创建数据库
mysql全表数据导入hdfs
mysql查询数据导入hdfs
mysql指定列导入hdfs
使用查询条件关键字将mysql数据导入hdfs
mysql数据导入hive
创建数据库
hive中创建user表
create table users(
id bigint,
name string
)
row format delimited fields terminated by "\t";mysql中创建user表并添加信息
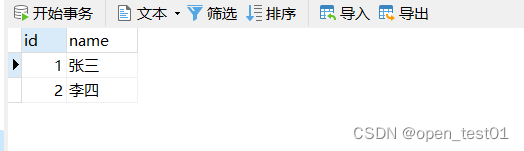
CREATE TABLE `user` (
`id` int(20),
`name` varchar(20)
);
mysql全表数据导入hdfs
全部导入
bin/sqoop import \
--connect jdbc:mysql://master:3306/spark-sql \
--username root \
--password p@ssw0rd \
--table user \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t"参数解读:
bin/sqoop import \ 导入命令
--connect jdbc:mysql://master:3306/spark-sql \ 选择数据源的mysql数据库路径
--username root \ mysql用户名
--password p@ssw0rd \ mysql用户密码
--table user \ 数据源表名
--target-dir /user/company \ 导入到的hdfs路径
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t"
hdfs中查看导入的结果
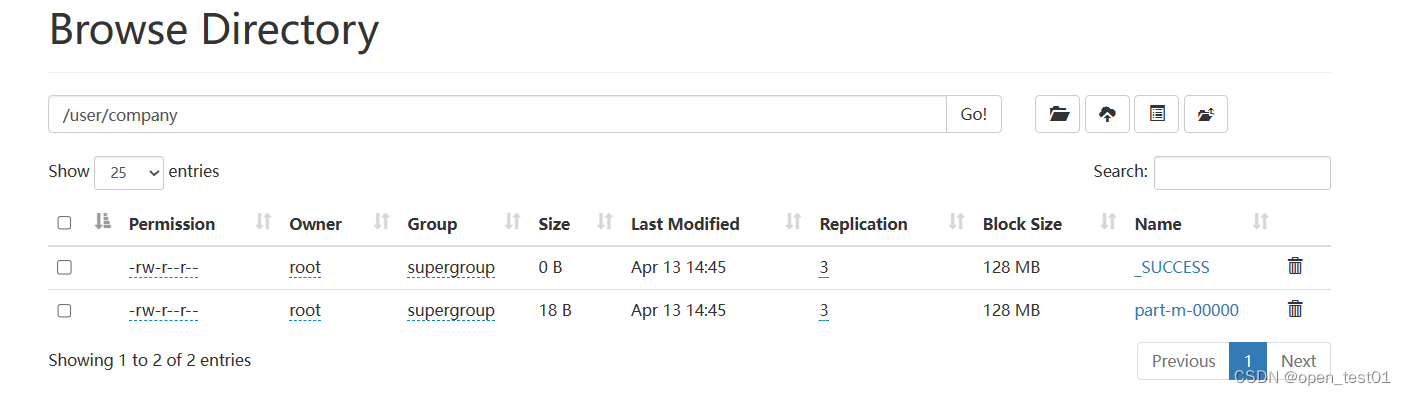
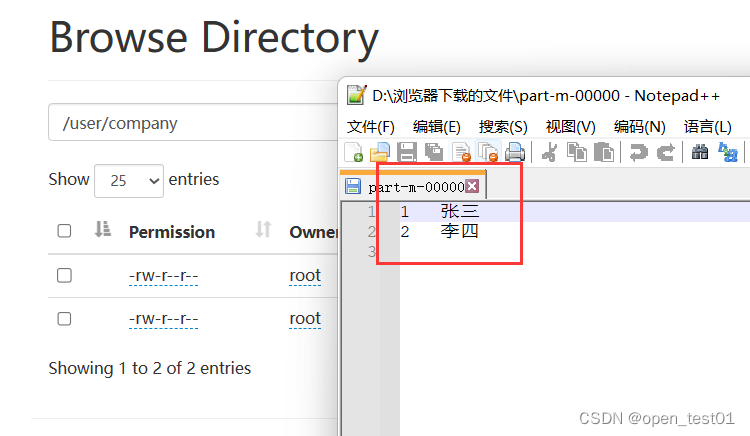
mysql查询数据导入hdfs
