下个项目可能要用hive比较多
之前对分区、分桶搞不明白
趁着最近又学习了一下
ps:之前说的prophet在年底前一定会放上来的
hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据:可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;可以将SQL语句转换为MapReduce任务运行,通过自己的SQL查询分析需要的内容,这套SQL简称Hive SQL,使不熟悉mapreduce的用户可以很方便地利用SQL语言查询、汇总和分析数据。
简单来说,
是基于hadoop的一个数据仓库工具;
hive底层仍然是hadoop,hive仅仅相当于一个hadoop上层的应用组件。
ps:表和列名不区分大小写
文章目录
- 一、DDL语句(数据定义语句)
- 1.创建/删除数据库
- 2.建表语句
- 2.1 内表internal table(默认)
- 2.2 外表external table
- 2.3 内表和外表的区别
- 2.4 分区、分桶
- 3. 修改表alter
- 4. 加载/导出数据
- 二、DQL语句(数据查询语句)
- 1.基本查询
- 2.生成视图、索引
- 3.hive的排序相关查询
- 4.分组排序实现
- 5.从全量表数据获取增量数据
- 6.获取表的最新分区
- 参考链接
一、DDL语句(数据定义语句)
1.创建/删除数据库
创建库:
create database 库名;
create database if not exists 库名;
删除库:
drop database 库名;#只能删除空库,没有表
drop database if exists 库名;
drop database 库名 cascade;#可以删除非空库
--查看库的列表:
show databases;
--使用库:
use databases;
--查看正在使用的库:
select current_database();
--查看库信息:
desc database 库名;
2.建表语句
查询语句中创建表并加载数据
create table score2 as select * from score1;
create external table score6 (s_id string,c_id string,s_score int) row format delimited fields terminated by ',' location '/myscore'; # 在创建表时通过location指定加载数据的路径
2.1 内表internal table(默认)
建表
CREATE TABLE guruhive_internaltable (id INT,Name STRING) Row format delimited Fields terminated by '\t';
加载数据
LOAD DATA INPATH '/user/guru99hive/data.txt' INTO table guruhive_internaltable;
删表
DROP TABLE guruhive_internaltable;
2.2 外表external table
建表
CREATE EXTERNAL TABLE guruhive_external(id INT,Name STRING)
Row format delimited Fields terminated by '\t' LOCATION '/user/guru99hive/guruhive_external;
加载数据
LOAD DATA INPATH '/user/guru99hive/data.txt' INTO TABLE guruhive_external;
删表
DROP TABLE guruhive_external;
2.3 内表和外表的区别
(https://www.geeksforgeeks.org/difference-between-hive-internal-and-external-tables/)
内表:
内表可以使用truncate table;
hive会把数据加载到数据库对应的warehouse下面;
删表之后,元数据和表的数据都被删了
外表:
不把数据放到warehouse下面;
不支持truncate table;
drop的时候,仅删除元数据(我的理解是,外表类似于一个视图的功能,给a数据建了一个映射表a,还可以建表a1,a2,把表a删了不影响a数据,也不影响a1,a2)
什么时候使用内表?什么时候使用外表?

