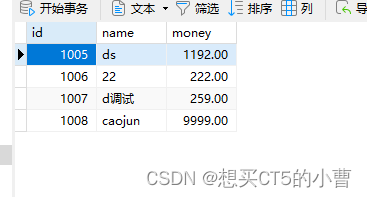
多处理器编程,本质上,就是把MR给每个处理器复制一份
每个处理器拿到MR,形成了自己的缓存内存空间,然后再在运行期间把运算结果写入共享内存

把i++做成一条指令
使用asm嵌入汇编,向sum的寄存器直接写入+1的值

把C语言转汇编
int main(){
int i = 0;
i++;
return 0;
}
Windows 在命令行使用 g++ sum_asm.c -S -fverbose-asm -o sum_asm.s
生成的结果如下
.text
.def __main; .scl 2; .type 32; .endef
.globl main
.def main; .scl 2; .type 32; .endef
.seh_proc main
main:
.LFB0:
pushq %rbp #
.seh_pushreg %rbp
movq %rsp, %rbp #,
.seh_setframe %rbp, 0
subq $48, %rsp #,
.seh_stackalloc 48
.seh_endprologue
# sum_asm.c:1: int main(){
call __main #
# sum_asm.c:2: int i = 0;
movl $0, -4(%rbp) #, i
# sum_asm.c:3: i++;
addl $1, -4(%rbp) #, i
# sum_asm.c:4: return 0;
movl $0, %eax #, _3
# sum_asm.c:5: }
addq $48, %rsp #,
popq %rbp #
ret
.seh_endproc
.ident "GCC: (x86_64-posix-seh-rev0, Built by MinGW-W64 project) 8.1.0"
从使用了rbp寄存器来判断,这是一个64位程序
CPU的μops(微操作)

基于data dependency做优化,两个修改相同寄存器(或读取等等有数据依赖关系)的指令CPU不能主动换顺序
- 根据data dependency,CPU会生成有向无环图(DAG)
- CPU就可以在一个时钟周期里取出多条指令,同时在处理器执行。

满足单处理器上 eventual memory consistency 的 内存一致性模型
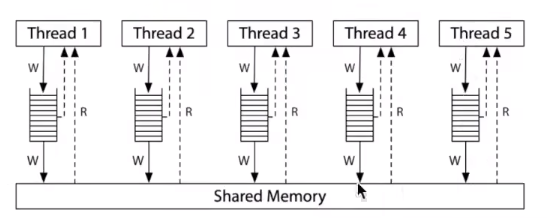
单核上遇到cache miss的时候,会把运行顺序修改,原本直接写入内存的操作,改为先写入cache,然后再等待任意长时钟周期再写入共享内存。
每个线程都有一个内存的副本(实际上就是MR),没有一致性可言
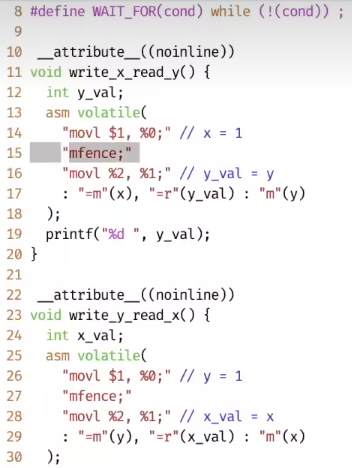
加入mfence 就可以保证当前线程缓存的内存写到共享内存以后,再处理下一条指令