本文实现的语音识别系统,主要是对语音识别的特征参数的提取和识别模型的匹配,进行深入的研究。首先,对语音识别进行了概述,给出了语音识别的系统框架。然后就是如何实现语音识别的问题,这个过程可分为两个部分:第一个是语音特征参数梅尔倒谱系数(MFCC)的提取,主要包括了对语音信号进行预处理过程,特征参数求取过程,而且重点分析了双门限端点检测。第二个就是矢量量化(VQ)模型匹配的过程,主要包括训练阶段和识别阶段:训练阶段主要是生成每一个说话人一一对应的码本,采用经典的LBG算法矢量量化形成码书,通过计算训练与识别的码书的距离,即可以辨别出待识别人是谁。在MATLAB软件这个平台下,获得了较好的实验仿真效果。实验表明,MFCC参数具有很好的鲁棒性,能够达到准确识别说话人身份的目的。
一、基本原理
语音信号产生模型:

语音信号在较短时间可以认为是平稳的,在这个前提之下,经典的语音信号模型可以用线性时不变系统来表示。为了了解语音信号的特性,给出语音产生的模型,如图4-1所示。 建立了一个离散时域的语音信号产生模型,这对于进一步的各项研究以及各种具体应用,起到非常重要的作用。图中给出一个较简单的模型,对于大多数研究和应用而言,这个模型完全可以满足需要的。
语音离散时域模型有三部分:激励源、声道模型和辐射模型。
(1)激励源
激励源是由浊音清音开关所处的位置来决定产生的语音信号是清音还是浊音。浊音时,激励信号由一个周期脉冲发生器产生,产生的序列是一个频率等于基因频率的冲击序列。为了使浊音的激励信号具有声门脉冲的实际波形,我们需要把冲激序列通过一个声门脉冲模型滤波器G(z),乘以系数的作用是调节浊音信号的幅度;清音时,随机噪声发生器产生激励,乘以系数的作用是调节清音信号的幅度。
(2)声道模型
第二,声道模型V(Z)给出了离散时域的声道传输函数,实际的声道被假设成一个变截面积的声管。采用流体力学的方法可以导出,在大多数情况下,声道模型是一个全极点函数。因此,V(z)可以表 示为:
可以看出,这里把截面积连续变化的声管近似分为了P段短声管的串联。P称为这个全极点滤波器的阶数。显然,P值越大模型的传递函数与声道实际传输函数越吻合,一般P值取8~12即可。
(3)辐射模型
辐射模型R(z)与嘴形有关,研究表明,口唇辐射在高频端较为显著,在低频端时影响较小,所以我们把辐射模型R(z)看为一阶高通滤波器。其表达式为:![]()
在以上的模型中,G(z) 和R(z)保持不变,基音周期、浊清音开关的位置以及声道模型参数中的参数,都是随时间变化的。
系统框图

