🎉🎉🎉点进来你就是我的人了
博主主页:🙈🙈🙈戳一戳,欢迎大佬指点!
人生格言:当你的才华撑不起你的野心的时候,你就应该静下心来学习!欢迎志同道合的朋友一起加油喔🦾🦾🦾
目标梦想:进大厂,立志成为一个牛掰的Java程序猿,虽然现在还是一个🐒嘿嘿
谢谢你这么帅气美丽还给我点赞!比个心

目录
一. 模拟实现ArrayList编辑
1.定义顺序顺序表
2. 函数实现
(1) 打印顺序表display()函数
(2) 新增元素函数add() (默认在数组最后新增)
(3) 在 pos 位置新增元素add()函数(与上方函数构成重载)
(4) 判定是否包含某个元素contains()函数
(5) 查找某个元素对应位置indexOf() 函数
(6) 获取pos位置的元素get()函数
(7) 将pos位置的元素更新为value set()函数
(8) 删除第一个关键字key remove()函数
(9) 获得顺序表的长度size()函数
(10) 清空顺序表clear()函数
(11) 异常的定义:
3.测试代码
二. ArrayList底层的扩容机制
三.顺序表的优缺点
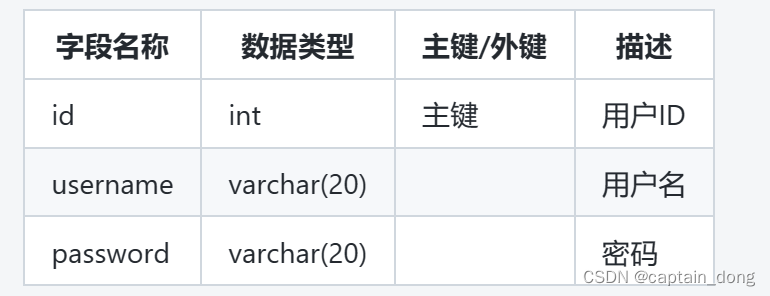
顺序表本质上就是一个数组,而顺序表就是实现对这个数组进行增删查改等操作方法的一个类,而Java中也有类似与顺序表的集合类:ArrayList<E> 下面我会对这个类里面比较重要且常用的方法进行实现。
一. 模拟实现ArrayList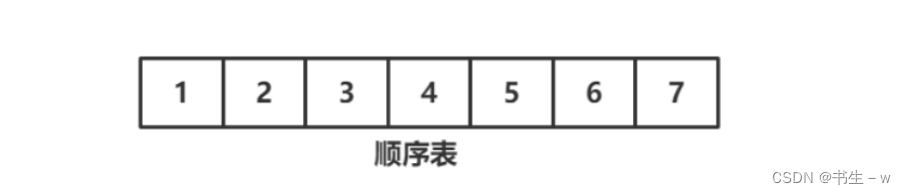
我们这里是模拟实现,所以实现基本功能即可

