一.虚拟机安装CentOS7并配置共享文件夹
二.CentOS 7 上hadoop伪分布式搭建全流程完整教程
三.本机使用python操作hdfs搭建及常见问题
四.mapreduce搭建
五.mapper-reducer编程搭建
mapper-reducer编程搭建
- 一、打开hadoop
- 二、创建mapper.py、reducer.py及参数文件
- 1.创建 mapper.py
- 2.创建reducer.py
- 3.创建参数文件
- 4.本地测试map与reduce
- 三、测试
- 1.hadfs中创建目录
- 2.上传test00.txt到hdfs中
- 3.执行测试例程
- 4.下载结果文件
一、打开hadoop

二、创建mapper.py、reducer.py及参数文件
1.创建 mapper.py
cd /home/huangqifa/software/
touch mapper.py
编辑内容
sudo gedit mapper.py
粘贴如下内容:
#!/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print '%s\t%s' % (word, 1)
# input comes from standard input
# remove leading and trailing whitespace
# split the line into words
# write the results to STDOUT
2.创建reducer.py
touch reducer.py
sudo gedit reducer.py
粘贴如下
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
Continue
if current_word == word:
current_count += count
else:
if current_word:
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
if current_word == word:
print '%s\t%s' % (current_word, current_count)
赋权
sudo chmod +x mapper.py
sudo chmod +x reducer.py
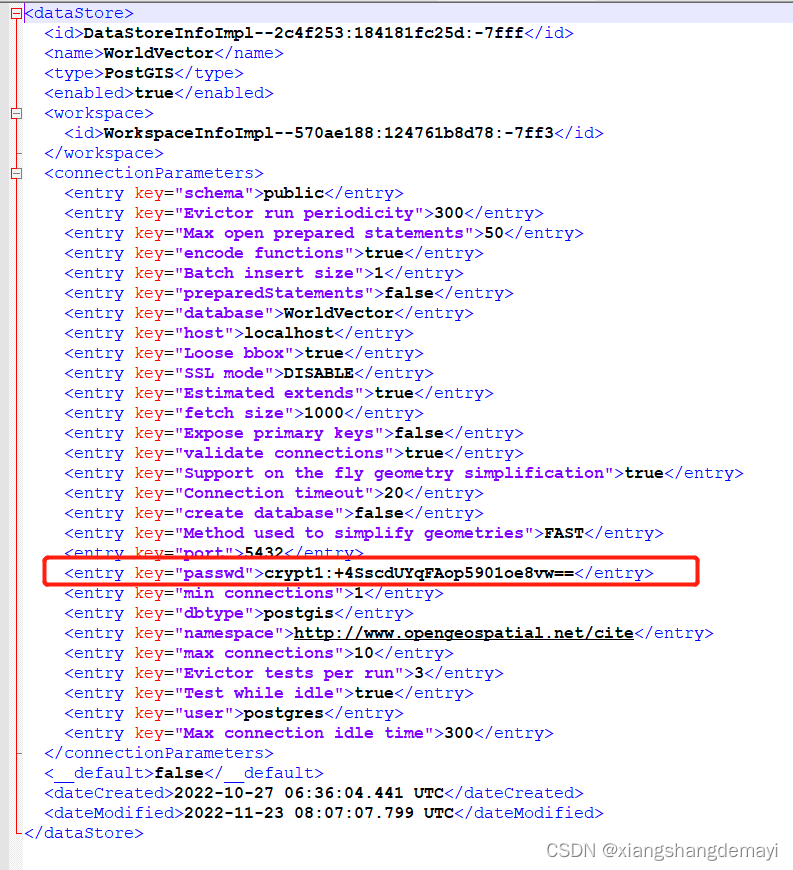
3.创建参数文件
touch test00.txt
粘贴如下
foo foo quux labs foo bar quux

4.本地测试map与reduce
测试mapper.py
echo "foo foo quux labs foo bar quux" | ./mapper.py
测试reducer.py
echo "foo foo quux labs foo bar quux" | ./mapper.py | sort -k1,1 | ./reducer.py
#其中sort -k 1起到了将mapper的输出按key排序的作用:-k, -key = POS1[,POS2] .

三、测试
1.hadfs中创建目录
hdfs dfs -mkdir -p /user/input
2.上传test00.txt到hdfs中
上传test00.txt到hdfs中的 /user/input目录
hdfs dfs -put /home/huangqifa/software/test00.txt /user/input

3.执行测试例程
hadoop jar /usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.7.7.jar -files /home/huangqifa/software/mapper.py,/home/huangqifa/software/reducer.py -mapper "mapper.py" -reducer "reducer.py" -input /user/input/test00.txt -output /user/output
注意修改为自己的mapper.py、reducer.py路径
若已存在/user/output执行时会报错
hdfs dfs -rm -r /user/output
查看输出文件
hdfs dfs -cat /user/output/*

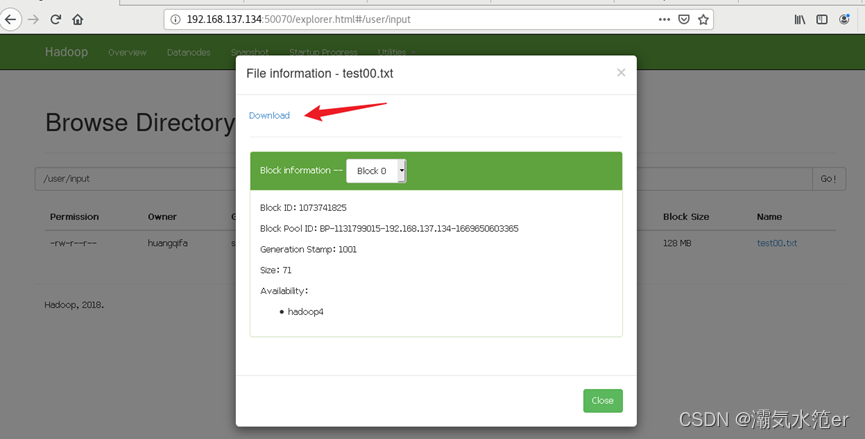
4.下载结果文件
hadoop fs -ls /user/output/
hadoop fs -get /user/output/part-00000

或者通过浏览器网页下载
参考
https://blog.csdn.net/andy_wcl/article/details/104610931
https://blog.csdn.net/qq_39315740/article/details/98108912