有点繁琐呀,我们只是5名学生信息,那如果说是50名,500名呢,难道我们真的要定义500个变量吗,那肯定是不现实的,那所以我们这种写法虽然能够实现,但是他不高级且低效,那为了实现这个需求呢,我们就可以通过,数据容器来去实现它了。
接下来用一个变量完成:
namelist = ["王丽红","周杰轮","林俊节","张学油","刘德滑"]
这个代码里面,定义了一个新的数据结构,这个是我们没有见过的,那这就是数据容器。
可以看到,这段代码一次性记录了5份数据,并将这5份数据保存在一个变量中。因此,当我们编写代码时,我们可以轻松地使用一个变量来记录多个数据,即使我们需要记录更多的数据也可以轻易扩展。这是数据容器最基本的价值,它可以容纳多份数据,使我们的代码更优雅、高效。因此,学习数据容器的主要目的是为了实现批量存储和处理多份数据。这是数据容器为我们带来的最大价值。
习惯看视频的同学可以看这个免费教程:
https://www.bilibili.com/video/BV1ZK411Q7uX/?vd_source=704fe2a34559a0ef859c3225a1fb1b42&wxfid=o7omF0RELrnx5_fUSp6D59_9ms3Y
数据容器
Python中的数据容器
一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素每一个元素,可以是任意类型的数据,如字符串、数字、布尔等。
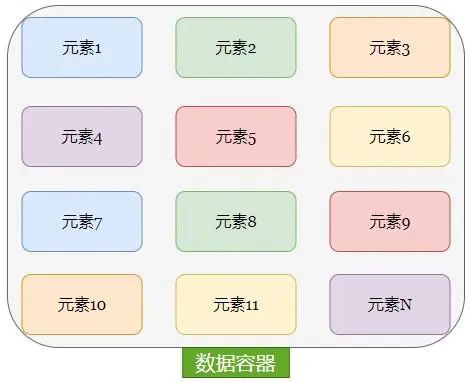
如上图,可以看到我们这边,就有了一个数据容器了 那在容器的内部就会有元素1,元素2,元素6,元素9,元素n等等一系列的元素在里面。
那么这个数量呢可以是非常非常多的。数据容器根据特点的不同,如:
-
是否支持重复元素
-
是否可以修改
-
是否有序,等
分为5类,分别是:
列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)我们将一一学习它们。
列表的定义
学习目标
-
掌握列表的定义格式
为什么需要列表
思考:有一个人的姓名(TOM)怎么在程序中存储?
答:字符串变量
思考:如果一个班级100位学生,每个人的姓名都要存储,应该如何书写程序?声明100个变量吗?
答:No,我们使用列表就可以了,列表一次可以存储多个数据
列表(list)类型,是数据容器的一类,我们来详细学习它。列表的定义基本语法:
# 字面量
[元素1,元素2,元素3,元素4,...]
# 定义变量
变量名称 = [元素1,元素2,元素3,元素4,...]
# 定义空列表
变量名称 = []
变量名称 = list()
列表内的每一个数据,称之为元素
-
以 [] 作为标识
-
列表内每一个元素之间用, 逗号隔开
列表的定义方式
现在让我们来简单的看一看它的案例演示吧,假设我们想要存储3个字符串的数据,然后通过print的语句将它的内容打印出来,又通过type语句查看了一下它的类型:
name_list = ['itheima','itcast','python']
print(name_list)
print(type(name_list))
输出结果为:
['itheima', 'itcast', 'python']
<class 'list'>
同时你看到他的类型叫做list,那这也是我们所说的列表。
我们在下面又定义了一个列表,那你会在列表中发现,3个元素好像类型都不一样
my_list = ['itheima',666,True]
print(my_list)
print(type(my_list))
那我们写完之后把他的内容打印出来,同时打印一下他的类型,也会发现可以正常的输出。
['itheima', 666, True]
<class 'list'>
证明了一件事情,就是我们的列表中,他存储的元素类型,可以是不同的数据类型。
那既然是这样的话我们来想一想,我们存储的元素类型他是不受限制的,那我在里面再存一个列表是否可以呢?肯定是可以的,那如果说在列表里面再存入列表。那这种行为我们把它叫做嵌套。
my_list = [[1,2,3],[4,5,6]]
print(my_list)
print(type(my_list))
我们会发现他里面有两个元素,第一个元素是个列表,第二个元素也是个列表。那所以当前我们写的这代码,就是写了一个列表,列表里面有两个元素,然后每一个元素又都是列表,那我们通过print语句以及type语句,打印出结果:
[[1, 2, 3], [4, 5, 6]]
<class 'list'>
同样也可以正常输出,且类型也是列表类型。
注意:列表可以一次存多个数据,且可以为不同的数据类型,支持嵌套。
列表的下标索引
学习目标
-
掌握使用列表的下标索引从列表中取出元素
如何从列表中取出特定位置的数据呢?我们可以使用:下标索引

如图,列表中的每一个元素,都有其位置下标索引,从前向后的方向,从0开始,依次递增我们只需要按照下标索引,即可取得对应位置的元素。
name_list =['Tom','Lily','Rose']
print(name_list[0]) # 结果:Tom
print(name_list[1]) # 结果:Lily
print(name_list[2]) # 结果:Rose
列表的下标(索引) - 反向
或者,可以反向索引,也就是从后向前:从-1开始,依次递减(-1、-2、-3......)

如图,从后向前,下标索引为:-1、-2、-3,依次递减。
name_list =['Tom','Lily','Rose']
print(name_list[-1]) # 结果:Rose
print(name_list[-2]) # 结果:Lily
print(name_list[-3]) # 结果:Tom
嵌套列表的下标(索引)
如果列表是嵌套的列表,同样支持下标索引其实我们就需要写两层下标索引就可以了
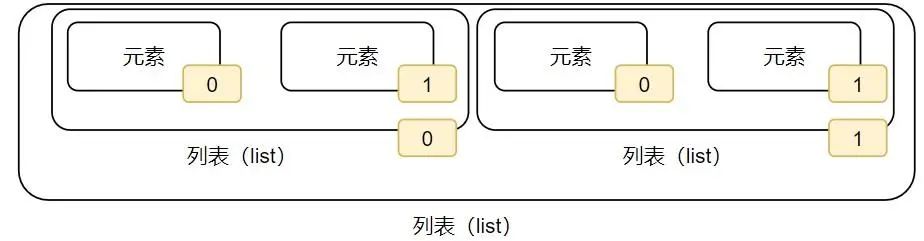
如图,下标就有2个层级了。
# 2层嵌套1ist
my_list=[[1,2,3],[4,5,6]]
# 获取内层第一个1ist
print(my_list[0]) #结果:[1,2,3]
# 获取内层第一个1ist的第一个元素
print(my_list[0][0]) #结果:1
列表的常用操作
学习目标
-
掌握列表的常用操作(方法)和特点
在我们前面学习了关于列表的定义以及使用下标索引去获取指定的元素值,那么除了这两种操作以外呢,我们的列表也提供了一系列的功能:比如插入元素,删除元素,清空列表,修改元素,统计元素个数等等功能,那么这些功能,我们都把它称之为叫做列表的方法。
那这里面我们有了一个新的名词,叫做方法,那方法又是什么呢?