1.定义顺序顺序表
public class MyArrayList{
public int[] elem;
public int usedSize;//目前存储元素个数
//默认容量
private static final int DEFAULT_SIZE = 10;
public MyArrayList() {
this.elem = new int[DEFAULT_SIZE];
}
}上方定义类SeqList即是顺序表,定义elem数组存储数据,定义usedSize表示当前数组中包含多少个元素,定义DEFAULT_SIZE值为了在构造方法中将顺序表初始化为DEFAULT_SIZE大小的数组。
2. 函数实现
(1) 打印顺序表display()函数
打印函数顾名思义就是将顺序表中所有的数据打印出来。打印完的标准就是将顺序表中的数组完全输出,因此用usedSize作为终止条件,
public void display() {
for (int i = 0; i < this.usedSize; i++) {
System.out.print(elem[i]+" ");
}
System.out.println();
}(2) 新增元素函数add() (默认在数组最后新增)
此函数是增加顺序表中元素的函数。增加元素时,有一点需要注意,你的顺序表是否含有空间放入新的元素。使用函数isFull()判断,若没有满就正常增加,若已满,先对顺序表扩容,再进行增加。
如何判断顺序表满没满?当数组的长度等于数组中包含元素就为满。
当数据载入顺序表成功后,数组中包含元素个数usedSize就需要加1。
