使用pandas读取每行不同列的CSV文件
对于序列模型而言,每条数据的大小都不一定相等,但对于一般的神经网络要求输入大小相等。目前的一种方法是选取当前数据集中最大长度的数据作为基准数据大小,其余的数据末尾补零来规范整个数据集每条数据的大小。
本文重点关注小规模的CSV数据集,通过pandas读取每行不同列的CSV文件,最终生成神经网络可以使用的数据
PS: 本文仅具有一般性,对于特定的数据集,还需要具体问题具体分析!!
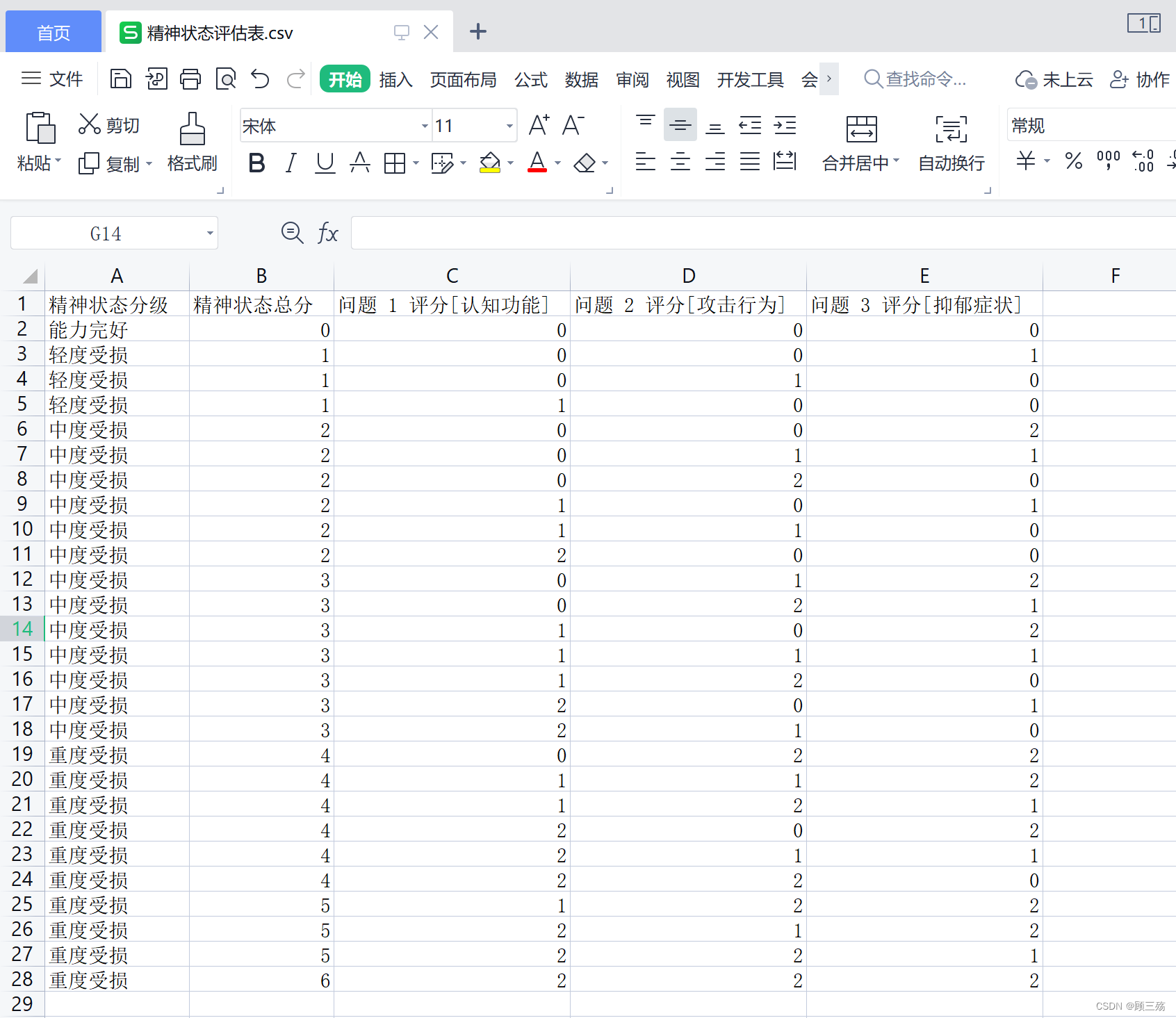
如图:

-
遍历train、test文件,获取最大列数据
largest_columtrain_path = 'train.csv' test_path = 'test.csv' largest_colum = 0 # 数据集中最大的列数 with open(train_path, 'r') as f: # 遍历train.csv, 获取训练集中的最大列数 datas = f.readlines() for i, l in enumerate(datas): largest_colum = largest_colum if largest_colum > len(l.split(',')) + 1 else len(l.split(',')) + 1 with open(test_path, 'r') as f: # 编列test.csv, 获取测试集中的最大列数 datas = f.readlines() for i, l in enumerate(datas): largest_colum = largest_colum if largest_colum > len(l.split(',')) + 1 else len(l.split(',')) + 1 -