我们来回忆一个内容,我们在前面学习过函数,那我们知道,函数是一个封装的代码单元,可以提供特定的功能。在Python中,如果我们将函数定义在class时,也又是类的成员之内的话,那么这个函数,他的名字就不会再叫函数了,而会称之为方法。
那可以看到,其实,函数和方法其实在功能上都是一样的,只不过他们写的地方是不同的。
# 函数
def add(x, y)
return x + y
# 方法
class Student:
def add(self,x , y):
return x + y
关于类和方法的定义,在面向对象章节我们学习,目前我们知道如何使用方法即可。
列表的查询功能(方法)
函数是一个封装的代码单元,可以提供特定功能。在Python中,如果将函数定义为class(类)的成员,那么函数会称之为:方法 方法和函数功能一样,有传入参数,有返回值,只是方法的使用格式不同:函数的使用:
num = add(1,2)
方法的使用:
student = Student()
num = student.add(1,2)
-
查找某元素的下标
功能:查找指定元素在列表的下标,如果找不到,报错ValueError
语法:列表.index(元素)
index就是列表对象(变量)内置的方法(函数)
my_list = ['itheima','itcast','python']
print(my_list.index('itcast')) # 结果1
列表的修改功能(方法)
-
修改特定位置(索引)的元素值:
-
语法:列表[下标] = 值
可以使用如上语法,直接对指定下标(正向、反向下标均可)的值进行:重新赋值(修改)
#正向下标
my_list = [1,2,3]
my_list[0] = 5
print(my_list) # 结果:[5,2,3]
#反向下标
my_list = [1,2,3]
my_list[-3] = 5
print(my_list) # 结果:[5,2,3]
-
插入元素:
语法:列表.insert(下标, 元素),在指定的下标位置,插入指定的元素
my_list = [1,2,3]
my_list.insert(1,"itheima")
print(my_list) # 结果 [1, 'itheima', 2, 3]
-
追加元素:
语法:列表.append(元素),将指定元素,追加到列表的尾部
my_list = [1,2,3]
my_list.append(4)
print(my_list) # 结果 [1, 2, 3, 4]
my_list = [1,2,3]
my_list.append([4,5,6])
print(my_list) #结果 [1, 2, 3, [4, 5, 6]]
-
追加元素方式2:
语法:列表.extend(其它数据容器),将其它数据容器的内容取出,依次追加到列表尾部
my_list = [1,2,3]
my_list.extend([4,5,6])
print(my_list) # 结果 [1, 2, 3, 4, 5, 6]
-
删除元素:
语法1:del 列表[下标]
语法2:列表.pop(下标)
my_list = [1,2,3]
#方式1
del my_list[0]
print(my_list) # 结果 [2, 3]
# 方式2
my_list.pop(0)
print(my_list) # 结果 [2, 3]
-
删除某元素在列表中的第一个匹配项
语法:列表.remove(元素)
my_list = [1,2,3,2,3]
my_list.remove(2)
print(my_list) # 结果:[1, 3, 2, 3]
-
清空列表内容
语法:列表.clear()
my_list = [1,2,3]
my_list.clear()
print(my_list) # 结果[]
-
统计某元素在列表内的数量
语法:列表.count(元素)
my_list = [1,1,1,2,3]
print(my_list.count(1)) # 结果:3
列表的查询功能(方法)
-
统计列表内,有多少元素语法:len(列表)
可以得到一个int数字,表示列表内的元素数量
my_list = [1,2,3,4,5]
print(len(my_list)) # 结果:5
列表的方法 - 总览
| 编号 | 使用方式 | 作用 |
|---|---|---|
| 1 | 列表.append(元素) | 向列表中追加一个元素 |
| 2 | 列表.extend(容器) | 将数据容器的内容依次取出,追加到列表尾部 |
| 3 | 列表.insert(下标, 元素) | 在指定下标处,插入指定的元素 |
| 4 | del 列表[下标] | 删除列表指定下标元素 |
| 5 | 列表.pop(下标) | 删除列表指定下标元素 |
| 6 | 列表.remove(元素) | 从前向后,删除此元素第一个匹配项 |
| 7 | 列表.clear() | 清空列表 |
| 8 | 列表.count(元素) | 统计此元素在列表中出现的次数 |
| 9 | 列表.index(元素) | 查找指定元素在列表的下标找不到报错ValueError |
| 10 | len(列表) | 统计容器内有多少元素 |
列表的方法 - 说明
功能方法非常多,同学们不需要硬记下来。
学习编程,不仅仅是Python语言本身,以后根据方向,会学习更多的框架技术。
除了经常用的,大多数是记忆不下来的。
我们要做的是,有一个模糊印象,知晓有这样的用法即可。
需要的时候,随时查阅资料即可。
列表的特点
经过上述对列表的学习,可以总结出列表有如下特点:
-
可以容纳多个元素(上限为2**63-1、9223372036854775807个)
-
可以容纳不同类型的元素(混装)
-
数据是有序存储的(有下标序号)
-
允许重复数据存在
-
可以修改(增加或删除元素等)
练习案例:常用功能练习
有一个列表,内容是:[21, 25, 21, 23, 22, 20],记录的是一批学生的年龄
请通过列表的功能(方法),对其进行
-
定义这个列表,并用变量接收它
-
追加一个数字31,到列表的尾部
-
追加一个新列表[29, 33, 30],到列表的尾部
-
取出第一个元素(应是:21)
-
取出最后一个元素(应是:30)
-
查找元素31,在列表中的下标位置
参考代码:
"""
演示List常用操作的课后练习
"""
# 1. 定义这个列表,并用变量接收它, 内容是:[21, 25, 21, 23, 22, 20]
mylist = [21, 25, 21, 23, 22, 20]
# 2. 追加一个数字31,到列表的尾部
mylist.append(31)
# 3. 追加一个新列表[29, 33, 30],到列表的尾部
mylist.extend([29, 33, 30])
# 4. 取出第一个元素(应是:21)
num1 = mylist[0]
print(f"从列表中取出来第一个元素,应该是21,实际上是:{num1}")
# 5. 取出最后一个元素(应是:30)
num2 = mylist[-1]
print(f"从列表中取出来最后一个元素,应该是30,实际上是:{num2}")
# 6. 查找元素31,在列表中的下标位置
index = mylist.index(31)
print(f"元素31在列表的下标位置是:{index}")
print(f"最后列表的内容是:{mylist}")
输出结果:
从列表中取出来第一个元素,应该是21,实际上是:21
从列表中取出来最后一个元素,应该是30,实际上是:30
元素31在列表的下标位置是:6
最后列表的内容是:[21, 25, 21, 23, 22, 20, 31, 29, 33, 30]
list(列表)的遍历
学习目标
-
掌握使用while循环,遍历列表的元素
-
掌握使用for循环,遍历列表的元素
列表的遍历 - while循环
既然数据容器可以存储多个元素,那么,就会有需求从容器内依次取出元素进行操作。将容器内的元素依次取出进行处理的行为,称之为:遍历、迭代。如何遍历列表的元素呢?可以使用前面学过的while循环
-
如何在循环中取出列表的元素呢?