2.4 分区、分桶
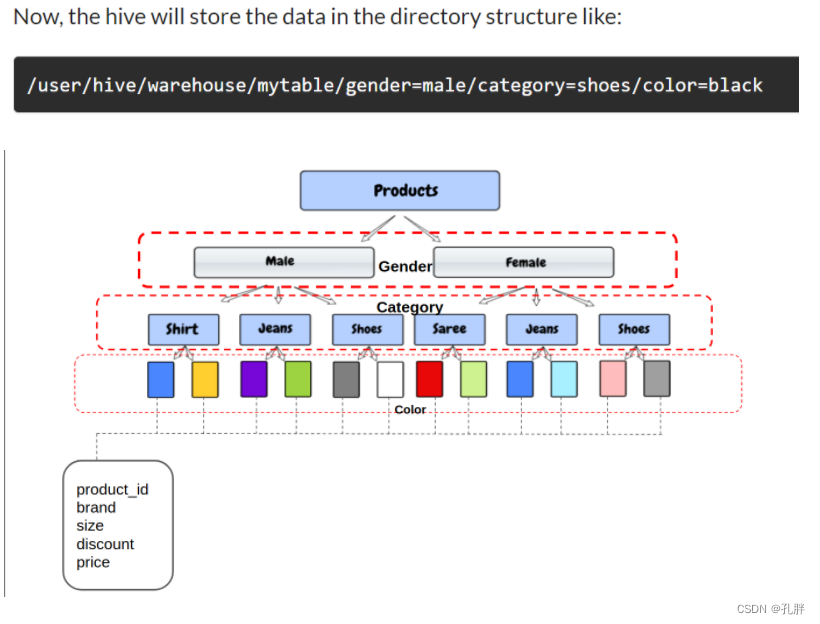
分区、分桶都是HDFS系统上处理大量数据时,用来减少在整张表上扫描,提升搜索速度的方法。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KrDpwy9v-1668075157215)(en-resource://database/70923:1)]
([https://sparkbyexamples.com/apache-hive/hive-partitioning-vs-bucketing-with-examples/](https://sparkbyexamples.com/apache-hive/hive-partitioning-vs-bucketing-with-examples/))](https://img-blog.csdnimg.cn/8d29ca65998c45e9b9c09b3766083c0b.png)
主要的不同是他们分割数据的方法
hive分区的话,我们会在数据的存放目录下,根据划分的数据生成不同的子目录。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JE5POyb6-1668075157219)(en-resource://database/70925:1)]
分区的语法:
CREATE TABLE products ( product_id string,
brand string,
size string,
discount float,
price float )
PARTITIONED BY (gender string,
category string,
color string);
对于分区表,要注意设置
set hive.exec.dynamic.partition.mode=nonstrict
然后再插入数据。
可以查看分区情况看
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Gdc4VyXm-1668075157221)(en-resource://database/70927:1)]](https://img-blog.csdnimg.cn/05043d13090544269c07243512f78675.png)
分桶表:
分桶表,是将一个完整的数据集分成若干部分。它存在的意义是:一是提高 join 查询的效率;二是利于抽样。
分桶表的实质,就是对分桶的字段做了hash 然后存放到对应文件中,也就是说向分桶表中插入数据的时候必然要执行一次MAPREDUCE,所以分桶表的数据只能通过从结果集查询插入的方式进行导入。(https://mp.weixin.qq.com/s/UR3acOscdh3NLw88tlH7rA)
另一种技巧来分解数据集,来更容易管理。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gFpjllfL-1668075157222)(en-resource://database/70929:1)]](https://img-blog.csdnimg.cn/7e1f83eace354b0fb981032130c60e28.png)
如果使用employee_id,那么会有太多分区了,如果用这个字段来分桶,那么可以确定有几桶,相同的employee_id会被分入同一个桶内。

在hive中,我们要使用分桶,需要设置set.hive.enforce.bucketing=true
分桶的语法
参考前面分区,无法对prices这样的连续数值进行分区,会产生无限个目录。可以对其进行分桶。
CREATE TABLE products ( product_id string,
brand string,
size string,
discount float,
price float )
PARTITIONED BY (gender string,
category string,
color string)
CLUSTERED BY (price) INTO 50 BUCKETS;
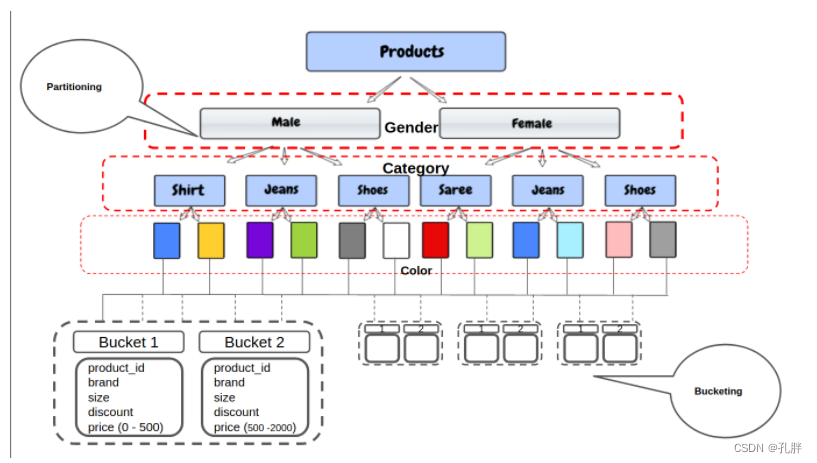
(非常好的一张图)
Now, only 50 buckets will be created no matter how many unique values are there in the price column. For example, in the first bucket, all the products with a price [ 0 – 500 ] will go, and in the next bucket products with a price [ 500 – 200 ] and so on.
