文章目录
- 基于`IRIS`列存储,我们能做什么
- 简介
- 使用场景
- 如何使用列存储
- 什么情况下使用列储存
- 统计数据数量`count`
- 计算字段平均值`avg`
- 计算字段和`sum`
- 列存储与行存储区别
- 总结
基于IRIS列存储,我们能做什么
简介
列存储是一种数据存储方式,与传统的行存储数据库(如关系数据库)不同。在列存储中,数据被存储在列中,而不是行中。
这种存储方式的主要优点在于,它可以更有效地存储和查询结构化数据,特别是需要执行大量聚合查询的数据。列存储数据库通常具有高性能,可以快速处理大量数据,并且适用于分析型数据仓库,时序数据,设备数据等。
列存储数据库通常使用NoSQL(Not Only SQL)数据库技术,并且不需要严格的数据模式。因此,它们更加灵活,可以快速适应数据变化,并且适用于处理大量数据。
使用场景
- 提高查询性能:列存储将同一列的数据存储在一起,减少了需要读取的磁盘块数量,因此在查询时可以更快地检索需要的数据,特别是当查询需要检索一部分列时,列存储可以提供更好的查询性能。
- 提高压缩比率:列存储可以使用列级别的压缩算法,由于同一列的数据通常具有相似性质,因此可以使用更高效的压缩算法,从而减少存储空间。
- 支持大规模数据分析:列存储是大规模数据分析的关键技术之一,因为它可以对大量的数据进行快速的分析和计算。通过将同一列的数据存储在一起,可以提供更高效的数据分析和聚合功能。
如何使用列存储
定义列存储需要在持久类中添加参数 STORAGEDEFAULT = "columnar并上类关键字Final。
定义User.Person表如下:
Class User.Person Extends %Persistent [ DdlAllowed, Final ]
{
Parameter STORAGEDEFAULT = "columnar";
Property Name As %String [ SqlColumnNumber = 2 ];
Property Number As %Integer [ SqlColumnNumber = 3 ];
Property Price As %Integer [ SqlColumnNumber = 4 ];
Property Amout As %Integer [ SqlColumnNumber = 5 ];
}
编译该类会产生如下所示的存储定义:
Storage Default
{
<Data name="_CDM_Amout">
<Attribute>Amout</Attribute>
<Structure>vector</Structure>
</Data>
<Data name="_CDM_Name">
<Attribute>Name</Attribute>
<Structure>vector</Structure>
</Data>
<Data name="_CDM_Number">
<Attribute>Number</Attribute>
<Structure>vector</Structure>
</Data>
<Data name="_CDM_Price">
<Attribute>Price</Attribute>
<Structure>vector</Structure>
</Data>
<DataLocation>^User.PersonD</DataLocation>
<IdLocation>^User.PersonD</IdLocation>
<IndexLocation>^User.PersonI</IndexLocation>
<StreamLocation>^User.PersonS</StreamLocation>
<Type>%Storage.Persistent</Type>
}
