😀大家好,我是白晨,一个不是很能熬夜,但是也想日更的人✈。如果喜欢这篇文章,点个赞👍,关注一下👀白晨吧!你的支持就是我最大的动力!💪💪💪

文章目录
- 📗前言
- 📙常用数据结构(一)
- 🍎单调栈
- 🍊单调队列
- 🥭并查集
- 🍋Trie
- 🍍哈希表
- 📘后记
📗前言
大家好,我是白晨。本次又为大家带来的是常用数据结构的模拟实现,主要用于在算法比赛中快速实现一种常用模拟实现。那为什么不用STL呢?首先,STL为了保证其接口的通用性以及要严格符合一个数据结构的定义,在使用时可能不是非常方便;其次,模拟实现的数据结构在运行速度方面是要快于STL的容器的。
上篇文章常用数据结构(一)我们介绍了单链表、双链表、栈、队列以及堆这五种最常用的数据结构的模拟实现,本次白晨将在上篇文章的基础上为大家介绍5种更高级的常用数据结构——单调栈、单调队列、并查集、Trie以及哈希表。
由于本次是面向新人的教程,白晨使用大量图片、动图和语言描述详细拆解一个模拟数据结构的实现。如果以前没有接触过并查集、Trie以及哈希表这几类数据结构的同学可以先阅读本篇文章种各个标题下链接的文章。话不多说,我们开始吧。

📙常用数据结构(一)
🍎单调栈
单调栈是指栈内元素单调递增或单调递减。具体来说,如果是单调递增栈,那么栈底到栈顶的元素就是从小到大排列的;如果是单调递减栈,那么栈底到栈顶的元素就是从大到小排列的。在使用单调栈时,我们可以利用这个特点来解决一些问题。
单调栈是一种和单调队列类似的数据结构。单调队列主要用于O(n)解决滑动窗口问题,单调栈则主要用于O(n)解决NGE问题(Next Greater Element),也就是,对序列中每个元素,找到下一个比它大的元素。
- 逻辑结构

上图为一个单调递增的栈。
- 物理结构
数组模拟栈。

- 具体实现
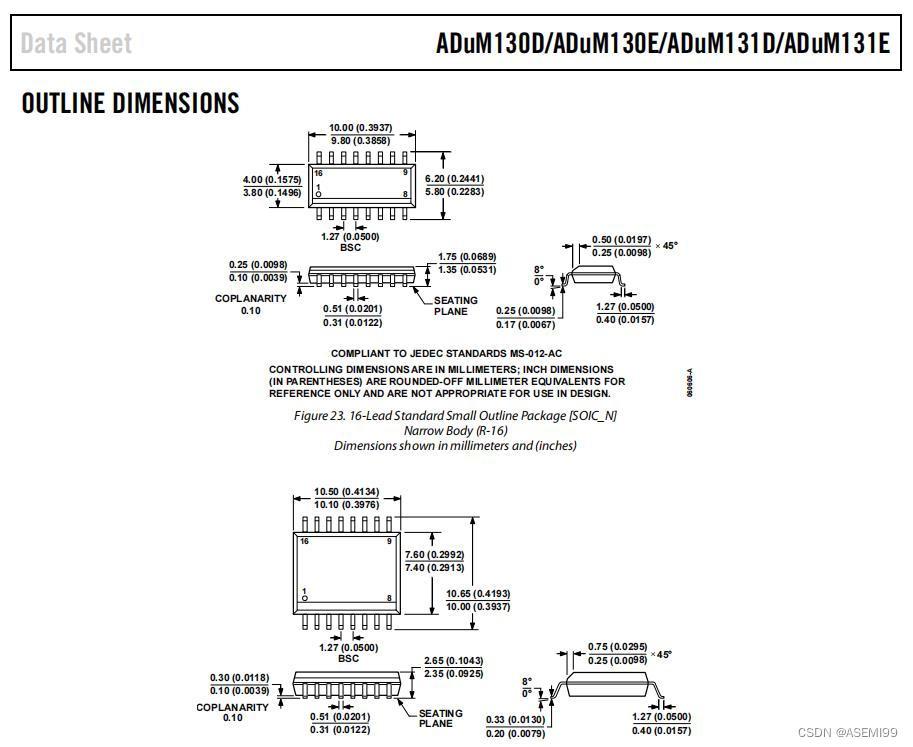
- 初始化
st为栈,top为栈顶下标。
const int N = 100010;
int st[N], top = 0; // 定义一个数组st和一个变量top,表示栈
- 插入
将一个元素插入单调栈时,为了维护栈的单调性,需要在保证将该元素插入到栈顶后整个栈满足单调性的前提下弹出最少的元素。
- 如果栈不为空且栈顶元素大于等于插入元素,那么就弹出栈顶元素,直到栈为空或者栈顶元素小于插入元素为止
- 将插入元素入栈
例如,栈中自底向上的元素为 { 0, 11, 45, 81 } 。插入元素 14 时为了保证单调性需要依次弹出元素 45, 81 ,操作后栈变为 { 0, 11, 14 } 。