什么时候进行分区?
当某个字段经常被查询且该字段类别不是很多的时候
不要对类别很多的字段建立分区,如每个id都建一个分区
分区内数据量不是很大的时候,建立分区效果会比较好
什么时候进行分桶?
字段类别很多,不适宜对其进行分区的时候
需要进行很多join操作的时候,建议考虑分桶
3. 修改表alter
- 修改表名称
alter table old_table_name rename to new_table_name;
- 增加、修改列信息
--查询表结构
desc score5;
--添加列
alter table score5 add columns (mycol string, mysco string);
--更新列
alter table score5 change column mysco mysconew int;
- 添加分区
--添加一个分区
alter table score add partition(month='201805');
--同时添加多个分区
alter table score add partition(month='201804') partition(month = '201803');
4. 加载/导出数据
加载
insert方式插入
insert into my_table values(1,'fayson1'); #单条插入
insert into my_table values(2,'fayson2'),(3,'fayson3'); #多条插入
insert方式追加插入查询结果
INSERT INTO my_table
SELECT id,name from test_user WHERE id > 3 and id < 5;
insert into table score partition(month ='201807') values ('001','002','100'); # 直接向分区里插
insert方式覆盖插入查询结果
INSERT OVERWRITE TABLE my_table
SELECT id,name from test_user WHERE id > 3 and id < 5;
insert overwrite table score2 partition(month = '201806') select s_id,c_id,s_score from score1;
插入到多张表
FROM test_user
INSERT INTO my_table select id, name where id > 4 and id < 6
INSERT INTO my_table1 select id, age
where id > 4 and id < 6;
load本地数据文件
追加
LOAD DATA LOCAL INPATH '/data/a.txt' INTO TABLE my_table;
load data local inpath '/export/servers/hivedatas/score.csv' into table score partition (month='201806'); # 直接向分区里插
load data local inpath '/export/servers/hivedatas/score.csv' into table score2 partition(year='2018',month='06',day='01'); # 直接向多分区的表里插
覆盖
LOAD DATA LOCAL INPATH '/data/a.txt' OVERWRITE INTO TABLE my_table;
load data local inpath '/export/servers/hivedatas/score.csv' overwrite into table score partition(month='201806'); # 直接向分区里插
Load HDFS数据文件
- 将文件put到HDFS的/data目录下
- 修改/data目录为hive用户
sudo -u hdfs hadoop fs -chown -R hive:hive /data
追加
LOAD DATA INPATH '/data/a.txt' INTO TABLE my_table;
覆盖
LOAD DATA INPATH '/data/a.txt' OVERWRITE INTO TABLE my_table;
导出
导出数据
--insert导出
--将查询的结果导出到本地
insert overwrite local directory '/export/servers/exporthive' select * from score;
--将查询的结果格式化导出到本地
insert overwrite local directory '/export/servers/exporthive' row format delimited fields terminated by '\t' collection items terminated by '#' select * from student;
--将查询的结果导出到HDFS上(没有local)
insert overwrite directory '/export/servers/exporthive' row format delimited fields terminated by '\t' collection items terminated by '#' select * from score;
--Hadoop命令导出到本地
dfs -get /export/servers/exporthive/000000_0 /export/servers/exporthive/local.txt;
--hive shell 命令导出
基本语法:(hive -f/-e 执行语句或者脚本 > file)
hive -e "select * from myhive.score;" > /export/servers/exporthive/score.txt
