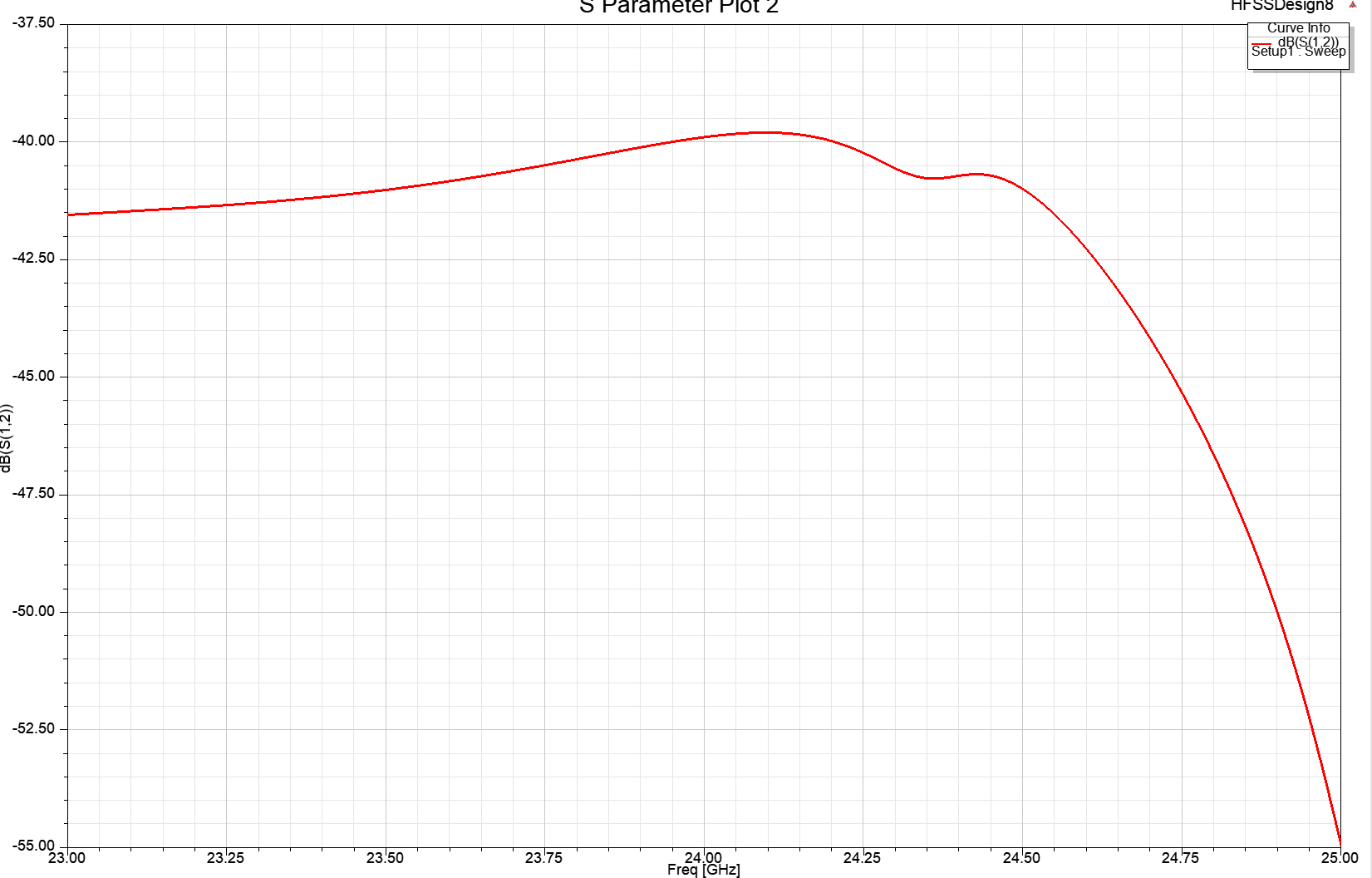
编写 YARA 规则 — yara 4.2.0 文档
YARA规则易于编写和理解,并且它们的语法是 类似于 C 语言。这是您可以编写的最简单的规则 YARA,它什么都不做:
rule dummy
{
condition:
false
}一、规则标识符
每个规则都以关键字“
rule”开头,后面跟着一个规则标识符。标识符必须遵循与C语言相同的词法约定,标识符命名有如下要求:
-
英文字母、数字、下划线组成的字符串
-
第一个字符不能是数字
-
对大小写敏感
-
不能超出128个字符长度
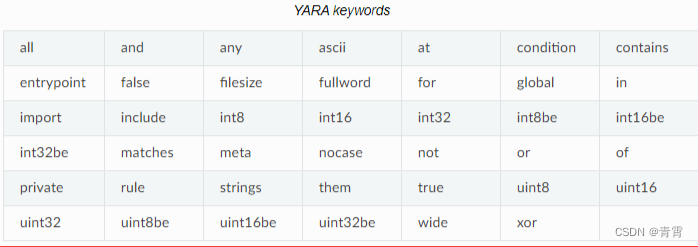
以下关键字是保留的,不能用作规则标识符:
二、注释
// 单行注释
/*
多行注释
*/
三、字符串
Yara中有三种类型的字符串:
3.1、十六进制字符串
定义原始字节序列
// 通配符?:可以代替某些未知字节,与任何内容匹配
rule WildcardExample
{
strings:
// 使用‘?’作为通配符
$hex_string = { 00 11 ?? 33 4? 55 }
condition:
$hex_string
}这个规则可以匹配下面的两个字符串:
00 11 01 33 43 55
00 11 AA 33 4N 55
// 跳转:可以匹配长度可变的字符串
rule JumpExample
{
strings:
// 使用‘[]’作为跳转,与任何长度为0-2字节的内容匹配
$hex_string1 = { 00 11 [2] 44 55 }
$hex_string2 = { 00 11 [0-2] 44 55 }
// 该写法与string1作用完全相同
$hex_string3 = { 00 11 ?? ?? 44 55 }
condition:
$hex_string1 and $hex_string2
}
这个规则可以匹配下面的两个字符串:
00 11 01 22 44 55
00 11 AA 44 55
// 匹配无限长的字符串
rule BuzzLightyear
{
strings:
$hex_string = { F4 23 [-] 62 B4 }
condition:
$hex_string
}
这个规则可以匹配下面的两个字符串:
F4 23 AA FF 62 B4
F4 23 AA AA AA AA AA...FF FF 62 B4
// 也可以使用类似于正则表达式的语法
rule AlternativesExample1
{
strings:
$hex_string = { 00 11 ( 22 | 33 44 ) 55 }
condition:
$hex_string
}
可以匹配以下内容:
00 11 22 55
00 11 33 44 55
// 还可以将上面介绍的方法整合在一起用
rule AlternativesExample2
{
strings:
$hex_string = { 00 11 ( 33 44 | 55 | 66 ?? 88 ) 99 }
condition:
$hex_string
}
这个规则可以匹配下面的三个字符串:
