- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊|接辅导、项目定制
本周进行SE模块在DenseNet上的改进实验,之后将改进思路迁移到YOLOv5模型上测试
首先是学习SE模块
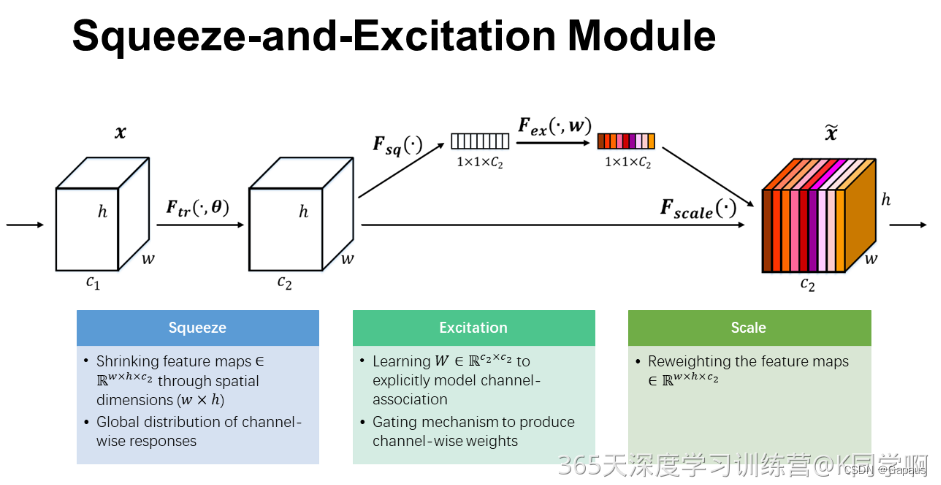
SE模块:Squeeze-and-Excitation Module
其中:
- Squeeze操作即将一个feature map的w,h使用平均池化压缩到1x1,而channel不变
- Excitation即激活层操作,用于将输入数据映射为对应channel的权重(使用sigmoid,输出值在0~1)
- 图中的Scale即将每个权重值乘上原本的feature map的对应层,得到新的feature map
代码借鉴了网上的写法,使用add_module()可以便于动态建立模型
class SELayer(nn.Module):
def __init__(self, ch_in, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(ch_in, ch_in // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(ch_in // reduction, ch_in, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
class _DenseLayer(nn.Module):
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate, efficient=False):
super(_DenseLayer, self).__init__()
self.norm1 = nn.BatchNorm2d(num_input_features)
self.relu1 = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(num_input_features, bn_size * growth_rate,
kernel_size=1, stride=1, bias=False)
self.norm2 = nn.BatchNorm2d(bn_size * growth_rate)
self.relu2 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(bn_size * growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False)
self.se1 = SELayer(growth_rate, reduction=16)
self.drop_rate = drop_rate
self.efficient = efficient
def forward(self, *prev_features):
concated_features = torch.cat(prev_features, 1)
bottleneck_output = self.conv1(self.relu1(self.norm1(concated_features)))
new_features = self.se1(self.conv2(self.relu2(self.norm2(bottleneck_output))))
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return new_features
class _Transition(nn.Sequential):
def __init__(self, num_input_features, num_output_features):
super(_Transition, self).__init__()
self.norm = nn.BatchNorm2d(num_input_features)
self.relu = nn.ReLU(inplace=True)
self.conv = nn.Conv2d(num_input_features, num_output_features,
kernel_size=1, stride=1, bias=False)
self.pool = nn.AvgPool2d(kernel_size=2, stride=2)
class _DenseBlock(nn.Module):
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate, efficient=False):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(
num_input_features + i * growth_rate,
