1. torch.nn.Module介绍
torch.nn 能够帮助我们更优雅地训练神经网络,使神经网络代码更加简洁和灵活。官方文档:Torch.NN。
在文档中可以看到第一块内容叫做 Container(容器),这就相当于神经网络的骨架,Container 之后的东西就用于往骨架里面填充,如 Convolution Layers(卷积层)、Pooling Layers(池化层),有卷积神经网络基础的小伙伴对这些词应该都很熟悉了。
Container 中有六个模块:Module、Sequential、ModuleList、ModuleDict、ParameterList、ParameterDict,其中最常用的为 Module,这是所有神经网络的最基本的类,其基本的构造方式如下:
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self): # 初始化
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x): # 前向传播
x = F.relu(self.conv1(x)) # 将 x 进行第一层卷积后用 ReLU 激活函数输出
return F.relu(self.conv2(x)) # 将处理后的 x 再进行第二层卷积后用 ReLU 处理后返回最后结果
现在我们尝试自己创建一个简单的神经网络,并输出前向传播的结果:
import torch
import torch.nn as nn
class Network(nn.Module):
def __init__(self): # 初始化
super(Network, self).__init__()
def forward(self, input):
output = input + 1
return output
network = Network()
x = torch.tensor(1.0) # x 为 tensor 类型
output = network(x) # Module 中的 call 函数会调用 forward 函数
print(output) # tensor(2.)
2. 卷积神经网络原理
卷积神经网络(CNN)中的卷积运算相当于图像处理中的“滤波器运算”。对于输入数据,卷积运算以一定间隔(步长)滑动滤波器(卷积核)的窗口并应用。如下图所示,将各个位置上滤波器的元素和输入的对应元素相乘,然后再求和(有时将这个计算称为乘积累加运算)。然后,将这个结果保存到输出的对应位置。将这个过程在所有位置都进行一遍,就可以得到卷积运算的输出:
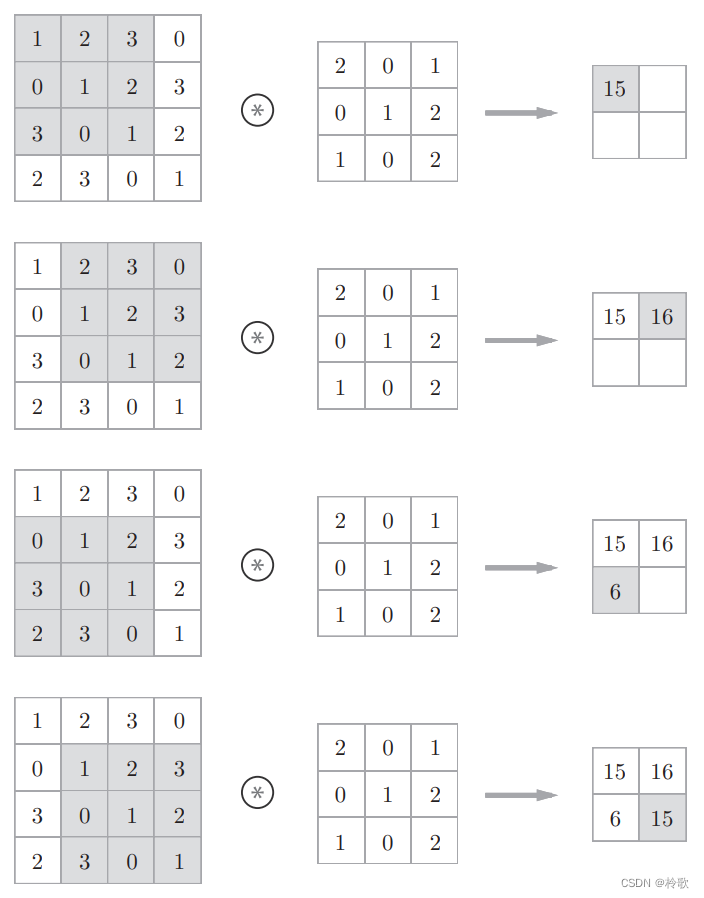
在全连接的神经网络中,除了权重参数,还存在偏置。CNN 中,滤波器的参数就对应之前的权重。并且,CNN 中也存在偏置。包含偏置的卷积运算的处理流如下图所示:
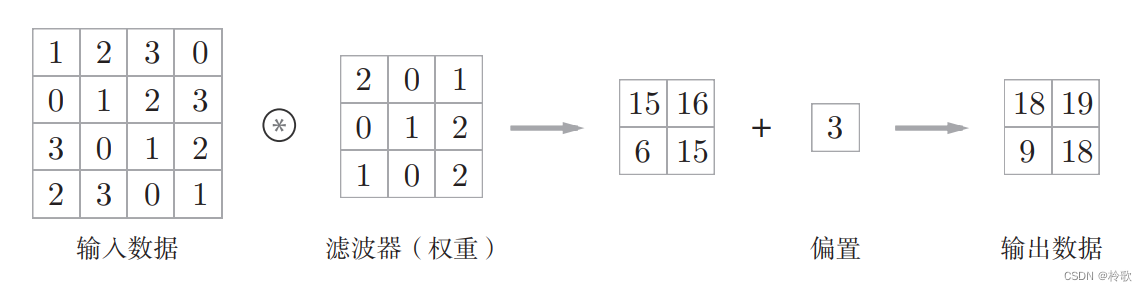
关于卷积神经网络更详细的讲解可以转至:【学习笔记】深度学习入门:基于Python的理论与实现。
现在,我们回到 PyTorch 上,我们以 Conv2d 函数为例,该函数的官方文档:TORCH.NN.FUNCTIONAL.CONV2D。
该函数有以下几个参数:
input:输入的图像,size 为(mini_batch, in_channels, height, width)。weight:卷积核的大小,size 为(out_channels, in_channels/groups, height, width)。bias:偏置,默认为None。stride:步长,用来控制卷积核移动间隔,如果为x则水平和竖直方向的步长都为x,如果为(x, y)则竖直方向步长为x,水平方向步长为y。padding:在输入图像的边沿进行扩边操作,以保证图像输入输出前后的尺寸大小不变,在 PyTorch 的卷积层定义中,默认的padding为零填充,即在边缘填充0。padding_mode:扩边的方式。dilation:设定了取数之间的间隔。
例如:
import torch
import torch.nn.functional as F
input = torch.tensor([
[1, 2, 3, 0],
[0, 1, 2, 3],
[3, 0, 1, 2],
[2, 3, 0, 1]
])
kernel = torch.tensor([
[2, 0, 1],
[0, 1, 2],
[1, 0, 2]
])
input = torch.reshape(input, (1, 1, 4, 4)) # batch_size = 1,channel = 1
kernel = torch.reshape(kernel, (1, 1, 3, 3))
output = F.conv2d(input, kernel, stride=1)
print(output)
# tensor([[[[15, 16],
# [ 6, 15]]]])
output = F.conv2d(input, kernel, stride=1, bias=torch.tensor([3])) # 注意 bias 必须也是矩阵
print(output)
# tensor([[[[18, 19],
# [ 9, 18]]]])






![[附源码]计算机毕业设计springboot电商小程序](https://img-blog.csdnimg.cn/f64b56c793b84f528a8837f773a7f4e4.png)
![[附源码]计算机毕业设计Springboot大学生志愿者服务管理系统](https://img-blog.csdnimg.cn/dd196b4ca6d54952abd4bdc894f5f4bf.png)