前言:
前面讲了Overfitted,这里重点讲解一下如何防止
Overfitting ,以及其中的方案之一 Regularization
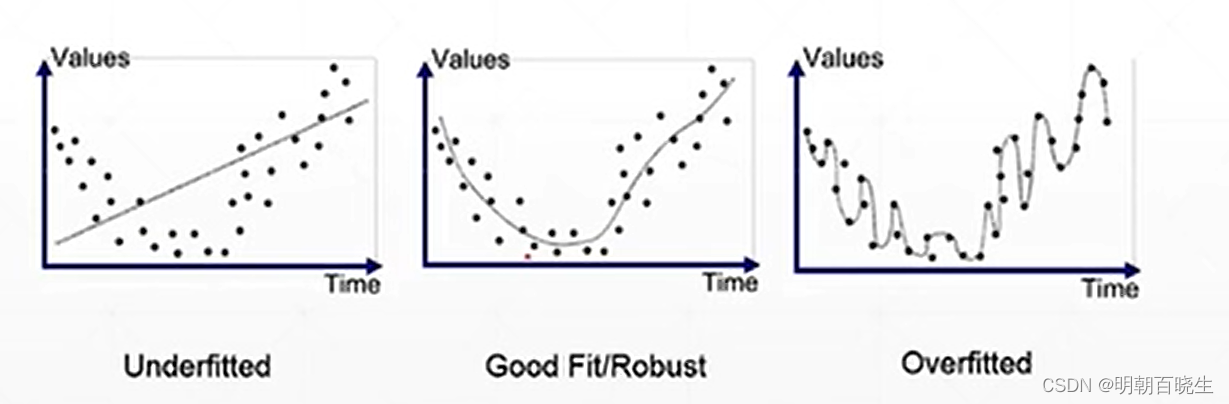
模型的参数量,模型的表达能力远超模型本身复杂度.
与之对应的是奥卡姆剃刀原理:
如何用最简单的方法得到最好的效果
找到关键的部分,简单灵活地去处理,你会发现,成功并不那么复杂。
目录:
1 more data
2: constraint model complexity
3 Dropout
4 data argumentation
5 Early Stopping
6 Regularization
一: More data
增加Train Data 数据集大小
有的时候,我们项目中没有办法获得那么大的数据集,
这个时候可以通过Gain 或者编码器 合成数据集,达到增加数据集容量
二 constraint model complexity(限制模型复杂度)
2.1 shallow:
单隐藏层神经网络就是典型的浅层(shallow)神经网络,即只包含一层隐含层
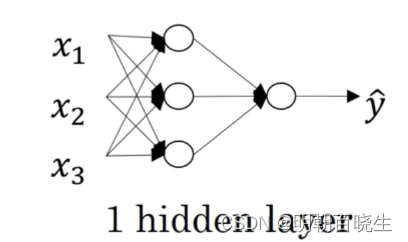
2.2 regularization
正规化 分为L1 正规化,和L2 正规化
在机器学习里面是一种最常用的方案
三 Dropout
dropout(随机失活):dropout是通过遍历神经网络每一层的节点,然后通过对该层的神经网络设置一个keep_prob(节点保留概率),即该层的节点有keep_prob的概率被保留,keep_prob的取值范围在0到1之间。通过设置神经网络该层节点的保留概率,使得神经网络不会去偏向于某一个节点(因为该节点有可能被删除),从而使得每一个节点的权重不会过大,有点类似于L2正则化,来减轻神经网络的过拟合。
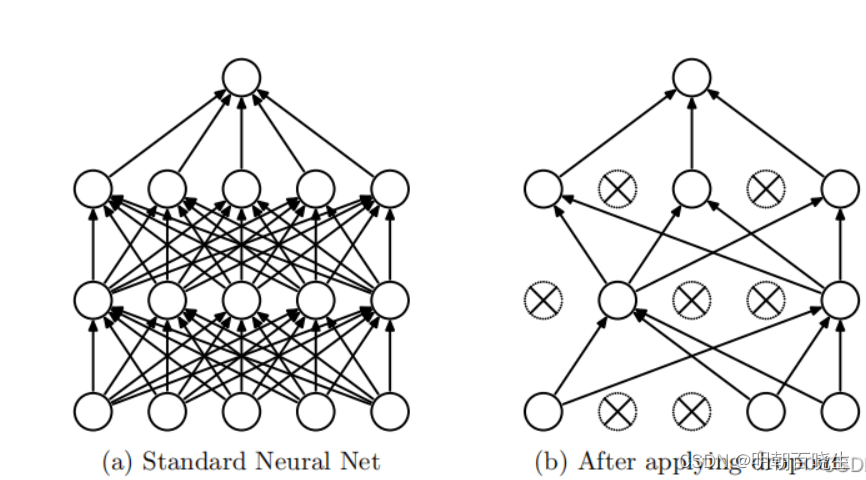
1 首先随机(临时)删掉网络中一半的隐藏神经元(以dropout rate为0.5为例),输入输出神经元保持不变
2 然后把输入x 通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一 小批(这里的批次batch_size由自己设定)训练样本执行完这个过程后,在没有被删除的神经元(
)上按照随机梯度下降法更新对应的参数(w,b)
重复以下过程:
sub-1、恢复被删掉的神经元()(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新),因此每一个mini- batch都在训练不同的网络。
sub-2、从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。
sub-3、对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新