00 11 33 44 99
00 11 55 99
00 11 66 AG 88 99
3.2、文本字符串
定义可读文本的部分。
转义符:
\" 双引号
\\ 反斜杠
\t 制表符
\n 换行符
\xdd 十六进制的任何字节
修饰符:
nocase: 不区分大小写
wide: 匹配2字节的宽字符, 这种宽字符串在许多二进制文件中都有出现
ascii: 匹配1字节的ascii字符
xor: 匹配异或后的字符串
fullword: 匹配完整单词,用于匹配那些前后没有附加其他字符的单词
private: 定义私有字符串
rule CaseInsensitiveTextExample
{
strings:
// 不区分大小写
$text_string = "foobar" nocase
// 匹配宽字符串
$wide_string = "Borland" wide
// 同时匹配2种类型的字符串
$wide_and_ascii_string = "Borland" wide ascii
// 匹配所有可能的异或后字符串
$xor_string = "This program cannot" xor
// 匹配所有可能的异或后wide ascii字符串
$xor_string = "This program cannot" xor wide ascii
// 限定异或范围
$xor_string = "This program cannot" xor(0x01-0xff)
// 全词匹配(匹配:www.domain.com 匹配:www.my-domain.com 不匹配:www.mydomain.com)
$wide_string = "domain" fullword
// 私有字符串可以正常匹配规则,但是永远不会在输出中显示
$text_string = "foobar" private
condition:
$text_string
}3.3、正则表达式
定义可读文本的部分。
yara规则允许使用正则表达式, 不过要用正斜杠而非双引号括起来使用(像Perl编程那样)
rule RegularShow
{
strings:
$re1 = /md5: [0-9a-fA-F]{32}/
$re2 = /state: (on|off)/
condition:
$re1 and $re2
}
该规则将捕获任何状态下找到的所有md5字符串。
你也可以在正则表达式中使用文本修饰符, 如nocase,ascii,wide和fullword。
四、条件表达式
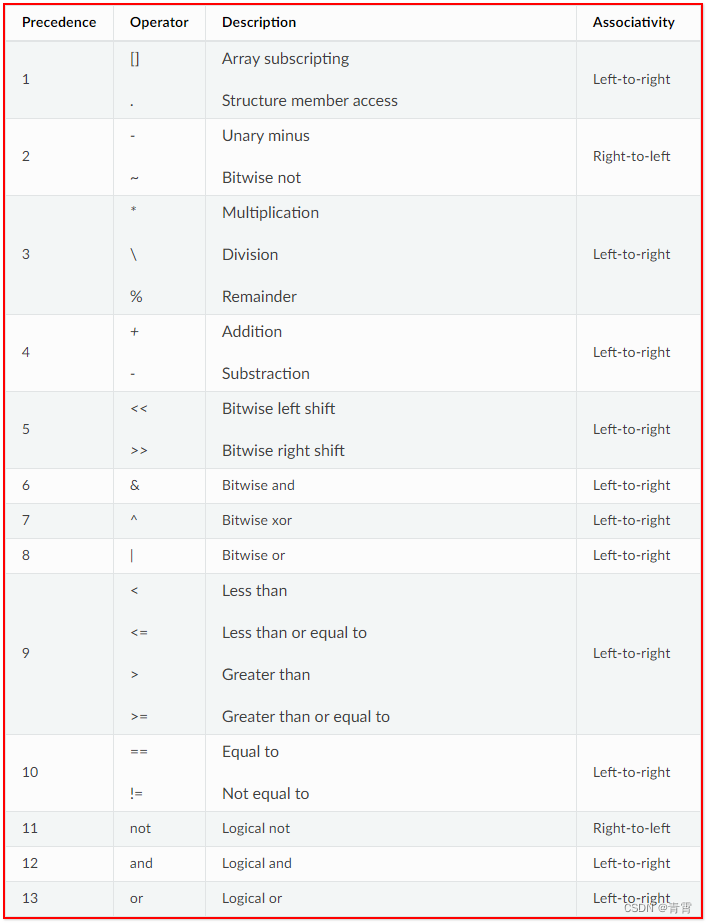
你可以在条件表达中使用如下运算符:
all any them
all of them // 匹配规则中的所有字符串
any of them // 匹配规则中的任意字符串
all of ($a*) // 匹配标识符以$a开头的所有字符串
any of ($a,$b,$c) // 匹配a, b,c中的任意一个字符串
1 of ($*) // 匹配规则中的任意一个字符串
#
// 匹配字符串在文件或内存中出现的次数
rule CountExample
{
strings:
$a = "dummy1"
