【创建随机点】工具位于【采样】工具下,如下所示:
假如我们有一个需求,要在很多数据里随机选择10个数据,就可以使用该工具。
假如我这里有全国的县级数据,我想要在里面随机抽选10个县城。
原始数据如下:

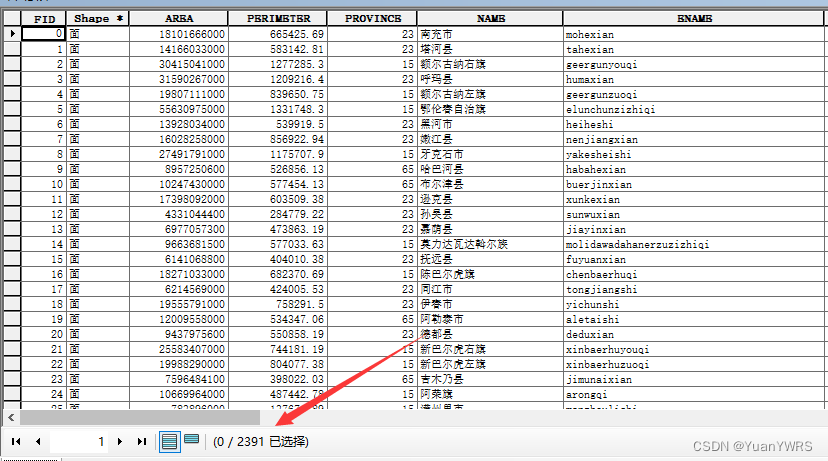
总共有2391个县,我们随机从里面抽取10个。
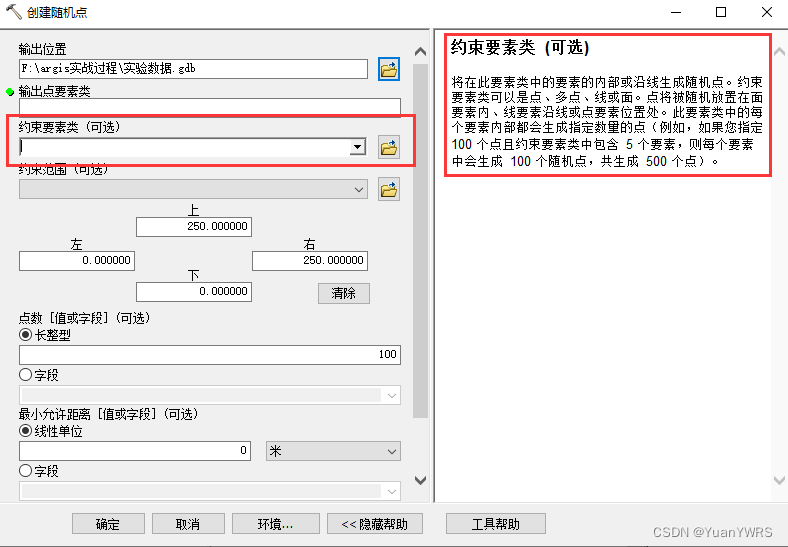
【创建随机点】工具里有一个设置是【约束要素类】,也就是我们所说的界限,是随机点生成的大范围线,所以我们先把以上的2391条数据进行【融合】操作,以得到一个大范围线。

