这篇文章,主要介绍微服务组件之Hystrix实现请求合并功能。
目录
一、Hystrix请求合并
1.1、什么是请求合并
1.2、请求合并的实现
(1)引入依赖
(2)编写服务提供者
(3)消费者(Service层代码)
(4)消费者(Controller层代码)
(5)测试请求合并
一、Hystrix请求合并
1.1、什么是请求合并
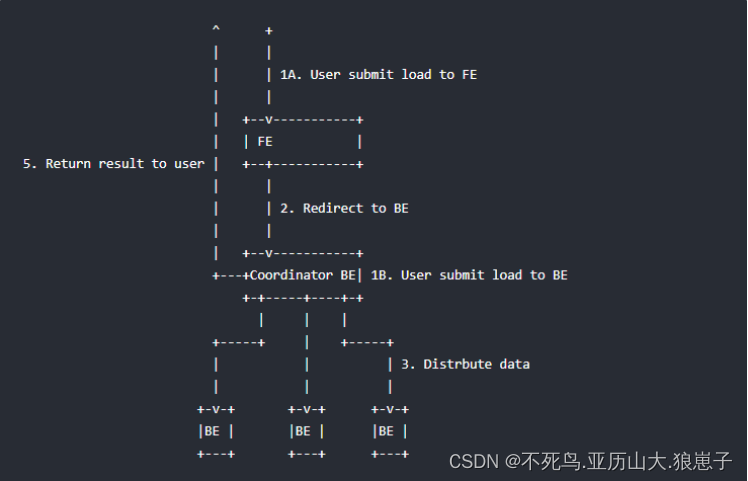
微服务和微服务之间的调用,都是需要建立通信连接的,就拿HTTP接口来说,每一次的通信都需要建立和断开连接,如果微服务之间的调用非常频繁,那就会有很多的连接在建立和断开,为了减少请求连接的数量,Hystrix提出了请求合并的功能。
请求合并,也就是将多个相同的请求合并成一个请求,然后只调用一次接口将所有的数据获取到,数据拿到之后,还需要将数据一次分发给合并之前的请求,这样每一个请求才能够正常的拿到属于自己的那一个返回结果。
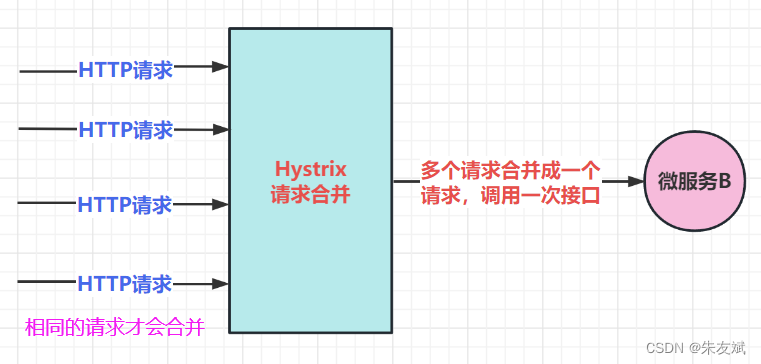
当开启请求合并之后,Hystrix针对那些相同的URI请求,会将其合并成一个请求,然后再去调用微服务接口,通过这里就可以看到,请求合并之后,原先多次调用的接口,现在只需要一次接口调用,减少了很多的请求连接,这也就能够提高系统的高可用性。
要实现请求合并,下游系统必须支持批处理接口,因为原先单次调用的接口,结果请求合并之后也就相当于是将多个接口的请求参数放到了一个接口里面,这样下游系统就必须能够支持批量处理多个请求参数的数据查询。
使用请求合并,一般来说,也就是针对查询类的接口,相当于下游系统要支持批量查询功能。到这你是不是想问,既然下游系统支持批量查询,那我直接调用批量查询接口不就可以了吗,干嘛还有多次一举,使用请求合并呢???
- 首先你要明白,你一个用户发起的接口,你直接调用批处理接口,那确实可以。
- 但是互联网中,一个应用系统存在很多的用户,每一个用户都可能调用相同的接口查询不同的数据,这个时候,请求合并就起作用啦。
要实现请求合并,可以使用【@HystrixCollapser】注解和【@HystrixCommand】注解。@HystrixCollapser 注解:指定某个方法需要开启请求合并功能。@HystrixCommand 注解:标记某个方法作为 Hystrix 的命令。
1.2、请求合并的实现
(1)引入依赖
- 在服务消费者端,引入hystrix的依赖。
<!--hystrix 依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>(2)编写服务提供者
前面说了,要实现请求合并功能,下游系统必须提供批处理的接口,所以在这里,服务提供者需要提供一个批量查询的接口。
package com.gitcode.hystrix.controller;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
/**
* @version 1.0.0
* @Date: 2023/4/9 10:11
* @Copyright (C) ZhuYouBin
* @Description: hystrix 请求合并
*/
@RestController
@RequestMapping("/hystrix/provider")
public class CollapseController {
/**
* 根据id批量查询
*/
@PostMapping("/hystrixCollapse")
public List<String> hystrixCollapse(@RequestBody List<String> ids) {
List<String> ans = new ArrayList<>();
// 这里模拟批处理的过程
ids.forEach(key -> {
ans.add("这是key=" + key + "的响应结果.");
});
return ans;
}
}
(3)消费者(Service层代码)
- 在消费者的Service服务层中,我们需要使用【@HystrixCollapser】注解和【@HystrixCommand】注解,声明需要实现请求合并的方法。
- 【@HystrixCollapser】注解:使用在需要开启请求合并的方法上面。
- 【@HystrixCommand】注解:使用在请求合并之后,执行批处理的接口方法上面。
package com.gitcode.hystrix.service;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCollapser;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixProperty;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
import java.util.List;
import java.util.concurrent.Future;
/**
* @version 1.0.0
* @Date: 2023/4/9 10:16
* @Copyright (C) ZhuYouBin
* @Description: Hystrix 请求合并
*/
@Service
public class HystrixCollapseService {
@Autowired
private RestTemplate restTemplate;
/**
* 根据ID查询
*/
@HystrixCollapser(collapserKey = "请求合并的唯一key",
// 作用域: 这里设置成全局的
scope = com.netflix.hystrix.HystrixCollapser.Scope.GLOBAL,
// 批处理方法: 当请求合并之后, hystrix 会调用这个批处理方法发起接口的调用【这个方法是自己写的】
batchMethod = "batchQueryData",
// 请求合并的属性: 满足什么条件才进行请求合并
collapserProperties = {
// 定义属性
// timerDelayInMilliseconds: 在指定时间内的所有相同请求,都将被请求合并, 单位毫秒, 默认10ms
// 200 毫秒内的请求将全部被合并
@HystrixProperty(name = "timerDelayInMilliseconds", value = "5000"),
// maxRequestsInBatch: 请求合并最大的请求数量,当到达这个数量之后,就会执行一次请求合并
@HystrixProperty(name = "maxRequestsInBatch", value = "4"),
}
)
// TODO 需要注意的是,请求合并的方法返回值必须是:Future 类型
public Future<String> queryById(String id) {
// 这个方法没啥作用了,所以不需要方法体,因为单个请求都将合并,之后统一的调用批处理方法
System.out.println("调用queryById方法......");
return null;
}
/**
* 请求合并之后的批处理方法
*/
@HystrixCommand
private List<String> batchQueryData(List<String> ids) {
// 在这里实现批量请求的调用
String url = "http://127.0.0.1:5678/hystrix/provider/hystrixCollapse";
final List<String> list = restTemplate.postForObject(url, ids, List.class);
System.out.println("调用batchQueryData批处理接口......");
return list;
}
}
- PS:这里留下一个疑问,Hystrix是怎么知道批量接口中,哪些数据应该是哪些请求的响应结果。
(4)消费者(Controller层代码)
在controller控制层,我们就只需要调用Service层的queryById()方法查询数据就可以啦,由于这个方法是Future类型,所以调用【Future.get()】方法就可以获取到返回值,需要注意的是:get()方法是阻塞的,返回值没有准备好,会一直处于阻塞等待状态。
package com.gitcode.hystrix.controller;
import com.gitcode.hystrix.service.HystrixCollapseService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.security.SecureRandom;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
/**
* @version 1.0.0
* @Date: 2023/4/9 10:16
* @Copyright (C) ZhuYouBin
* @Description:
*/
@RestController
@RequestMapping("/hystrix/consumer")
public class CollapseController {
@Autowired
private HystrixCollapseService hystrixCollapseService;
@GetMapping("/requestCollapse")
public String requestCollapse() throws ExecutionException, InterruptedException {
String id = new SecureRandom().nextInt() + "";
final Future<String> future = hystrixCollapseService.queryById(id);
// 获取方法的返回值,阻塞等待
final String result = future.get();
System.out.println("返回值: " + result);
return "success,接口返回值是: " + result;
}
}
(5)测试请求合并
依次启动eureka注册中心、consumer服务消费者、provider服务提供者工程,我这里采用jemeter进行并发请求测试,当然,你也可以直接浏览器多次刷新访问接口进行测试。

调用接口之后,查看控制台输入日志:

到此,Hystrix实现请求合并就介绍啦。
综上,这篇文章结束了,主要介绍微服务组件之Hystrix实现请求合并功能。