目录
GPT
无监督预训练
有监督微调
如何将模型应用于下游任务?
试验结果
GPT-2
摘要
Introduction
Approach
数据集&模型
试验结果
GPT-3
核心点
名词解释
few-shot做法图示
数据集
GPT
由无监督预训练+有监督微调组成
-
无监督预训练

-
有监督微调

-
如何将模型应用于下游任务?
做法是在Transformer输出层后增加线性层
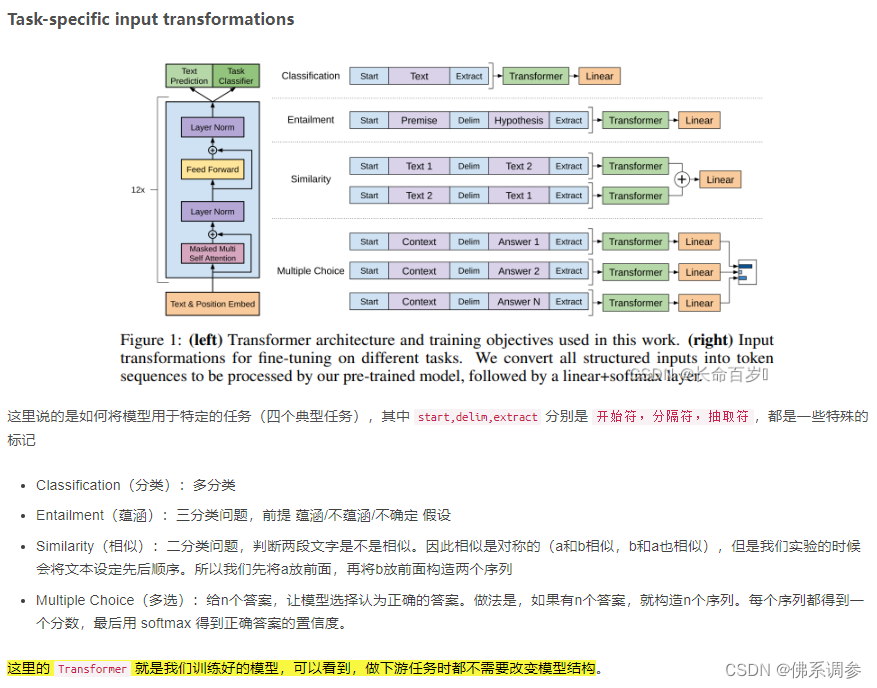
-
试验结果

GPT-2
论文:Language Models are Unsupervised Multitask Learners
注:标题里的多任务学习是指模型同时在NLP中的多个任务上进行学习
-
摘要
用了 WebText,有百万级别的文本,最大的 GPT-2 模型有 1.5B 参数。
本文的主要卖点是 zero-shot。
-
Introduction
