LeetCode 1206. 设计跳表
难度: h a r d \color{red}{hard} hard
题目描述
不使用任何库函数,设计一个 跳表 。
跳表 是在 O ( l o g ( n ) ) O(log(n)) O(log(n)) 时间内完成增加、删除、搜索操作的数据结构。跳表相比于树堆与红黑树,其功能与性能相当,并且跳表的代码长度相较下更短,其设计思想与链表相似。
例如,一个跳表包含 [ 30 , 40 , 50 , 60 , 70 , 90 ] [30, 40, 50, 60, 70, 90] [30,40,50,60,70,90] ,然后增加 80 80 80、 45 45 45 到跳表中,以下图的方式操作:

Artyom Kalinin [CC BY-SA 3.0], via Wikimedia Commons
跳表中有很多层,每一层是一个短的链表。在第一层的作用下,增加、删除和搜索操作的时间复杂度不超过 O ( n ) O(n) O(n)。跳表的每一个操作的平均时间复杂度是 O ( l o g ( n ) ) O(log(n)) O(log(n)),空间复杂度是 O ( n ) O(n) O(n)。
了解更多 : https://en.wikipedia.org/wiki/Skip_list
在本题中,你的设计应该要包含这些函数:
- b o o l s e a r c h ( i n t t a r g e t ) bool search(int target) boolsearch(inttarget) : 返回target是否存在于跳表中。
- v o i d a d d ( i n t n u m ) void add(int num) voidadd(intnum): 插入一个元素到跳表。
- b o o l e r a s e ( i n t n u m ) bool erase(int num) boolerase(intnum): 在跳表中删除一个值,如果 n u m num num 不存在,直接返回false. 如果存在多个 n u m num num ,删除其中任意一个即可。
注意,跳表中可能存在多个相同的值,你的代码需要处理这种情况。
示例 1:
输入
["Skiplist", "add", "add", "add", "search", "add", "search", "erase", "erase", "search"]
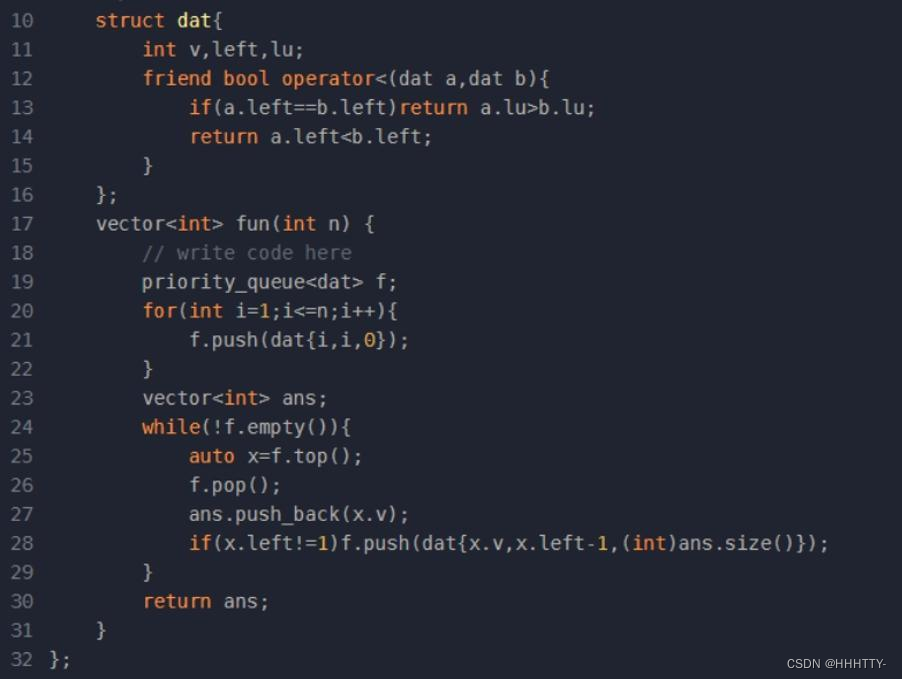
[[], [1], [2], [3], [0], [4], [1], [0], [1], [1]]
输出
[null, null, null, null, false, null, true, false, true, false]
解释
Skiplist skiplist = new Skiplist();
skiplist.add(1);
skiplist.add(2);
skiplist.add(3);
skiplist.search(0); // 返回 false
skiplist.add(4);
skiplist.search(1); // 返回 true
skiplist.erase(0); // 返回 false,0 不在跳表中
skiplist.erase(1); // 返回 true
skiplist.search(1); // 返回 false,1 已被擦除
提示:
- 0 < = n u m , t a r g e t < = 2 ∗ 1 0 4 0 <= num, target <= 2 * 10^{4} 0<=num,target<=2∗104
- 调用 s e a r c h search search, a d d add add, e r a s e erase erase操作次数不大于 5 ∗ 1 0 4 5 * 10^{4} 5∗104
算法
(数据结构-单链表)

首先需要定义链表的最大高度 level,这里取一个经验值 level=8,Redis 中设置是 32。
我们可以看到 head 节点在每一层都会连接一个链表,由上图引出跳表节点的结构:
-
节点值
val -
存储当前节点在每一层的
next指针,方便我们操作(为了方便理解我们可以把图中每个节点的高度都看成level,没在图中画出来的就是指向NULL,而它们的值都是相同的val。
节点结构代码实现:
// 定义跳表节点
struct Node {
int val; // 节点值
vector<Node*> next; // 记录节点在每一层的 next,next[i] 表示当前节点第 i 层的 next
Node(int _val) : val(_val) { // 构造函数
next.resize(level, NULL); // 初始化 next 数组的大小和层数 level 相同,初始值都指向 NULL
}
}*head; // 定义头节点 head
