第三章 Collections类
3.1 Collections常用功能
java.utils.Collections是集合工具类,用来对集合进行操作。常用方法如下:
public static void shuffle(List<?> list):打乱集合顺序。
public static <T> void sort(List<T> list):将集合中元素按照默认规则排序。
public static <T> void sort(List<T> list,Comparator<? super T> ):将集合中元素按照指定规则排序。
代码演示:
public class CollectionsDemo {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<Integer>();
list.add(100);
list.add(300);
list.add(200);
list.add(50);
//排序方法
Collections.sort(list);
System.out.println(list);
}
}
结果:
[50,100, 200, 300]
我们的集合按照默认的自然顺序进行了排列,如果想要指定顺序那该怎么办呢?
3.2 Comparator比较器
创建一个学生类,存储到ArrayList集合中完成指定排序操作。
Student 类
public class Student{
private String name;
private int age;
//构造方法
//get/set
//toString
}
测试类:
public class Demo {
public static void main(String[] args) {
// 创建四个学生对象 存储到集合中
ArrayList<Student> list = new ArrayList<Student>();
list.add(new Student("rose",18));
list.add(new Student("jack",16));
list.add(new Student("abc",20));
Collections.sort(list, new Comparator<Student>() {//注意和TreeSet比较
@Override
public int compare(Student o1, Student o2) {
return o1.getAge()-o2.getAge();//以学生的年龄升序(前-后是升序)
}
});
for (Student student : list) {
System.out.println(student);
}
}
}
Student{name='jack', age=16}
Student{name='rose', age=18}
Student{name='abc', age=20}
总结:回顾一下TreeSet的比较,也是用Lambda表达式,和这个一模一样。
3.3 可变参数
在JDK1.5之后,如果我们定义一个方法需要接受多个参数,并且多个参数类型一致,我们可以对其简化.
格式:
修饰符 返回值类型 方法名(参数类型... 形参名){ }
底层:
其实就是一个数组
好处:
在传递数据的时候,省的我们自己创建数组并添加元素了,JDK底层帮我们自动创建数组并添加元素了
代码演示:
public class ChangeArgs {
public static void main(String[] args) {
int sum = getSum(6, 7, 2, 12, 2121);
System.out.println(sum);
}
public static int getSum(int... arr) {
int sum = 0;
for (int a : arr) {
sum += a;
}
return sum;
}
}
注意:
1.一个方法只能有一个可变参数
2.如果方法中有多个参数,可变参数要放到最后。
应用场景: Collections
在Collections中也提供了添加一些元素方法:
public static <T> boolean addAll(Collection<T> c, T... elements):往集合中添加一些元素。
代码演示:
public class CollectionsDemo {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<Integer>();
//原来写法
//list.add(12);
//list.add(14);