while (top > 0 && st[top] >= num) top--; // 如果栈不为空且栈顶元素大于等于num,那么就弹出栈顶元素,直到栈为空或者栈顶元素小于num为止
st[++top] = num; // 将num压入栈中
单调栈一般只用插入这个操作,出栈一般在插入的过程中就已经完成。
- 练习题目

🍬原题链接:单调栈
🪅算法思想:
- 实现一个单调栈即可。
🪆代码实现:
#include <iostream>
using namespace std;
const int N = 100010;
int st[N], top = 0; // 定义一个数组st和一个变量top,表示栈
int main()
{
int n;
scanf("%d", &n); // 读入一个整数n
while (n--)
{
int num;
scanf("%d", &num); // 读入一个整数num
while (top > 0 && st[top] >= num) top--; // 如果栈不为空且栈顶元素大于等于num,那么就弹出栈顶元素,直到栈为空或者栈顶元素小于num为止
if (top > 0) printf("%d ", st[top]); // 如果栈不为空,那么栈顶元素就是num后面第一个比它小的数
else printf("-1 "); // 否则就不存在这样的数
st[++top] = num; // 将num压入栈中
}
return 0;
}
🍊单调队列
单调队列是一个限制只能队尾插入,但是可以两端删除的双端队列。单调队列存储的元素值,是从队首到队尾呈单调性的(要么单调递增,要么单调递减)。
但是单调队列和单调栈的功能有重合,所以我们一般不直接使用单调队列,而是使用基于单调队列的衍生数据结构——滑动窗口。下面讲解的数据结构为滑动窗口。
滑动窗口是一种基于双指针的一种思想,两个指针指向的元素之间形成一个窗口。
- 逻辑结构

- 物理结构
数组模拟实现滑动窗口。
- 具体实现
下面以单调递增队列举例。
- 初始化
a存储数据,q为队列,存储数据在a中下标。
head为队头下标,tail为队尾下标,sz为滑动窗口的大小。初始化队列,将队头指针
head赋值为0,将队尾指针tail赋值为-1。
const int N = 1000010;
int a[N], q[N];
int head, tail;
int sz;
注意:滑动窗口q存储的是a中数据的下标,而不是直接存储数据,并且滑动窗口大小指的是覆盖数组a中元素的个数,而不是单调队列的长度。
- 入队
滑动窗口的入队操作是从队尾进行插入,保证队列的单调性。具体来说,当要插入一个元素时,
- 判断
q队头元素,是否已经小于等于当前插入元素在a中的下标i减sz,如果小于,必须从队头出元素以保证插入这个元素不会超出滑动窗口的范围。- 从队尾开始,将所有比该元素
a[i]大的元素出队,直到遇到一个比该元素小的元素或者队列为空。- 将该元素的下标入队。
例如,有a={1,3,-1,-3,5,3,6,7},i为5,此时将a[5] = 3插入sz = 3滑动窗口中。

