目录
- 一、sort命令
- 1.1、命令演示
- 二、unip命令
- 1、命令演示
- 1、列题:
- 2、使用脚本来查看用户有没有被恶意登录,查看登录用户的对应ip地址
- 三、tr命令
- 1.1、命令演示
- 1.2、使用tr命令对数组进行排序
- 五、从Windows里拉文件到Linux系统中要做的潜在条件
- 六、cut命令
一、sort命令
sort命令—以行为单位对文件内容进行排序,也可以根据不同的数据类型来排序比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
语法格式:
sort [选项] 参数(文件排序)
cat 文件名 | sort 选项
| 常用选项 | 命令解释 |
|---|---|
| -n | 按照数字进行排序 |
| -r | 反向排序 |
| -u | 等同于unig,表示相同的数据仅显示一行 |
| -t | 指定字段分隔符,默认使用 [Tab]键分隔 |
| -k | 指定排序字段 |
| -o <输出文件> | 将排序后的结果转存至指定文件 |
| -f | 忽略大小写,会将小写字母都转换为大写字母来进行比较 |
| -b | 忽略每行前面的空格 |
1.1、命令演示
1、不加上-n,只会看首个字符来排序
[root@dz666 ~]# sort shuzi.txt
1
10
100
155
177
2
3
333
333
35
444
444
75
2、加上-n后就会按大小来排序
[root@dz666 ~]# sort shuzi.txt -n
1
2
3
10
35
75
100
155
177
333
333
444
444
3、加上-r后就是用反向排序
[root@dz666 ~]# sort shuzi.txt -n -r
444
333
333
177
155
100
75
35
10
3
2
1
4、使用-u后将重复的行内容都压缩在一行
[root@dz666 ~]# sort shuzi.txt -n -r -u
888
777
666
555
444
333
177
155
100
75
35
10
3
2
1
5、使用-t来指定分割符,-k指定排序字段,-n指定大小顺序
#使用-t来指定分割符,-k指定字段,-n指定大小顺序
[root@dz666 ~]# cat test1 | sort -t "." -k 4 -n
192.168.102.12
192.168.102.14
192.168.102.15
192.168.102.17
192.168.102.19
192.168.102.20
192.168.102.40
192.168.102.100
192.168.102.111
6、使用-o,效果为从定向输出,直接写入指定目录的文件
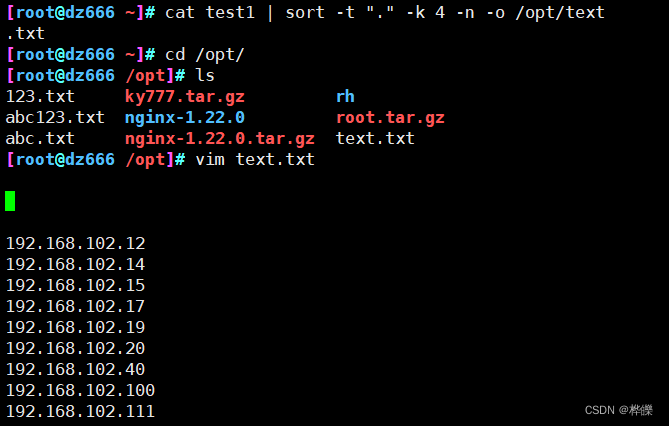
使用-b后忽略每行前面的空格
[root@dz666 ~]# cat test1 | sort -t "." -k 4 -n -b