//list.add(15);
//list.add(1000);
//采用工具类 完成 往集合中添加元素
Collections.addAll(list, 5, 222, 1,2);
System.out.println(list);
}
第四章 斗地主发牌
4.1 案例介绍
按照斗地主的规则,完成洗牌发牌的动作。 具体规则:
使用54张牌打乱顺序,三个玩家参与游戏,三人交替摸牌,每人17张牌,最后三张留作底牌。
4.2 案例分析
-
准备牌:
牌可以设计为一个ArrayList<String>,每个字符串为一张牌。 每张牌由花色数字两部分组成,我们可以使用花色集合与数字集合嵌套迭代完成每张牌的组装。 牌由Collections类的shuffle方法进行随机排序。
-
发牌
将每个人以及底牌设计为ArrayList<String>,将最后3张牌直接存放于底牌,剩余牌通过对3取模依次发牌。
-
看牌
直接打印每个集合。
4.3 代码实现
public class CollectionsDemo3 {
//准备牌盒
static ArrayList<String> list = new ArrayList<>();
//静态代码块
static{
//1.准备牌
String[] colorArr = {"黑桃","红桃","梅花","方块"};
String[] numberArr = {"3","4","5","6","7","8","9","10","J","Q","K","A","2"};
for (String color : colorArr) {
for (String number : numberArr) {
list.add(color + number);
}
}
list.add("大王");
list.add("小王");
}
public static void main(String[] args) {
//2.洗牌
Collections.shuffle(list);//随机打乱牌的顺序
//3.发牌
ArrayList<String> diPai = new ArrayList<>();
ArrayList<String> zhouXC = new ArrayList<>();//定义三个不同玩家的集合
ArrayList<String> zhouRF = new ArrayList<>();
ArrayList<String> liuDH = new ArrayList<>();
//遍历的时候。如果仅仅只想获取元素,增强for
//如果在遍历的时候,要添加或者删除,用迭代器
//如果在遍历的时候,要操作索引,用普通for
for (int i = 0; i < list.size(); i++) {
//索引 跟 牌 有一个对应关系
//索引 % 3 == 0 发给第一个人
//索引 % 3 == 1 发给第二个人
//索引 % 3 == 2 发给第三个人
String poker = list.get(i);
if(i <= 2){//最后三张牌是底牌
diPai.add(poker);
continue;
}
if(i % 3 == 0){
zhouXC.add(poker);
}else if(i % 3 == 1){
zhouRF.add(poker);
}else{
liuDH.add(poker);
}
}
//4.遍历
System.out.println("底牌:" + diPai);
System.out.println("周星驰:" + zhouXC);
System.out.println("周润发:" + zhouRF);
System.out.println("刘德华:" + liuDH);
}
}
第五章 Map集合
5.1 概述
现实生活中,我们常会看到这样的一种集合:IP地址与主机名,身份证号与个人,系统用户名与系统用户对象等,这种一一对应的关系,就叫做映射。Java提供了专门的集合类用来存放这种对象关系的对象,即java.util.Map接口。
我们通过查看Map接口描述,发现Map接口下的集合与Collection接口下的集合,它们存储数据的形式不同,如下图。

Collection中的集合,元素是孤立存在的(理解为单身),向集合中存储元素采用一个个元素的方式存储。
Map中的集合,元素是成对存在的(理解为夫妻)。每个元素由键与值两部分组成,通过键可以找对所对应的值。
Collection中的集合称为单列集合,Map中的集合称为双列集合。需要注意的是,
Map中的集合不能包含重复的键,值可以重复;每个键只能对应一个值。
5.2 Map的常用子类
