一、源码
github源码
二、介绍
采用Tesseract OCR识别
采用多线程进行图片识别
- 界面
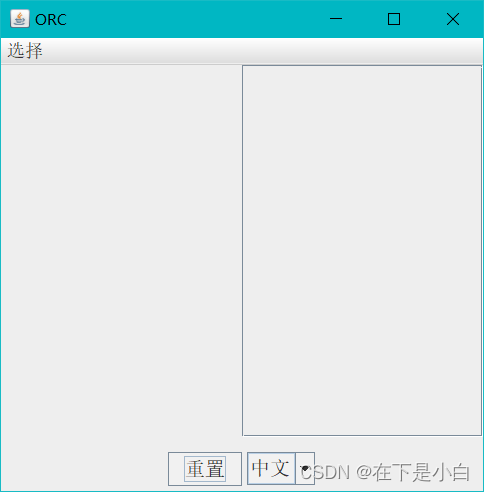
- 选择
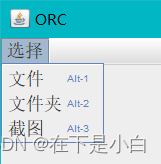
- 文件是可以识别本地的多张图片
- 文件夹是识别文件夹里面的所有图片的内容
- 截图 可以复制到剪切板、可以识别也可以直接保存
- 重置 是清除选择的图片和识别结果
- 语言选择 是选择不同的模型。提高识别率
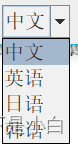
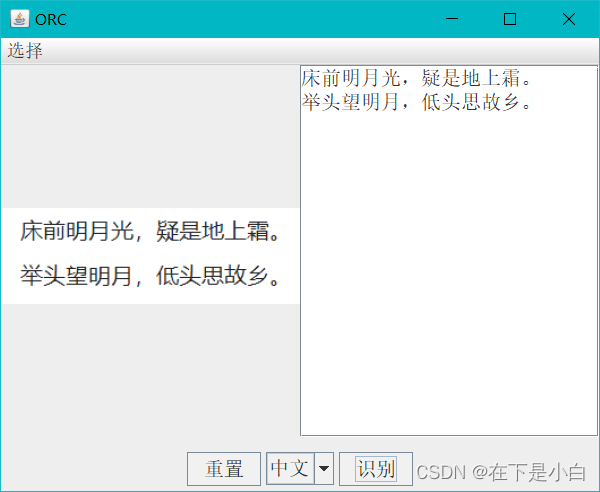
中文识别
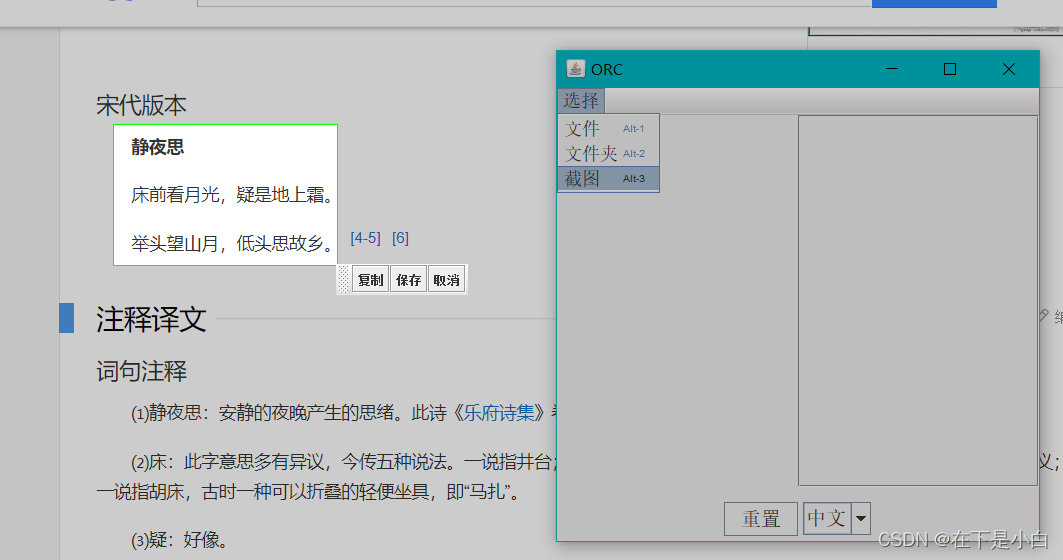
