1 DETR
1.1 DETR处理流程
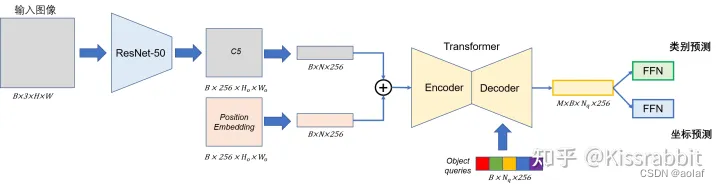
1.1.1 将图像输入给Backbone获得图像特征与位置编码
①. 对给定的输入图像通过resnet进行特征提取,最终得到特征图C5∈RBx2048xhxw,其中h、w为输入图像尺寸得1/32。随后再用一层1×1卷积压缩一下通道,得到特征图P5∈RBx256xhxw。将其转换为Transformer输入格式:[B, h*w, 256]。
②. 为了保证图像二维的特性,需要在X和Y两个维度都去计算Position Embedding。利用Position Embedding为输入序列提供位置信息。
综上,经过self.backbone(),可以获得图像特征src以及对应得位置编码pos 。
class DETR(nn.Module):
""" This is the DETR module that performs object detection """
def __init__(self, backbone, transformer, num_classes, num_queries, aux_loss=False):
super().__init__()
self.num_queries = num_queries
self.transformer = transformer
hidden_dim = transformer.d_model
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)
self.query_embed = nn.Embedding(num_queries, hidden_dim)
self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1)
self.backbone = backbone
self.aux_loss = aux_loss
def forward(self, samples: NestedTensor):
if isinstance(samples, (list, torch.Tensor)):
samples = nested_tensor_from_tensor_list(samples)
# features: [mask, src], pos: 位置编码[2, 256, 27, 24]
features, pos = self.backbone(samples)
# src:[2, 2048, 27, 24], mask:[2, 27, 24]
src, mask = features[-1].decompose()
assert mask is not None
# 将图像特征src的通道数由2048降维至256然后进行encoder、decoder
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]
# 全连接,类别预测 [6, b, 100, 256]--->[6, b, 100, 92]
outputs_class = self.class_embed(hs)
# bbox (cx, cy, w, h), 均属于0~1区间,因此采用sigmoid映射到(0, 1), [6, b, 100, 256]--->[6, b, 100, 4]
outputs_coord = self.bbox_embed(hs).sigmoid()
# 只取最后一层的decoder结果
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
# 是否保留decoder中间层结果
if self.aux_loss:
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)
return out
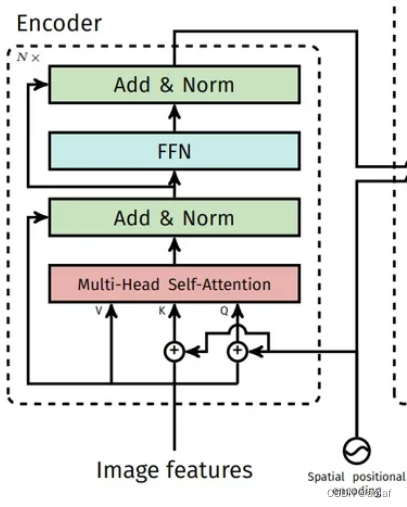
1.1.2 Encoder层
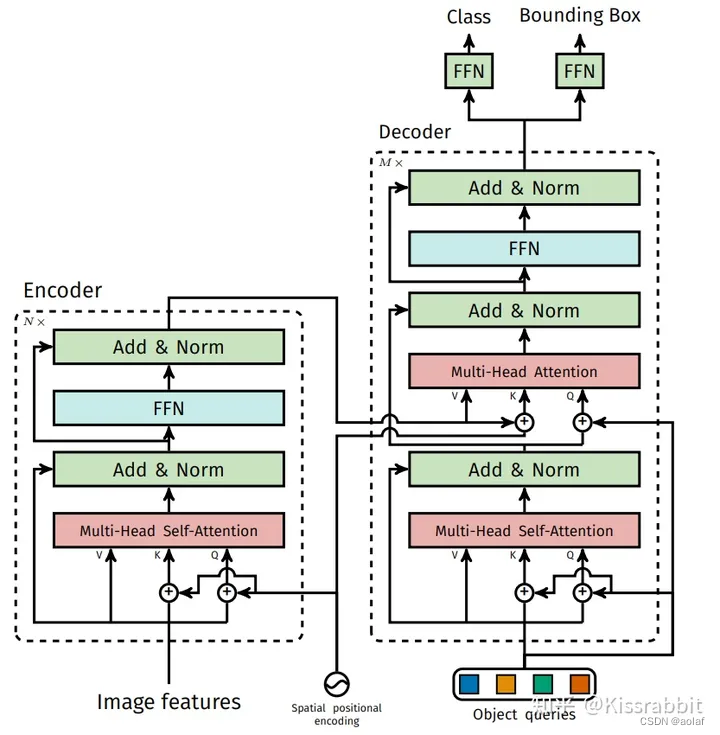
DETR中,只将Q、K和位置编码进行相加,然后进入Transformer中的Encoder层。共有N层Encoder,其中一层的具体步骤如图所示:
其中:Add主要类似于ResNet中的跳层链接,用于防止加深网络时的梯度消失,同时可以保留原始的输入序列信号,有助于Transformer对原始序列的学习。
Norm则是进行LayerNorm操作。
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
# Q、K和位置编码相加,q、k = src + pos src: [h*w, b, 256], pos:[h*w, b, 256]
q = k = self.with_pos_embed(src, pos)
# 使用mutil-head attention src2: [h*w, b, 256]
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0]
# src: [h*w, b, 256], src = x + H, 其中x为原始输入,H为Multi-head Attention的输出
src = src + self.dropout1(src2)
# LayerNorm 归一化
src = self.norm1(src)
# FFN
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