public void add(int data) {
if (this.usedSize == elem.length) {
this.elem = Arrays.copyOf(elem, elem.length * 2;
}
elem[usedSize] = data;
usedSize++;
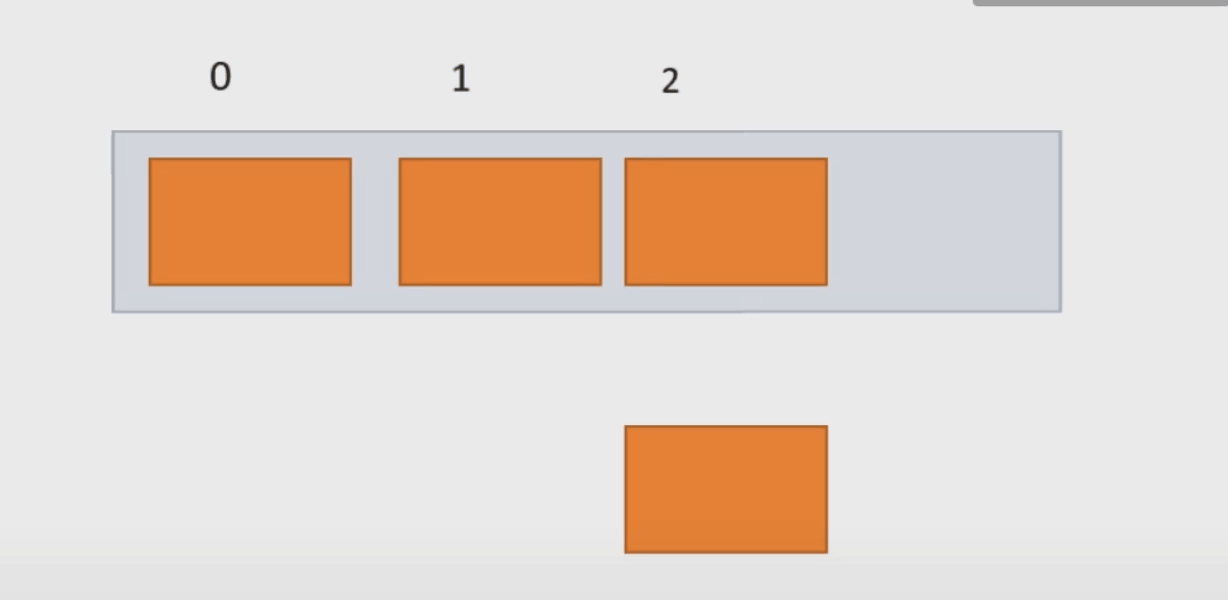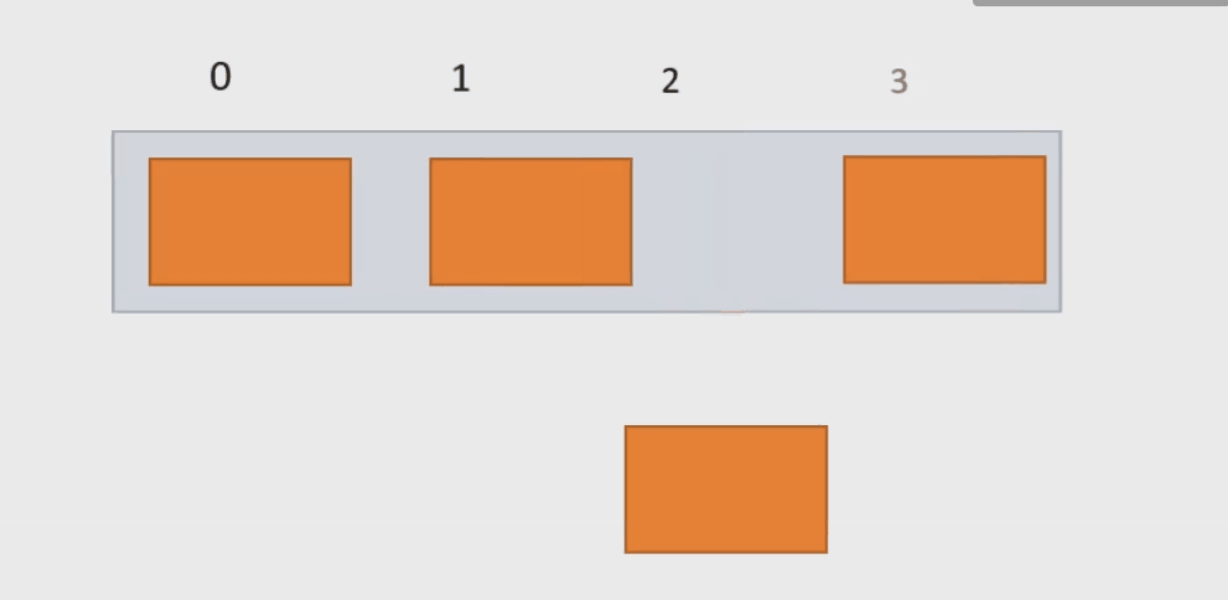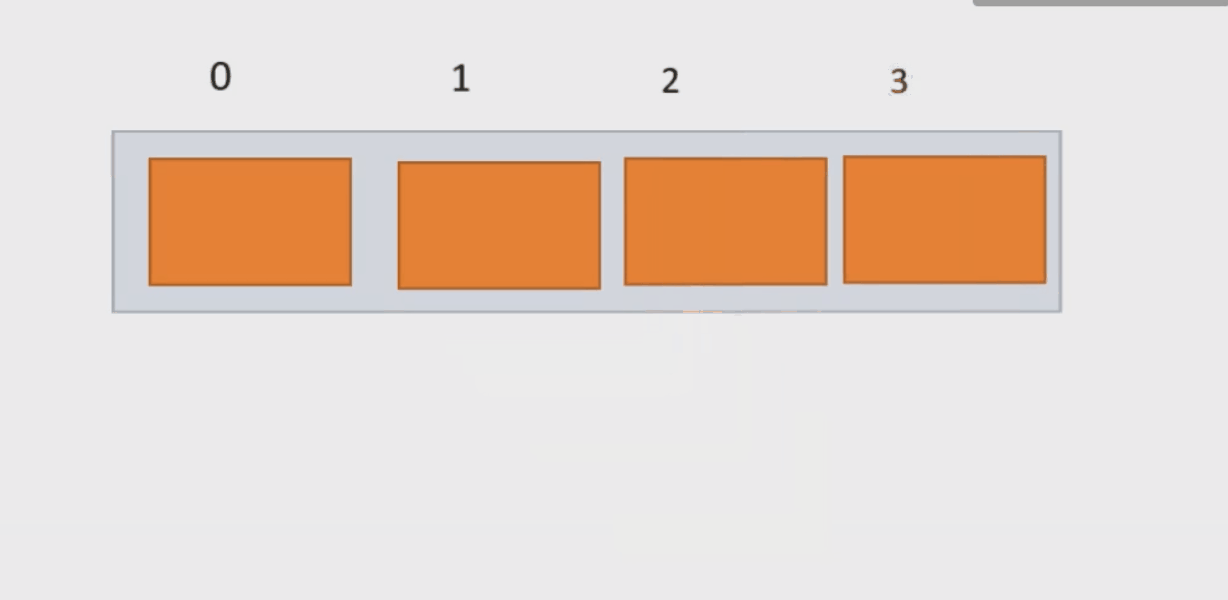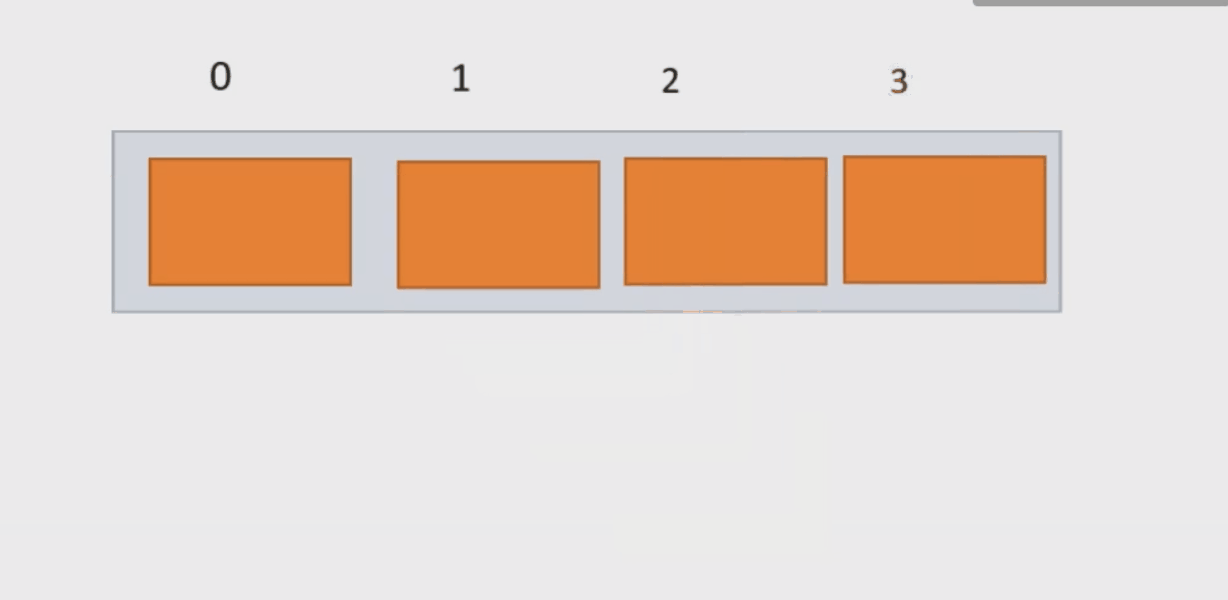
}(3) 在 pos 位置新增元素add()函数(与上方函数构成重载)
我们要判断传过来的下标的合法性;分析pos的取值范围:我们要把新增函数放到现在已有元素之间,因此我们可以知道,pos的范围应该是 0<=pos<usedSize.若给定的下标不合法,我们就抛出一个异常,让程序停下来。
再者这个函数功能也是添加,因此我们也需要判断顺序表空间的问题。
若我们插入的位置已有元素,我们需把从pos位置的元素向后移,为data数据挪开位置。
当数据载入顺序表成功后,数组中包含元素个数usedSize就需要加1。
public void add(int pos, int data) {
if (pos < 0 || pos > usedSize) {
throw new ArrayIndexException("下标非法,请检查");
}
if (this.usedSize == elem.length) {
this.elem = Arrays.copyOf(elem, elem.length * 2;
}
for (int i = usedSize - 1; i >= pos; i--) {
elem[i + 1] = elem[i];
}
elem[pos] = data;
usedSize++;
}下面动图演示:
(4) 判定是否包含某个元素contains()函数
拿到需要找的数据toValue,遍历数组,将数组中的所有值与toValue进行比较,若数组中的值有与toValue相等,那么就返回true,否则返回false。
public boolean contains(int toValue) {
for (int i = 0; i < usedSize; i++) {
if (elem[i] == toValue) {
return true;
}
}
return false;
}(5) 查找某个元素对应位置indexOf() 函数
同上方思想一致,拿到需要找的数据toValue,遍历数组,将数组中的所有值与toValue进行比较,若数组中的值有与toValue相等,那么就返回下标i,否则返回-1。
public int indexOf(int toValue) {
for (int i = 0; i < usedSize; i++) {
if (elem[i] == toValue) {
return i;
}
}
return -1;
}(6) 获取pos位置的元素get()函数
我们要判断下标是否合法,我们需要顺序表中的元素,因此pos不能超过顺序表中第一个元素的下标和最后一个元素的下标,即下标是0<=pos<usedSize,如果不在这个范围内,我们抛出一个异常,让程序停下来。