【融合】工具位于【地理处理】下,注意在进行融合设置时,不要勾选【字段】里的任何内容,否则就会按照所选字段进行融合,而得不到大范围了。处理后的结果如左侧箭头所示,为中国的最大范围。
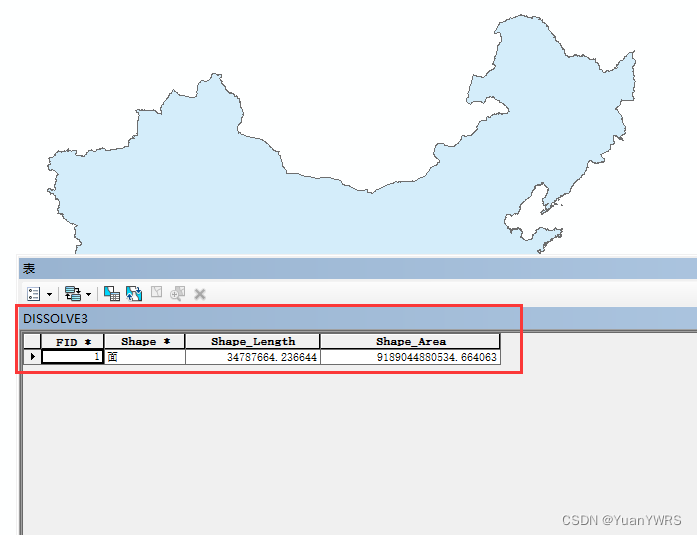
可以看到这个面数据没什么可使用的字段信息。
如果我们在融合时选择了某一字段,比如NAME,以地名进行融合,得到的结果就不是我们想要的大范围界限。
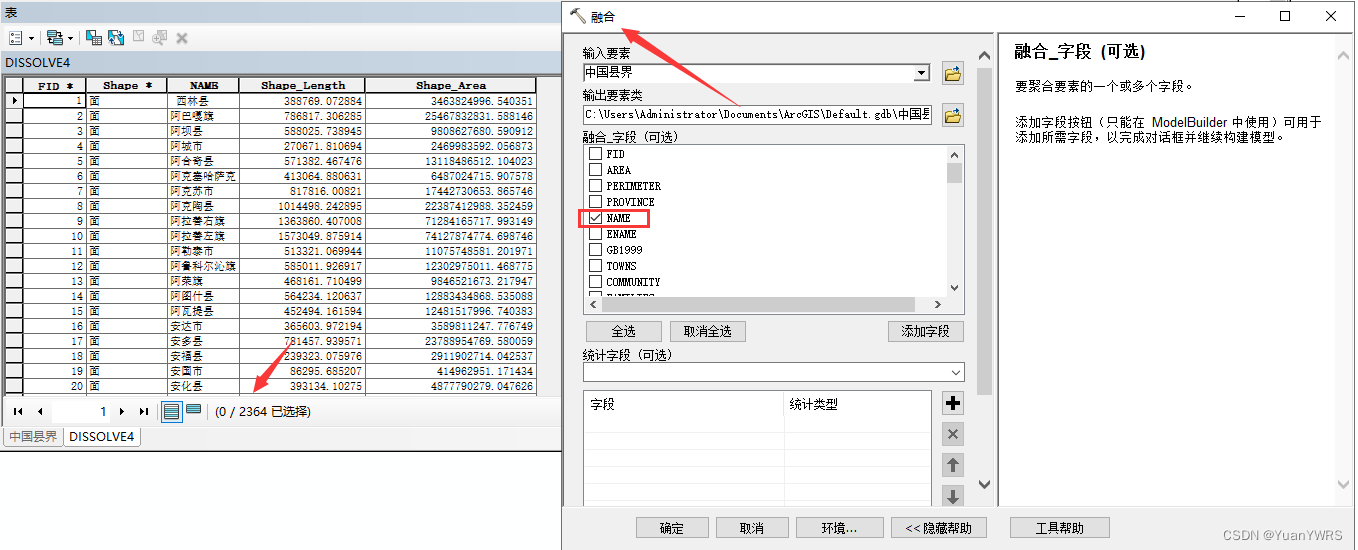

上图是处理结果。
然后进行创建随机点操作:
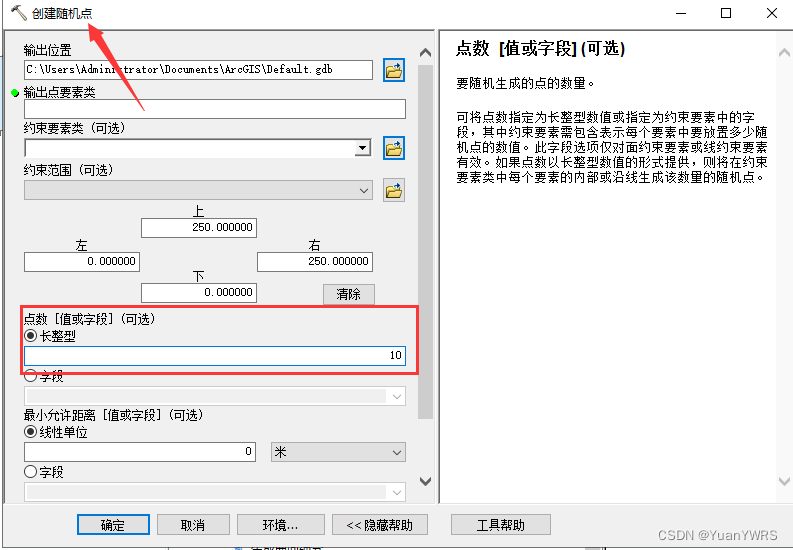
进行创建随机点的操作,在【点数】里选择10,表示会生成10个随机点。