通过查看Map接口描述,看到Map有多个子类,这里我们主要讲解常用的HashMap集合、LinkedHashMap集合。

HashMap<K,V>:存储数据采用的哈希表结构,元素的存取顺序不能保证一致。由于要保证键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。
LinkedHashMap<K,V>:HashMap下有个子类LinkedHashMap,存储数据采用的哈希表结构+链表结构。通过链表结构可以保证元素的存取顺序一致;通过哈希表结构可以保证的键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。
TreeMap<K,V>:TreeMap集合和Map相比没有特有的功能,底层的数据结构是红黑树;可以对元素的键进行排序,排序方式有两种:自然排序和比较器排序
tips:Map接口中的集合都有两个泛型变量<K,V>,在使用时,要为两个泛型变量赋予数据类型。两个泛型变量<K,V>的数据类型可以相同,也可以不同。
5.3 Map的常用方法
Map接口中定义了很多方法,常用的如下:
public V put(K key, V value): 把指定的键与指定的值添加到Map集合中。
public V remove(Object key): 把指定的键所对应的键值对元素 在Map集合中删除,返回被删除元素的值。
public V get(Object key)根据指定的键,在Map集合中获取对应的值。
public Set<K> keySet(): 获取Map集合中所有的键,存储到Set集合中。
public Set<Map.Entry<K,V>> entrySet(): 获取到Map集合中所有的键值对对象的集合(Set集合)。
public boolean containKey(Object key):判断该集合中是否有此键。
先看put()方法:
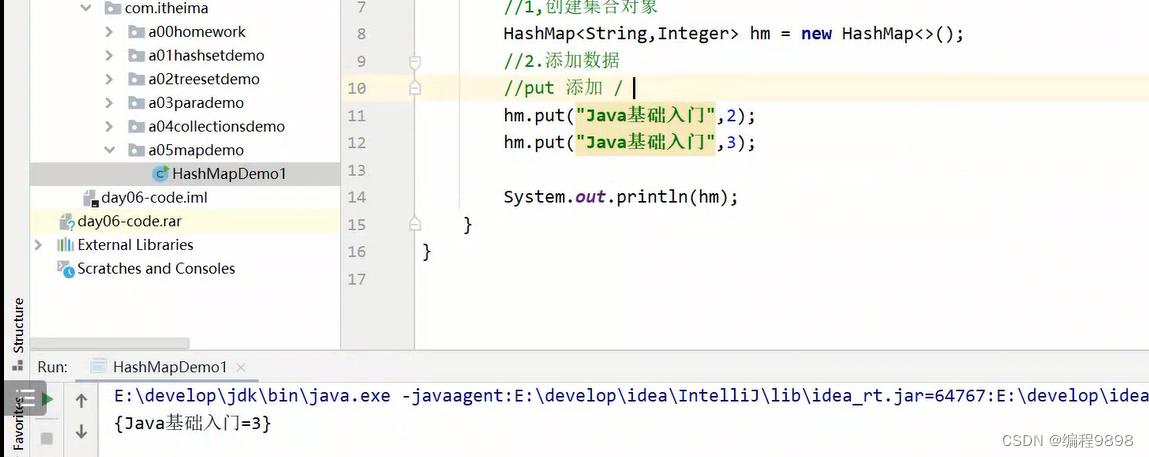
当键值相同时,后面的值会覆盖掉前面的值,这是put()方法的一个特点。
再看:
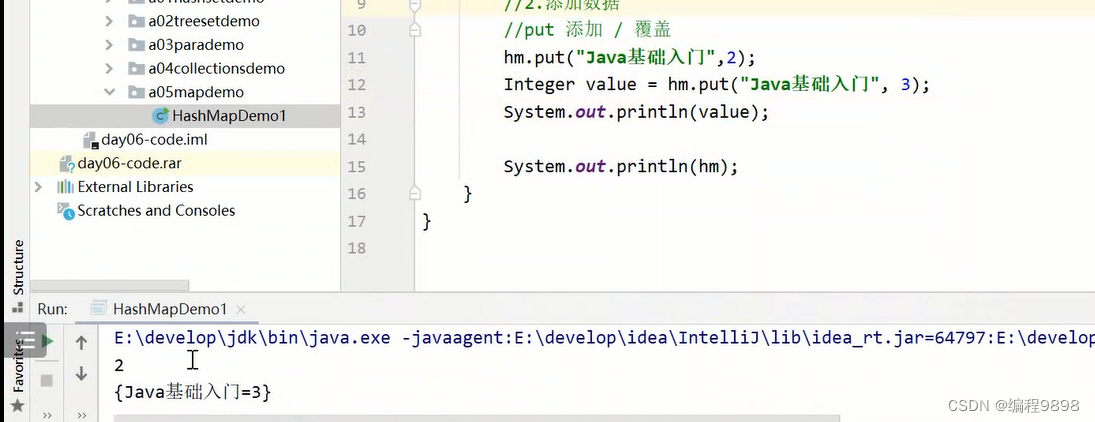
发现put()方法的返回值是返回被覆盖的那个值。但是这个我们一般用不到。
Map接口的方法演示
public class MapDemo {
public static void main(String[] args) {
//创建 map对象
HashMap<String, String> map = new HashMap<String, String>();
//添加元素到集合
map.put("黄晓明", "杨颖");
map.put("文章", "马伊琍");
map.put("邓超", "孙俪");
System.out.println(map);
//String remove(String key)
System.out.println(map.remove("邓超"));//remove返回值是被删除的键值对的值
System.out.println(map);
// 想要查看 黄晓明的媳妇 是谁
System.out.println(map.get("黄晓明"));
System.out.println(map.get("邓超"));
}
}
总结:
使用put方法时,若指定的键(key)在集合中没有,则没有这个键对应的值,返回null,并把指定的键值添加到集合中;
若指定的键(key)在集合中存在,则返回值为集合中键对应的值(该值为替换前的值),并把指定键所对应的值,替换成指定的新值。
5.4 Map的遍历
首先要知道一点的是:Map不能直接用迭代器进行遍历。
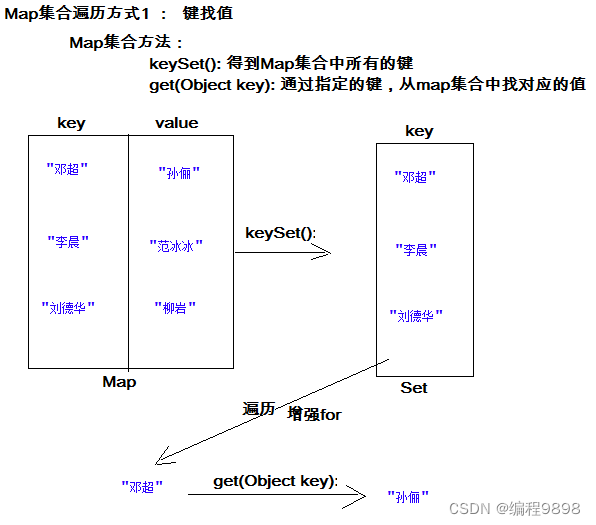
方式1:键找值方式
通过元素中的键,获取键所对应的值
分析步骤:
获取Map中所有的键,由于键是唯一的,所以返回一个Set集合存储所有的键。方法提示:
keyset()遍历键的Set集合,得到每一个键。
根据键,获取键所对应的值。方法提示:
get(K key)
遍历图解:
代码示例:
//1.创建一个集合
HashMap<String,String> hm = new HashMap<>();
//2.添加元素
hm.put("郭靖","黄蓉");
hm.put("尹志平","小龙女");
hm.put("林平之","岳灵珊");
//3.遍历
//方式一:键找值
//先把所有的键都获取出来,放到一个Set集合中
Set<String> keys = hm.keySet();