截图的框选,不满意重新拖动即可重新截取
- 可以复制到剪切板和左侧识别
- 可以保存到本地
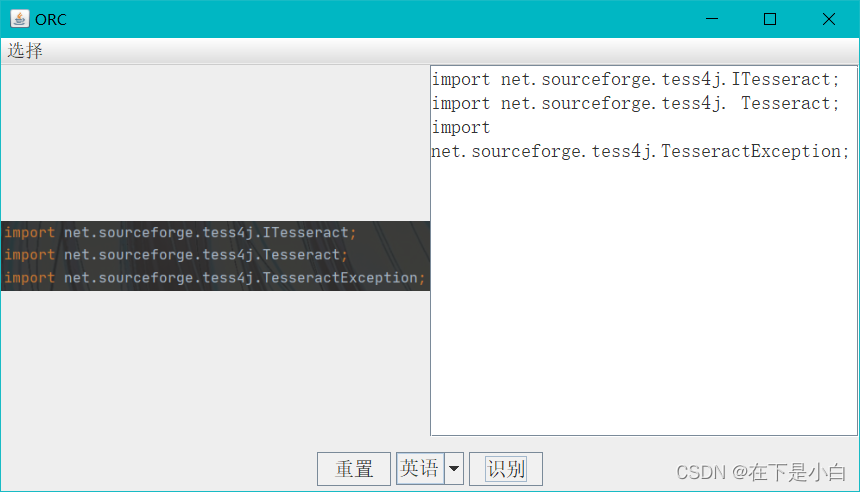
英语识别
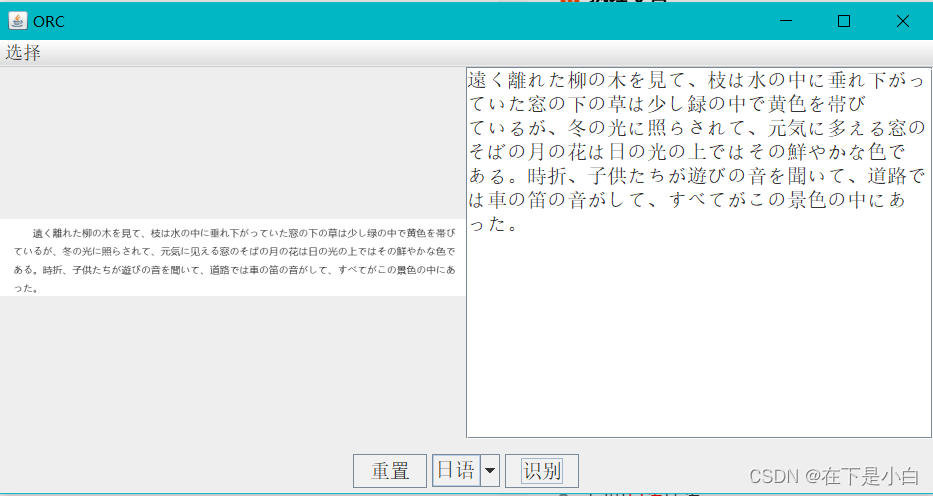
日语识别
韩语识别
韩语很奇怪,明明已经识别出来了,但是显示有问题
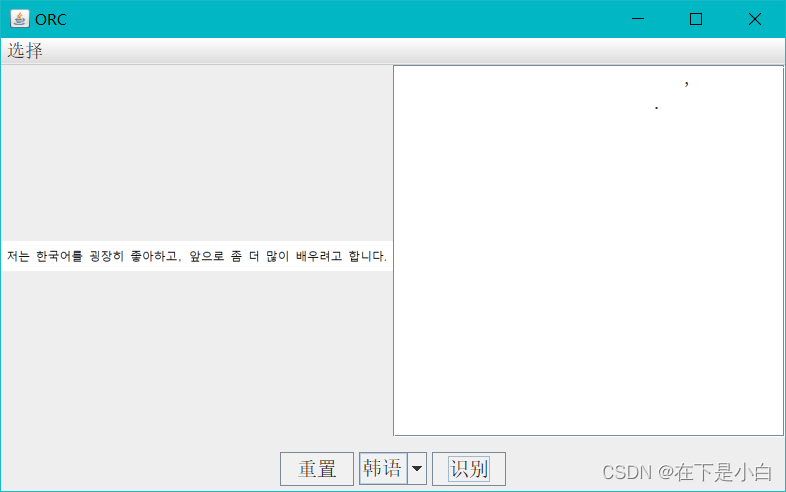
手动复制内容
저는 한국어를 굉장히 좋아하고, 앞으로 좀 더 많이 배우려고 합니다.
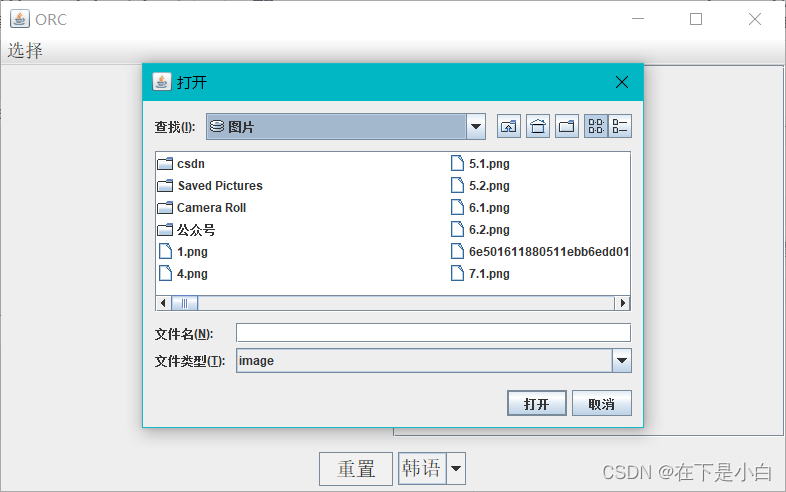
文件识别
弹出文件选择框,可以多选
文件夹识别
就不做演示了,就是选择你要识别的文件夹,然后递归识别改文件夹内的所有jgp、png图片进行文件识别
识别的结果还是很不错的