建立这个系统分为两个阶段:训练阶段和识别阶段。在训练阶段,系统的每个说话人进行录音,依次建立每个说话人的模型码本;而在识别阶段,待识别说话人录音提取的参数与码本进行比较,如果二者之间的距离小于一定的阈值,则可识别说话人,否则不能识别。
二、语音信号预处理
预处理包括去零、预加重、分帧、加窗。进行预加重是因为,对于语音信号的频谱通常是频率越高谱值越小,在语音信号的频谱提高两倍时,其功率谱的幅度约下降6dB,所以预加重的目的就是提升高频部分,使信号的频谱变得平坦,便于进行频谱分析。分帧是把语音信号看成是,很多短段的平稳的语音,这种分析处理方法叫做短时分析方法。加窗,实际上就是把语音信号通过滤波器组,体现在时域是时域表达式求卷积,在频率是频率表达式求乘积,为什么要加窗呢?是因为之后我们会对窗中的数据进行快速傅立叶变换(FFT),它假设窗中的信号是一个周期信号,通过加窗,就使得语音信号有周期的特性了。语音信号的预处理过程在后面的内容中有详细的实现过程。
三、特征提取
不同人的发声器官的生理结构有所差别,在不同的环境中成长的人即使发同一个音时发声器官的动作也不尽相同。这种能够表征说话人的信息,是通过共振峰频率及带宽、平均基频、频谱基本形状等这些物理可测量的参数特征表现出来的。特征参数对于不同的说话人应该是有差异的,这种差异称为话者间的差异(Interspeaker Variance)。话者间的差异是由说话人不同的声道特性产生的,这种差即可将不同的说话人区分开来。
那么如何从语音信号中提取特征参数就是说话人识别的关键。在理想情况下,这些特征应该具有如下的特点:
(1)具有很高的区别说话人的能力,能够充分体现说话人个体间的差异;
(2)在输入语音收到传输通道和噪音的影响时,能够具有较好的健壮性;
(3)易于提取,易于计算,并且在特征各维参数之间具有良好的独立性;
(4)不容易被模仿。
语音信号经过预处理后,仅几秒钟的语音就会产生很大的数据量。提取说话人特征的过程,实际上就是去除原来语音中的冗余信息,减少数据量的过程。特征参数的选择与提取对于说话人识别效果至关重要,一般将语音信号的特征参数分为两类:第一类是时域特征参数,第二类是变换域特征参数。前者通常可以用来进行端点检测,后者可以用来提取特征,生成识别码本。这两类参数的提取过程在提取梅尔倒谱系数的实现中作详细说明。
四、实现过程
语音识别的实现主要分为两个部分:第一个是提取特征参数;第二个是识别模型。寻找良好性能的特征参数和提取算法是提高识别系统性能的关键问题,找到合适的识别模型进行模式匹配也是系统的重要组成部分。
语音识别是指通过对说话人语音信号的分析处理,提取相应的特征或建立相应的模型,用来确认说话人的身份。目前,在语音识别中最常用的特征参数是基于声道的LPCC(linear prediction cepstral coefficient)和基于听觉特性的MFCC(Mel frequency cepstral coefficient)参数。MFCC参数识别效率比LPCC高、收敛速度快、鲁棒性好。因此本文中选择最常用的特征参数梅尔倒谱系数(MFCC)和矢量量化法(VQ)实现说话人识别,下面我们先提取梅尔倒谱系数,研究实现说话人识别的具体过程。
1、提取梅尔倒谱系数(MFCC)
梅尔倒谱系数(MFCC)是说话人识别算法中最常用的参数,它反映的是梅尔频率与赫兹频率的非线性的对应关系。MFCC的分析符合人类的听觉特性,人耳具有些特殊的功能,能在嘈杂的环境中以及各种异变情况下分辨出各种语音,其中耳蜗起了关键作用。耳蜗实质上就相当于是一个滤波器组,耳蜗滤波作用是在对数频率尺度上进行的,1000 Hz以下是线性尺度,1000 Hz以上是对数尺度,这就使人耳对高频敏感。根据这一原则研究了一组类似于人耳蜗作用的滤波器即Mel频率滤波器。MFCC是使用傅立叶分析提取的语音特征参数,是类似于指数的形式,它和实际频域之间的关系式为:
式中,![]() 是以Mel为单位的感知频域,是以Hz为单位的实际频域。将语音信号的频谱变换到感知域中,能更好的进行模拟听觉过程的处理。
是以Mel为单位的感知频域,是以Hz为单位的实际频域。将语音信号的频谱变换到感知域中,能更好的进行模拟听觉过程的处理。
MFCC参数的详细提取过程如图所示:

1.1信号预处理
(1)语音信号数字化。语音信号是一种模拟信号,无法直接用来进行数字化分析,因此我们需要把模拟信号转化为数字信号,这个过程叫做模/数转换。语音输入信号经过采样和量化两个步骤,就得到时间和幅度上均为离散的数字语音信号。首先说采样,奈奎斯特采样定律指出,采样频率应大于原始语音频率的两倍,才能不丢失信息。结合实际情况,正常人发音的频率范围在40Hz一3400Hz,所以语音信号处理采样频率应该大于8000Hz,为了提高识别率,经实际验证,选择4.41kHz的采样频率比较合适,因此我们在后面的仿真实验中选择4.41kHz的采样频率。
(2)去零
去零,就是去掉静音的部分,找到段语音真正有效的内容。去掉静音部分,在后续的使用中更加方便、快速,防止输入信号为0作为分母的情况出现。
(3)预加重
预加重是一种在发送端对输入信号高频分量进行补偿的信号处理方式。随着信号速率的提高,信号在传输过程中受损很大,为了在接收终端能得到比较好的信号波形,就需要对受损的信号进行补偿,预加重技术的思想就是在传输线的始端增强信号的高频成分,以补偿高频分量在传输过程中的过大衰减。而预加重对噪声并没有影响,因此有效地提高输出信噪比。信噪比越大,说明混在信号里的噪声越小,声音回放的音质量越高,否则相反。
我们在这个部分应用预加重主要是为了消除发声过程中,声带和嘴唇造成的效应,来补偿语音信号受到发音系统所压抑的高频部分。并且能凸显高频的共振峰,使信号的频谱变得平坦,便于频谱分析。我们选择具有6dB/倍频程的提高频率特性的预加重数字滤波器实现,其Z传递函数为: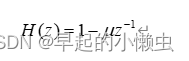
其中u值接近1,典型取值在0.94-0.97之间
(4)分帧
傅里叶变换要求输入信号是平稳的。语音信号在宏观上是不平稳的,在微观上是平稳的,具有短时平稳性(10—30ms内可以认为语音信号近似不变),这个就可以把语音信号分为一些短段进行处理,每一个短段称为一帧(CHUNK)。在后面需要给语音信号进行加窗,加窗会让波形的细节丢失,这时为了防止丢失波形信息,在分诊时前一帧和后一帧要有重叠的部门,这部分叫做帧移。帧移一般取值为帧长的1/3-1/2,这样前一帧的信息又可以重新找到
(5)加窗
加窗即与一个窗函数相乘,加窗之后是为了进行傅里叶展开。加窗的目的:一是使全局更加连续,避免出现吉布斯效应;二是使加窗时候,原本没有周期性的语音信号呈现出周期函数的部分特征;三十增加帧左右两端的连续性。加窗的代价是一帧信号的两端部分被削弱了,所以在分帧的时候,帧与帧之间需要有重叠。在语音信号处理中,常用窗函数是汉宁窗。汉宁窗可以有效的克服泄露现象,应用也最为广泛。
汉宁窗表达式: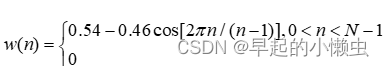
1.2、信号快速傅里叶变换
由于信号在时域上的变换通常很难看出信号的特性,所以通常将它转换为频域上的能量分布来观察,不同的能量分布,就能代表不同语音的特性。所以在乘上汉宁窗后,每帧还必须再经过快速傅里叶变换以得到在频谱上的能量分布。对分帧加窗后的各帧信号进行快速傅里叶变换得到各帧的频谱。并对语音信号的频谱取模平方得到语音信号的功率谱。
1.3、经Mel滤波器组频响加权
经过傅里叶变换的函数的幅度将被一组Mel尺度的三角滤波器组的频率响应加权。Mel刻度滤波器组的中心频率按照Mel频率均匀排列,每个三角滤波器的两个底点是相邻滤波器的中心,这些滤波器的中心频率和带宽与听觉临界边带滤波器组大体一致。这里我们设计的是一个有100个三角滤波器的滤波器组,图为三角形滤波器。