192.168.102.12
192.168.102.14
192.168.102.15
192.168.102.17
192.168.102.19
192.168.102.20
192.168.102.40
192.168.102.100
192.168.102.111
二、unip命令
unig命令—用于报告或者忽略文件中连续的重复行,常与 sort 命令结合使用
语法格式:
uniq [选项] 参数
cat 文件名 | unig 选顶
| 常用选项 | 命令解释 |
|---|---|
| -c | 进行计数,并删除文件中重复出现的行 |
| -d | 仅显示连续的重复行 |
| -u | 仅显示出现一次的行 |
1、命令演示
先使用sort -n命令来整理序列在使用uniq来去除重合的数
[root@dz666 ~]# sort shuzi.txt -n | uniq
1
2
3
10
35
75
100
155
177
333
444
555
666
777
888
使用uniq -d 来查看重复的值
[root@dz666 ~]# sort shuzi.txt -n | uniq -d
333
444
使用uniq -u 来查看没有重复的值
[root@dz666 ~]# sort shuzi.txt -n | uniq -u
1
2
3
10
35
75
100
155
177
555
666
777
888
查看这个内容中的行内容出现的次数可以使用 uniq -c 来查看
[root@dz666 ~]# sort shuzi.txt -n | uniq -c
1 1
1 2
1 3
1 10
1 35
1 75
1 100
1 155
1 177
2 333
2 444
1 555
1 666
1 777
1 888
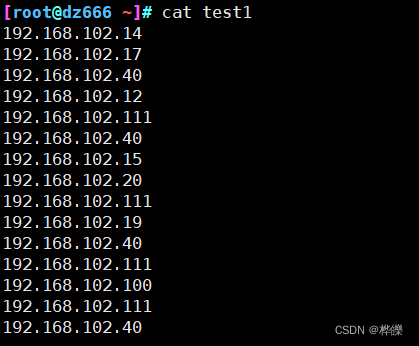
1、列题:
在这些ip地址中查看有哪些重复超过3次的ip地址
#!/bin/bash
cat test1 | sort -n -t "." -k 4 | uniq -c > /root/abc.txt
IFSB=$IFS
IFS=$'\n' #for循环的空格符只输出一个
for i in $(cat /root/abc.txt)
do
#获取出第一列的值
num=$(echo $i | awk '{print $1}')
if [ $num -gt 3 ]
then
#获取出这个文件的值
echo $i | awk '{print $2}'
fi
done
IFS=$IFSB #恢复原来的值
2、使用脚本来查看用户有没有被恶意登录,查看登录用户的对应ip地址
在源主机里查看日志
使用cd /var/log/ #进入var目录里的log里
使用tail secure -f #来查看日志
查看日志里的输入错误密码的用户ip地址
如果被人攻击了会出现大量的ip地址报错