抛弃原有csv的列索引,使用
largest_colum作为索引读取csv文件col_name = [i for i in range(largest_colum)] # 生成CSV数据每一列的索引 train_data = pd.read_csv(train_path, header=None, sep=',', names=col_name, engin='python') train_data = pd.read_csv(test_path, header=None, sep=',', names=col_name, engin='python')读出后数据为:
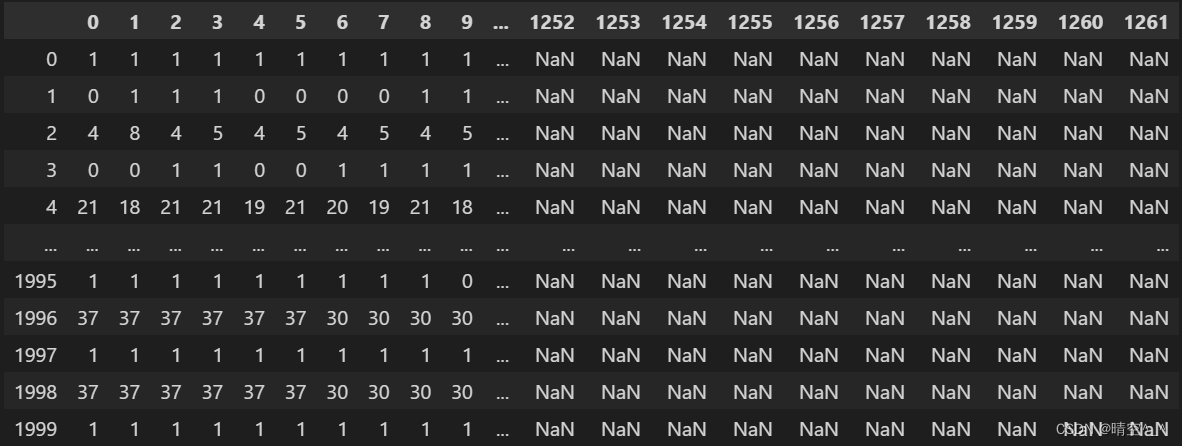
-
将末尾不够长的数据填充为0(不一定必须是0,要与数据集中原有数据区分开)
train_data = train_data.fillna(-1) test_data = test_data.fillna(-1) -
将pandas矩阵转化为torch tensor
train_features = torch.tensor(train_data, dtype=torch.float32) test_features = torch.tensor(test_data, dtype=torch.float32)


![[C++]:万字超详细讲解多态以及多态的实现原理(面试的必考的c++考点)](https://img-blog.csdnimg.cn/04c16237ebb943a899981ce69e863a68.png)