# Add
src = src + self.dropout2(src2)
# LayerNorm 归一化
src = self.norm2(src)
return src
1.1.3 Decoder层
DETR中共有M个Decoder模块,其中每一层decoder里是包含两个Attention模块的:
①. self-attention:
输入为DETR定义的Object queries可学习向量,维度为[B, N, 256], 初始化为0,其中N表示一张图片需要输出的预测结果数量,默认为100,即一张图像最多会被检测出100个物体,如果没有这么多物体,比如只检测出了20个,那么剩余的80个位置就是背景。
②. cross-attention:
第二个attention输入中的Q来自于Decoder中的第一个self-attention:
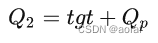
第二个attention输入中的K、V来自于Encoder最后输出的结果,其中K需要加上位置编码:
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
# q = k = tgt + Qp, tgt: [100, b, 256], pos:[100, b, 256]
q = k = self.with_pos_embed(tgt, query_pos)
# 求解MultiHeadAttention输出的结果, tgt2: [100, b, 256]
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask, key_padding_mask=tgt_key_padding_mask)[0]
# Add
tgt = tgt + self.dropout1(tgt2)
# layerNorm归一化
tgt = self.norm1(tgt)
# cross attention
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos), # Decoder上一个attention的输出+ Qp作为Decoder的第二个MultiHeadAttention中的Q
key=self.with_pos_embed(memory, pos), # Encoder的输出K + Encoder的位置编码作为Decoder的第二个MultiHeadAttention中的K
value=memory, attn_mask=memory_mask, # Encoder的输出V作为Decoder的第二个MultiHeadAttention中的V
key_padding_mask=memory_key_padding_mask)[0]
# Add
tgt = tgt + self.dropout2(tgt2)
# layerNorm归一化
tgt = self.norm2(tgt)
# FFN
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
# Add
tgt = tgt + self.dropout3(tgt2)
# layerNorm归一化
tgt = self.norm3(tgt)
return tgt
1.1.4 全连接输出类别预测分支与bbox预测分支
由于M层Decoder的输出维度为[M, B, 100, 256], 我们通常只采用最后一层结果进行预测,同时接上全连接层分别预测类别和bbox框。
类别预测outputs_class 的维度是[M, B, 100, 92], 92是由于coco中类别索引共91个,加上背景类
位置预测outputs_coord 的维度是[M, B, 100, 4],分别是bbox的中心点坐标和宽高,都是相对坐标,即值域在(0, 1)范围内,所以DeTR后面用了sigmoid来做一次映射。
outputs_class = self.class_embed(hs)
outputs_coord = self.bbox_embed(hs).sigmoid()
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
1.1.5 正负样本匹配
对于M个GT,在N个预测结果中找到最合适的M个预测结果与其一一对应,DeTR中,一个目标只有一个正样本,属于one-to-one匹配策略。
具体操作:
①. 计算N个预测结果和M个GT之间的类别cost和边界框cost
②. 根据cost值,利用匈牙利匹配给M个GT确定与其最匹配的M个预测框。
@torch.no_grad()
def forward(self, outputs, targets):
bs, num_queries = outputs["pred_logits"].shape[:2]
# We flatten to compute the cost matrices in a batch
out_prob = outputs["pred_logits"].flatten(0, 1).softmax(-1) # [batch_size * num_queries, num_classes]
out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4]
# Also concat the target labels and boxes
tgt_ids = torch.cat([v["labels"] for v in targets])