-
使用列表[下标]的方式取出
循环条件如何控制?
-
定义一个变量表示下标,从0开始
-
循环条件为下标值 < 列表的元素数量
index = 0
while index < len(列表):
元素 = 列表[index]
对元素进行处理
index += 1
列表的遍历 - for循环
除了while循环外,Python中还有另外一种循环形式:for循环。
对比while,for循环更加适合对列表等数据容器进行遍历。
语法:
# for 临时变量 in 数据容器:
# 对临时变量进行处理
实例演示:
my_list = [1,2,3,4,5,]
for i in my_list:
print(i)
#结果为:
1
2
3
4
5
表示,从容器内,依次取出元素并赋值到临时变量上。
结果在每一次的循环中,我们可以对临时变量(元素)进行处理。
每一次循环将列表中的元素取出,赋值到变量i,供操作
while循环和for循环的对比
while循环和for循环,都是循环语句,但细节不同:
-
在循环控制上:
-
while循环可以自定循环条件,并自行控制
-
for循环不可以自定循环条件,只可以一个个从容器内取出数据
-
在无限循环上:
-
while循环可以通过条件控制做到无限循环
-
for循环理论上不可以,因为被遍历的容器容量不是无限的
-
在使用场景上:
-
while循环适用于任何想要循环的场景
-
for循环适用于,遍历数据容器的场景或简单的固定次数循环场景
代码
my_list = [1,2,3,4,5]
for i in my_list:
print("小美,我喜欢你")
输出结果为:
小美,我喜欢你
小美,我喜欢你
小美,我喜欢你
小美,我喜欢你
小美,我喜欢你
练习案例:取出列表内的偶数
定义一个列表,内容是:[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
-
遍历列表,取出列表内的偶数,并存入一个新的列表对象中
-
使用while循环和for循环各操作一次
通过while循环,从列表:[1,2,3,4,5,6,7,8,9,10]中取出偶数,组成新列表:[2,4,6,8,10]
通过f0循环,从列表:[1,2,3,4,5,6,7,8,9,10]中取出偶数,组成新列表:[2,4,6,8,10]
提示:
-
通过if判断来确认偶数
-
通过列表的append方法,来增加元素
参考代码:
# while 方法
old_list = [1,2,3,4,5,6,7,8,9,10]
new_list = []
i = 0
while i < len(old_list):
if old_list[i] % 2 == 0:
new_list.append(old_list[i])
i += 1
print(new_list)
# for 方法
old_list = [1,2,3,4,5,6,7,8,9,10]
new_list = []
for num in old_list:
if num % 2 == 0:
new_list.append(num)
print(new_list)
元组的定义
学习目标
-
掌握元组的定义格式
为什么需要元组
好的,首先让我们思考一个问题:为什么需要元组?我们之前学习的列表很强大,可以存储多个元素类型并且不受限制,但是我们想一想:列表有一个特点,它是可修改的。如果我需要传递的信息不能被篡改,那么列表就不太适合了。因此,我们需要引出另一种数据容器——元组。
元组和列表一样,都可以存储多个不同类型的元素,但是它们最大的区别在于,一旦元组定义完成就无法修改,因此可以将其视为只读列表。所以,如果我们需要在程序中封装数据,但又不希望封装的数据被篡改,那么元组就非常适合了。
接下来让我们看一下如何定义元组。
定义元组
元组定义:定义元组使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型。
# 定义元组字面量
(元素,元素,元素,……,元素,)
# 定义元组变量
变量名称 = (元素,元素,元素,……,元素,)
# 定义空元组
变量名称 = () # 方式1
变量名称 = tuple() # 方式2
注意事项:
# 定义3个元素的元组
t1 = (1,"Hello",True)
# 定义1个元素的元组
t2 = ("Hello",) #注意,必须带逗号,否则不是元组
注意事项:元组只有一个数据,这个数据后面要添加逗号
元组也支持嵌套:
# 定义一个嵌套元组
t1=((1,2,3),(4,5,6))
print(t1[0][0]) # 结果:1
元组的相关操作:
#根据下标(索引)取出数据
t1=(1,2,'he11o')
print(t1[2]) # 结果:'he11o'
#根据index(),查找特定元素的第一个匹配项
t1=(1,2,'hello',3,4,'hello')
print(t1.index('hello')) # 结果:2
#统计某个数据在元组内出现的次数
t1=(1,2,'he11o',3,4,'he11o')
print(t1.count('he1lo')) # 结果:2
#统计元组内的元素个数
t1=(1,2,3)
print(len(t1)) # 结果 3
| 编号 | 方法 | 作用 | |
|---|---|---|---|
| 1 | index() | 查找某个数据,如果数据存在返回对应的下标,否则报错 | |
| 2 | count() | 统计某个数据在当前元组出现的次数 | |
| 3 | len(元组) | 统计元组内的元素个数 | |
元组由于不可修改的特性,所以其操作方法非常少
元组的相关操作 - 注意事项
-
不可以修改元组的内容,否则会直接报错
# 尝试修改元组内容
t1=(1,2,3)
t1[0]=5
TypeError: 'tuple' object does not support item assignment
-
可以修改元组内的list的内容(修改元素、增加、删除、反转等)
# 尝试修改元组内容
t1 = (1,2,['itheima','itcast'])
t1[2][1]='best'
print(t1) # 结果:(1,2,['itheima','best'])
(1, 2, ['itheima', 'best'])
-
不可以替换list为其它list 或其它类型
# 尝试修改元组内容
t1 = (1,2,['itheima','itcast'])
t1[2]= [1,2,3]
print(t1)
TypeError: 'tuple' object does not support item assignment
元组的遍历
同列表一样,元组也可以被遍历。
可以使用while循环和for循环遍历它
while循环
my_tuple=(1,2,3,4,5)
index =0
while index < len(my_tuple):
print(my_tuple[index])
index += 1
for循环
my_tuple=(1,2,3,4,5)
for i in my_tuple:
print(i)
运行结果
1
2
3
4
5
元组的特点
经过上述对元组的学习,可以总结出列表有如下特点:
-
可以容纳多个数据
-
可以容纳不同类型的数据(混装)
-
数据是有序存储的(下标索引)
-
允许重复数据存在
-
不可以修改(增加或删除元素等)
-
支持for循环
多数特性和list一致,不同点在于不可修改的特性。
练习案例:元组的基本操作
定义一个元组,内容是:('周杰轮', 11, ['football', 'music']),记录的是一个学生的信息(姓名、年龄、爱好) 请通过元组的功能(方法),对其进行
-
查询其年龄所在的下标位置