之前主流任务都是在一个任务上收集一个数据集,然后来训练。这是因为,当前模型的泛化性都不是很好。Bert和GPT提出后,主流是在大的数据集上进行预训练,然后对子任务再 fine-tune。这仍然有两个问题:
- 在子任务上还是需要重新训练模型
- 需要针对子任务收集数据集,这导致,模型在扩展到新任务时开销是比较大的。
GPT-2 还是做语言模型,但是在扩展到下游任务时,会有 zero-shot 的设定,不需要再重新训练模型
-
Approach
GPT中,在微调的时候引入了开始符,间隔符等特殊符号,这些是模型在预训练时候没有见到过的(微调的时候会进行学习)。现在 GPT-2 要做的是 zero-shot,模型在做下游任务时不能进行微调,因此不能引入这些特殊符号,否则模型就会很困惑,输入的形式应该更像自然语言,和之前相似。
这就引入了 prompt(McCann et al 2018年提出),用一些自然语言来充当一些符号的作用。
- 比如翻译任务,可以写成一个序列:translate to french, english text, french text。这里既有明显的起始,分隔,又是正常的自然语言
- 比如阅读理解任务,可以写成:answer the question, document, question, answer 。是同样的道理
为什么可以工作(可能):
- 模型足够强大,能够理解提示符
- 在文本里面,这样的话可能也很常见
-
数据集&模型
数据:Common Crawl是一个网页抓取项目,抓取网页供大家下载。但是信噪比低,有些网页可能就是垃圾网页。因此最终使用了 Reddit(算是一些已经过滤好的网页),最后得到4500万个链接,最终的数据集有800w文本,40GB。
因为数据量很大了,因此可以设计更大的模型。一共设计了 4 个。

-
试验结果
和别的zero-shot方法比,性能是提升的
在NLP的一些任务上还不错,一些任务上差一些。但是随着模型大小的增加,性能还是呈上升的趋势。
GPT-3
论文:Language Models are Few-shot Leaners
-
核心点
- 采用few-shot