for (String key : keys) {
//得到每一个键之后,再通过键找值
String value = hm.get(key);
System.out.println(key + ", " + value);
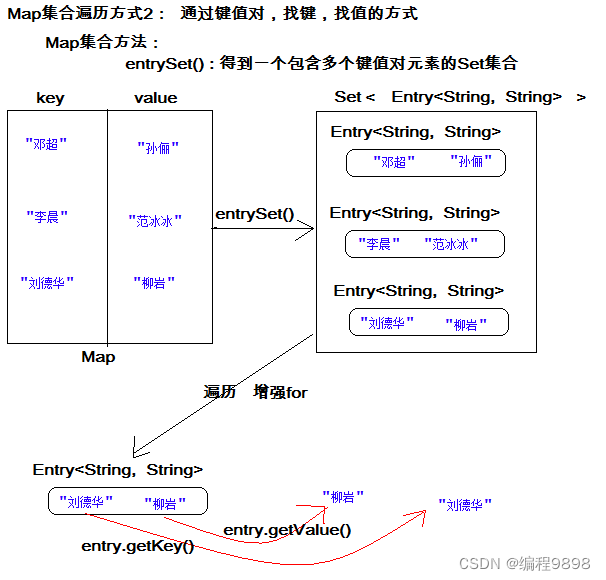
方式2:键值对方式
即通过集合中每个键值对(Entry)对象,获取键值对(Entry)对象中的键与值。
Entry键值对对象:
我们已经知道,Map中存放的是两种对象,一种称为key(键),一种称为value(值),它们在在Map中是一一对应关系,这一对对象又称做Map中的一个Entry(项)。Entry将键值对的对应关系封装成了对象。即键值对对象,这样我们在遍历Map集合时,就可以从每一个键值对(Entry)对象中获取对应的键与对应的值。
在Map集合中也提供了获取所有Entry对象的方法:
-
public Set<Map.Entry<K,V>> entrySet(): 获取到Map集合中所有的键值对对象的集合(Set集合)。(注意这里有泛型的嵌套)
获取了Entry对象 , 表示获取了一对键和值,那么同样Entry中 , 分别提供了获取键和获取值的方法:
public K getKey():获取Entry对象中的键。
public V getValue():获取Entry对象中的值。
操作步骤与图解:
获取Map集合中,所有的键值对(Entry)对象,以Set集合形式返回。方法提示:
entrySet()。遍历包含键值对(Entry)对象的Set集合,得到每一个键值对(Entry)对象。
通过键值对(Entry)对象,获取Entry对象中的键与值。 方法提示:
getkey() getValue()
遍历图解:
tips:Map集合不能直接使用迭代器或者foreach进行遍历。但是转成Set之后就可以使用了。
代码示例:
//1.创建一个集合
HashMap<String,String> hm = new HashMap<>();
//2.添加元素
hm.put("郭靖","黄蓉");
hm.put("尹志平","小龙女");
hm.put("林平之","岳灵珊");
hm.put("韦小宝","双儿");
hm.put("成昆","阳夫人");
//3.获取Map集合中的每一个键值对对象Entry
//把每一个键值对对象放到一个Set集合中
Set<Map.Entry<String, String>> entries = hm.entrySet();
//遍历Set集合
for (Map.Entry<String, String> entry : entries) {
//entry 依次表示每一个键值对对象
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + ", " + value);
}
方式3:lambda表达式方式
和单列集合一样,涉及到forEach方法:
代码示例:
package com.itheima.a08mapdemo;
import java.util.HashMap;
import java.util.function.BiConsumer;
public class MapDemo4 {
public static void main(String[] args) {
//1.创建一个集合
HashMap<String, String> hm = new HashMap<>();
//2.添加元素
hm.put("郭靖", "黄蓉");
hm.put("尹志平", "小龙女");
hm.put("林平之", "岳灵珊");
hm.put("韦小宝", "双儿");
hm.put("成昆", "阳夫人");
//3.利用匿名内部类来遍历集合
hm.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String key, String value) {
System.out.println(key + ", " + value);
}
});
//4.利用lambda表达式来遍历集合
hm.forEach((String key, String value) -> {
System.out.println(key + ", " + value);
}
);
//5.简化lambda表达式来遍历集合
hm.forEach((key, value) -> System.out.println(key + ", " + value) );
}
}
(下面的知识点明天讲)
练习:统计景点次数
需求:
