目录
#include
• .:换行符以外的任何字符
• […]:…字符中的任何一个
• [^…]:…字符之外的任何一个
• [[:charclass:]]:指定之字符类charclass中的一个
• \n, \t, \f, \r, \v:换行符,tab符号,还有。。。
• \xhh, \uhhh:一个十六进制字符或unicode字符
• \d, \D:一个数字,一个非数字
• \s, \S:一个空白字符,一个非空白字符
• \w, \W:一个字母,数字,下划线;不是字母,数字,下划线
• *:匹配0次或多次
• ?:0次或一次
• +:至少一次
• {n}:n次
• {n, }:至少n次
• {n, m}:至少n次,至多m次
• (…):设定分组
• \1, \2, \3:第n个分组
• ^:一行的起点
• $:一行的终点
一个正则表达式的语法是否正确是在运行时解析的
一个对象:match_results对象:
• match_results是个template,C++标准库提供了若干预定义的实例化实现:
○ smatch:匹配string
○ cmatch:匹配const char*
○ wsmatch:匹配wstring
○ wcmatch:匹配wcstring
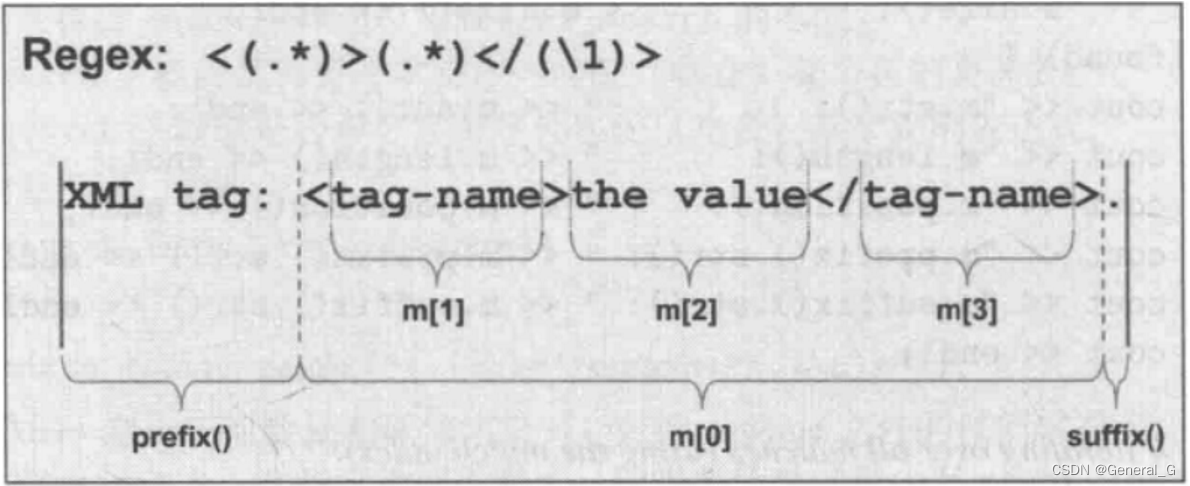
• sub_match对象m[n],所有sub_match对象都派生自pair<>, first是第一个字符的位置,second成员是最末字符的下一个位置
○ 一个sub_match对象m[0],表示匹配合格的所有字符
○ 一个prefix(), 第一个匹配合格的字符前方所有字符
○ 一个suffix(), 最后一个匹配合格的字符后方的所有字符
○ size():匹配到的子对象的个数
○ 捕获组可以以m[n] 访问
• match_results对象作为一个整体,提供了:
○ str():
§ 匹配合格的整体string,str()或str(0)
§ 第n个匹配合格的substring,str(n)
§ 如果不存在这样的string则返回空
○ length()
§ 匹配合格的整体字符串长度,length()或length(0)
§ 第n个匹配合格的子字符串长度,length(n)
○ position():
§ 匹配合格的整体字符串的位置:position()或position(0)
§ 第n个匹配合格的子字符串位置:position(n)
○ begin()/cbegin()/end()/cend():可用来迭代匹配的子对象,从m[0]到m[n]
两个迭代器:
正则表达式迭代器:regex_iterator, sregex_iterator,为了注意迭代正则查找的所有匹配成果
sregex_iterator pos(data.cbegin(), data.cend(), reg);
sregex_iterator end;
for(; pos != end; ++pos){
cout << "match: " << pos->str() << endl;
cout << " tag: " << pos->str(1) << endl;
cout << "value: " << pos->str(2) << endl;
}
Regex Token Iterator:处理子序列之间的内容,特别是打算将string拆分成一个个语汇单元,regex_token_iterator<>就提供了这样的功能
三个函数:
regex_match:检验是否整个字符序列匹配某个正则表达式,,返回true
regex_search:检验是否部分字符序列匹配某个正则表达式,搜索全部,但只输出第一个匹配到的,返回true
regex_replace
2.这些函数的参数:
(seq, m, r, mft)/(seq, r, mft)
3.指定regex对象:
对象:
• regex r(re 【,f】):re可以为string,一个表示字符范围的迭代器对,一个指向空字符结尾的字符数组的指针,一个字符指针,一个计数器,一个花括号包围的字符列表,f是指出对象如何处理的标识,默认为ECMAScript
• r1=re
• r1.assign(re, f)
• r.mark_count()
• f.flags()
异常:
如果正则表达式存在错误,在运行时标准库会抛出一个类型为regex_error的异常:
• what:描述发生了什么错误
• code: