一、概述
Motivation:直接提升PLATO的size训练不work
Methods:
- 通过curriculum learning技术来构建一个高质量的开放领域机器人
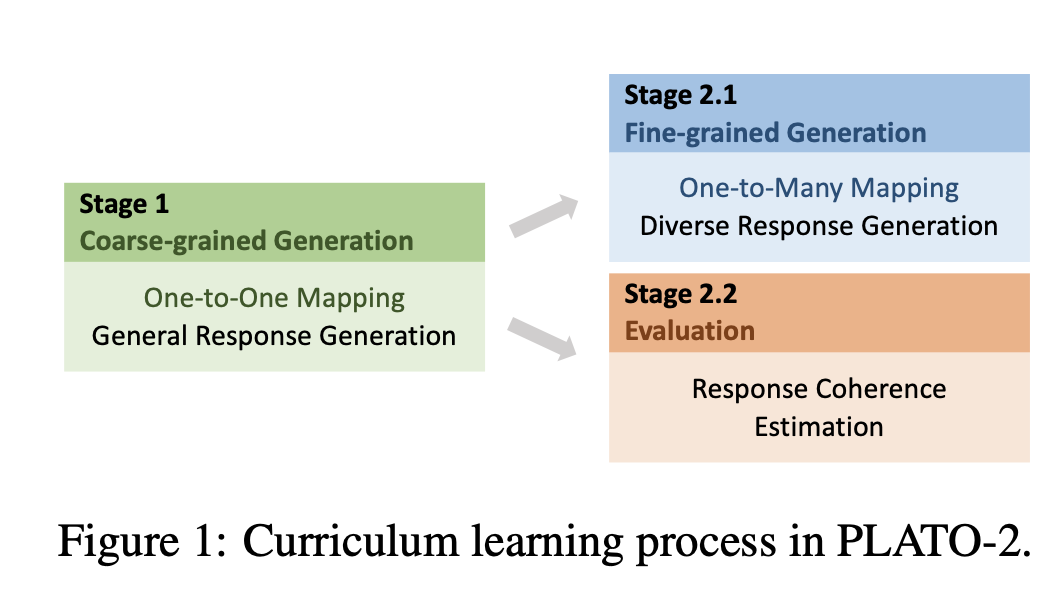
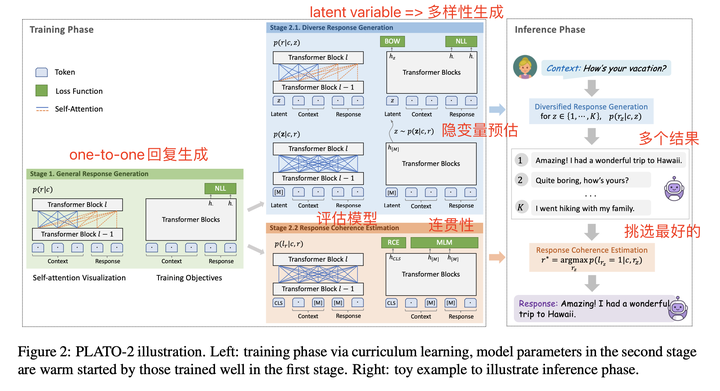
- 第一阶段:coarse-gained generation model:再简单的one-to-one框架下学习粗力度的回复生成模型
- 第二阶段:精调的模型来提高多样性和选择best的回复
-
- latent variables:提高多样性
- evaluation model:选择最好的回复
Conclusion:
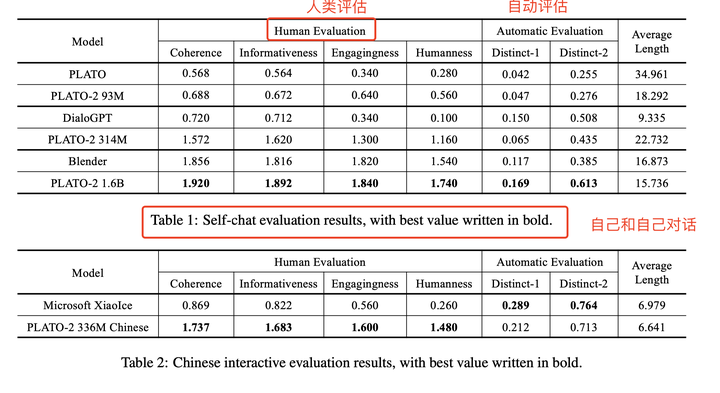
- 在中文以及英文数据集上,PLATO-2都获得了实质的提升
- 在人类评估指标上非常不错,计算指标上与小冰差一点,小冰可能是检索型的方法来实现的
- 在2020年DSTC9开放域,任务型,知识型对话任务上,都取得了第一名的成绩
二、大纲
三、详细内容
-
Introduction
-
预训练模型在开放域对话取得了不错的进展
-
竞品
-
GPT-2,DialoGPT在Reddit comments数据上预训练
-
meena,参数量提升到2.6B + 跟多社交媒体数据 => 回复质量有很大的提升
-
Blender:通过在人工标注的数据集上fine-tune来降低toxic,bias,并且强调环境、知识、同理心和个性等理想的对话技能