四 data argumentation
数据增强,这在图像处理里面常用
| 随机旋转一般情况下是对输入图像随机旋转[0,360) |
| 随机裁剪是对输入图像随机切割掉一部分 |
| 色彩抖动指的是在颜色空间如RGB中,每个通道随机抖动一定的程度。 |
| 是指在图像中随机加入少量的噪声。该方法对防止过拟合比较有效 |
| 水平翻转 |
| 竖直翻转 |
五 Early Stopping
使用Validation Data 做一个提前终止
六 Regularization
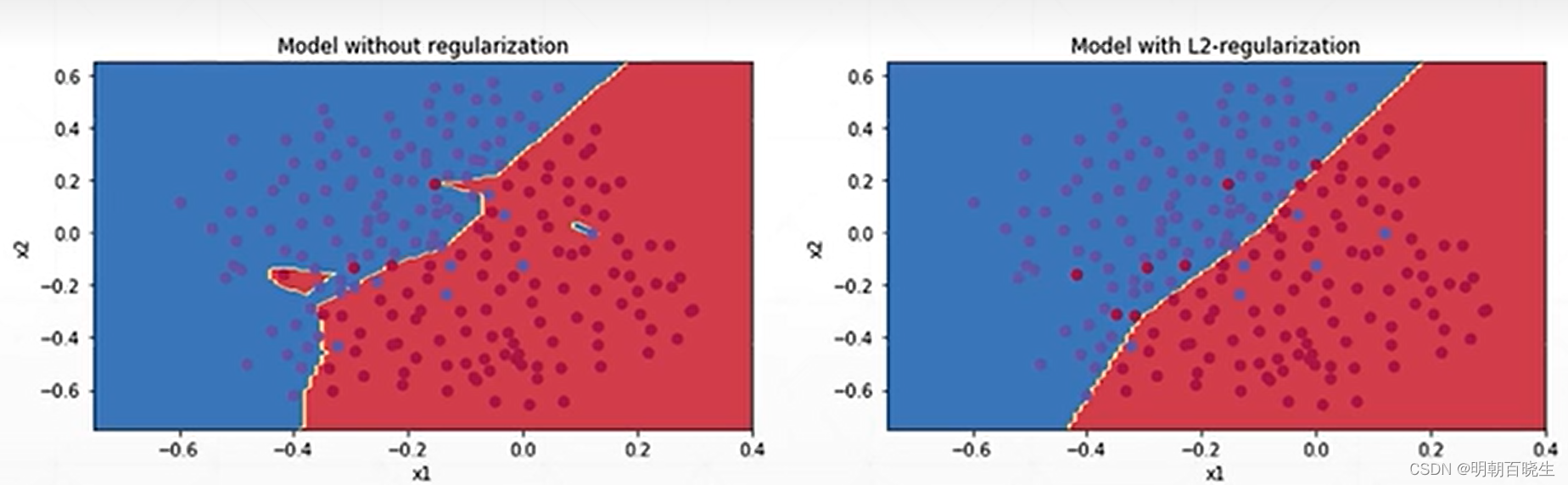
正规化有两种,一种是L1 正规化(有降维的效果)
另一种是L2正规化

对于L2 正规化有默认的参数可以直接配置
# -*- coding: utf-8 -*-
"""
Created on Wed Apr 26 16:56:05 2023
@author: chengxf2
"""
import torch
from torch import optim
from torch import nn
# 先定义一个三层感知机,激活函数使用Relu(小于0的,都转换为0)
class MLP(nn.Module):
def __init__(self, in_dim, hid_dim1, hid_dim2, out_dim):
super(MLP, self).__init__()
#使用Sequential快速搭建三层感知机
self.layer = nn.Sequential(
# 第一层
nn.Linear(in_dim, hid_dim1),
nn.ReLU(),
nn.Linear(hid_dim1, hid_dim2),
nn.ReLU(),
nn.Linear(hid_dim2, out_dim),
nn.ReLU()
)
def forward(self, x):
y = self.layer(x)
return y
def train():
print("\n step1 init model")
learning_rate =1e-3
net =MLP(28*28, 300, 200, 10)
optimizer = optim.SGD(net.parameters(),lr =learning_rate, weight_decay=0.01) #L2正规化
criteon = nn.CrossEntropyLoss()
print("\n step2 forward")
data = torch.randn(10, 28*28)
output = net(data)
label = torch.Tensor([1, 0, 4, 7, 9, 3, 4, 5, 3, 2]).long()
print("\n step3 backward")