- 尽管few-shot会给少量带标签的样本,但GPT-3在预训练之后,不做任何的梯度更新or微调
-
名词解释
- meta-learning,元学习:作者取名不是很精确,作者大致意思是训练一个很大的模型,并且泛化性能还不错
- in-context learning,上下文学习:在推理的时候,即使给一些带标注的样本,也不对模型权重进行更新或者微调。
-
few-shot做法图示
图中的箭头叫做prompt(提示),告诉模型接下来该你输出了
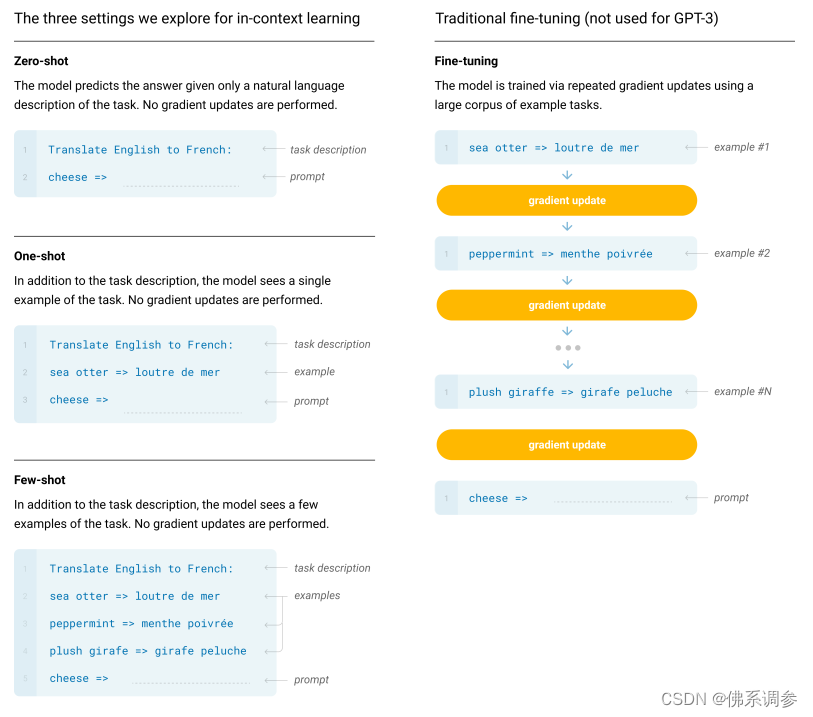
-
数据集
Common Crawl数据集量很大,但是大部分文章质量都比较低,因此需要进行处理
1.训练一个二分类模型(逻辑回归),redit数据集作为正例,Crawl数据集作为负例。训练好分类器之后对Common Crawl数据集做预测,如果预测偏正例的话就保留,如果预测偏负例的话就过滤掉。
2.去重,采用lsh算法判断两篇文章(两个集合)的相似性,去除相似度高的