搞清楚节点结构之后,下面就好办了,不管是查找、插入、删除都需要先找到目标值或者找到目标值的前一个节点,那么这里我们统一设计一个辅助函数 find():找到小于目标值的最大的节点,由于跳表是多层链表结构,所以要找的不是一层而是每一层。
find() 函数代码实现:
// 辅助函数:找到每一层 i 小于目标值 target 的最大节点 pre[i],最后 pre 中存的就是每一层小于 target 的最大节点
void find(int target, vector<Node*>& pre) {
auto p = head; // 从头节点开始遍历每一层
for (int i = level - 1; i >= 0; i -- ) { // 从上层往下层找
while (p->next[i] && p->next[i]->val < target) p = p->next[i]; // 如果当前层 i 的 next 不为空,且它的值小于 target,则 p 往后走指向这一层 p 的 next
pre[i] = p; // 退出 while 时说明找到了第 i 层小于 target 的最大节点就是 p
}
}
有了辅助函数之后,如何实现查找、插入、删除操作呢?不管是哪种操作首先调用 find() 得到每一层小于目标值的最大节点数组 pre
1、查找 search():由于第 0 层的数据是最全的,所以只需要在第 0 层查找是否存在即可,代码如下:
// 从跳表中查找 target
bool search(int target) {
vector<Node*> pre(level);
find(target, pre); // 先找到每一层 i 小于目标值 target 的最大节点 pre[i]
auto p = pre[0]->next[0]; // 因为最下层【0】的节点是全的,所以只需要判断 target 是否在第 0 层即可,而 pre[0] 正好就是小于 target 的最大节点,如果 pre[0]->next[0] 的值不是 target 说明没有这个元素
return p && p->val == target;
}
2.、插入 insert():新建要插入的节点,从第 0 层开始插入,往上每层 50% 的插入,50% 的概率不插入,相当于两个点中有一个在上层插入(当然这并不一定),只不过这样较好实现,理论上是一样的。具体插入操作就是单链表插入,代码如下:
// 向跳表中插入元素 num
void add(int num) {
vector<Node*> pre(level);
find(num, pre); // 先找到每一层 i 小于目标值 target 的最大节点 pre[i]
auto p = new Node(num); // 创建要插入的新节点
for (int i = 0; i < level; i ++ ) { // 遍历每一层,从下往上插入新节点
p->next[i] = pre[i]->next[i]; // 这两步就是单链表的插入
pre[i]->next[i] = p;
if (rand() % 2) break; // 每一层有 50% 的概率不插入新节点
}
}
3、删除 erase():因为是多层结构,所以需要把每一层等于目标值的节点都删除,具体删除操作就是单链表删除,代码如下:
// 从跳表中删除 num
bool erase(int num) {
vector<Node*> pre(level);
find(num, pre); // 先找到每一层 i 小于目标值 target 的最大节点 pre[i]
// 先判断 num 是否存在,不存在直接返回 false
// 第 0 层存储的是全部节点,所以只需要判断 pre[0]->next[0](第 0 层小于 num 的最大节点的在第 0 层的 next) 是不是 num 即可
auto p = pre[0]->next[0];
if (!p || p->val != num) return false;
// 否则删除每一层的 num,如果 pre[i]->next[i] == p 说明第 i 层存在 p
for (int i = 0; i < level && pre[i]->next[i] == p; i ++ ) {
pre[i]->next[i] = p->next[i]; // 单链表删除
}
delete p; // 删除节点 p,防止内存泄漏
return true;
}
复杂度分析
- 时间复杂度:查询、删除、插入的时间复杂度近似 O ( l o g n ) O(logn) O(logn)
C++ 代码
class Skiplist {
public:
static const int level = 8; // 层数,经验值 8,太大浪费空间,因为每一个节点都要存在每一层的 next,层数越多节点数越多
// 定义跳表节点
struct Node {
int val; // 节点值
vector<Node*> next; // 记录节点在每一层的 next,next[i] 表示当前节点第 i 层的 next