某个班级80名学生,现在需要组成秋游活动,班长提供了四个景点依次是(A、B、C、D), 每个学生只能选择一个景点,请统计出最终哪个景点想去的人数最多。
代码示例:
//1.让同学们进行选择
String[] arr = {"A","B","C","D"};
Random r = new Random();
//把同学们的选择都存入到集合中
ArrayList<String> list = new ArrayList<>();
for (int i = 0; i < 80; i++) {
int randomIndex = r.nextInt(arr.length);
list.add(arr[randomIndex]);
}
//2.统计每个景点的选择次数
//A=10 B=20 C=30 D=40
HashMap<String,Integer> hm = new HashMap<>();
//遍历list集合,拿到每一个景点的名字
for (String name : list) {
if(hm.containsKey(name)){
//表示已经存在
//如果当前景点已经存在,把原有的次数拿出来+1
//此时put(景点的名字,新的次数)
int count = hm.get(name);
count++;
hm.put(name,count);
}else{
//表示不存在
//如果当前景点在map集合不存在,表示第一次选择
//此时put(景点的名字,1)
hm.put(name,1);
}
}
//3.遍历map集合
hm.forEach((key,value)->System.out.println(key + ", " + value));
5.5 HashMap存储自定义类型
小结:

还有:

练习:每位学生(姓名,年龄)都有自己的家庭住址。那么,既然有对应关系,则将学生对象和家庭住址存储到map集合中。学生作为键, 家庭住址作为值。
注意,学生姓名相同并且年龄相同视为同一名学生。
编写学生类:
public class Student {
private String name;
private int age;
//构造方法
//get/set
@Override
public boolean equals(Object o) {//必须重写equals方法
if (this == o)
return true;
if (o == null || getClass() != o.getClass())
return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {//必须重写hashCode方法
return Objects.hash(name, age);
}
}
编写测试类:
public class HashMapTest {
public static void main(String[] args) {
//1,创建Hashmap集合对象。
Map<Student,String> map = new HashMap<Student,String>();
//2,添加元素。
map.put(new Student("lisi",28), "上海");
map.put(new Student("wangwu",22), "北京");
map.put(new Student("wangwu",22), "南京");
//3,取出元素。键找值方式
Set<Student> keySet = map.keySet();
for(Student key: keySet){
String value = map.get(key);
System.out.println(key.toString()+"....."+value);
}
}
}
当给HashMap中存放自定义对象时,如果自定义对象作为key存在,这时要保证对象唯一,必须重写对象的hashCode和equals方法(如果忘记,请回顾HashSet存放自定义对象)。
如果要保证map中存放的key和取出的顺序一致,可以使用
java.util.LinkedHashMap集合来存放。
5.6 LinkedHashMap介绍(底层有双链表机制保证数据添加的时候有序,打印的时候也是有序)
我们知道HashMap保证成对元素唯一,并且查询速度很快,可是成对元素存放进去是没有顺序的,那么我们要保证有序,还要速度快怎么办呢?
在HashMap下面有一个子类LinkedHashMap,它是链表和哈希表组合的一个数据存储结构。
面试加分:LinkedHashMap保证有序是怎么实现的?
用双链表,它保证数据的存的顺序和取的顺序是一致的!!