3.增加已知的高质量数据集,比如BERT,GPT, GPT-2采用的所有数据集
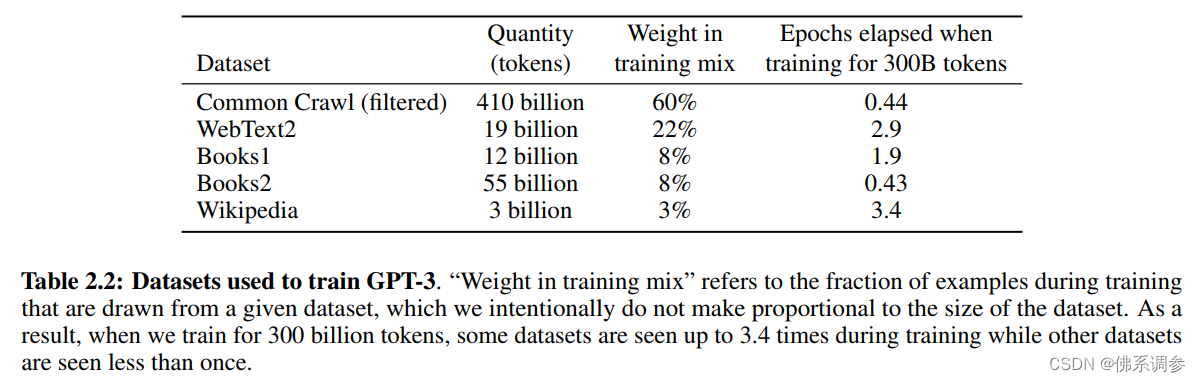
可以看到,虽然Common Crawl数据集tokens非常多,但在训练过程中的采用只占60%,即训练时不是平等对待每一个数据集的
InstructGPT
论文:Training language models to follow instructions with human feedback, 2022.03
训练主要是两大核心技术点
1. Instruct Tuning(指令微调)
2. 基于人工反馈的强化学习(Reinforcement learning from Human Feedback, RLHF)
ChatGPT
只有blog,没有官方论文,官方说和InstructGPT是兄弟模型
- 训练
基本上分成三大步骤(具体是四步)
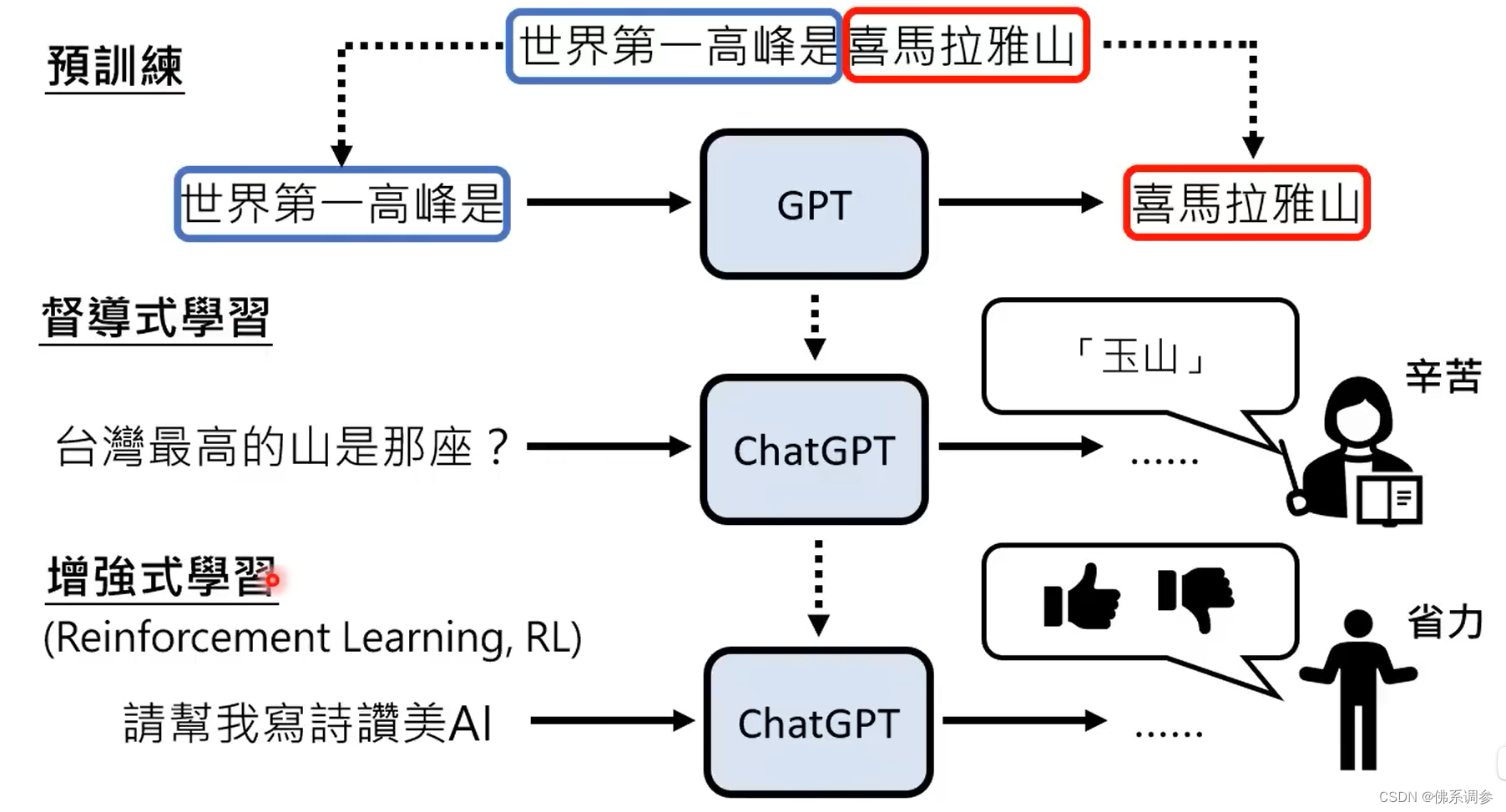