public int get(int pos) {
if(pos<0||pos>=usedSize){
throw new ArrayIndexException("下标非法,请查看!");
}
return elem[pos];
}(7) 将pos位置的元素更新为value set()函数
同上方一样,我们要判断下标是否合法,我们需要顺序表中的元素,因此pos不能超过顺序表中第一个元素的下标和最后一个元素的下标,即下标是0<=pos<usedSize,如果不在这个范围内,我们抛出一个异常,让程序停下来。最后将value赋到pos位置
public void set(int pos, int value) {
if(pos<0||pos>=usedSize){
throw new ArrayIndexException("下标错误,请查看!");
}
elem[pos] = value;
}(8) 删除第一个关键字key remove()函数
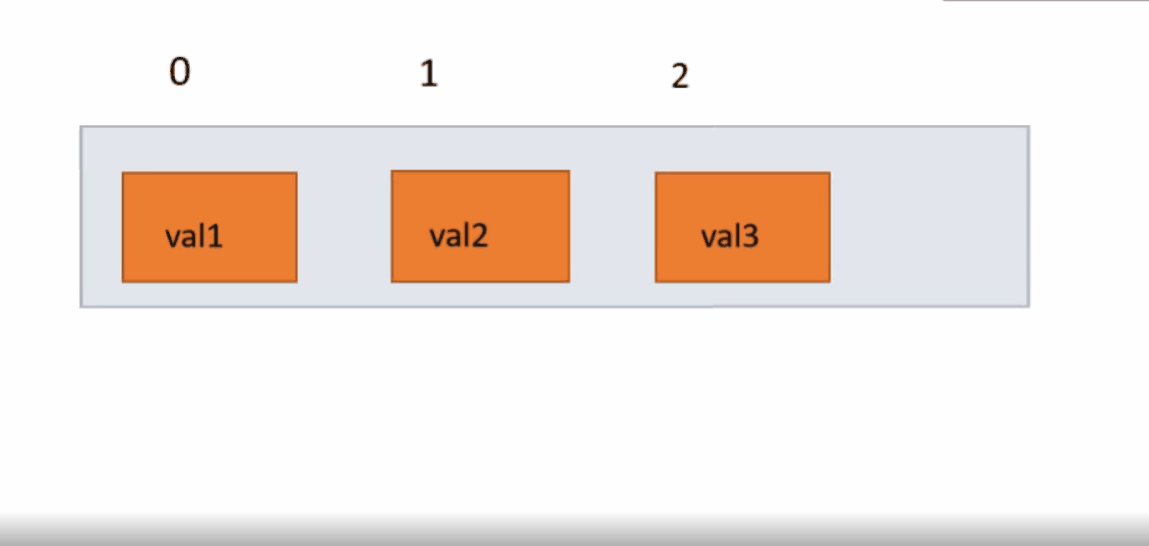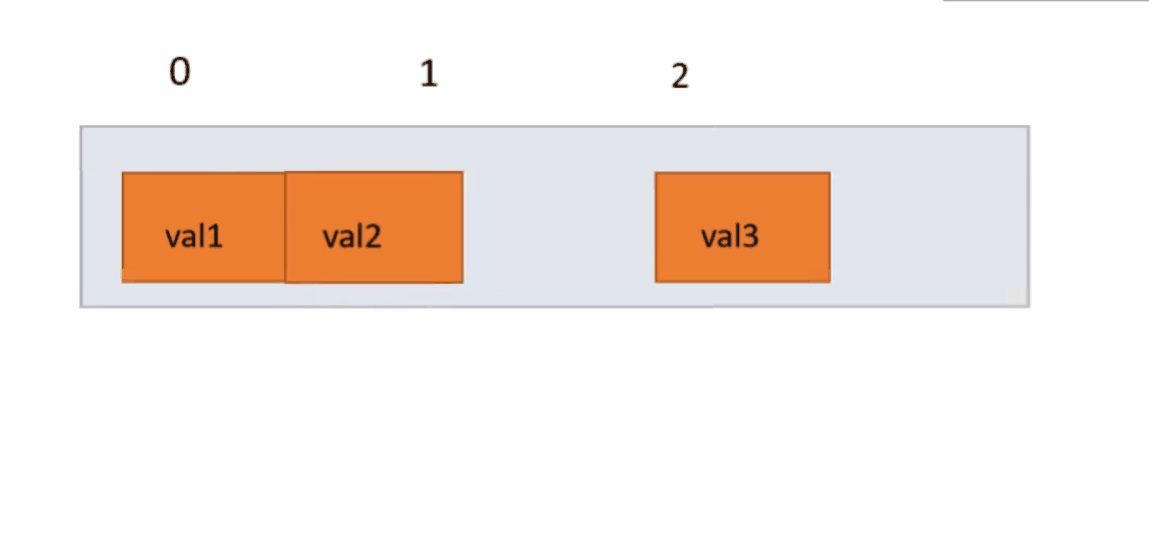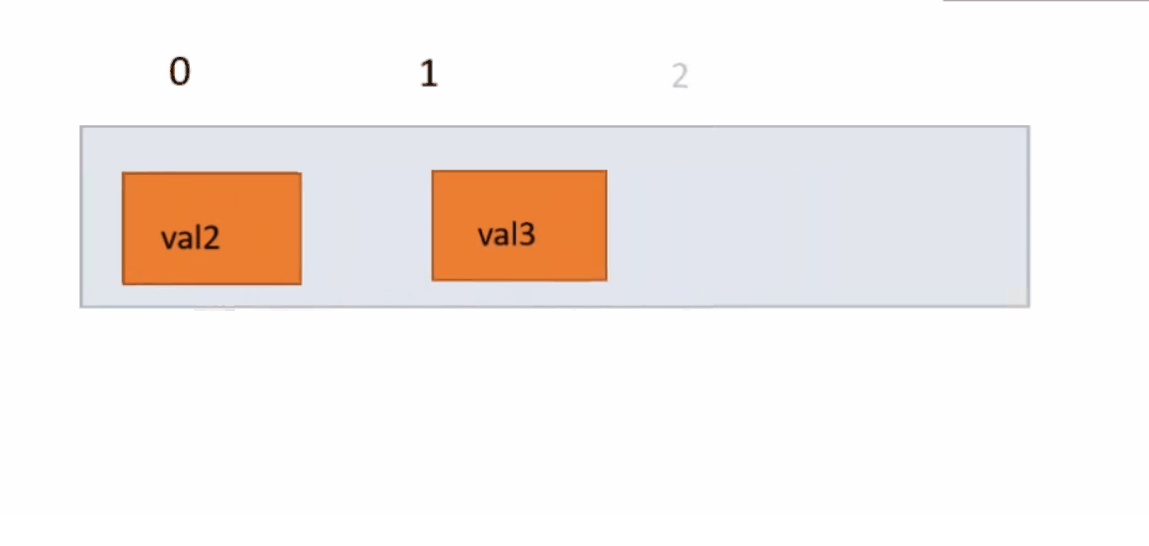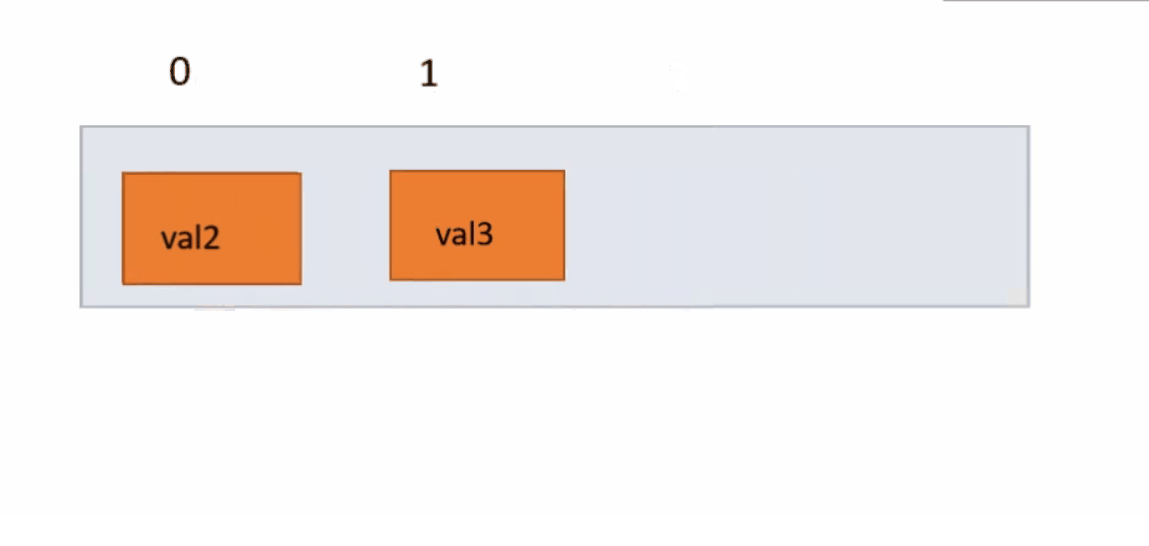
我们先调用indexOf()函数,判断顺序表中是否有我们删除的值,若有找到这个值的下标,没有就返回false。有就以覆盖的方式,将index下标的元素用他后一个元素覆盖,一直往复到最后一个元素,因为删除了一个元素,所以将usedSize减一,因为在覆盖时,最后一个元素是无效数据所以没有覆盖,我们将他置为0。