-
查询学生的姓名
-
删除学生爱好中的football
-
增加爱好:coding到爱好list内
-
查询其年龄所在的下标位置:
参考代码
# 查询其年龄所在的下标位置
student = ('周杰轮', 11, ['football', 'music'])
age_index = student.index(11)
print(age_index) # 输出:1
# 查询学生的姓名:
student = ('周杰轮', 11, ['football', 'music'])
name = student[0]
print(name) # 输出:周杰轮
# 或者
student = ('周杰轮', 11, ['football', 'music'])
name = student.index('周杰轮')
print(name) # 输出:0
# 删除学生爱好中的football:
student = ('周杰轮', 11, ['football', 'music'])
student[2].remove('football')
print(student) # 输出:('周杰轮', 11, ['music'])
# 增加爱好:coding到爱好list内:
student = ('周杰轮', 11, ['football', 'music'])
student[2].append('coding')
print(student) # 输出:('周杰轮', 11, ['football', 'music', 'coding'])
字符串
学习目标
-
掌握字符串的常见操作
再识字符串
本小节让我们来学习一个老朋友——字符串。本小节的学习目标也非常简单,我们需要以数据容器的视角来学习一下字符串,并掌握它的常见操作。
虽然字符串看起来不像列表或元组那样明显地存放了许多数据,但不可否认的是,字符串同样也是数据容器的一种,它是字符的容器。一个字符串可以存放任意数量的字符。
比如字符串 "itheima",如果把它看做一个数据容器,那它就像下面这张图一样,其中每一个字符就是一个元素,每个元素还都有一个下标索引。

字符串的下标(索引)
和其它容器如:列表、元组一样,字符串也可以通过下标进行访问
-
从前向后,下标从0开始
-
从后向前,下标从-1开始
#通过下标获取特定位置字符
name ="itheima"
print(name[0]) # 结果i
print(name[-1]) # 结果a
同元组一样,字符串是一个:无法修改的数据容器。所以:
-
修改指定下标的字符 (如:字符串[0] = “a”)
-
移除特定下标的字符 (如:del 字符串[0]、字符串.remove()、字符串.pop()等)
-
追加字符等 (如:字符串.append())
均无法完成。如果必须要做,只能得到一个新的字符串,旧的字符串是无法修改。
字符串的常用操作
-
查找特定字符串的下标索引值
语法:字符串.index(字符串)
my_str = "itcast and itheima"
print(my_str.index("and")) # 结果7
-
字符串的替换
语法:字符串.replace(字符串1,字符串2)
功能:将字符串内的全部:字符串1,替换为字符串2
注意:不是修改字符串本身,而是得到了一个新字符串哦
name = "itheima itcast"
new_name=name.replace("it","传智")
print(new_name) # 结果:传智heima传智cast
print(name) # 结果:itheima itcast
可以看到,字符串name本身并没有发生变化而是得到了一个新字符串对象
-
字符串的分割
语法:字符串.split(分隔符字符串)
功能:按照指定的分隔符字符串,将字符串划分为多个字符串,并存入列表对象中
注意:字符串本身不变,而是得到了一个列表对象
name="传智播客 传智教育 黑马程序员 博学谷"
name_list = name.split(" ")
print(name_list) # 结果:[传智播客,'传智教育,黑马程序员,博学谷
print(type(name_list)) # 结果:<class!1ist'>
可以看到,字符串按照给定的 <空格>进行了分割,变成多个子字符串,并存入一个列表对象中。
-
字符串的规整操作(去前后空格)
语法:字符串.strip()
my_str = "itheima and itcast"
print(my_str.strip()) # 结果:"itheima and itcast"
-
字符串的规整操作(去前后指定字符串)
语法:字符串.strip(字符串)
my_str ="12itheima and itcast21"
print(my_str.strip("12")) # 结果:"itheima and itcast"
注意,传入的是“12” 其实就是:”1”和”2”都会移除,是按照单个字符。
-
统计字符串中某字符串的出现次数
语法:字符串.count(字符串)
my_str = "itheima and itcast"
print(my_str.count ("it")) # 结果:2
-
统计字符串的长度
语法:len(字符串)
my_str="1234abcd!@#$黑马程序员"
print(len(my_str)) # 结果:20
可以看出:
-
数字(1、2、3...)
-
字母(abcd、ABCD等)
-
符号(空格、!、@、#、$等)
-
中文
均算作1个字符 所以上述代码,结果20
字符串常用操作汇总
| 编号 | 操作 | 说明 |
|---|---|---|
| 1 | 字符串[下标] | 根据下标索引取出特定位置字符 |
| 2 | 字符串.index(字符串) | 查找给定字符的第一个匹配项的下标 |
| 3 | 字符串.replace(字符串1, 字符串2) | 将字符串内的全部字符串1,替换为字符串2 不会修改原字符串,而是得到一个新的 |
| 4 | 字符串.split(字符串) | 按照给定字符串,对字符串进行分隔不会修改原字符串,而是得到一个新的列表 |
| 5 | 字符串.strip() 字符串.strip(字符串) | 移除首尾的空格和换行符或指定字符串 |
| 6 | 字符串.count(字符串) | 统计字符串内某字符串的出现次数 |
| 7 | len(字符串) | 统计字符串的字符个数 |
字符串的遍历
同列表、元组一样,字符串也支持while循环和for循环进行遍历
while循环
my_str = "黑马程序员"
index = 0
while index < len(my_str):
print(my_str[index])
index += 1
for循环
my_str = "黑马程序员"
for i in my_str:
print(i)
输出结果都为:
黑
马
程
序
员
字符串的特点
作为数据容器,字符串有如下特点:
-
只可以存储字符串
-
长度任意(取决于内存大小)
-
支持下标索引
-
允许重复字符串存在
-
不可以修改(增加或删除元素等)
-
支持for循环
基本和列表、元组相同
不同与列表和元组的在于:字符串容器可以容纳的类型是单一的,只能是字符串类型。
不同于列表,相同于元组的在于:字符串不可修改
练习案例:分割字符串
给定一个字符串:"itheima itcast boxuegu"
-
统计字符串内有多少个"it"字符
-
将字符串内的空格,全部替换为字符:"|"
-
并按照"|"进行字符串分割,得到列表
提示:
字符串itheima itcast boxuegu中有:2个it字符
字符串itheima itcast boxuegu,被替换空格后,结果:itheima|itcastboxuegu