public class LinkedHashMapDemo {
public static void main(String[] args) {
LinkedHashMap<String, String> map = new LinkedHashMap<String, String>();
map.put("邓超", "孙俪");
map.put("李晨", "范冰冰");
map.put("刘德华", "朱丽倩");
Set<Entry<String, String>> entrySet = map.entrySet();
for (Entry<String, String> entry : entrySet) {
System.out.println(entry.getKey() + " " + entry.getValue());
}
}
}
结果:
邓超 孙俪 李晨 范冰冰 刘德华 朱丽倩
5.7 TreeMap集合
1.TreeMap介绍
TreeMap集合和Map相比没有特有的功能,底层的数据结构是红黑树;可以对元素的键进行排序,注意,是对键进行排序,而不是对值进行排序!排序方式有两种:自然排序和比较器排序;到时使用的是哪种排序,取决于我们在创建对象的时候所使用的构造方法;
public TreeMap() 使用自然排序 public TreeMap(Comparator<? super K> comparator) 比较器排序
2.演示
案例演示自然排序
public static void main(String[] args) {
TreeMap<Integer, String> map = new TreeMap<Integer, String>();
map.put(1,"张三");
map.put(4,"赵六");
map.put(3,"王五");
map.put(6,"酒八");
map.put(5,"老七");
map.put(2,"李四");
System.out.println(map);
}
控制台的输出结果为:
{1=张三, 2=李四, 3=王五, 4=赵六, 5=老七, 6=酒八}
案例演示比较器排序
需求:
创建一个TreeMap集合,键是学生对象(Student),值是居住地 (String)。存储多个元素,并遍历。
要求按照学生的年龄进行升序排序,如果年龄相同,比较姓名的首字母升序, 如果年龄和姓名都是相同,认为是同一个元素;
实现:
为了保证age和name相同的对象是同一个,Student类必须重写hashCode和equals方法,这两个方法重写的场景只有两种:
1、只有在HashSet中存储自定义对象
2、HashMap的键存储自定义对象
3、TreeSet、TreeMap的键底层是用红黑树实现的,我们不需要重写hashCode和equals方法,我们只需要给TreeSet里面的元素还有TreeMap的键指定排序规则。
public class Student {
private int age;
private String name;
//省略get/set..
public Student() {}
public Student(int age, String name) {
this.age = age;
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age &&
Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(age, name);
}
}
public static void main(String[] args) {
TreeMap<Student, String> map = new TreeMap<Student, String>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
//先按照年龄升序
int result = o1.getAge() - o2.getAge();
if (result == 0) {
//年龄相同,则按照名字的首字母升序
return o1.getName().charAt(0) - o2.getName().charAt(0);
} else {
//年龄不同,直接返回结果
return result;
}
}
});
map.put(new Student(30, "jack"), "深圳");
map.put(new Student(10, "rose"), "北京");
map.put(new Student(20, "tom"), "上海");
map.put(new Student(10, "marry"), "南京");
map.put(new Student(30, "lucy"), "广州");
System.out.println(map);
}
控制台的输出结果为:
{
Student{age=10, name='marry'}=南京,
Student{age=10, name='rose'}=北京,
Student{age=20, name='tom'}=上海,
Student{age=30, name='jack'}=深圳,
Student{age=30, name='lucy'}=广州
}
5.8 Map集合练习
需求:
输入一个字符串中每个字符出现次数。
分析:
-
获取一个字符串对象
-
创建一个Map集合,键代表字符,值代表次数。
-
遍历字符串得到每个字符。
-
判断Map中是否有该键。
-
如果没有,第一次出现,存储次数为1;如果有,则说明已经出现过,获取到对应的值进行++,再次存储。
-
打印最终结果
这种方法就比之前单纯的计算器思想高级的多。
方法介绍
public boolean containKey(Object key):判断该集合中是否有此键。
代码:
public class MapTest {
public static void main(String[] args) {
//友情提示
System.out.println("请录入一个字符串:");
String line = new Scanner(System.in).nextLine();
// 定义 每个字符出现次数的方法
findChar(line);
}
private static void findChar(String line) {
//1:创建一个集合 存储 字符 以及其出现的次数
HashMap<Character, Integer> map = new HashMap<Character, Integer>();
//2:遍历字符串
for (int i = 0; i < line.length(); i++) {
char c = line.charAt(i);
//判断 该字符 是否在键集中
if (!map.containsKey(c)) {//说明这个字符没有出现过
//那就是第一次
map.put(c, 1);
} else {
//先获取之前的次数
Integer count = map.get(c);
//count++;
//再次存入 更新
map.put(c, ++count);
}
}
System.out.println(map);
}
}
集合的知识多而杂乱,大家学习的时候一定要结构化学习,对比学习,学习的过程中的同时要总结。我相信,你多学几遍,集合一定能拿下!








![深度学习基础入门篇[七]:常用归一化算法、层次归一化算法、归一化和标准化区别于联系、应用案例场景分析。](https://img-blog.csdnimg.cn/img_convert/1a5a92c378832c41ea3aefb989a5247e.png)