如上图是生成的10个随机点。
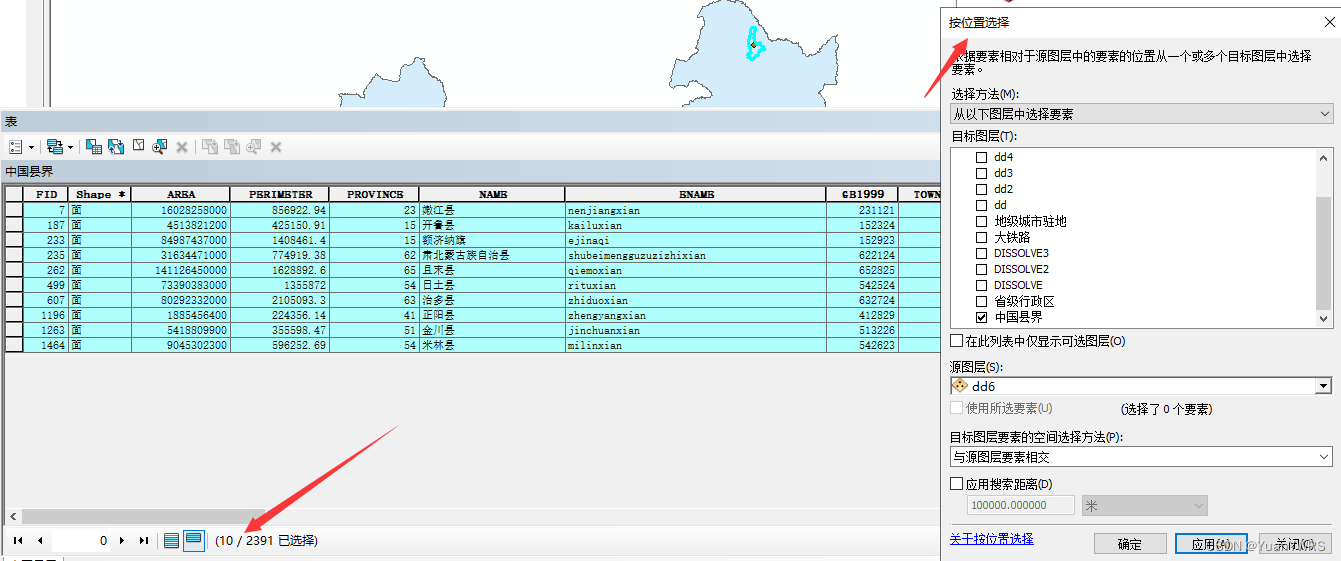
通过【按位置选择】空间叠加操作,可以在2391个数据里随机的选择了我们需要的10个县城。

如上所示为选择结果。
【但是】:
如果我们把随机点的【点数】设置为50,结果会怎样呢?
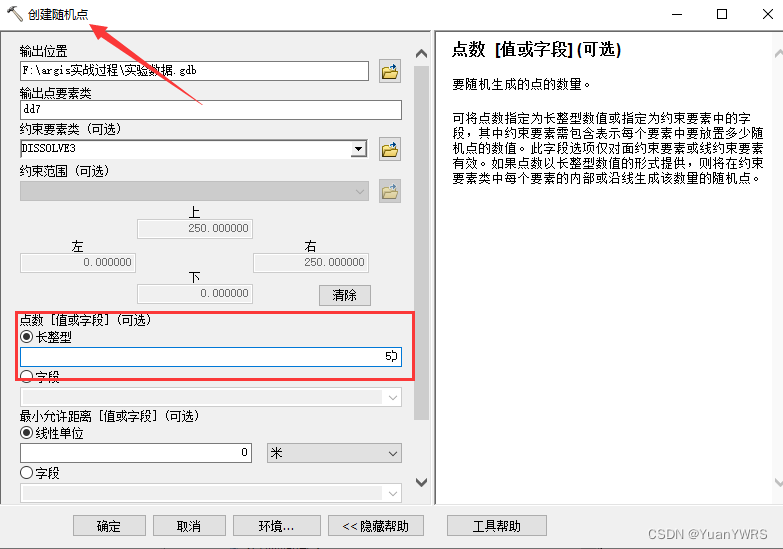

以上是生成的50个随机点位。

但是进行空间位置叠加后发现,只能选择44个县城,这表明,有几个点位在同一个县城里。
因此,这个功能的使用,对于点位的选择是有要求的,总体数据数量不大,点位生成过多,就会造成实验失败的情况。
所以在使用这个功能时,要对数据总量和生成点位个数进行合理评估。

![[附源码]Python计算机毕业设计高校教材网上征订系统](https://img-blog.csdnimg.cn/5dc8be79f0fc4997b53ebd4fa5f77014.png)