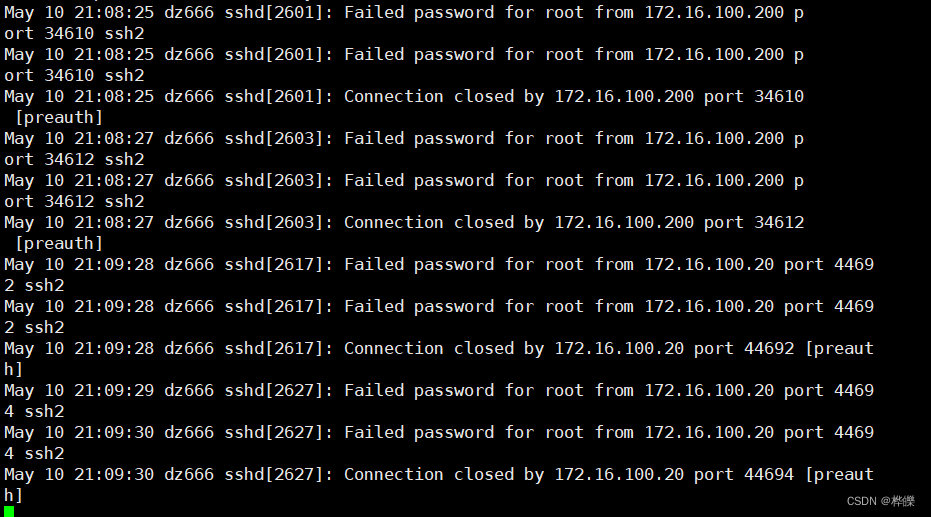
使用shell脚本将输入错误次数过多的ip地址放进黑名单里
#!/bin/bash
count=$(cat /var/log/secure | grep 'Failed password' | awk '{print $11}' | sort -n | uniq -c )
IFSB=$IFS
IFS=$'\n' #for循环的空格符只输出一个
for i in $count
do
num=$(echo $i | awk '{print $1}') #对重复的ip地址进行分片查看**加粗样式**
if [ $num -gt 3 ]
then
IP=$(echo $i | awk '{print $2}')
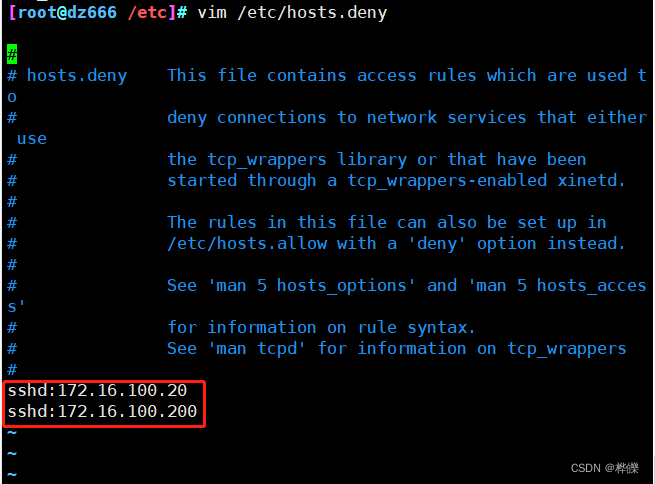
echo "sshd:$IP" >> /etc/hosts.deny #将出现错误次数过多的ip地址放进黑名单文件里
fi
done
IFS=$IFSB
在指定的文件里找到了登录错误过多用户的ip地址,将这些ip地址加入黑名单中
三、tr命令
tr命令—常用来对来自标准输入的字符进行替换、压缩和删除
语法格式:
tr [选项][参数]
| 常用选项 | 命令解释 |
|---|---|
| -c | 保留字符集1的字符,其他的字符 (包括换行符\n) 用字符集2替换 |
| -d | 删除所有属于字符集1的字符 |
| -s | 将重复出现的字符串压缩为一个字符;用字符集2 替换 字符集1 |
| -t | 字符集2 替换 字符集1,不加选项同结果 |
参数:
字符集1:指定要转换或删除的原字符集。当执行转换操作时,必须使用参数"字符集2”指定转换的目标宁符集。但执行删除操作时,不需要参数"字符集2"
字符集2:指定要转换成的目标宁符集。
[root@dz666 ~]# echo abc | tr 'a-z' 'A-Z'
ABC
[root@dz666 ~]#
[root@dz666 ~]# echo abc | tr 'a' 'A'
Abc
[root@dz666 ~]# echo abc | tr 'ac' 'AC'
AbC
[root@dz666 ~]# echo abc | tr 'ac' 'AX'
AbX
[root@dz666 ~]#
1.1、命令演示
1、使用-c来进行替换,不想将换行符进行替换的话加入\n
[root@dz666 ~]# echo -e "abc\nabcd\nab"
abc
abcd
ab
[root@dz666 ~]# echo -e "abc\nabcd\nab" | tr -c 'ab' '1'
[rooecho -e "abc\nabcd\nab" | tr -c 'ab\n' '1'
ab1
ab11
ab
2、删除某个字符使用-d来实现
[root@dz666 ~]# echo 'hellow nb'
hellow nb