$b = "dummy2"
condition:
//a字符串出现6次,b字符串大于10次
#a == 6 and #b > 10
}
@
//可以使用@a[i],获取字符串$a在文件或内存中,第i次出现的偏移或虚拟地址
//小标索引从1开始,并非0
//如果i大于字符串出现的次数,结果为NaN(not a number 非数值)
!
//可以使用!a[i],获取字符串$a在文件或内存中,第i次出现时的字符串长度
//下标索引同@一样都是从1开始
//!a 是 !a[1]的简写
at
// 匹配字符串在文件或内存中的偏移
rule AtExample
{
strings:
$a = "dummy1"
$b = "dummy2"
condition:
// a和b字符串出现在文件或内存的100和200偏移处
$a at 100 and $b at 200
}
in
// 在文件或内存的某个地址范围内匹配字符串
rule InExample
{
strings:
$a = "dummy1"
$b = "dummy2"
condition:
$a in (0..100) and $b in (100..filesize)
}
filesize
// 使用关键字匹配文件大小
rule FileSizeExample
{
condition:
// filesize只在文件时才有用,对进程无效
// KB MB后缀只能与十进制大小一起使用
filesize > 200KB
}
entrypoint
// 匹配PE或ELF文件入口点(高版本请使用PE模块的pe.entry_point代替)
rule EntryPointExample1
{
strings:
$a = { E8 00 00 00 00 }
condition:
$a at entrypoint
}
rule EntryPointExample2
{
strings:
$a = { 9C 50 66 A1 ?? ?? ?? 00 66 A9 ?? ?? 58 0F 85 }
condition:
$a in (entrypoint..entrypoint + 10)
}
of
// 匹配多个字符串中的某几个
rule OfExample1
{
strings:
$a = "dummy1"
$b = "dummy2"
$c = "dummy3"
condition:
// 3个字符串只需匹配任意2个
2 of ($a,$b,$c)
}
for xxx of xxx :(xxx)
功能:对多个字符串匹配相同的条件
格式:for AAA of BBB : ( CCC )
含义:
在BBB字符串集合中,至少有AAA个字符串,满足了CCC的条件表达式,才算匹配成功。
在CCC条件表达式中,可以使用'$'依次代替BBB字符串集合中的每一个字符串。
// for..of其实就是of的特别版,所以下面2个例子作用相同
any of ($a,$b,$c)
for any of ($a,$b,$c) : ( $ )
// 在abc这3个字符串集合中,至少有1个字符串,必须满足字符串内容与entrypoint相同的条件。$表示集合中的所有字符串. 本例中, 它是字符串$a, $b和$c.