-
PlATO v1: 132M 参数 + 8M samples,提升PLATO参数规模会有训练不稳定以及效率问题
-
-
本文:
-
尝试去提升PLATO的size,并且通过curriculum learning技术来提高训练效率。
-
第一阶段:粗粒度生成模型,具备生成典型的多样性的回复能力,也可能造成典型而沉闷的回复,可能会有安全问题,但是对通用生成的概念的学习还是非常有用的
-
latent variables + evaluation => 聚焦于特定的任务,
-
-
对比v1版本,通过课程学习来逐渐学习回复生成,先从one-to-one,然后做成one-to-many,并且将模型的参数提高到billions的量级
-
在闲聊,任务型对话,知识型对话都取得不错的效果,在DSTC9上做了验证
-
-
-
Methodology
-
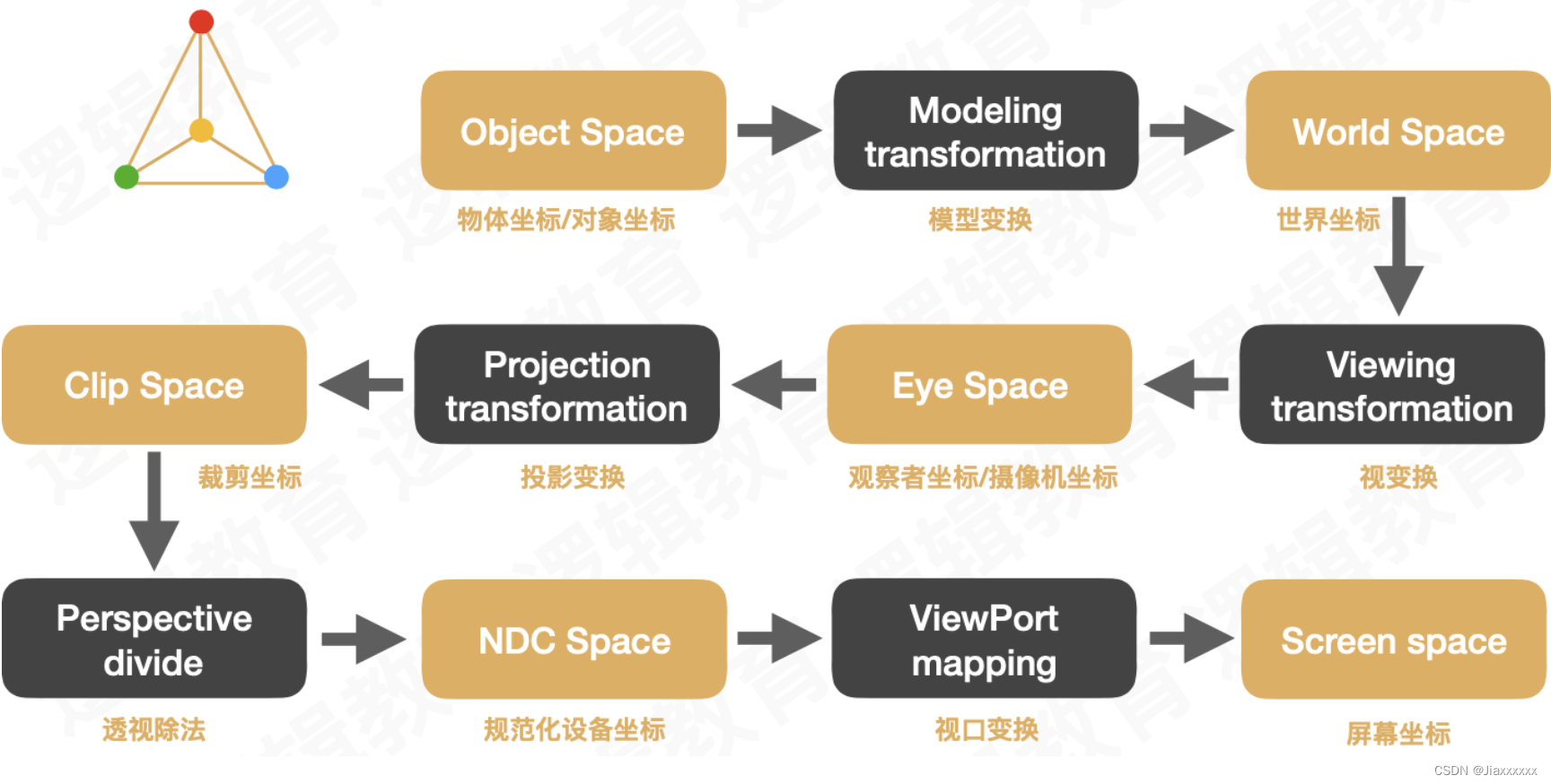
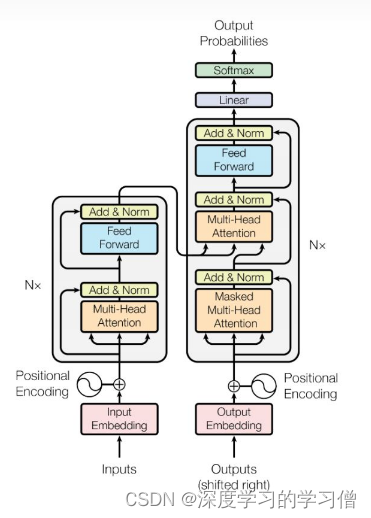
transformer结构 + pre-normalization,与seq2seq不同,没有独立的encoder和decoder网络
-
bi-directional上下文编码 + uni-directional 回复生成
-
-
Experiments
-
training
-
训练是在64个Nvidia Tesla V100 32G GPU卡上进行的。1.6B参数模型完成课程学习过程大约需要3周时间。
-
1.2B (context, response) samples in the training set, 0.1M samples in the validation set, and 0.1M sam- ples in the test set
-
Chinese vocabulary, it contains 30K BPE tokens
-
standard version of 1.6B parameters, a small version of 314M parameters, and a tiny version of 93M parameters
-
-
Evaluation Metrics
-
automatic:distinct-1/2:评估词的多样性,不同的gram的词/生成词的总数
-
human
-
utterance-level(话语层次):
-
coherence:衡量是上下文的相关性和一致性
-
informativeness:衡量回复的信息量
-
dialogue-level(对话层次):
-
engagingness:是否想聊更长的对话
-
humanness:是否像人类
-
[0,1,2]的分数,分数越高越好
-
机器和自己对话结果
-
-
-
-
选择经典的200个话题来作为topic
-
小冰在distinct指标表现比较好,他可能用了检索的方式来做的
-
PLATO-2在人工指标上比较好
-
PLATO-2在DSTC9比赛的开放域对话、知识型对话以及任务型对话的任务上都拿到了第一名的成绩