// 当队列中的头元素的下标 小于 滑动窗口的下限,出队
if (head <= tail && q[head] < i - k + 1) head++;
// 当队尾元素值 大于 当前元素,此时队尾元素将不再会被输出,所以直接从队尾出队
// 这也是为了满足当前队列的单调性为 单调递增,输出时直接输出队头就是最小的元素
while (head <= tail && a[q[tail]] > a[i]) tail--;
q[++tail] = i;
单调递增的滑动窗口同理:
- 判断
q队头元素,是否已经小于等于当前插入元素在a中的下标i减sz,如果小于,必须从队头出元素以保证插入这个元素不会超过滑出窗口的范围。- 从队尾开始,将所有比该元素
a[i]小的元素出队,直到遇到一个比该元素大的元素或者队列为空。- 将该元素的下标入队。
- 取滑动窗口最值
单调递增队列队头元素为 滑动窗口中最最小值的下标,滑动窗口中最最小值为
a[q[head]];单调递减队列队头元素为 滑动窗口中最最大值的下标,滑动窗口中最最大值为
a[q[head]]。
int res = a[q[head]];
下面的题目就是滑动窗口最直接的使用,如果你能理解下面的题目,相信你就完全懂了滑动窗口。
- 练习题目

🍬原题链接:滑动窗口
🪅算法思想:
- 首先,定义了一个数组
a[N],存储数据,以及一个队列q[N],存储数据在a中的下标。 - 接着,输入
n和k,以及n个数据。 - 然后,输出滑动窗口的最小值。定义了两个变量
head和tail,分别表示队列的头和尾。head初始化为0,tail初始化为-1。从0到n-1遍历数组a,每次都进行以下操作:- 当队列中的头元素的下标小于滑动窗口的下限时,出队。
- 当队尾元素值大于当前元素时,此时队尾元素将不再会被输出,所以直接从队尾出队。这也是为了满足当前队列的单调性为单调递增,输出时直接输出队头就是最小的元素。
- 将当前元素入队。
- 如果
i >= k - 1,则输出a[q[head]]。
- 最后,输出滑动窗口的最大值。与上面类似。
🪆代码实现:
#include <iostream>
using namespace std;
const int N = 1000010;
int a[N], q[N]; // a存储数据,q为队列,存储数据在a中下标
int head, tail;
int main()
{
int n, k;
scanf("%d%d", &n, &k);
for (int i = 0; i < n; ++i) scanf("%d", &a[i]);
// 输出滑动窗口最小值
head = 0, tail = -1;
for (int i = 0; i < n; ++i)
{
// 当队列中的头元素的下标 小于 滑动窗口的下限,出队
if (head <= tail && q[head] < i - k + 1) head++;
// 当队尾元素值 大于 当前元素,此时队尾元素将不再会被输出,所以直接从队尾出队
// 这也是为了满足当前队列的单调性为 单调递增,输出时直接输出队头就是最小的元素
while (head <= tail && a[q[tail]] > a[i]) tail--;
q[++tail] = i;
if (i >= k - 1) printf("%d ", a[q[head]]);
}
puts("");
head = 0, tail = -1;
for (int i = 0; i < n; ++i)
{
if (head <= tail && q[head] < i - k + 1) head++;
while (head <= tail && a[q[tail]] < a[i]) tail--;
q[++tail] = i;
if (i >= k - 1) printf("%d ", a[q[head]]);
}
puts("");
return 0;
}
🥭并查集
并查集 (英文:Disjoint-set data structure,直译为不交集数据结构)是一种数据结构 ,用于处理一些不交集 (Disjoint sets,一系列没有重复元素的集合)的合并及查询问题。并查集支持如下操作:
查询:查询某个元素属于哪个集合,通常是返回集合内的一个"代表元素"。这个操作是为了判断两个元素是否在同一个集合之中。
合并:将两个集合合并为一个。
本篇文章只介绍并查集的模拟实现,想具体了解并查集的同学可以参考这篇文章——【数据结构与算法】并查集。
举个例子,有小明、小亮、小虎、小李、小王、小孙六个学生,已知小明和小孙是同学,小王和小明是同学,小亮和小李是同学,小虎和小孙是同学。
- 问:
小虎和小王是什么关系,小李和小王是什么关系?