for 1 of ($a,$b,$c) : ( $ at entrypoint )
for any of ($a,$b,$c) : ( $ at entrypoint )
// 所有字符串,在文件或内存中出现的次数必须大于3,才算匹配成功。
for all of them : ( # > 3 )
// 所有以$a开头的字符串,在文件或内存中第2次出现的位置必须小于9
for all of ($a*) : (@[2] < 0x9)
引用其它规则
rule Rule1
{
strings:
$a = "dummy1"
condition:
$a
}
rule Rule2
{
strings:
$a = "dummy2"
condition:
$a and Rule1
}
全局规则
// 全局规则(global rule)可以在匹配其他规则前优先筛选,
// 比如在匹配目标文件之前需要先筛选出小于2MB的文件,在匹配其他规则
global rule SizeLimit
{
condition:
filesize < 2MB
}
私有规则
//私有规则(private rule)可以避免规则匹配结果的混乱,
//比如使用私有规则进行匹配时,YARA不会输出任何匹配到的私有规则信息
//私有规则单独使用意义不大,一般可以配合"引用其它规则"的功能一起使用。比如为了判断文件是否恶意, 有这样一条私有规则, 要求文件必须是ELF文件. 一旦满足这个要求, 随后就会执行下一条规则. 但我们在输出里想看的并不是该文件它是不是ELF, 我们只想知道文件是否恶意, 那么私有规则就派上用场了.
//私有规则也可以和全局规则一起使用,只要添加“Private”、“global”关键字即可
private rule PrivateRuleExample
{
...
}
规则标签
// 规则标签,可以让你在YARA输出的时候只显示你感兴趣的规则,而过滤掉其它规则的输出信息(yara -t tagname)
// 你可以为规则添加多个标签
rule TagsExample1 : Foo Bar Baz
{
...
}
rule TagsExample2 : Bar
{
...
}
导入模块
// 使用“import”导入模块
// 你可以自己编写模块,也可以使用官方或其它第三方模块
// 导入模块后,就可以开始使用模块导出的变量或函数
import "pe"
import "cuckoo"
pe.entry_point == 0x1000
cuckoo.http_request(/someregexp/)
外部变量
// 外部变量允许你在使用YARA -d命令时指定一个自定义数据,
// 外部变量可以是int, str或boolean类型
// ext_var是一个外部变量, 它在运行时会分配有一个值
rule ExternalVariableExample2
{
condition:
ext_var == 10
}
/* 外部变量可以和操作符contains和matches一起使用
contains:如果字符串包含指定的子字符串,返回True
matches: 如果字符串匹配给定的正则表达式时,返回True
*/
rule ExternalVariableExample3
{
condition:
string_ext_var contains "text"
}
rule ExternalVariableExample4
{
condition:
string_ext_var matches /[a-z]+/
}
// 也可以将matches操作符和正则表达式一起使用
rule ExternalVariableExample5
{
condition:
// [a-z]+/is中的i表示匹配时不区分大小写. s表示是在单行(single line)模式
string_ext_var matches /[a-z]+/is
}
文件包含
// 作用于C语言一样,可以包含其它规则到当前文件中
include "other.yar"
// 相对路径
include "./includes/other.yar"
include "../includes/other.yar"
// 全路径
include "/home/plusvic/yara/includes/other.yar"
五、参考
编写 YARA 规则 — yara 4.2.0 文档