Node(int _val) : val(_val) { // 构造函数
next.resize(level, NULL); // 初始化 next 数组的大小和层数 level 相同,初始值都指向 NULL
}
}*head; // 定义头节点 head
Skiplist() {
head = new Node(-1); // 初始化一个不存在的节点值 -1
}
~Skiplist() {
delete head; // 析构函数删除 head
}
// 辅助函数:找到每一层 i 小于目标值 target 的最大节点 pre[i],最后 pre 中存的就是每一层小于 target 的最大节点
void find(int target, vector<Node*>& pre) {
auto p = head; // 从头节点开始遍历每一层
for (int i = level - 1; i >= 0; i -- ) { // 从上层往下层找
while (p->next[i] && p->next[i]->val < target) p = p->next[i]; // 如果当前层 i 的 next 不为空,且它的值小于 target,则 p 往后走指向这一层 p 的 next
pre[i] = p; // 退出 while 时说明找到了第 i 层小于 target 的最大节点就是 p
}
}
// 从跳表中查找 target
bool search(int target) {
vector<Node*> pre(level);
find(target, pre); // 先找到每一层 i 小于目标值 target 的最大节点 pre[i]
auto p = pre[0]->next[0]; // 因为最下层【0】的节点是全的,所以只需要判断 target 是否在第 0 层即可,而 pre[0] 正好就是小于 target 的最大节点,如果 pre[0]->next[0] 的值不是 target 说明没有这个元素
return p && p->val == target;
}
// 向跳表中插入元素 num
void add(int num) {
vector<Node*> pre(level);
find(num, pre); // 先找到每一层 i 小于目标值 target 的最大节点 pre[i]
auto p = new Node(num); // 创建要插入的新节点
for (int i = 0; i < level; i ++ ) { // 遍历每一层,从下往上插入新节点
p->next[i] = pre[i]->next[i]; // 这两步就是单链表的插入
pre[i]->next[i] = p;
if (rand() % 2) break; // 每一层有 50% 的概率不插入新节点
}
}
// 从跳表中删除 num
bool erase(int num) {
vector<Node*> pre(level);
find(num, pre); // 先找到每一层 i 小于目标值 target 的最大节点 pre[i]
// 先判断 num 是否存在,不存在直接返回 false
// 第 0 层存储的是全部节点,所以只需要判断 pre[0]->next[0](第 0 层小于 num 的最大节点的在第 0 层的 next) 是不是 num 即可
auto p = pre[0]->next[0];
if (!p || p->val != num) return false;
// 否则删除每一层的 num,如果 pre[i]->next[i] == p 说明第 i 层存在 p
for (int i = 0; i < level && pre[i]->next[i] == p; i ++ ) {
pre[i]->next[i] = p->next[i]; // 单链表删除
}
delete p; // 删除节点 p,防止内存泄漏
return true;
}
};
/**
* Your Skiplist object will be instantiated and called as such:
* Skiplist* obj = new Skiplist();
* bool param_1 = obj->search(target);
* obj->add(num);
* bool param_3 = obj->erase(num);
*/
备注
转载自 LeetCode 1206. 设计跳表





![[Java]Cookie机制](https://img-blog.csdnimg.cn/img_convert/95a3396126b1e8d1a4e426a61b924cb7.webp?x-oss-process=image/format,png)




![[CVE漏洞复现系列]CVE2017_0147:永恒之蓝](https://img-blog.csdnimg.cn/ce05a22ec04d4f6b82b5389b40a178c1.png#pic_center)