hive -f export.sh > /export/servers/exporthive/score.txt
--export导出到HDFS上
export table score to '/export/exporthive/score';
内表操作,export导出与import导入
create table techer2 like techer; --依据已有表结构创建表
export table techer to '/export/techer';
import table techer2 from '/export/techer';
二、DQL语句(数据查询语句)
1.基本查询
--1、查看表的创建信息:
show create table db.table1;
--查询表结构
desc score5;
--列出表的列和列的类型
DESCRIBE EXTENDED page_view;
--2、查看表的分区信息:
show partitions db.table1;
--查看是内表还是外表
desc formatted tablename; --得到Table Type ,也可以得到表的location。 根据Table Type值可以知道表是内部表(MANAGED_TABLE)还是外部表(EXTERNAL_TABLE)。内部表的存储位置是hive.metastore.warehouse.dir(默认是:/user/hive/warehouse)
--3、查看表的记录数:
select count(*) from db.table1 where dt = '2019-03-21';
--4、简单连接操作:
select t1.userid, t1.name, t2.score from
(select userid, name from db.table1 where dt = '2019-03-21' ) t1
left join
(select userid, score from db.table2 where dt='2019-03-21') t2
on t1.userid=t2.userid;
--5、给字段起别名:
select userid as user_id from db.table1 where dt = '2019-03-19' ;
--6、求两个表的差集,出在表A中,但不能出现表B中,即 A-B:
select a.user_id from
(select user_id from db.table1) a
left outer join
(select user_id from db.table2) b
on a.user_id = b.user_id
where b.user_id is null ;
--7、条件查找 -- 模糊匹配 单一条件
例如 字段 text 查询包含 'BeiJing' 的列
where text like concat('%','BeiJing','%')
where text like '%BeiJing%' -- 有待测试
--8、条件查找 -- 模糊匹配 多条件 查询
例如 字段 text 查询包含 'BeiJing' 'ShangHai' 的列
where text regexp 'BeiJing|ShangHai'
--9.去重后统计行数
select count(*) from (select distinct id from ab.table where dt='2020-05-26') a
2.生成视图、索引
视图和表类似,不占用物理空间,只保留结构,我理解的是在表上做一定筛选存为视图,方便在筛选上做查询。
Create VIEW Sample_ViewAS SELECT * FROM employees WHERE salary>25000
create view if not exists view_name
as
select a1,a2,a3 from table_name;
--删除视图
drop view if exists view_name;
创建索引
--语法
Create INDEX <INDEX_NAME> ON TABLE < TABLE_NAME(column names)>
--eg
Create INDEX sample_Index ON TABLE guruhive_internaltable(id)
3.hive的排序相关查询
基本的排序操作
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qV0s2lIv-1668075157233)(en-resource://database/70945:1)]](https://img-blog.csdnimg.cn/1334f08e42584048b128a51fc89524c6.png)
注意: 关键字 asc 和 desc 表示升序和降序,其中 cluster by 指定的列只能降序
使用示例:
-- 1、 对单个字段,降序排序(如果是多个字段,就继续在后面追加即可)
-- 按照年龄降序排序, sort by 使用方法与order by 一样。
select user_id, age from db.table order by age desc;
--2、 先按照班级class分组,在按照得分score、年龄age 升序排列
select class, age, score from db.table distribute by class sort by age asc, score asc;
--3、 先按照班级class分组,在按照年龄age 排列
select class, age from db.table cluster by class sort by age;
注意:
1、order by 会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