注意:使用查询导入时必须要在查询语句后面加上 $CONDITIONS
bin/sqoop import \
--connect jdbc:mysql://master:3306/spark-sql \
--username root \
--password p@ssw0rd \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
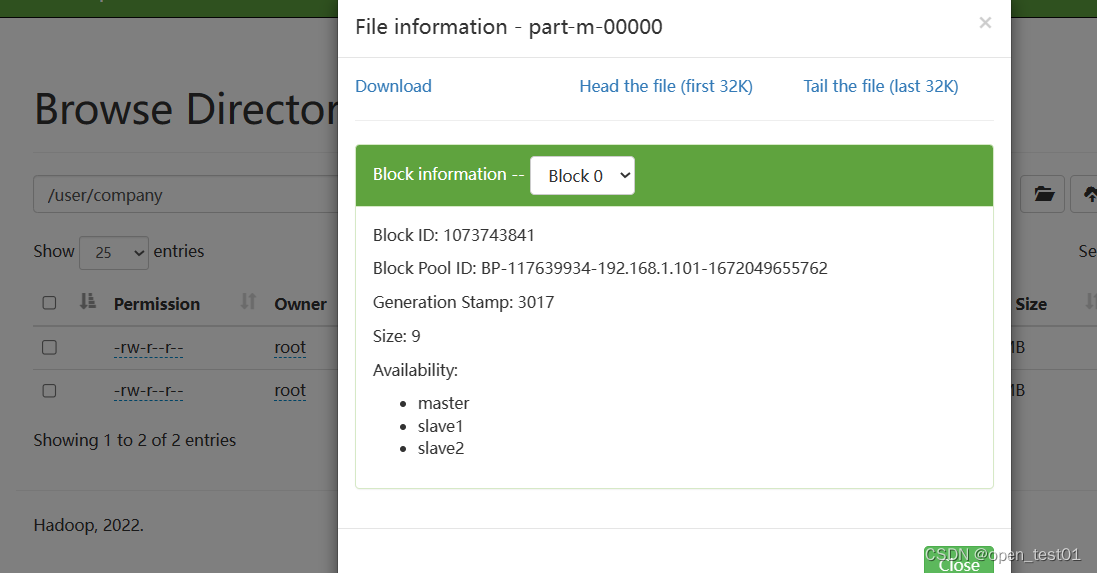
--query 'select * from user where id = 2 and $CONDITIONS;'
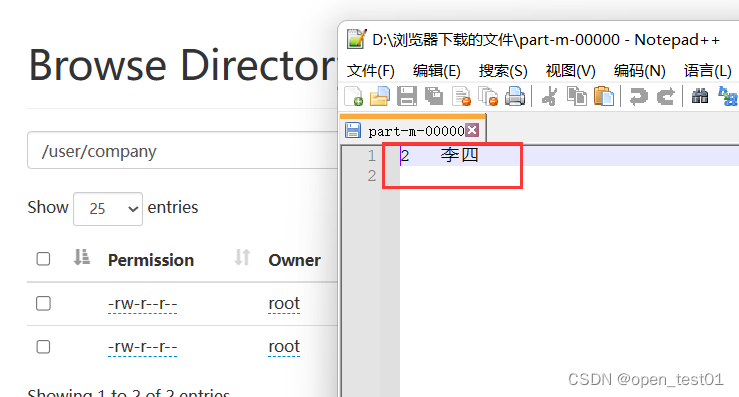
hdfs中查看导入的结果
mysql指定列导入hdfs
使用 --columns 来指定导入的列
bin/sqoop import \
--connect jdbc:mysql://master:3306/spark-sql \
--username root \
--password p@ssw0rd \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--columns name \
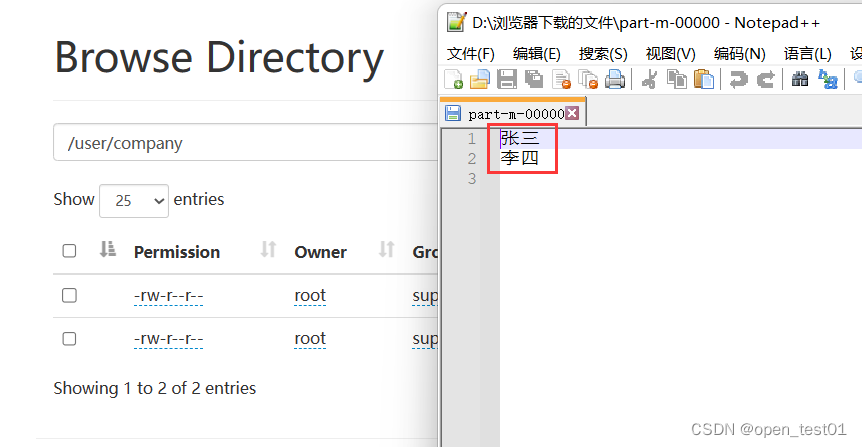
--table userhdfs中查看导入的结果
使用查询条件关键字将mysql数据导入hdfs
使用 --where来指定查询的条件
bin/sqoop import \
--connect jdbc:mysql://master:3306/spark-sql \
--username root \
--password p@ssw0rd \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--table user \
--where "id=1"
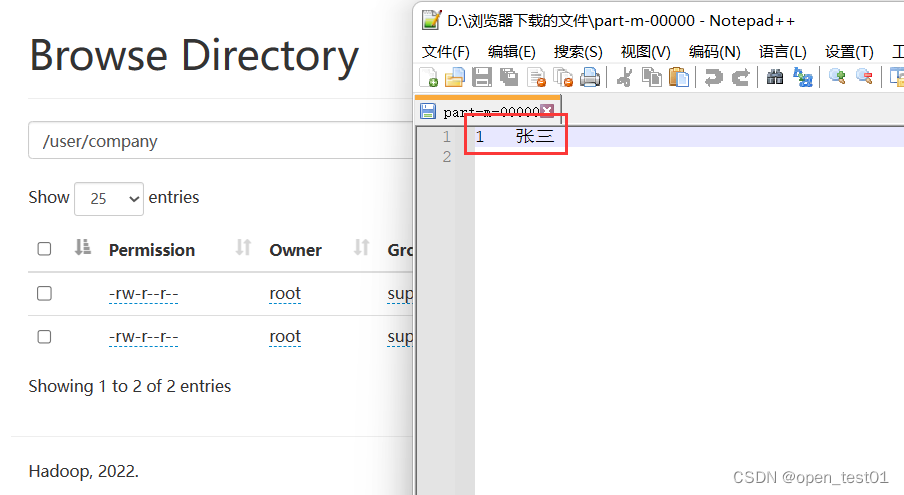
hdfs中查看导入的结果
mysql数据导入hive