按照常识,我们可以把互为同学的学生划入同一个集合,如果两个同学的名字在同一个集合中出现,那么这两个人互为同学。反之,两个人不是同学。

观察上图,小虎和小王是同学关系,小李和小王不是同学关系。
上面就是并查集的简单应用,并查集能够快速合并两个集合以及快速查询两个元素是否在一个集合中,时间复杂度在大量查询的情况下可以达到O(1)。
- 逻辑结构

- 物理结构
数组模拟实现并查集。
- 具体实现
- 初始化
- 存储结构:数组
- 初始化:数组元素全部初始化为
-1。- 下标
i:从1号下标开始使用。- 存储数据
p[i]:孩子结点中存放父节点的下标,并查集的元素初始化为自身下标。
const int N = 100010;
int p[N];
for (int i = 1; i <= n; ++i) p[i] = i;
- 根结点查找
并查集最核心的操作就是查询元素集合的根,如果两个元素集合的根相同,说明两个元素在同一个集合中。子节点存放的是父节点的下标,只需要向上查找就能找到根。
- 如果当前节点不是根节点,就递归地找到它的父节点,然后将它的父节点指向根节点。这样可以压缩路径,使得每个节点都直接指向根节点,从而提高了查找效率。
- 如果当前节点是根节点,直接返回自己的下标。
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
- 合并
将两个集合合并:
- 查找两个要合并元素的根节点,根节点相同则不用合并;
- 如果两个根节点不同,则将随便将其中一个集合的根节点连接到另一个集合根节点下。
void merge(int x, int y)
{
p[find(x)] = find(y);
}
- 相关题目

🍬原题链接:合并集合
🪅算法思想:
并查集基本实现 + 应用。
🪆代码实现:
// 模板并查集
#include <iostream>
using namespace std;
const int N = 100010;
int p[N];
// 根结点查找 + 路径优化
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
void merge(int x, int y)
{
p[find(x)] = find(y);
}
int main()
{
int n, m;
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; ++i) p[i] = i;
while (m--)
{
char op[2];
int x, y;
scanf("%s%d%d", op, &x, &y);
if (op[0] == 'M') merge(x, y);
else
{
if (find(x) == find(y)) puts("Yes");
else puts("No");
}
}
return 0;
}
🍋Trie
Trie字典树又叫前缀树(prefix tree),用以较快速地进行单词或前缀查询。Trie树本质上就是一棵多叉树,用来存储字符串或者其他数据。
本篇文章只介绍Trie的模拟实现,想具体了解Trie的同学可以参考这篇文章——【数据结构与算法】Trie_
- 逻辑结构

- 物理结构
数组模拟实现Trie。
- 具体实现
- 初始化
- Trie:利用类似于单链表的方式模拟树形结构,Trie[i]就是一个结点,而Trie[i][26]为每个节点存储的子节点下标,相当于静态节点的26个子节点指针
- cnt:统计以Trie树的第N个结点所代表的字母结尾的单词数量
- idx:与单链表的idx类似,由于Trie树是利用二维数组模拟的,每一个Trie[i]为一个结点
const int N = 100010;
int Trie[N][26];
int cnt[N];
int idx = 0;
- 插入
将字符串
s插入到Trie中:
- 从根节点开始遍历字符串的每个字符;
- 如果该字符没有被插入到当前结点下,就将其插入(启用一个新节点,将新节点的下标保存到父节点),然后跳转到子节点,从子节点继续插入。
- 最后,以下标为 p 结点结尾的单词数量加 1。
void insert(const string& s)
{
int p = 0; // 从头结点开始遍历
for (int i = 0; i < s.size(); ++i)
{
int pos = s[i] - 'a'; // 下标映射
// 如果该字母没有被插入到当前结点下,将其插入(启用一个新节点,将新节点的下标保存到父节点)
// 当Trie[p][pos] 的值为0时,代表当前位置没有子节点
if (!Trie[p][pos]) Trie[p][pos] = ++idx;
p = Trie[p][pos]; // 跳转到子节点,从子节点继续插入
}
cnt[p]++; // 以下标为p结点结尾的单词数量加1
}
- 查询
查询字符串
s是否在Trie中出现过:
- 从根节点开始遍历字符串的每个字符;
- 如果该字符没有被插入到当前结点下,说明当前字母查找失败;
- 否则,继续查找。最后返回以下标为 p 结点结尾的单词数量。
int query(const string& s)
{
int p = 0;
for (int i = 0; i < s.size(); ++i)
{
int pos = s[i] - 'a';
// 当Trie[p][pos] 的值为0时,代表当前位置没有子节点,也说明当前字母查找失败
if (!Trie[p][pos]) return 0;
p = Trie[p][pos]; // 有子节点,继续查找
}
return cnt[p];
}
- 练习题目