[root@dz666 ~]# echo 'hellow nb' | tr -d ' '
#删除空字符,让两个字符连在一起
hellownb
[root@dz666 ~]# echo 'hellow nb' | tr -d 'ol'
#删除在这个字符串里有ol的所有字符
hew nb
3、使用-s来压缩重复的字符,也能实现替换
[root@dz666 ~]# echo 'thisssss iiiiiiis tessssssst linnnnnne' | tr -s 'sin' #将重复的字符写入进行压缩
this is test line
[root@dz666 ~]# echo 'thisssss iiiiiiis tessssssst linnnnnne' | tr -s 'sin' 'SIN'
thIS IS teSt lINe
[root@dz666 ~]# echo -e "ab\n\n\n\n\n\ncd"
ab
cd
[root@dz666 ~]# echo -e "ab\n\n\n\n\n\ncd" | tr -s "\n"
ab
cd
#使用tr -s命令来将中间空的换行符压缩成一个换行符
1.2、使用tr命令对数组进行排序
[root@dz666 ~]# arr=(63 2 4 3 15 1)
[root@dz666 ~]# echo ${arr[@]}
63 2 4 3 15 1
[root@dz666 ~]# echo ${arr[@]} | tr ' ' '\n'
63
2
4
3
15
1
[root@dz666 ~]# echo ${arr[@]} | tr ' ' '\n' | sort -n
#对数组进行大小排序
1
2
3
4
15
63
[root@dz666 ~]# echo ${arr[@]} | tr ' ' '\n' | sort -n | tr '\n' ' '
1 2 3 4 15 63 [root@dz666 ~]#
使用shell脚本来编写数组的排序
#!/bin/bash
arr=(24 36 53 12 6 9 1 3)
echo "排序前数组的值为; ${arr[@]}"
newarr=$(echo ${arr[@]} | tr ' ' '\n' | sort -n | tr '\n' ' ')
echo "排序后的数据的值为: ${newarr[@]}"

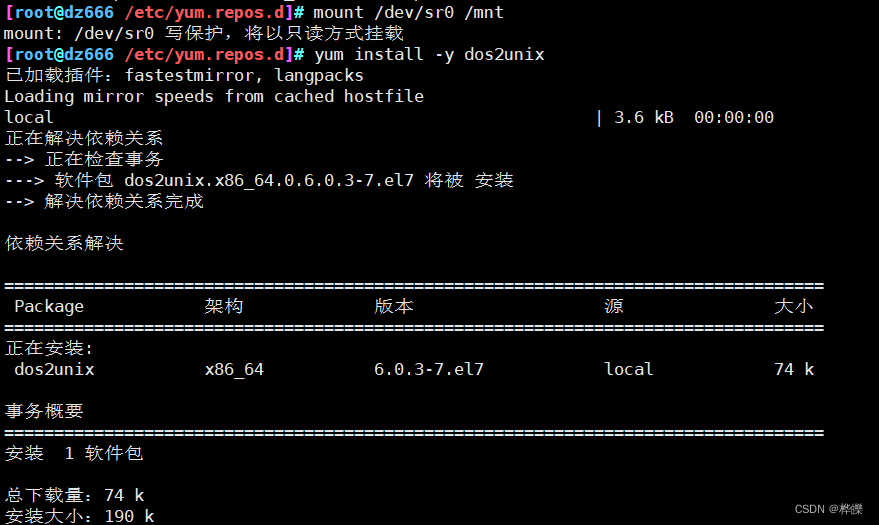
五、从Windows里拉文件到Linux系统中要做的潜在条件
使用在线源安装dos2unix
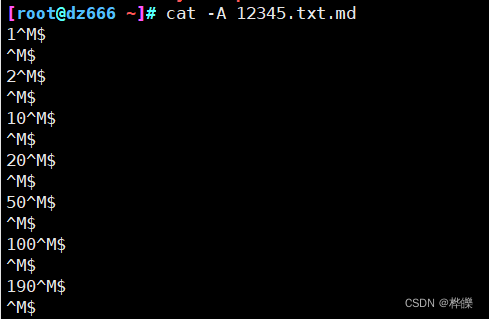
将Windows拉文件到Linux主机里会显示^M,用这个文件时会出现报错
使用
[root@dz666 ~]# dos2unix 12345.txt.md
#使用这个软件加上对应的文件名进行修改
dos2unix: converting file 12345.txt.md to Unix format ...