此存储定义看起来与为标准类定义创建的定义略有不同,后者使用传统的基于行的存储布局。虽然Global名称相同,但每个使用列式存储的属性都有一个 <Data> 元素。 (CDM代表列数据映射。) <Data> 标签的名称属性用作 ^User.PersonI Global中的下标,<Attribute> 元素包含属性名称,<Structure> 元素带有值向量表示向量用于以列形式表示属性的值。
向User.Person表添加数据,代码如下:
ClassMethod Save(num)
{
ts
for i = 1 : 1 : num {
s obj = ##class(User.Person).%New()
s obj.Name = "yx" _ $random(100)
s obj.Number = $random(100)
s obj.Price = $random(100)
s obj.Amout = obj.Number * obj.Price
s sc = obj.%Save()
ret:($$$ISERR(sc)) $system.Status.GetErrorText(sc)
}
b
tc
q $$$OK
}
列存储持久类中每个属性的数据存储在列中,数据并不存储在行中。所以^User.GlobalD中仅包含ID,不包含数据。
USER>w ##class(M.ColumnStorage).Save(1)
1
USER>w ##class(M.ColumnStorage).Save(1)
1
USER>w ##class(M.ColumnStorage).Save(1)
1
USER>zw ^User.PersonD
^User.PersonD=3
^User.PersonD(1)=""
^User.PersonD(2)=""
^User.PersonD(3)=""
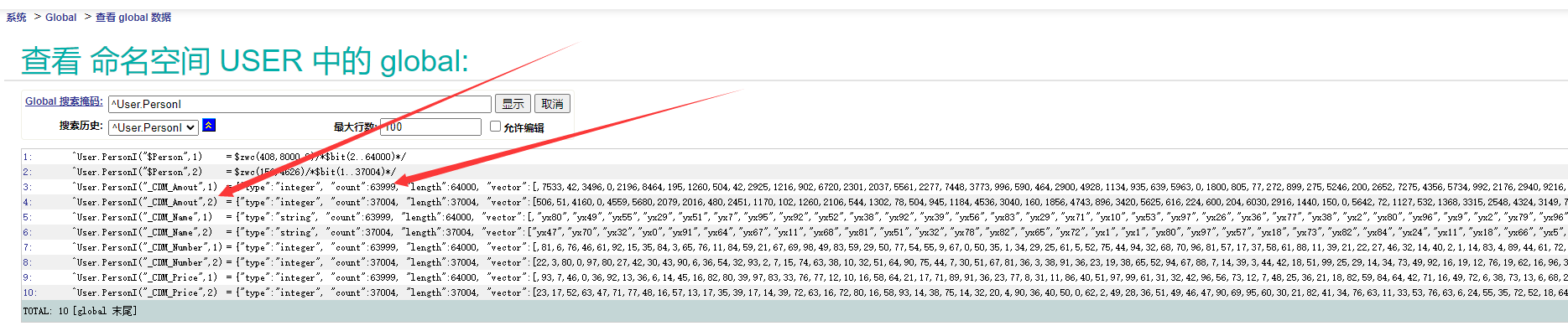
数据保存在^User.PersonI索引中,以Json格式保存数据。
type- 字段类型。count- 数据数量。vector- 数据值。length- 向量长度。
USER>zw ^User.PersonI
^User.PersonI("$Person",1)=$zwc(412,1,0)/*$bit(2..4)*/
^User.PersonI("_CDM_Amout",1)={"type":"integer", "count":3, "length":4, "vector":[,7533,42,3496]} ; <VECTOR>
^User.PersonI("_CDM_Name",1)={"type":"string", "count":3, "length":4, "vector":[,"yx80","yx49","yx55"]} ; <VECTOR>
^User.PersonI("_CDM_Number",1)={"type":"integer", "count":3, "length":4, "vector":[,81,6,76]} ; <VECTOR>
^User.PersonI("_CDM_Price",1)={"type":"integer", "count":3, "length":4, "vector":[,93,7,46]} ; <VECTOR>
这里我们注意索引第二个节点,代表当前索引存储数据的序号,当数据length超过64,000时,下标会自动加一。
注:count计数低于length,因为该列包含 NULL 值。
添加10W条数据。
USER>w ##class(M.ColumnStorage).Save(100000)
1
什么情况下使用列储存
创建User.People表字段与User.Person表相同,但User.People表为行存储,User.Person表为列储存。