🍬原题链接:Trie字符串统计
🪅算法思想:
按照字典树的结构进行插入和查询即可,主要注意实现。
具体实现见下面代码。
🪆代码实现:
#include <iostream>
#include <string>
using namespace std;
const int N = 100010;
int Trie[N][26]; // Trie树,利用类似于单链表的方式模拟树形结构,Trie[i]就是一个结点,而Trie[i][26]为每个节点存储的子节点下标,相当于静态节点的26个子节点指针
int cnt[N]; // 统计以Trie树的第N个结点所代表的字母结尾的单词数量
int idx = 0; // 与单链表的idx类似,由于Trie树是利用二维数组模拟的,每一个Trie[i]为一个结点
// 所以要让二维数组表示出树形关系,就得让父节点指向子节点的下标,idx代表当前使用到了哪一个结点,每使用一个结点,idx++。
// 初始除了头结点(Trie[0])以外,其他结点都没有使用,所以idx = 0。
int n;
void insert(const string& s)
{
int p = 0; // 从头结点开始遍历
for (int i = 0; i < s.size(); ++i)
{
int pos = s[i] - 'a'; // 下标映射
// 如果该字母没有被插入到当前结点下,将其插入(启用一个新节点,将新节点的下标保存到父节点)
// 当Trie[p][pos] 的值为0时,代表当前位置没有子节点
if (!Trie[p][pos]) Trie[p][pos] = ++idx;
p = Trie[p][pos]; // 跳转到子节点,从子节点继续插入
}
cnt[p]++; // 以下标为p结点结尾的单词数量加1
}
int query(const string& s)
{
int p = 0;
for (int i = 0; i < s.size(); ++i)
{
int pos = s[i] - 'a';
// 当Trie[p][pos] 的值为0时,代表当前位置没有子节点,也说明当前字母查找失败
if (!Trie[p][pos]) return 0;
p = Trie[p][pos]; // 有子节点,继续查找
}
return cnt[p];
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n;
while (n--)
{
string op, s;
cin >> op >> s;
if (op == "I") insert(s);
else cout << query(s) << endl;
}
return 0;
}
🍍哈希表
**哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度,哈希表的增删查改操作都是O(1)。**这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
本篇文章只介绍哈希的模拟实现,想具体了解哈希的同学可以参考这篇文章——【算法】哈希表
- 两种结构
- 开散列(拉链法)

- 闭散列(开放寻址法)

这两种实现的区别在于发生哈希冲突(关键值根据哈希函数得到的映射位置相同)以后处理的方式不同,拉链法是将冲突的元素全部在一个位置上串起来,像一个拉链一样;而开放寻址法是通过再哈希,确定一个没有值使用新的位置,保证一个位置只存放一个值。
- 开散列具体实现
- 初始化
哈希表的大小一般为质数,减少哈希冲突。
h:哈希表,对应位置存储单链表下标
e:存储数据值。
ne:存储该节点的下一个节点的坐标。
idx:指向e和ne中下一个要使用的节点。e,ne,idx:单链表,模拟每个哈希结点下挂的拉链。这里要注意上面的模拟单链表不是一般意义上的单链表,而是用数组模拟了多个单链表,用ne[k] = -1表示 NULL。ne[k] = -1时,表示k结点没有后驱结点了,也就是一个单链表结束。
const int N = 100003; // 超过10w的最小质数
int h[N];
int e[N], ne[N], idx;
- 插入
将数据插入哈希表:
先计算出
x的哈希值k,然后将x插入到以h[k]为头结点的单链表中。
void insert(int x)
{
int k = (x % N + N) % N; // 保证模出来的数一定为正数
// 单链表头插
e[idx] = x;
ne[idx] = h[k];
h[k] = idx++;
}
- 查询
查询数据是否在哈希表中:
先计算出
x的哈希值k,然后遍历以h[k]为头结点的单链表,查找是否存在x。
bool find(int x)
{
int k = (x % N + N) % N;
for (int i = h[k]; i != -1; i = ne[i])
if (e[i] == x)
return true;
return false;
}
- 闭散列具体实现
- 初始化
null:表示此位置为空
h:哈希表,存数据。开散列法时间复杂度主要取决于冲突次数,所以将数组大小开成要求大小的2~3倍。
const int N = 200003, null = 0x3f3f3f3f;
int h[N];
- 查询
查询数据是否在哈希表中,查询成功返回下标,失败返回该数应该被插入的下标:
先计算出
x的哈希值k,然后从h[k]开始往后遍历数组,直到找到x或者遇到空位置为止。
int find(int x)
{
int k = (x % N + N) % N;
// 不考虑数组被占满的情况
while (h[k] != null && h[k] != x)
{
k++;
if (k == N) k = 0;
}
return k;
}
- 插入
将数据插入哈希表中:
先调用
find函数查找x是否已经存在,如果不存在,则将x插入到find函数返回的下标处。
void insert(int x)
{
int k = find(x);
if (h[k] == null) h[k] = x;
}
- 练习题目

