1 正则表达式是什么
正则表达式(Regular Expression)其实就是一门工具,目的是为了字符串模式匹配,从而实现搜索和替换功能。它起源于上个20世纪50年代科学家在数学领域做的一些研究工作,后来才被引入到计算机领域中。从它的命名我们可以知道,它是一种用来描述规则的表达式。而它的底层原理也十分简单,就是使用状态机的思想进行模式匹配。https://regexper.com/
https://juejin.cn/post/6844903845227659271
2 正则表达式实践
2.1 test() exec() replace() match() 的简单用法
test() - 用来查看正则表达式与指定的字符串是否匹配。
const reg = /前端/
const res = reg.test('学前端,找zhaoshuai-lc');
console.log(res) // true
const regExpExecArray = reg.exec('学前端,找赵帅');
console.log(regExpExecArray)

replace() - 用来替换字符串中符合规则的字符。
let str = '学前端,找大哥'
let strNew = str.replace(reg, 'zhaoshuai-lc');
console.log(strNew) // 学zhaoshuai-lc,找大哥
// 全局替换 g
const _reg = /前端/g
let _str = '学前端,找大哥 学前端,找大哥 学前端,找大哥 学前端,找大哥 学前端,找大哥'
let _strNew = _str.replace(_reg, 'zhaoshuai-lc');
console.log(_strNew)
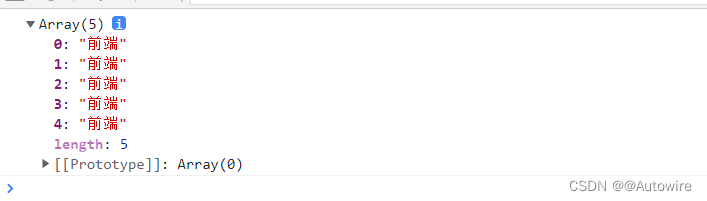
match() - 可在字符串内检索指定的值,或找到一个或多个正则表达式的匹配。
// const m_reg = /前端/
const m_reg = /前端/g
let strMatch = '学前端,找大哥 学前端,找大哥 学前端,找大哥 学前端,找大哥 学前端,找大哥'
let regExpMatchArray = strMatch.match(m_reg);
console.log(regExpMatchArray)
2.2 修饰符
修饰符约束正则执行的某些细节行为,如是否区分大小写、是否全局匹配。
- i 单词ignore的缩写,正则匹配时字母不区分大小写。
- g 单词global 的缩写,匹配所有满足正则表达式的结果。
// i 忽略大小写
const i_reg = /a/i
let i_res = i_reg.test('AAAddd'); //true
console.log(i_res)
// g 全局匹配
const g_reg = /java/ig
let g_str = '学JAVA,找大哥 学java,找大哥 学JAVA,找大哥 学java,找大哥 学java,找大哥'
let g_strNew = g_str.replace(g_reg, 'zhaoshuai-lc');
console.log(g_strNew) // 学zhaoshuai-lc,找大哥 学zhaoshuai-lc,找大哥 学zhaoshuai-lc,找大哥 学zhaoshuai-lc,找大哥 学zhaoshuai-lc,找大哥
2.3 元字符
一些具有特殊含义的字符,可以极大提高了灵活性和强大的匹配功能。
比如 : 匹配26个英文字母,用普通字符表示 abcde.….xyz,但是用元字符表示的话,只需要[a-z]
2.3.1 边界符
- 单词边界
找出某句话中的某个单词,例如: The cat scattered his food all over the room.
想找到cat这个单词,但是如果只是使用/cat/这个正则,就会同时匹配到cat和scattered这两处文本,这时候就可以用到单词边界\b。
// 单词边界
const reg = /cat/g
const str = 'The cat scattered his food all over the room.'
let res = str.replace(reg, 'dog');
console.log(res) // The dog sdogtered his food all over the room.
- 字符串边界
^ 表示匹配行首的文本
$ 表示匹配行尾的文本
注意:如果^和$在一起,表示必须是精确匹配
// 字符串边界 ^ $
const reg = /^a/
let strT = 'adafjk'
let resT = reg.test(strT);
console.log(resT) // true
let strF = 'dadafjk'
let resF = reg.test(strF);
console.log(resF) // false
const _reg = /a$/
let _strT = 'adafjka'
let _resT = reg.test(_strT);
console.log(_resT) // true
let _strF = 'dadafjk'
let _resF = reg.test(_strF);
console.log(_resF) // false
// ^ $ 在一个表示精确匹配 中间写什么就匹配什么
const reg_ = /^a$/
let str_ = 'a'
let res_ = reg_.test(str_);
console.log(res_) // true
const reg__ = /^a$/
let str__ = 'aaa'
let res__ = reg__.test(str__);
console.log(res__) // false
2.3.2 量词
- {x}: x次
- {min, max}: 介于min次到max次之间
- {min, }: 至少min次
- {0, max}: 至多max次