tgt_bbox = torch.cat([v["boxes"] for v in targets])
# Compute the classification cost. Contrary to the loss, we don't use the NLL,
# but approximate it in 1 - proba[target class].
# The 1 is a constant that doesn't change the matching, it can be ommitted.
cost_class = -out_prob[:, tgt_ids]
# Compute the L1 cost between boxes
cost_bbox = torch.cdist(out_bbox, tgt_bbox, p=1)
# Compute the giou cost betwen boxes
cost_giou = -generalized_box_iou(box_cxcywh_to_xyxy(out_bbox), box_cxcywh_to_xyxy(tgt_bbox))
# Final cost matrix
C = self.cost_bbox * cost_bbox + self.cost_class * cost_class + self.cost_giou * cost_giou
C = C.view(bs, num_queries, -1).cpu()
sizes = [len(v["boxes"]) for v in targets]
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(C.split(sizes, -1))]
return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
1.1.6 损失函数计算
其中类别损失采用交叉熵损失,回归损失采用giou + L1损失。
def loss_labels(self, outputs, targets, indices, num_boxes, log=True):
assert 'pred_logits' in outputs
# 类别预测结果 [b, 100, 92]
src_logits = outputs['pred_logits']
# 先获取样本的索引idx变量,去索引那些被匈牙利算法匹配上的预测框和目标框
idx = self._get_src_permutation_idx(indices)
# 正样本类别
target_classes_o = torch.cat([t["labels"][J] for t, (_, J) in zip(targets, indices)])
# 初始化为背景类91
target_classes = torch.full(src_logits.shape[:2], self.num_classes, dtype=torch.int64, device=src_logits.device)
# idx正样本处设置正样本类别
target_classes[idx] = target_classes_o
# 交叉熵损失
loss_ce = F.cross_entropy(src_logits.transpose(1, 2), target_classes, self.empty_weight)
losses = {'loss_ce': loss_ce}
if log:
# TODO this should probably be a separate loss, not hacked in this one here
losses['class_error'] = 100 - accuracy(src_logits[idx], target_classes_o)[0]
return losses
def loss_boxes(self, outputs, targets, indices, num_boxes):
assert 'pred_boxes' in outputs
# 先获取样本的索引idx变量,去索引那些被匈牙利算法匹配上的预测框和目标框
idx = self._get_src_permutation_idx(indices)
# bbox预测结果 [7, 4]
src_boxes = outputs['pred_boxes'][idx]
# bbox标签
target_boxes = torch.cat([t['boxes'][i] for t, (_, i) in zip(targets, indices)], dim=0)
# l1 损失
loss_bbox = F.l1_loss(src_boxes, target_boxes, reduction='none')
losses = {}
losses['loss_bbox'] = loss_bbox.sum() / num_boxes
# giou损失
loss_giou = 1 - torch.diag(box_ops.generalized_box_iou(box_ops.box_cxcywh_to_xyxy(src_boxes), box_ops.box_cxcywh_to_xyxy(target_boxes)))
losses['loss_giou'] = loss_giou.sum() / num_boxes
return losses