1.4、离散余弦变换(DCT)
得到每个滤波器组输出的对数能量后,实际上对信号难以线性处理,而同态频谱变换,就是对它们取对数运算,变成分量的和,形成一个矢量。为了去除各维信号之间的相关性,则需要对矢量作离散余弦变换,这时就得到了我们要提取的特征参数,即梅尔倒谱系数。
2、VQ模型匹配
矢量量化(VQ)匹配
矢量量化法(VQ)匹配过程,即是把每个说话人的语音看作是一个信号源,在每一个说话人的训练语音中提取特征参数矢量,然后用传统的LBG算法聚类生成码本。与测试得到的码本进行匹配,已确认待识别人事那个说话人。
我们的训练集是一个有M个矢量源(语音信号采样点数为M)
其中:M=录音时间×采样频率=2×44100=88200
训练集:![]() ;
;
源矢量是N维的则:
假设码矢的数目是K(设置为经验值16),码书表示为:![]() ;
;
每一个码矢是个N维向量:

即要求码矢Cn是编码区域Sn内所有的训练样本向量的平均向量。在实现中,需要保证每个编码区域至少要有一个训练样本向量,这样上面这条式的分母才不为01.
3、VQ工作流程
程序在运行的过程中主要分为训练和识别两部分,第一部分训练是指针对每个说话人的声音特征进行提取,并利用LBG算法对其进行特征训练,而LBG算法的思路则是利用分裂的思想,通常按倍数递增,一直到码本数量增加到码本的误差达到预设值停止,最终的结果相当于降维:此时码本的维度是K×N。,第二部分识别则是通过同样的特征提取方式对测试声音进行提取并生成码本,码本生成结束后与之前训练好的码本进行匹配,用dist函数计算其欧几里德距离,并生成N×P维的矩阵。该矩阵将被其他程序调用以生成最终的识别结果
五、系统仿真
1.训练
(1)选择编号:对训练者进行编号,方便语音信息的存储与识别匹配;
(2)开始录音:调用audiorecorder函数进行录制,录音时间3秒,并用audiowrite保存录制文件;
(3)训练码本:训练录音结束后,对所训练者的录音生成码本。
2.识别模块:
(1)训练录音:识别者随意说话,时间设为3秒,同时实现端点检测处理;
(2)语音播放:播放出待识别的语音;
(3)特征提取:对识别者的语音提取MFCC参数,并生成识别码本;
(4)识别结果:把识别者的码本与训练码本进行匹配,显示出结果“待识别说话人与第N个训练者匹配”。
六、仿真结果
我们选择一个人进行说话人仿真识别实验,分别标记为3号。仿真实验具体操作步骤分为训练和识别两步。
(1)训练阶段:录入三秒语音信号


最后通过FFT变换,经过Mel滤波器,再进行DCT变换,得到Mel倒谱系数。将得到的系统特征矢量通过LBG算法进行矢量量化,得到量化后的码书。
在语音测试时,也类似进行语音录制,通过同样的过程得到测试语音段的码书。将其与训练所得的所有码书进行对比,得到欧氏距离最短的,就是要找的说话人。如下图所示,实验验证该参与者的声音均能正确识别。
源码工程文件分享:
链接:https://pan.baidu.com/s/1OaAieuwp2fUWj-shx-9u0g
提取码:duoj