public boolean remove(int key) {
int index = indexOf(key);
if (index == -1) {
System.out.println("没有这个数据");
return false;
}
for (int i = index; i < usedSize - 1; i++) {
elem[i] = elem[i + 1];
}
usedSize--;
elem[usedSize] = 0;
return true;
}下面动图演示:
(9) 获得顺序表的长度size()函数
当前数组中包含多少个元素,顺序表就是多长,因此顺序表的长度就是usedSize的大小。
public int size() {
return usedSize;
}(10) 清空顺序表clear()函数
因为所有的函数都是围绕这usedSisz进行构造的,我们只需将usedSize置为0,其他函数就无法进行运行(此处并非范例)
public void clear() {
usedSize = 0;
}(11) 异常的定义:
public class ArrayIndexException extends RuntimeException{
public ArrayIndexException() {
}
public ArrayIndexException(String message) {
super(message);
}
}3.测试代码
public class Test {
public static void main(String[] args) {
MyArrayList MyArrayList =new MyArrayList();
//添加数据
MyArrayList.add(1);
MyArrayList.add(2);
MyArrayList.add(3);
MyArrayList.add(4);
MyArrayList.add(5);
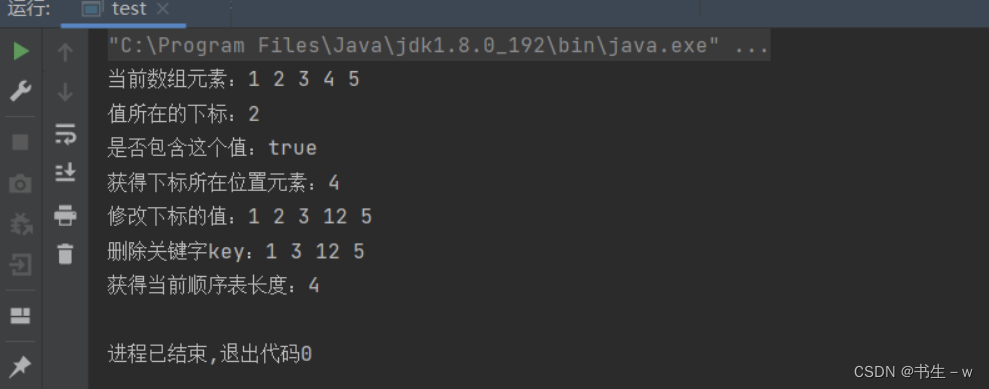
//打印
System.out.print("当前数组元素:");
MyArrayList.display();
//值所在的下标
System.out.print("值所在的下标:");
System.out.println(MyArrayList.indexOf(3));
//是否包含这个值
System.out.print("是否包含这个值:");
System.out.println(MyArrayList.contains(2));
//获得下标所在位置元素
System.out.print("获得下标所在位置元素:");
System.out.println(MyArrayList.get(3));
//修改下标的值
System.out.print("修改下标的值:");
MyArrayList.set(3,12);
MyArrayList.display();
//删除关键字key
System.out.print("删除关键字key:");
MyArrayList.remove(2);