其实将mysql导入hive中 在中间还是在hdsf中中转存储了一下 然后在从hdfs导入到hive中
bin/sqoop import \
--connect jdbc:mysql://master:3306/spark-sql \
--username root \
--password p@ssw0rd \
--table user \
--num-mappers 1 \
--hive-import \
--fields-terminated-by "\t" \
--hive-overwrite \
--hive-table default.users参数解读:
--hive-import \ 导入hive的命令
--hive-overwrite \ 写入方式
--hive-table default.users hive表 指定数据库中的表:数据库.表

在hive中查看导入结果
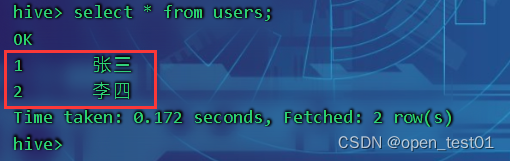
导入hive并添加分区字段
sqoop import \
--connect jdbc:mysql://mysql_host/mydatabase \
--username mysql_username \
--password mysql_password \
--table my_table \
--hive-import \
--create-hive-table \
--hive-table my_db.my_table \
--hive-partition-key part_col \
--hive-partition-value '2023-04-13' \
--target-dir /user/hive/warehouse/my_db.db/my_table/part_col=2023-04-13;


![【论文阅读】[JBHI] VLTENet、[ISBI]](https://img-blog.csdnimg.cn/21f47ce9df0949a9bc686ce00d25bba0.png)