预训练的一个大作用:
在多种语言上做预训练后,只要教某一种语言的某一个任务,大模型会自动学习其他语言的相同任务
四个详细步骤
1.预训练,学习文字接龙
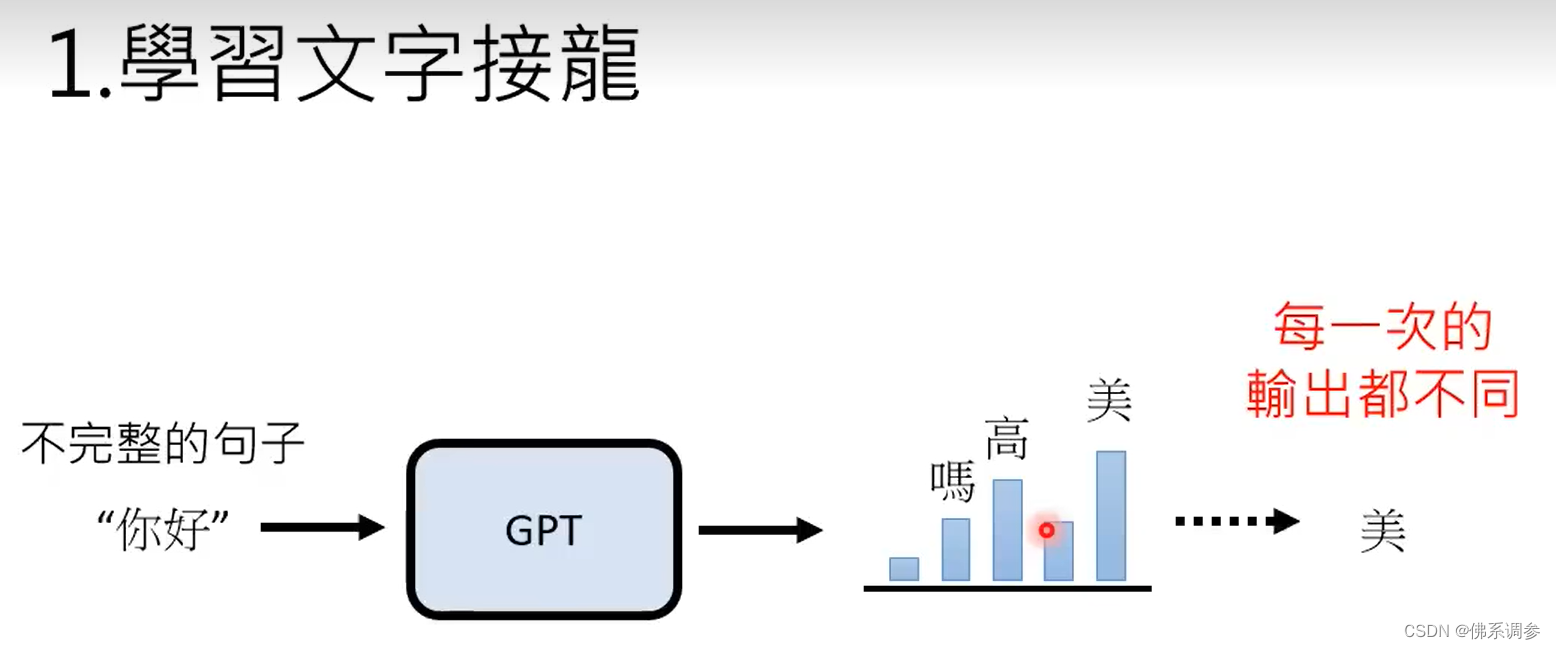
在推理时候,每一次输出是不同的,因此GPT的直接输出是概率分布,然后从概率分布中进行采样,概率大的词更容易被采样到,但每次并不是取概率最大的词作为输出
2. 人类老师引导文字接龙的方向
不需要穷举,即不需要标注太多的符合人类理解的语句,每种问题提供一些正确范例就行了,因为在第一阶段预训练大模型其实也已经部分学习到这些了。

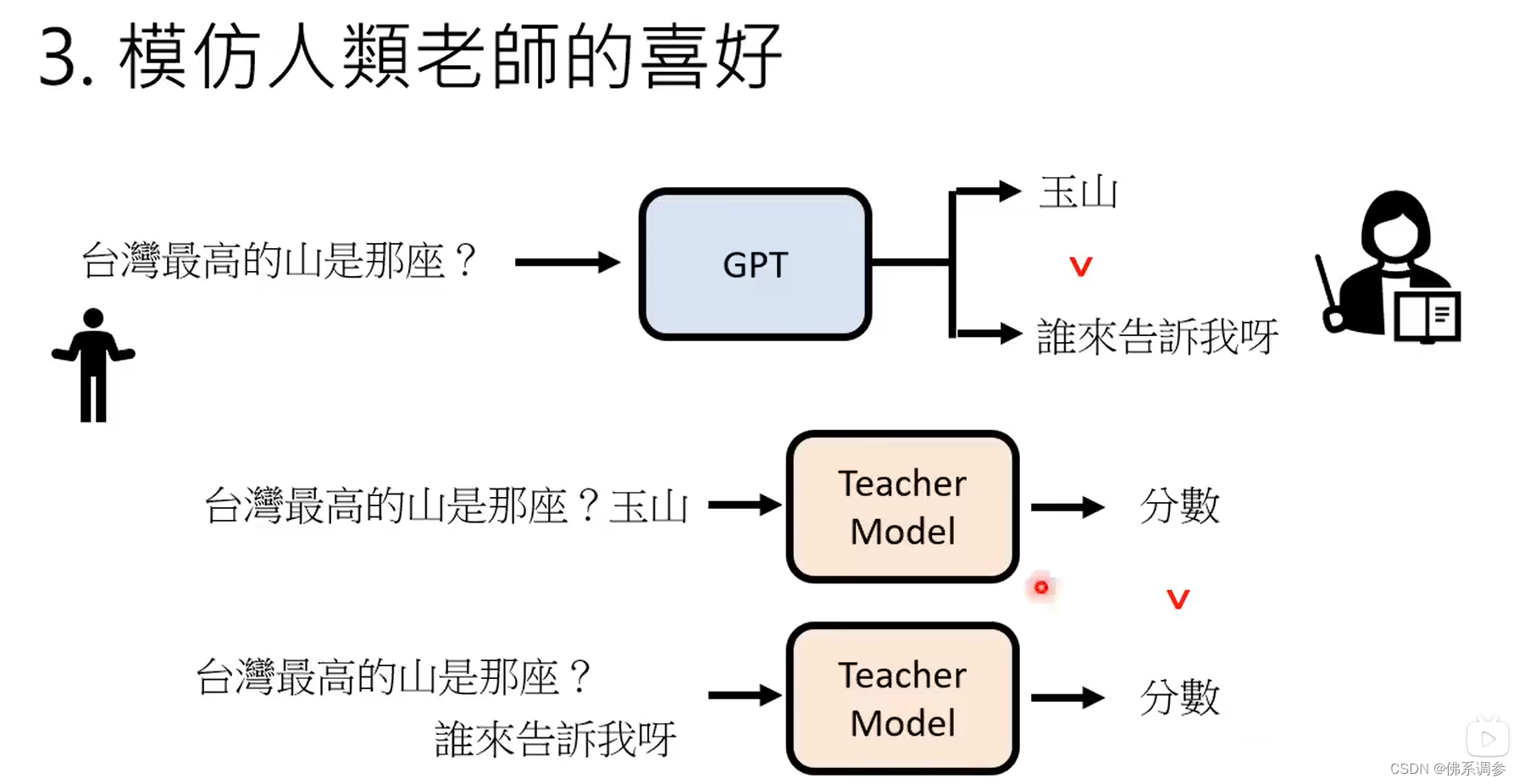
3. 模仿人类老师的喜好
ChrtGPT 的API之前已经公开,openAI收集了很多人类问题,因为ChatGPT是具有随机性的,因此同一个问题会输出多种答案,然后雇佣人类对每个问题的不同答案进行评分(人类老师不需要提供正确答案,只需要评分)