// * 0次 或者多次
const reg = /^a*$/
console.log(reg.test('a')) // true
console.log(reg.test('')) // true
console.log(reg.test('aaa')) // true
console.log(reg.test('b')) // false
// + 1次 或者多次
const _reg = /^a+$/
console.log(_reg.test('a')) // true
console.log(_reg.test('')) // false
console.log(_reg.test('aaa')) // true
console.log(_reg.test('b')) // false
// ? 0次 或者1次
const __reg = /^a?$/
console.log(__reg.test('a')) // true
console.log(__reg.test('')) // true
console.log(__reg.test('aaa')) // false
console.log(__reg.test('b')) // false
// {n} 只能有n次
const n_reg = /^a{3}$/
console.log(n_reg.test('a')) // false
console.log(n_reg.test('')) // false
console.log(n_reg.test('aaa')) // true
console.log(n_reg.test('b')) // false
// {n,} >= n 次
const n__reg = /^a{2,}$/
console.log(n__reg.test('a')) // false
console.log(n__reg.test('')) // false
console.log(n__reg.test('aaa')) // true
console.log(n__reg.test('aa')) // true
// {n,m} >= n 次 并且 <= m 次
const n_m_reg = /^a{2,3}$/
console.log(n_m_reg.test('a')) // false
console.log(n_m_reg.test('')) // false
console.log(n_m_reg.test('aaa')) // true
console.log(n_m_reg.test('aa')) // true
console.log(n_m_reg.test('aaaa')) // false
console.log(n_m_reg.test('aaaaa')) // false
2.3.3 字符类
- []匹配字符集合
// [abc] 匹配abc中的任意一个
let reg = /[abc]/
console.log(reg.test('abc')) // true
console.log(reg.test('andy')) // true
console.log(reg.test('body')) // true
console.log(reg.test('conde')) // true
console.log(reg.test('jlkjlkj')) // false
// 匹配a-z中的任意一个
let _reg = /[a-z]/
// let _reg = /[A-Z]/
// let _reg = /[0-9]/
// let _reg = /[a-zA-Z0-9_]/ 大小写数字下划线
// [^] 需要写到中括号 表示取反
let __reg = /[^0-9]/
console.log(__reg.test('aaa')) // true
console.log(__reg.test('1111')) // false
console.log(__reg.test('*ddoo')) // true
- .匹配除换行符之外的任意单个字符
如果本来这个字符不是特殊字符,使用转义符号就会让它拥有特殊的含义。我们常常需要匹配一些特殊字符,比如空格,制表符,回车,换行等, 而这些就需要我们使用转义字符来匹配。

// . 匹配除换行符之外的任何单个字符
let reg = /./
console.log(reg.test('')) // false
console.log(reg.test('1')) // true
console.log(reg.test('a')) // true
console.log(reg.test('aaa')) // true
console.log(reg.test('\r')) // false
console.log(reg.test('\na')) // true
console.log(reg.test('\n')) // false
2.3.4 预定义

2.4 分组
其中分组体现在:所有以()元字符所包含的正则表达式被分为一组,每一个分组都是一个子表达式,它也是构成高级正则表达式的基础。
// 分组 abc 匹配一次或者多次
let reg = /(abc)+/
console.log(reg.test('adcdd')) // false
console.log(reg.test('abcc')) // true
console.log(reg.test('abdabcc')) // true
2.5 分组捕获
// 分组捕获 例如将YYYY-MM-DD格式的日期替换成MM/DD/YYYY
let _reg = /^\d{4}-\d{2}-\d{2}$/
let date = '2022-03-22'
console.log(_reg.test(date)) // true
let __reg = /^(\d{4})-(\d{2})-(\d{2})$/
let _date = '2022-03-22'
let res = _date.replace(__reg, '$2/$3/$1');
console.log(res) // 03/22/2022
2.6 分支结构
// 分支结构
let str1 = '学JAVA找zhaoshuai-lc'
let str2 = '学PYTHON找zhaoshuai-lc'
let str3 = '学前端找zhaoshuai-lc'
let reg = /前端|JAVA/
console.log(reg.test(str1)) // true
console.log(reg.test(str2)) // false
console.log(reg.test(str3)) // true