MyArrayList.display();
//获得长度
System.out.print("获得当前顺序表长度:");
System.out.println(MyArrayList.size());
}
}输出结果如下:
二. ArrayList底层的扩容机制
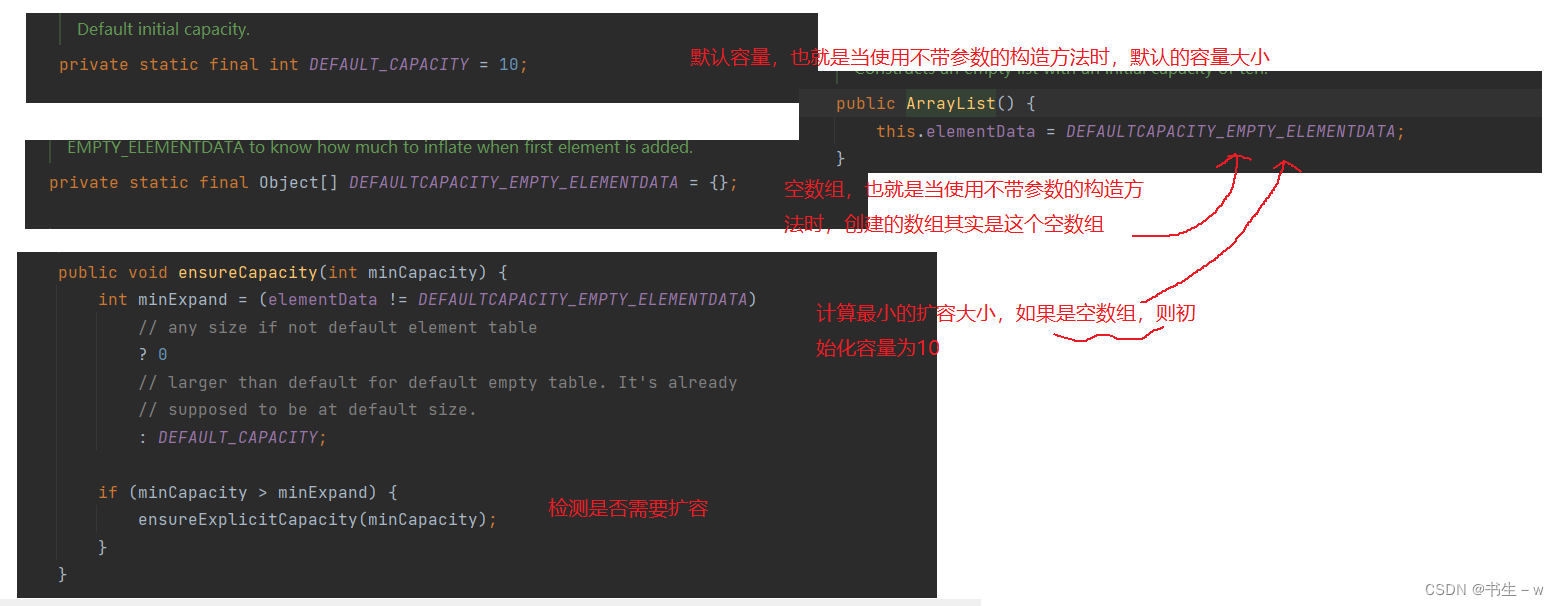
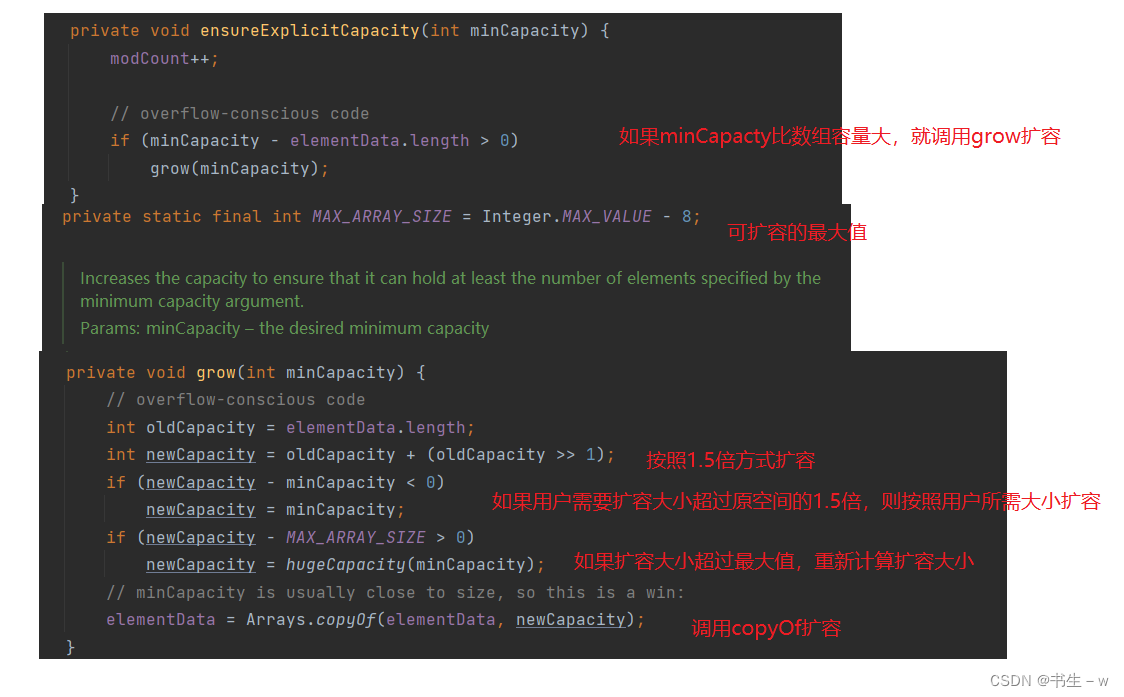
ArrayList是一个动态类型的顺序表,即在插入元素的时候会自动扩容,下面是扩容机制:
🕯️总结:
✨当使用无参的构造方法创建ArrayList,容量默认值10在第一次插入的时候才会初始化初始容量,而不是在创建的时候就初始化容量
✨在插入时,会检测是否真正需要扩容,如果需要,调用grow扩容
✨初步预估按照原容量的1.5倍扩容
✨如果用户所需大小超过预估的1.5倍,则按照用户所需大小扩容
✨真正扩容之前检测是否能扩容成功,防止太大导致扩容失败✨使用copyOf进行扩容
三.顺序表的优缺点
顺序表也是分情况使用的,如何判断呢?总结了它的优缺点,可以作为参考。
优点:
- 无需为表示表中元素之间的逻辑关系而增加额外的存储空间。
- 可以快速地获取表中任意位置的元素。
缺点:
- 插入和删除操作需要移动大量元素(时间复杂度高)。
- 当线性表长度变化较大时,难以确定存储空间的容量。
- 造成存储空间的“碎片”。(当我们添加元素时,例如我们有101个元素,数组初始大小为100,扩容为1.5倍,初始大小无法存储全部元素,因此需要扩容,扩容为150大小,这就浪费了49个空间)