Class User.People Extends %Persistent
{
Property Name As %String [ SqlColumnNumber = 2 ];
Property Number As %Integer [ SqlColumnNumber = 3 ];
Property Price As %Integer [ SqlColumnNumber = 4 ];
Property Amout As %Integer [ SqlColumnNumber = 5 ];
}
分别给User.People表与User.Person表添加1000W条数据。
如下示例计算的数据量均为1000W条数据。
统计数据数量count
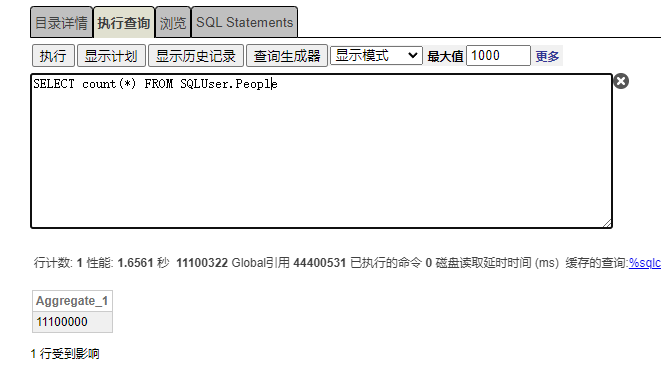
统计User.People表,数据数量,如图执行时间为1.6561秒。引用Global数量11100322个。
统计User.Person表,数据数量,如图执行时间为0.0026秒。引用Global数量496个。
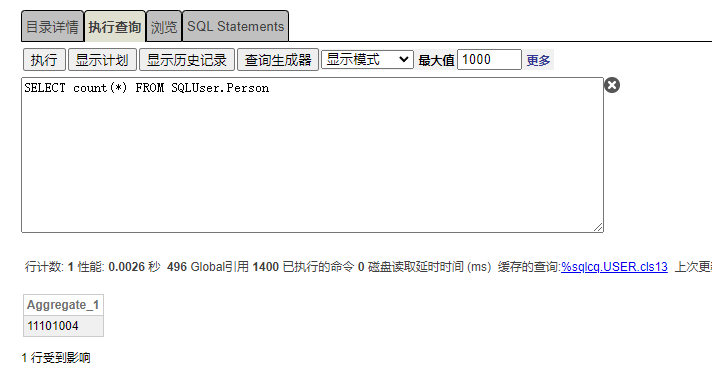
如上可观察到列储存User.Person聚合count效率是行储存User.People表 636倍。
计算字段平均值avg
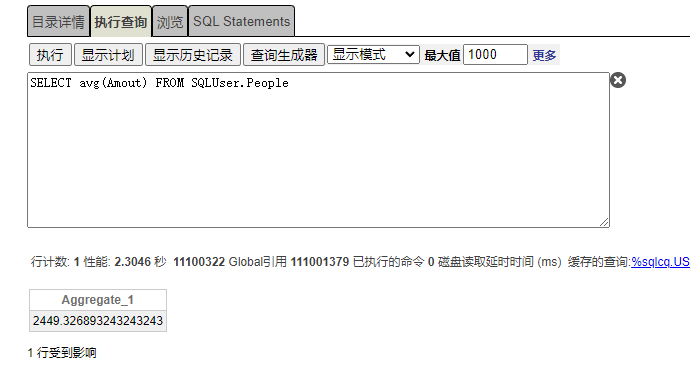
计算User.People表,Amount字段平均值,如图执行时间为2.3046秒。引用Global数量11101379个。
计算User.Person表,Amount字段平均值,如图执行时间为0.0179秒。引用Global数量2447个。
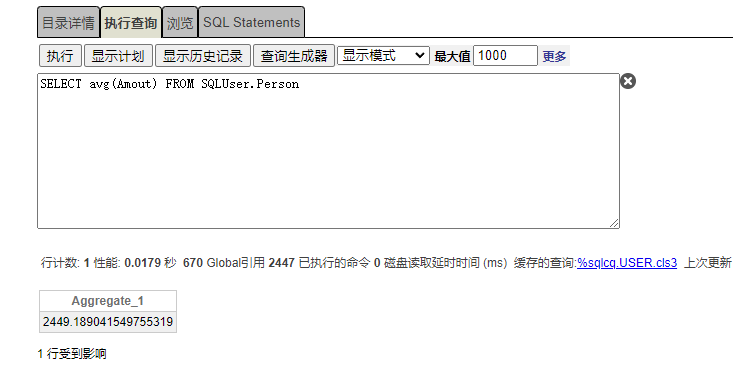
如上可观察到列储存User.Person聚合avg效率是行储存User.People表 128倍。
计算字段和sum
计算User.People表,Amount字段所有数据之和,如图执行时间为2.2902秒。引用Global数量88801366个。
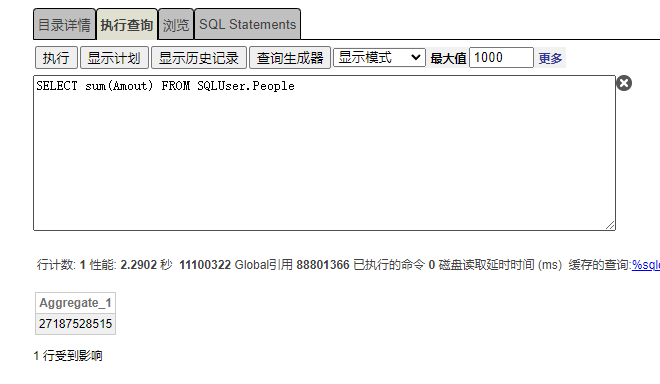
计算User.Person表,Amount字段数据之和,如图执行时间为0.0075秒。引用Global数量1922个。
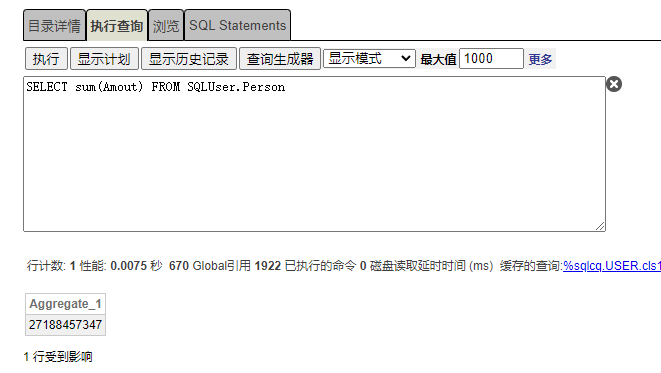
如上可观察到列储存User.Person聚合sum效率是行储存User.People表 305倍。
列存储与行存储区别
| 列存储 | 行存储 | |
|---|---|---|
| 数据存储 | 主数据存储在每列一个Global中。 64,000 个数据元素的序列存储在单独的Global。 | 主要数据存储在一个Global中。每行数据都存储在单独的Global下标中。 |
| 插入数据速度 | 慢,(因为每个列存储表插入数据时,会打开多个Global去赋值) | 快。(因为insert时,仅需要打开一个Global,添加$list即可) |
| 使用场景 | 不频繁变动的数据,例如,台帐,日志,病人生命体征数据,就很适合。 | 频繁变动的数据。 |
| 数据里要求 | SQL 表数据量大于100w(数据量100w时效率与行存储效率区别不大)。 | SQL 表数据量小于100w,则无需考虑列式存储。 |
| 单列数据查询 | 列存储查询时,单列所有数据都在一个Global中。查询1000w条数据可能只需174个Global。 | 行存储查询时,需要将每一列的Global保存到内存中,在根据Global的$list再取值。查询1000w条数据。就需要查询1000W个Global。 |

总结
- 选择正确的存储方式可以将查询性能提高一个数量级。
以上是个人对基于列存储的一些理解,由于个人能力有限,欢迎大家提出意见,共同交流。