#正在修改文件内容
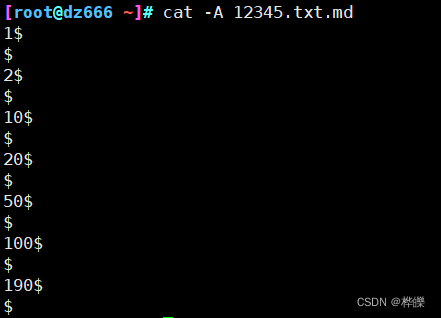
[root@dz666 ~]# cat 12345.txt.md
使用 “cat-A 文件名” 查看修改完成没
六、cut命令
cut命令—显示行中的指定部分,删除文件中指定字段
语法格式:
cut 参数
cat 文件名 | cut 选项
| 常用选项 | 命令解释 |
|---|---|
| -f | 通过指定哪一个字段进行提取。cut命令使用"TAB”作为默认的字段分隔符 |
| -d | “TAB”是默认的分隔符,使用此选项可以更改为其他的分隔符。 |
| - - complement | 此选项用于排除所指定的字段 |
| - -output-delimiter | 更改输出内容的分隔符 |
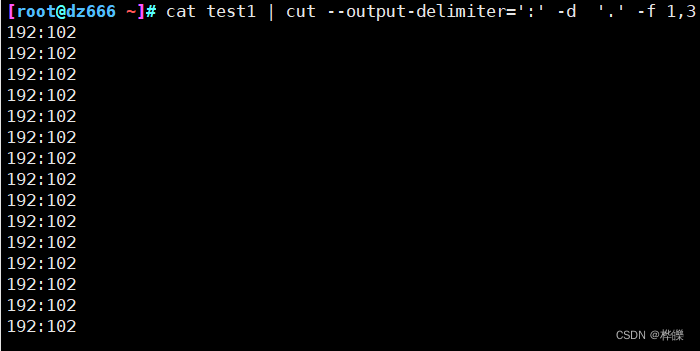
1、使用-f和-d来指示分割字段
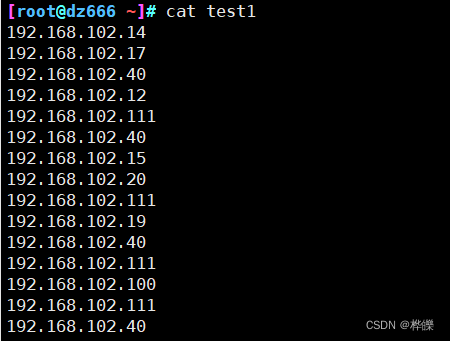
[root@dz666 ~]# cat test1 | cut -d '.' -f 4
14
17
40
12
111
40
15
20
111
19
40
111
100
111
40
实现多字段分割显示
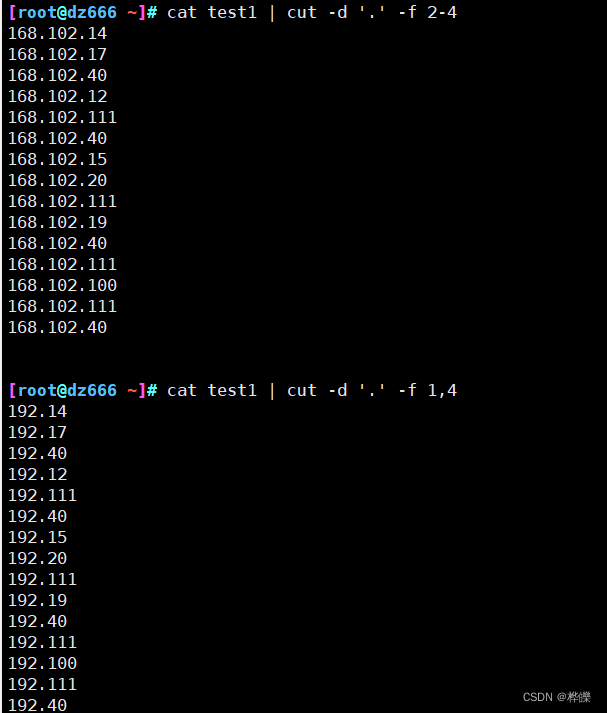
2、使用–complement命令来进行反向输出,除了指定的数不显示,其他都输出
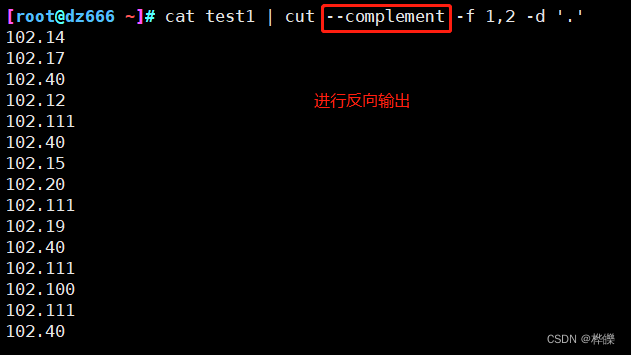
3、使用–output-delimiter命令来指定输出内容的分隔符