字符串itheima|itcastlboxuegu,按照|分隔后,得到:['itheima','itcast','boxuegu']
count、replace、split
示例代码:
"""
字符串课后练习演示
"itheima itcast boxuegu"
"""
my_str = "itheima itcast boxuegu"
# 统计字符串内有多少个"it"字符
num = my_str.count("it")
print(f"字符串{my_str}中有{num}个it字符")
# 将字符串内的空格,全部替换为字符:"|"
new_my_str = my_str.replace(" ", "|")
print(f"字符串{my_str}被替换空格后,结果是:{new_my_str}")
# 并按照"|"进行字符串分割,得到列表
my_str_list = new_my_str.split("|")
print(f"字符串{new_my_str}按照|分割后结果是:{my_str_list}")
数据容器(序列)的切片
学习目标
-
了解什么是序列
-
掌握序列的切片操作
序列
那么,什么是序列呢?序列是指内容连续有序,可使用下标索引的一类数据容器。我们之前学习的列表、元组和字符串都满足这些特点,因此它们都可以被称为序列。如下图所示,它们都是典型的序列:元素挨个紧密排列在一起,相邻元素之间是连续的,同时支持下标索引操作。


序列的概念比较简单,现在我们来看一下序列的操作,其中一个常用的操作是切片。
序列的常用操作 - 切片
序列支持切片,即:列表、元组、字符串,均支持进行切片操作
切片:从一个序列中,取出一个子序列
语法:序列[起始下标:结束下标:步长]
表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列:
-
起始下标表示从何处开始,可以留空,留空视作从头开始
-
结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
-
步长表示,依次取元素的间隔
-
步长1表示,一个个取元素
-
步长2表示,每次跳过1个元素取
-
步长N表示,每次跳过N-1个元素取
-
步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)
注意,此操作不会影响序列本身,而是会得到一个新的序列(列表、元组、字符串)
序列的切片演示
my_list = [1, 2, 3, 4, 5]
new_list = my_list[1:4] # 下标1开始,下标4(不含)结束,步长1
print(new_list) # 结果:[2, 3, 4]
my_tuple = (1, 2, 3, 4, 5)
new_tuple = my_tuple[:] # 从头开始,到最后结束,步长1
print(new_tuple) # 结果:(1, 2, 3, 4, 5)
my_list = [1, 2, 3, 4, 5]
new_list = my_list[::2] # 从头开始,到最后结束,步长2
print(new_list) # 结果:[1, 3, 5]
my_str = "12345"
new_str = my_str[:4:2] # 从头开始,到下标4(不含)结束,步长2
print(new_str) # 结果:"13"
my_str = "12345"
new_str = my_str[::-1] # 从头(最后)开始,到尾结束,步长-1(倒序)
print(new_str) # 结果:"54321"
my_list = [1, 2, 3, 4, 5]
new_list = my_list[3:1:-1] # 从下标3开始,到下标1(不含)结束,步长-1 (倒序)
print(new_list) # 结果:[4, 3]
my_tuple = (1, 2, 3, 4, 5)
new_tuple = my_tuple[:1:-2]
# 从头(最后)开始,到下标1(不含)结束,步长-2(倒序)
print(new_tuple) # 结果:(5, 3)
可以看到,这个操作对列表、元组、字符串是通用的
同时非常灵活,根据需求,起始位置,结束位置,步长(正反序)都是可以自行控制的
练习案例:序列的切片实践
有字符串:"万过薪月,员序程马黑来,nohtyP学"
-
请使用学过的任何方式,得到"黑马程序员"
可用方式参考:
-
倒序字符串,切片取出或切片取出,然后倒序
-
split分隔"," replace替换"来"为空,倒序字符串
"""
演示序列的切片的课后练习
"万过薪月,员序程马黑来,nohtyP学"
"""
my_str = "万过薪月,员序程马黑来,nohtyP学"
# 倒序字符串,切片取出
result1 = my_str[::-1][9:14]
print(f"方式1结果:{result1}")
# 切片取出,然后倒序
result2 = my_str[5:10][::-1]
print(f"方式2结果:{result2}")
# split分隔"," replace替换"来"为空,倒序字符串
result3 = my_str.split(",")[1].replace("来", "")[::-1]
print(f"方式3结果:{result3}")
数据容器:set(集合)
学习目标
-
掌握集合的定义格式
-
掌握集合的特点
-
掌握集合的常见操作
为什么使用集合
我们目前接触到了列表、元组、字符串三个数据容器了。基本满足大多数的使用场景。
为何又需要学习新的集合类型呢?
通过特性来分析:
-
列表可修改、支持重复元素且有序
-
元组、字符串不可修改、支持重复元素且有序同学们,有没有看出一些局限?
局限就在于:它们都支持重复元素。如果场景需要对内容做去重处理,列表、元组、字符串就不方便了。而集合,最主要的特点就是:不支持元素的重复(自带去重功能)、并且内容无序
集合的定义
基本语法:
#定义集合字面量
{元素,元素,....,元素}
#定义集合变量
变量名称={元素,元素,......,元素}
#定义空集合
变量名称=set()
和列表、元组、字符串等定义基本相同:
-
列表使用:[]
-
元组使用:()
-
字符串使用:""
-
集合使用:{}
示例代码
names = {"黑马程序员","传智播客","itcast","itheima","黑马程序员","传智播客"}
print(names)
运行结果
{'itcast', '传智播客', '黑马程序员', 'itheima'}
结果中可见:去重且无序因为要对元素做去所以无法保证顺序和创建的时候一致重处理
集合的常用操作 - 修改
首先,因为集合是无序的,所以集合不支持下标索引访问,但是集合和列表一样,是允许修改的,所以我们来看看集合的修改方法。
-
添加新元素
语法:集合.add(元素)。
功能:将指定元素,添加到集合内
结果:集合本身被修改,添加了新元素
my_set = {"Hello","World"}
my_set.add("itheima")
print(my_set) # 结果 {'Hello','itheima','World']
-
移除元素
语法:集合.remove(元素)
功能:将指定元素,从集合内移除
结果:集合本身被修改,移除了元素
my_set = {"Hello","World","itheima"}
my_set.remove("Hello")
print(my_set) # 结果{'World','itheima'
-
从集合中随机取出元素
语法:集合.pop()
功能,从集合中随机取出一个元素
结果:会得到一个元素的结果。同时集合本身被修改,元素被移除