接下来训练一个教师模型,来自动对每个问题的每个答案进行评分,从而让教师模型模仿人类的偏好
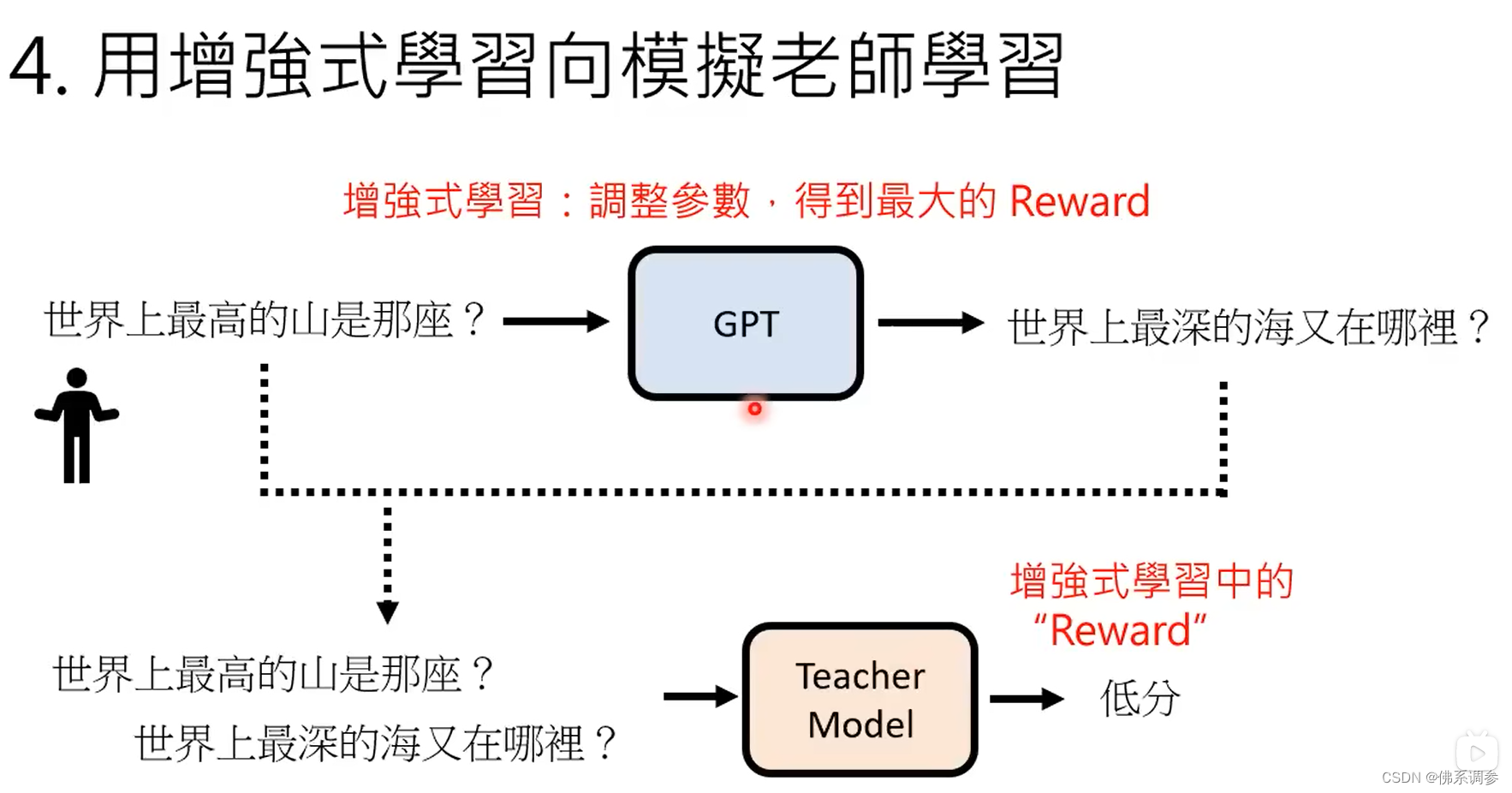
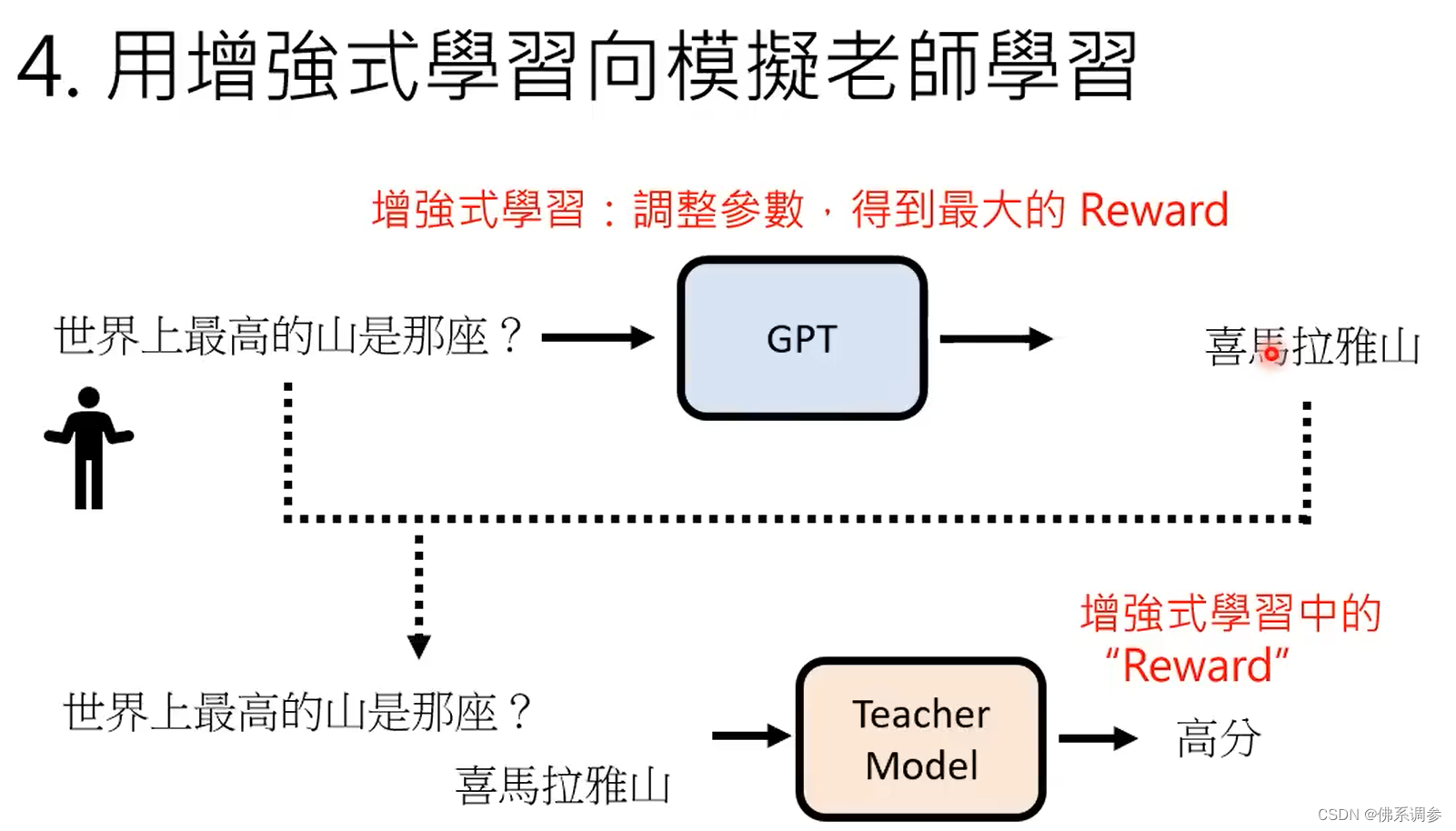
4. 用强化学习RL向模仿老师学习
将问题和chatGPT的回答一起输入到教师模型中,将教师模型输出的分数作为强化学习中的reward,调整chatGPT的参数,从而使得教师模型得到最大的reward。
模型大小与训练集总结
| 模型 | 发布日期 | 模型参数大小 | 训练集大小 |
|---|---|---|---|
| GPT | 2018. | 117M (0.117B) | 1GB |
| GPT-2 | 2019 | 1.5B (1542M) | 40GB |
| GPT-3 | 2020 | 175B | 570GB |
| InstructGPT | 2022.03 | ||
| ChatPT | 2022 | ||
| GPT-4 | |||