2、sort by不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1,则sort by只保证每个reducer的输出有序,不保证全局有序。
3、distribute by(字段)根据指定的字段将数据分到不同的reducer,且分发算法是hash散列。
4、Cluster by(字段) 除了具有Distribute by的功能外,还会对该字段进行排序。
因此,如果分桶和sort字段是同一个时,此时,cluster by = distribute by + sort by
完整查询
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY| ORDER BY col_list]
]
[LIMIT number]
注意:
如果使用 group by 分组,则 select 后面只能写分组的字段或者聚合函数
where和having区别:
1 having是在 group by 分完组之后再对数据进行筛选,所以having 要筛选的字段只能是分组字段或者聚合函数
2 where 是从数据表中的字段直接进行的筛选的,所以不能跟在gruop by后面,也不能使用聚合函数
4.分组排序实现
一般有两种实现方式:
(1)row_number() over( partition by 分组字段 order by 排序字段) as rank(rank 可随起名,表示排序后标识)
(2)row_number() over( distribute by 分组字段 sort by 排序字段) as rank(rank 可随起名,表示排序后标识)
-- 注意:
--1、 partition by 只与 order by 组合使用
--2、 distribute by 只与 sort by 组合使用
--3、 rank,可以随便起的名字,表示排序后的序号,例如,1,2,3,4,5...
--4、 分组字段、排序字段,均可为多个字段。
--5、 分组字段设置为常量,例如为1,这时,仅可以获取按照排列字段,排序后的--序号。
--使用示例:
--1、选取每个班级成绩前三名的同学:
select class, student, score from (
select class, student, score, row_number() over (distribute by class sort by score desc) as rank from db.table1
)as t1
where t1.rank < 4;
--2、distribute by,后面可以跟常数,例如1,这样只是获取按照某一列排序后的标识:
select class, student, score, row_number() over (distribute by 1 sort by score desc) as rank from db.table1;
参考链接:1基本排序、2分组排序
5.从全量表数据获取增量数据
select a.id from
(select distinct id from db.table1 where dt='2020-05-27') a
left outer join
(select distinct id from db.table1 where dt='2020-05-26') b
on a.id=b.id
where b.id is null
抽样
我们从表pv_gender_sum表中的32个桶中,选择第3个桶。
INSERT OVERWRITE TABLE pv_gender_sum_sample
SELECT pv_gender_sum.*
FROM pv_gender_sum TABLESAMPLE(BUCKET 3 OUT OF 32);
6.获取表的最新分区
partition="show partitions db.table1;"
latest_info=$(hive -e "$partition" | sort | tail -n 1)
latest_dt=${latest_info:3:13}
echo $latest_dt
查看表的分区
select PART_NAME FROM PARTITIONS WHERE TBL_ID=(SELECT TBL_ID FROM TBLS WHERE TBL_NAME='<table_name>');
参考链接
https://baike.baidu.com/item/hive/67986?fr=aladdin
hive教程:https://www.guru99.com/hive-tutorials.html !!!
https://www.geeksforgeeks.org/difference-between-hive-internal-and-external-tables/ 内表和外表的区别
分区、分桶的区别:
https://www.analyticsvidhya.com/blog/2020/11/data-engineering-for-beginners-partitioning-vs-bucketing-in-apache-hive/#h2_8
https://mp.weixin.qq.com/s/UR3acOscdh3NLw88tlH7rA
https://stackoverflow.com/questions/19128940/what-is-the-difference-between-partitioning-and-bucketing-a-table-in-hive
https://mp.weixin.qq.com/s/Xz31A1rje7vYwGcYzHXfcw 很长的hive总结
hive官方教程的翻译:https://blog.csdn.net/strongyoung88/article/details/53743937



![[SQL]视图和权限](https://img-blog.csdnimg.cn/img_convert/bfa5518295ad897fb4101c63b64d802c.png)