my_set = {"Hello","World","itheima"}
element =my_set.pop()
print(my_set) # 结果{'World','itheima'}
print(element) # 结果'He11o
-
清空集合
语法:集合.clear()
功能,清空集合
结果:集合本身被清空
my_set = {"Hello","World","itheima"}
my_set.clear()
print(my_set) # 结果:set() 空集合
-
取出2个集合的差集
语法:集合1.difference(集合2),
功能:取出集合1和集合2的差集(集合1有而集合2没有的)
结果:得到一个新集合,集合1和集合2不变
set1 = {1,2,3}
set2 = {1,5,6}
set3 = set1.difference(set2)
print(set3) # 结果:{2,3} 得到的新集合
print(set1) # 结果:{1,2,3}不变
print(set2) # 结果:{1,5,6}不变
-
消除2个集合的差集
语法:集合1.difference_update(集合2)
功能:对比集合1和集合2,在集合1内,删除和集合2相同的元素。
结果:集合1被修改,集合2不变
setl ={1,2,3}
set2={1,5,6}
set1.difference_update(set2)
print(set1) # 结果:{2,3]
print(set2) # 结果:{1,5,6}
-
2个集合合并
语法:集合1.union(集合2)
功能:将集合1和集合2组合成新集合
结果:得到新集合,集合1和集合2不变
set1 = {1,2,3}
set2 = {1,5,6}
set3 = set1.union(set2)
print(set3) # 结果:{1,2,3,5,6},新集合
print(set1) # 结果:{1,2,3},set1不变
print(set2) # 结果:{1,5,6},set2不变
集合的常用操作 - 集合长度
-
查看集合的元素数量
语法:len(集合)
功能:统计集合内有多少元素
结果:得到一个整数结果
set1={1,2,3}
print(len(set1)) # 结果3
集合的常用操作 - for循环遍历
集合同样支持使用for循环遍历
set1={1,2,3}
for i in set1:
print(i)
# 结果
1
2
3
要注意:集合不支持下标索引,所以也就不支持使用while循环。
集合常用功能总结
| 编号 | 操作 | 说明 |
|---|---|---|
| 1 | 集合.add(元素) | 集合内添加一个元素 |
| 2 | 集合.remove(元素) | 移除集合内指定的元素 |
| 3 | 集合.pop() | 从集合中随机取出一个元素 |
| 4 | 集合.clear() | 将集合清空 |
| 5 | 集合1.difference(集合2) | 得到一个新集合,内含2个集合的差集原有的2个集合内容不变 |
| 6 | 集合1.difference_update(集合2) | 在集合1中,删除集合2中存在的元素集合1被修改,集合2不变 |
| 7 | 集合1.union(集合2) | 得到1个新集合,内含2个集合的全部元素原有的2个集合内容不变 |
| 8 | len(集合) | 得到一个整数,记录了集合的元素数量 |
集合的特点
经过上述对集合的学习,可以总结出集合有如下特点:
-
可以容纳多个数据 • 可以容纳不同类型的数据(混装)
-
数据是无序存储的(不支持下标索引)
-
不允许重复数据存在
-
可以修改(增加或删除元素等)
-
支持for循环
练习案例:信息去重
有如下列表对象:my_list = ['黑马程序员', '传智播客', '黑马程序员', '传智播客', 'itheima', 'itcast', 'itheima', 'itcast', 'best'] 请:
-
定义一个空集合
-
通过for循环遍历列表
-
在for循环中将列表的元素添加至集合
-
最终得到元素去重后的集合对象,并打印输出

示例代码:
"""
演示集合的课后练习题
my_list = ['黑马程序员', '传智播客', '黑马程序员', '传智播客',
'itheima', 'itcast', 'itheima', 'itcast', 'best']
"""
my_list = ['黑马程序员', '传智播客', '黑马程序员', '传智播客',
'itheima', 'itcast', 'itheima', 'itcast', 'best']
# 定义一个空集合
my_set = set()
# 通过for循环遍历列表
for element in my_list:
# 在for循环中将列表的元素添加至集合
my_set.add(element)
# 最终得到元素去重后的集合对象,并打印输出
print(f"列表的内容是:{my_list}")
print(f"通过for循环后,得到的集合对象是:{my_set}")
字典的定义
学习目标
-
掌握字典的定义格式
为什么使用字典
生活中的字

通过【字】就能找到对应的【含义】
所以,我们可以认为,生活中的字典就是记录的一堆:【字】:【含义】 【字】:【含义】 ..
为什么需要字典
Python中字典和生活中字典十分相像:
| 生活中的字典 | Python中的字典 |
|---|---|
| 【字】:【含义】【字】:【含义】 | |
| 可以按【字】找出对应的【含义】 | Key: Value Key: Value |
| 可以按【Key】找出对应的【Value】 |
老师有一份名单,记录了学生的姓名和考试总成绩。
| 姓名 | 成绩 |
|---|---|
| 王力鸿 | 77 |
| 周杰轮 | 88 |
| 林俊节 | 99 |
现在需要将其通过Python录入至程序中,并可以通过学生姓名检索学生的成绩。使用字典最为合适:
{"王力鸿":99,
"周杰轮":88,
"林俊节":77
}
可以通过Key(学生姓名),取到对应的Value(考试成绩)
所以,为什么使用字典?
因为可以使用字典,实现用key取出Value的操作
字典的定义
字典的定义,同样使用{},不过存储的元素是一个个的:键值对,如下语法:
#定义字典字面量
{key:value,key:value,......,key:value}
#定义字典变量
my_dict = {key:value,key:value,......,key:value}
#定义空字典
my_dict ={} # 空字典定义方式1
my_dict= dict{} # 空字典定义方式2
-
使用{}存储原始,每一个元素是一个键值对
-
每一个键值对包含Key和Value(用冒号分隔)
-
键值对之间使用逗号分隔
-
Key和Value可以是任意类型的数据(key不可为字典)
-
Key不可重复,重复会对原有数据覆盖
前文中记录学生成绩的需求,可以如下记录:
stu_score = {"王力鸿":99,"周杰轮":88,"林俊节":77}
字典数据的获取
字典同集合一样,不可以使用下标索引
但是字典可以通过Key值来取得对应的Value
# 语法,字典[Key]可以取到对应的Value
stu_score={"王力鸿":99,"周杰轮":88,"林俊节":77}
print(stu_score["王力鸿"]) # 结果99
print(stu_score["周杰轮"]) # 结果88
print(stu_score["林俊节"]) # 结果77
字典的嵌套
字典的Key和Value可以是任意数据类型(Key不可为字典)那么,就表明,字典是可以嵌套的需求如下:记录学生各科的考试信息
| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 王力鸿 | 77 | 66 | 33 |
| 周杰轮 | 88 | 86 | 55 |
| 林俊节 | 99 | 96 | 66 |
代码:
stu_score={"王力鸿":{"语文":77,"数学":66,"英语":33},"周杰轮":{"语文":88,"数学":86,"英语":55},
"林俊节":{"语文":99,"数学":96,"英语":66}}
优化一下可读性,可以写成:
stu_score = {
"王力鸿":{"语文":77,"数学":66,"英语":33},
"周杰轮":{"语文":88,"数学":86,"英语":55},
"林俊节":{"语文":99,"数学":96,"英语":66}
}
嵌套字典的内容获取,如下所示:
stu_score = {
"王力鸿":{"语文":77,"数学":66,"英语":33},
"周杰轮":{"语文":88,"数学":86,"英语":55},
"林俊节":{"语文":99,"数学":96,"英语":66}
}
print(stu_score["王力鸿"]) # 结果:{"语文":77,"数学":66,"英语":33}
print(stu_score["王力鸿"]["语文"]) # 结果:77
print(stu_score["周杰轮"]["数学"]) # 结果:86
字典的常用操作
学习目标
-
掌握字典的常用操作
-
掌握字典的特点
字典的常用操作
-
新增元素
语法:字典[Key] = Value
结果:字典被修改,新增了元素
stu_score ={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
# 新增:张学油的考试成绩
stu_score['张学油']=66
print(stu_score) # 结果:{王力鸿:77,'周杰轮:88,林俊节:99,张学油:66}
-
更新元素
语法:字典[Key] = Value
结果:字典被修改,元素被更新
注意:字典Key不可以重复,所以对已存在的Key执行上述操作,就是更新Value值
stu_score ={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
# 更新:王力鸿的考试成绩
stu_score['王力鸿']=100
print(stu_score) # 结果:{王力鸿:100,周杰轮:88,林俊节:99}
-
删除元素
语法:字典.pop(Key)
结果:获得指定Key的Value,同时字典被修改,指定Key的数据被删除
stu_score ={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
value=stu_score.pop("王力鸿")
print(value) # 结果:77
print(stu_score) # 结果:{"周杰轮":88,"林俊节":99}
-
清空字典
语法:字典.clear()
结果:字典被修改,元素被清空
stu_score ={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
stu_score.clear()
print(stu_score) # 结果:{}
-
获取全部的key
语法:字典.keys()
结果:得到字典中的全部Key
stu_score ={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
keys = stu_score.keys()
print(keys) # 结果:dict_keys(['王力鸿','周杰轮','林俊节])
-
遍历字典
语法:for key in 字典.keys()
stu_score ={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
keys = stu_score.keys()
for key in keys:
print(f"学生:{key},分数:{stu_score[key]}")
学生:王力鸿,分数:77
学生:周杰轮,分数:88
学生:林俊节,分数:99
注意:字典不支持下标索引,所以同样不可以用while循环遍历。
-
计算字典内的全部元素(键值对)数量
语法:len(字典)
结果:得到一个整数,表示字典内元素(键值对)的数量
stu_score ={
"王力鸿":77,
"周杰轮":88,
"林俊节":99
}
print(len(stu_score)) # 结果 3
字典的常用操作总结
| 编号 | 操作 | 说明 |
|---|---|---|
| 1 | 字典[Key] | 获取指定Key对应的Value值 |
| 2 | 字典[Key] = Value | 添加或更新键值对 |
| 3 | 字典.pop(Key) | 取出Key对应的Value并在字典内删除此Key的键值对 |
| 4 | 字典.clear() | 清空字典 |
| 5 | 字典.keys() | 获取字典的全部Key,可用于for循环遍历字典 |
| 6 | len(字典) | 计算字典内的元素数量 |
字典的特点
经过上述对字典的学习,可以总结出字典有如下特点:
-
可以容纳多个数据 • 可以容纳不同类型的数据
-
每一份数据是KeyValue键值对
-
可以通过Key获取到Value,Key不可重复(重复会覆盖)
-
不支持下标索引
-
可以修改(增加或删除更新元素等)
-
支持for循环,不支持while循环
课后练习:升职加薪
有如下员工信息,请使用字典完成数据的记录。
并通过for循环,对所有级别为1级的员工,级别上升1级,薪水增加1000元
| 姓名 | 部门 | 工资 | 级别 |
|---|---|---|---|
| 王力鸿 | 科技部 | 3000 | 1 |
| 周杰轮 | 市场部 | 5000 | 2 |
| 林俊节 | 市场部 | 7000 | 3 |
| 张学油 | 科技部 | 4000 | 1 |
| 刘德滑 | 市场部 | 6000 | 2 |
运行后,输出如下信息:
全体员工当前信息如下:
{'王力鸿':{'部门':'科技部','工资':3000,'级别':1},'周杰轮':{'部门':'市场部','工资':5000,'级别':2},
'林俊节':{'部门':'市场部','工资':6000,'级别':3},'张学油':{'部门':'科技部','工资':4000,'级别':1},
'刘德滑':{'部门':'市场部','工资':6000,'级别':2}}
全体员工级别为1的员工完成升值加薪操作,操作后:
{'王力鸿':{'部门':'科技部','工资':4000,'级别':2},'周杰轮':{'部门':'市场部','工资':5000,'级别':2},
'林俊节':{'部门':'市场部','工资':6000,'级别':3},'张学油':{'部门':'科技部','工资':5000,'级别':2},
'刘德滑':{'部门':'市场部','工资':6000,'级别':2}}
参考代码:
"""
演示字典的课后练习:升职加薪,对所有级别为1级的员工,级别上升1级,薪水增加1000元
"""
# 组织字典记录数据
info_dict = {
"王力鸿": {
"部门": "科技部",
"工资": 3000,
"级别": 1
},
"周杰轮": {
"部门": "市场部",
"工资": 5000,
"级别": 2
},
"林俊节": {
"部门": "市场部",
"工资": 7000,
"级别": 3
},
"张学油": {
"部门": "科技部",
"工资": 4000,
