一、LinkedHashMap与HashMap的结构区别
HashMap
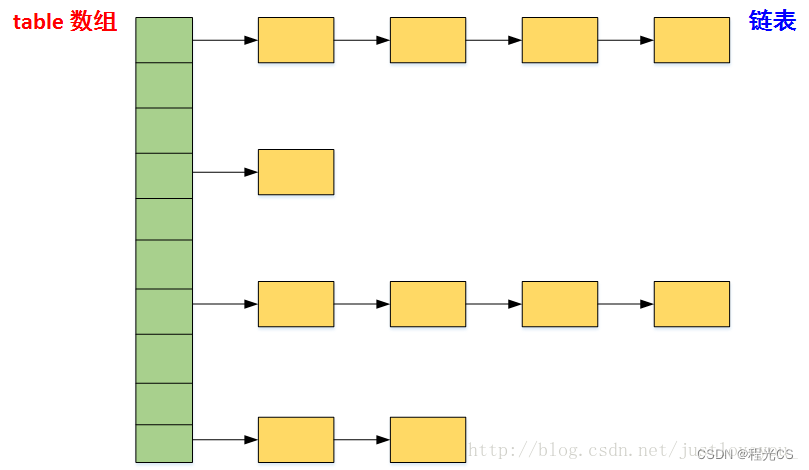
LinkedHashMap
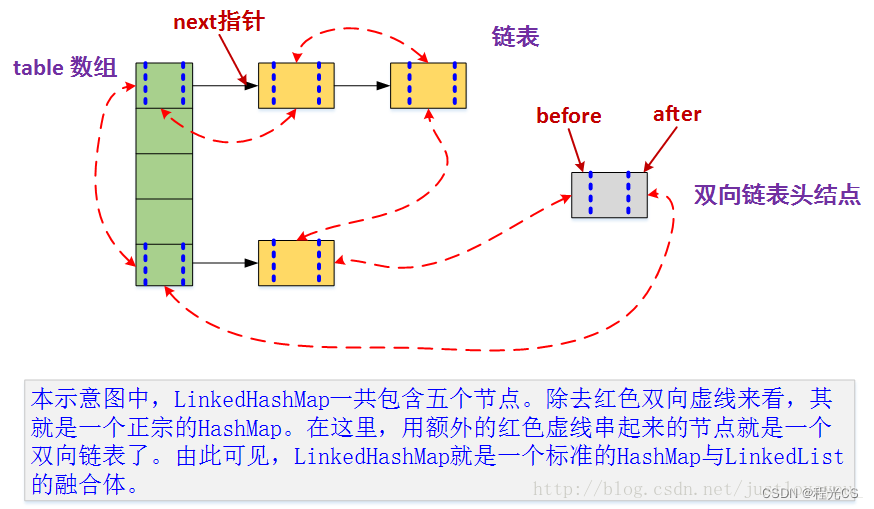
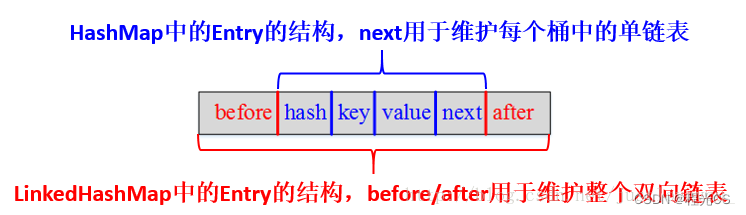
结构区别:LinkedHashMap的元素Entry中多两个用于维护双向链表的指针before、after,并且在LinkedHashMap中有两个head、tail指针用于记录双向链表的头结点和尾结点。
二、LinkedHashMap顺序迭代原理
LinkedHashMap可保证通过keySet()、entrySet()、forEach()等方法获取的元素具有顺序性,顺序分为两种:
- 添加顺序:获取元素的顺序与其被添加的顺序一致。
- 访问顺序:按元素被访问的时间进行排序,越近被访问的排在越后面,put和get等方法都表示访问。
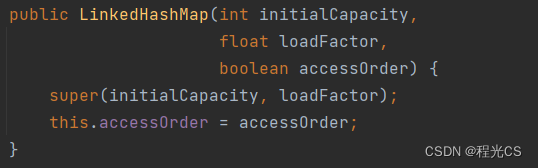
在LinkedHashMap通过成员变量accessOrder来决定按哪种顺序排序,默认为false添加顺序,只有通过下面这个构造方法在创建LinkedHashMap时将accessOrder设置为true,才表示访问顺序。
1. 添加顺序实现原理
添加顺序实现很简单,就是在按照HashMap规则添加元素后,还会执行一个方法将其添加到双向链表的尾部,然后更新尾结点tail。因此迭代时从双向链表head迭代到tail即为访问顺序。
2. 访问顺序实现原理
put添加元素后依然会将其添加到双向链表的尾部,表示是最近被访问到的。但是如果accessOrder为true,那么在下面这些访问方法中都会调用afterNodeAccess()将被访问元素移动到双向链表的尾部。因此在双向链表中就实现了元素的访问顺序。
三、LinkedHashMap实现LRU算法
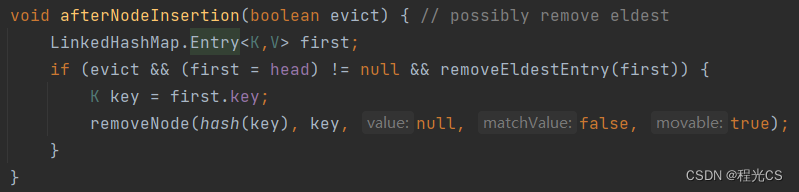
在LinkedHashMap中还有一个钩子方法removeEldestEntry(),在插入元素后调用的afterNodeInsertion()方法中会调用这个方法,如果它返回true那么就会移除Map中最老的元素即head,在添加顺序中head就是最早添加的元素,在访问顺序中head就是最长时间没被访问的元素。
因此我们可以重写钩子方法removeEldestEntry(),来利用LinkedHashMap实现LRU算法(LeetCode链接):
public class LRUCache {
private final LinkedHashMap<Integer, Integer> map;
private final int capacity;
public LRUCache(int capacity) {
this.capacity = capacity;
//1、选用可设置accessOrder的构造函数
//2、重写removeEldestEntry()方法,在插入元素后若size大于容量,则返回true,移除最长时间没被访问的元素
map = new LinkedHashMap<Integer, Integer>(capacity+1, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > capacity;
}
};
}
public int get(int key) {
try {
return map.get(key);
} catch (Exception e) {
return -1;
}
}
public void put(int key, int value) {
map.put(key, value);
}
}