growth_rate=growth_rate,
bn_size=bn_size,
drop_rate=drop_rate,
efficient=efficient,
)
self.add_module('denselayer%d' % (i + 1), layer)
def forward(self, init_features):
features = [init_features]
for name, layer in self.named_children(): # 遍历上面add_module生成的模型
new_features = layer(*features)
features.append(new_features)
return torch.cat(features, 1)
class DenseNet(nn.Module):
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=24, compression=0.5, bn_size=4,
drop_rate=0,
num_classes=10, small_inputs=True, efficient=False):
super(DenseNet, self).__init__()
# First convolution
if small_inputs:
self.features = nn.Sequential(
nn.Conv2d(3, num_init_features, kernel_size=3, stride=1, padding=1, bias=False))
else:
self.features = nn.Sequential(
nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(num_init_features),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False)
)
# Each denseblock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(
num_layers=num_layers,
num_input_features=num_features,
bn_size=bn_size,
growth_rate=growth_rate,
drop_rate=drop_rate,
efficient=efficient,
)
self.features.add_module('denseblock%d' % (i + 1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
trans = _Transition(num_input_features=num_features,
num_output_features=int(num_features * compression))
self.features.add_module('transition%d' % (i + 1), trans)
num_features = int(num_features * compression)
# self.features.add_module('SE_Block%d' % (i + 1),SE_Block(num_features, reduction=16))
# Final batch norm
self.features.add_module('norm_final', nn.BatchNorm2d(num_features))
# Linear layer
self.classifier = nn.Linear(num_features, num_classes)
def forward(self, x):
features = self.features(x)
out = F.relu(features, inplace=True)
out = F.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
在DenseNet上测试:
数据集刚好存了之前天气识别的图片,所以直接用了这个,训练结果:

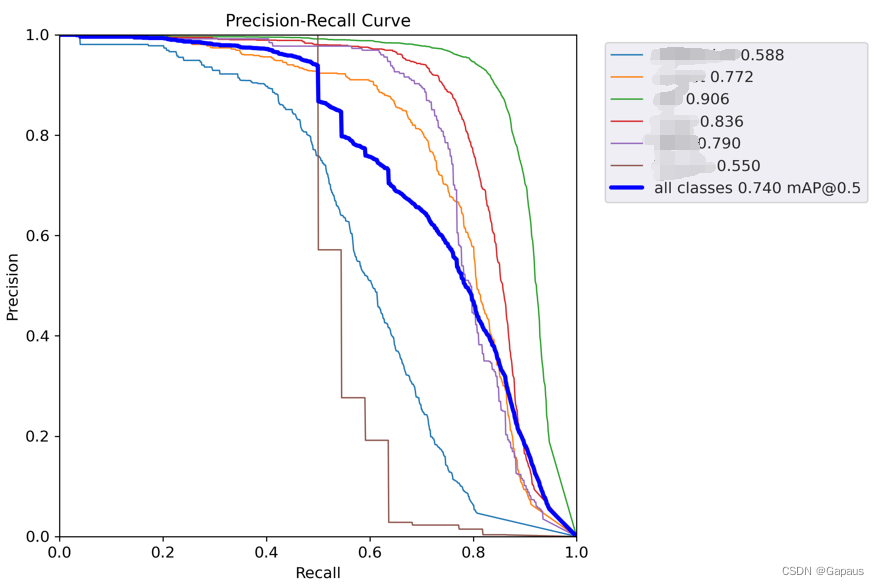
下面是在YOLOv5上的实验,SE模块加在哪里就不写了,最后相较于原版yolov5(mAP=0.73),mAP有0.05的提升,其中还含有概率成分,不过条件不允许,就没办法多次训练取均值了,
虽然效果一般,但也是改了这么几次模型,第一次有一点点提升。
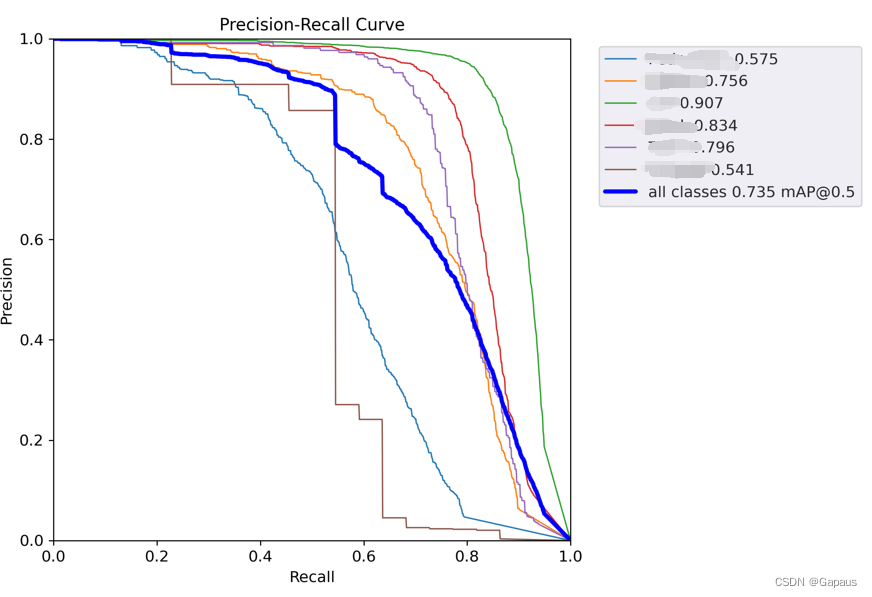
将SE模块根据自己的想法修改了一下,有了1%的提升,看来注意力机制在视觉上的表现是不错的,后续会进行其他注意力模块的引入测试