loss = criteon(output, label)
# 清空梯度,在每次优化前都要进行此操作
optimizer.zero_grad()
# 损失的反向传播
loss.backward()
# 利用优化器进行梯度更新
optimizer.step()
if __name__ == "__main__":
train()
针对L1 正规化,PyTorch 需要自己实现,方案如下
# -*- coding: utf-8 -*-
"""
Created on Thu Apr 27 15:23:56 2023
@author: chengxf2
"""
import torch
from torch import optim
from torch import nn
# 先定义一个三层感知机,激活函数使用Relu(小于0的,都转换为0)
class MLP(nn.Module):
def __init__(self, in_dim, hid_dim1, hid_dim2, out_dim):
super(MLP, self).__init__()
#使用Sequential快速搭建三层感知机
self.layer = nn.Sequential(
# 第一层
nn.Linear(in_dim, hid_dim1),
nn.ReLU(),
nn.Linear(hid_dim1, hid_dim2),
nn.ReLU(),
nn.Linear(hid_dim2, out_dim),
nn.ReLU()
)
def forward(self, x):
y = self.layer(x)
return y
net =MLP(100, 50, 25, 10)
optimizer = optim.SGD(net.parameters(),lr=1e-3)
regularization_loss = 0.0
criteon = nn.CrossEntropyLoss()
for param in net.parameters():
L1= torch.abs(param)
regularization_loss +=L1
data = torch.randn(10, 28*28)
logits = net(data)
target = torch.Tensor([1, 0, 4, 7, 9, 3, 4, 5, 3, 2]).long()
classify_loss = criteon(logits, target)
loss = classify_loss+0.01*regularization_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
参考
Dropout的深入理解(基础介绍、模型描述、原理深入、代码实现以及变种)_dropout模型_ㄣ知冷煖★的博客-CSDN博客
数据增强(Data Argumentation)_左小田^O^的博客-CSDN博客