🍬原题链接:模拟散列表
🪅算法思想:
按照哈希表的思想进行实现,主要看下文代码实现。
🪆代码实现:
- 拉链法(开散列法)
// 拉链法
#include <iostream>
#include <cstring>
using namespace std;
const int N = 100003; // 超过10w的最小质数
int h[N]; // 哈希表,对应位置存储单链表下标
int e[N], ne[N], idx; // 单链表,模拟每个哈希结点下挂的拉链
// 这里要注意上面的模拟单链表不是一般意义上的单链表,而是用数组模拟了多个单链表,用ne[k] = -1表示 NULL
// ne[k] = -1时,表示k结点没有后驱结点了,也就是一个单链表结束
void insert(int x)
{
int k = (x % N + N) % N; // 保证模出来的数一定为正数
// 单链表头插
e[idx] = x;
ne[idx] = h[k];
h[k] = idx++;
}
bool find(int x)
{
int k = (x % N + N) % N;
for (int i = h[k]; i != -1; i = ne[i])
if (e[i] == x)
return true;
return false;
}
int main()
{
int m;
scanf("%d", &m);
memset(h, 0xff, sizeof h);
while (m--)
{
char op[2];
int x;
scanf("%s%d", op, &x);
if (op[0] == 'I') insert(x);
else
{
if (find(x)) puts("Yes");
else puts("No");
}
}
return 0;
}
- 开放寻址法(闭散列法)
// 开放寻址法
#include <iostream>
#include <cstring>
using namespace std;
const int N = 200003, null = 0x3f3f3f3f; // null表示这个位置为空
int h[N]; // 开散列法时间复杂度主要取决于冲突次数,所以将数组大小开成要求大小的2~3倍
// 查找成功返回下标,失败返回该数应该被插入的下标
int find(int x)
{
int k = (x % N + N) % N;
// 不考虑数组被占满的情况
while (h[k] != null && h[k] != x)
{
k++;
if (k == N) k = 0;
}
return k;
}
void insert(int x)
{
int k = find(x);
if (h[k] == null) h[k] = x;
}
int main()
{
memset(h, 0x3f, sizeof(h));
int m;
scanf("%d", &m);
while (m--)
{
char op[2];
int x;
scanf("%s%d", op, &x);
if (op[0] == 'I') insert(x);
else
{
int k = find(x);
if (h[k] != null) puts("Yes");
else puts("No");
}
}
return 0;
}
📘后记
本篇文章的数据结构非常重要,不仅是算法题目中最常用的几种结构,更是以后图论等算法的基础。希望大家能够将本篇文章和常用数据结构(一)中的数据结构模板牢牢记住,做到随用随写。
如果讲解的有不对之处还请指正,我会尽快修改,多谢大家的包容。
如果大家喜欢这个系列,还请大家多多支持啦😋!
如果这篇文章有帮到你,还请给我一个大拇指 👍和小星星 ⭐️支持一下白晨吧!喜欢白晨【算法】系列的话,不如关注👀白晨,以便看到最新更新哟!!!
我是不太能熬夜的白晨,我们下篇文章见。