"级别": 1
},
"刘德滑": {
"部门": "市场部",
"工资": 6000,
"级别": 2
}
}
print(f"员工在升值加薪之前的结果:{info_dict}")
# for循环遍历字典
for name in info_dict:
# if条件判断符合条件员工
if info_dict[name]["级别"] == 1:
# 升职加薪操作
# 获取到员工的信息字典
employee_info_dict = info_dict[name]
# 修改员工的信息
employee_info_dict["级别"] = 2 # 级别+1
employee_info_dict["工资"] += 1000 # 工资+1000
# 将员工的信息更新回info_dict
info_dict[name] = employee_info_dict
# 输出结果
print(f"对员工进行升级加薪后的结果是:{info_dict}")
拓展:数据容器对比总结
数据容器分类
数据容器可以从以下视角进行简单的分类:
-
是否支持下标索引
-
支持:列表、元组、字符串 - 序列类型
-
不支持:集合、字典 - 非序列类型
-
是否支持重复元素:
-
支持:列表、元组、字符串 - 序列类型
-
不支持:集合、字典 - 非序列类型
-
是否可以修改
-
支持:列表、集合、字典
-
不支持:元组、字符串
数据容器特点对比
| 列表 | 元组 | 字符串 | 集合 | 字典 | |
|---|---|---|---|---|---|
| 元素数量 | 支持多个 | 支持多个 | 支持多个 | 支持多个 | 支持多个 |
| 元素类型 | 任意 | 任意 | 仅字符 | 任意 | Key:Value Key:除字典外任意类型 Value:任意类型 |
| 下标索引 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 重复元素 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 可修改性 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| 数据有序 | 是 | 是 | 是 | 否 | 否 |
| 使用场景 | 可修改、可重复的一批数据记录场景 | 不可修改、可重复的一批数据记录场景 | 一串字符的记录场景 | 不可重复的数据记录场景 | 以Key检索 Value的数据记录场景 |
数据容器的通用操作
到目前为止,我们已经掌握了 5 种数据容器。现在,让我们来学习它们的通用操作。虽然每种容器都有自己独特的特点,但它们也有一些通用的操作。
数据容器的通用操作 - 遍历
数据容器尽管各自有各自的特点,但是它们也有通用的一些操作。首先,在遍历上:
-
5类数据容器都支持for循环遍历
-
列表、元组、字符串支持while循环,集合、字典不支持(无法下标索引)
尽管遍历的形式各有不同,但是,它们都支持遍历操作。
数据容器的通用统计功能
除了遍历这个共性外,数据容器可以通用非常多的功能方法
-
len(容器)
统计容器的元素个数
my_list = [1, 2, 3]
my_tuple = (1, 2, 3, 4, 5)
my_str = "itiheima"
print(len(my_list)) # 结果3
print(len(my_tuple)) # 结果5
print(len(my_str)) # 结果7
-
max(容器)
统计容器的最大元素
my_list = [1, 2, 3]
my_tuple = (1, 2, 3, 4, 5)
my_str = "itiheima"
print(max(my_list)) # 结果3
print(max(my_tuple)) # 结果5
print(max(my_str)) # 结果t
-
min(容器)
统计容器的最小元素
my_list = [1, 2, 3]
my_tuple = (1, 2, 3, 4, 5)
my_str = "itiheima"
print(min(my_list)) # 结果1
print(min(my_tuple)) # 结果1
print(min(my_str)) # 结果a
同学们可能会疑惑,字符串如何确定大小?下一小节讲解。
容器的通用转换功能
除了下标索引这个共性外,还可以通用类型转换
list(容器) 将给定容器转换为列表
tuple(容器) 将给定容器转换为元组
str(容器) 将给定容器转换为字符串
set(容器) 将给定容器转换为集合
容器通用排序功能
通用排序功能 sorted(容器, [reverse=True]) 将给定容器进行排序
注意,排序后都会得到列表(list)对象。
容器通用功能总览
| 功能 | 描述 |
|---|---|
| 通用for循环 | 遍历容器(字典是遍历key) |
| max | 容器内最大元素 |
| min() | 容器内最小元素 |
| len() | 容器元素个数 |
| list() | 转换为列表 |
| tuple() | 转换为元组 |
| str() | 转换为字符串 |
| set() | 转换为集合 |
| sorted(序列, [reverse=True]) | 排序,reverse=True表示降序得到一个排好序的列表 |
字符串大小比较
在上一节课的通用数据容器操作中,我们使用了Min和Max函数,在数据容器中找到最小和最大的元素。在上一节课中,我们有一个问题,那就是字符串如何进行大小比较?在本节课中,我们将讲解这个问题。但在讲解字符串大小比较之前,我们需要先普及一个概念,这就是ASCII码表。在我们的程序中,字符串中使用的字符可以是大写或小写的英文字母、数字以及特殊符号,如感叹号、斜杠、竖杠、“@”符号、井号、空格等。每个字符都有其对应的ASCII码表值,因此字符串的比较基于字符所对应的数字码值的大小来进行。
字符串进行比较就是基于数字的码值大小进行比较的。
下面是一个典型的ASCII码表,其中我们可以找到我们所使用的一系列符号或字符对应的码值。例如,数字0123456789对应的码值从48到57,我们经常使用的大写英文字母从A到Z,对应的码值在65到90之间,小写英文字母从a到z,对应的码值在97到122之间。因此,我们常用字符的码值都可以在表中找到,因此,字符串的大小比较就很容易理解了。
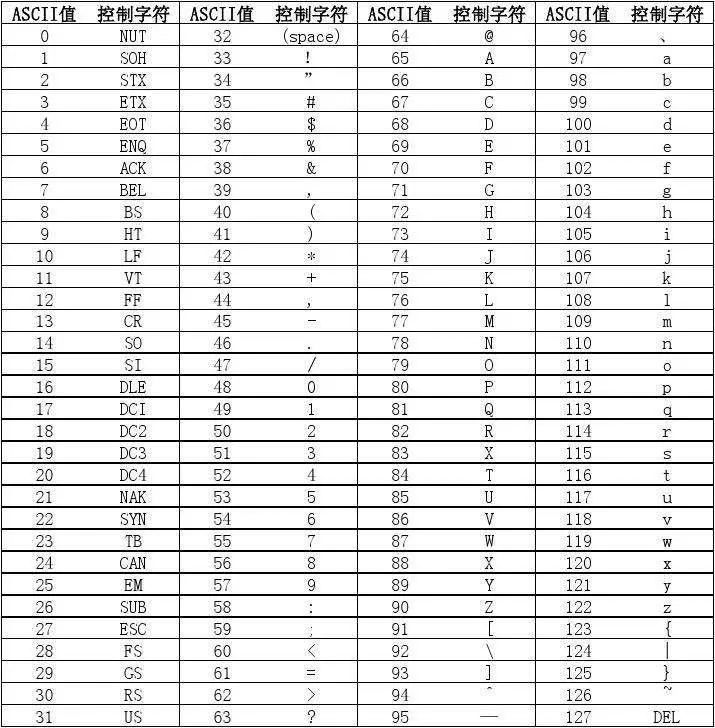
例如,一个小写的a和一个大写的A,我们说谁大谁小,实际上是通过码值进行比较的。小写的a和大写的A谁大谁小,也会发现小写的a的码值是97,比大写的A的65要大,所以字符串比较的基准依据就是 ASCII 码表的码值。了解这个概念之后,我们来看一下字符串进行比较的方式。
字符串比较
字符串是按位比较,也就是一位位进行对比,只要有一位大,那么整体就大。
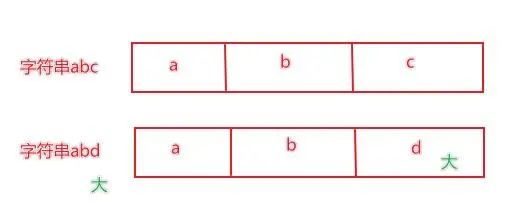
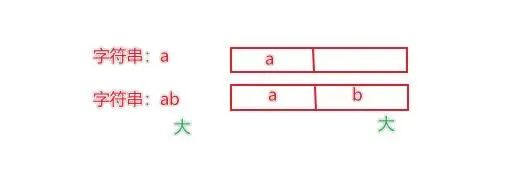
"""
演示字符串大小比较
"""
# abc 比较 abd
print(f"abd大于abc,结果:{'abd' > 'abc'}")
# a 比较 ab
print(f"ab大于a,结果:{'ab' > 'a'}")
# a 比较 A
print(f"a 大于 A,结果:{'a' > 'A'}")
# key1 比较 key2
print(f"key2 > key1,结果:{'key2' > 'key1'}")
输出结果
abd大于abc,结果:True
ab大于a,结果:True
a 大于 A,结果:True
key2 > key1,结果:True