Paper name
KAT: A Knowledge Augmented Transformer for Vision-and-Language
Paper Reading Note
URL: https://arxiv.org/pdf/2112.08614.pdf
TL;DR
- 2022 NAACL 论文,提出了 Knowledge AugmentedTransformer (KAT),提出了一种同时利用显式和隐式知识的 PPL,在 OK-VQA 上取得了 SOTA 效果
Introduction
背景
- 最近大型 transformer 研究工作的主要重点是优化模型参数中的信息量
- 在这项工作中,作者提出了一个补充问题:多模态 transformer 能否在推理中利用显式知识?
- 如下图所示,为了回答左侧示例中的问题,系统需要通过显性知识将生物体与鸟类联系起来,然后应用从爬行动物进化而来的隐性知识来回答问题;同样,对于右边示例中的问题,系统需要识别船只和港口,并需要使用隐式知识判断需要利用锚来阻止船只移动:

- 【现有方案问题】现有的方法主要是单模态的,已经在知识检索和答案预测的范式下有算法方案。但是对检索到的知识的质量和相关性,以及如何整合隐式知识 (如常识) 和显式知识 (如 Wikidata) 的推理过程还没有很好的解决方案,比如现有方案有以下缺陷
- 使用问题或图像标签中的关键词检索的显性知识可能过于通用,这会导致知识推理过程中产生噪音或不相关的知识
- 现有的工作主要集中在显性知识上,而显性知识通常以百科全书文章或知识图表的形式出现。虽然这类知识可能有用,但不足以回答许多基于知识的问题。
- 【挑战】这里的一个关键挑战是准确地将图像内容与抽象的外部知识联系起来
- 【现有方案问题】现有的方法主要是单模态的,已经在知识检索和答案预测的范式下有算法方案。但是对检索到的知识的质量和相关性,以及如何整合隐式知识 (如常识) 和显式知识 (如 Wikidata) 的推理过程还没有很好的解决方案,比如现有方案有以下缺陷
本文方案
- 本文提出了 Knowledge AugmentedTransformer (KAT),在 OK-VQA 上取得了 SOTA 效果(+6%)
- 在 encoder-decoder 结构中继承了显式和隐式的知识,同时在生成答案时仍然联合这两个知识来源
- 此外,显式知识集成提高了本文分析中模型预测的可解释性
- 本文主要贡献有:
- 知识提取方案更新:显著提高所提取知识的质量和相关性
- 对于隐式知识,设计了新的提示,以从冻结参数的GPT-3模型中提取初步答案和支持证据
- 对于显式知识,使用CLIP模型设计了一个基于对比学习的显式知识检索器,其中所有检索到的知识都集中在视觉对齐的实体上
- 基于编码器-解码器 transformer 的推理架构
- OK-VQA 取得了 SOTA 结果
- 知识提取方案更新:显著提高所提取知识的质量和相关性
Dataset/Algorithm/Model/Experiment Detail
实现方式
问题定义
- 对于给定训练数据集
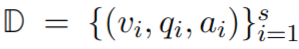
其中 v i v_{i} vi 是第 i 张训练图片;s 是所有的训练图片数目; q i q_{i} qi 和 a i a_{i} ai 分别是第 i 个问题和对应的答案 - 模型 IO 设计
- 输入 v i v_{i} vi 和 q i q_{i} qi,自回归地输出 a i a_{i} ai
显式知识检索
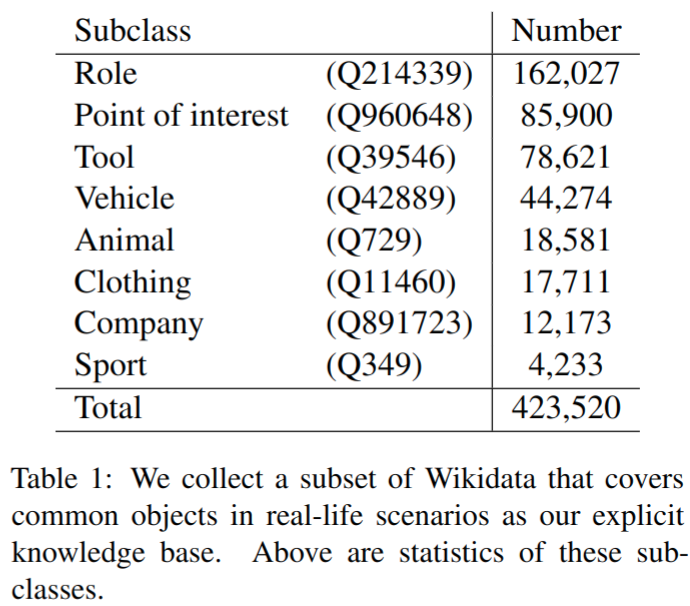
- 构建了一个显式的知识库 K,涵盖了Wikidata中的8类动物、车辆和其他常见物体
- 知识库中的每个 entry 包含:实体和对应的描述
- 显式知识检索流程
- 对于知识库中所有 entry 都基于一个 dense encoder Eent(·) 提取为 d 维特征
- 对于输入图片,使用滑动窗生成 N 个子区域图片,每个都基于图片 encoder Eimg(·) 来提取 d 维特征
- 基于上述两者特征计算相似度,每个图像 patch 都挑选前 k 个最相关的知识库特征,共挑选出 Nxk 个知识库 entry,然后基于相似度再选择 top-m 个 entry。
- 这里图像和知识库的 encoder 使用了 CLIP (ViT-B/16 variant)
知识库构建
- 使用 English Wikidata (Sep. 20, 2021 版本),包含 95, 870, 584 实体
- 提取了一个子集,它涵盖了现实场景中的常见对象;删除字符串标签或相应描述为空或非英语的所有实体,最终得到包含 423, 520 实体知识库
隐式知识检索
- 参考之前工作基于 GPT-3 来提取隐式知识
- 对于每个图像问题对,首先通过 SOTA 的 image caption 模型将图像 vi 转换为文本描述 C,然后构造一个精心设计的文本提示,该提示由一个通用指令语句、文本描述C、问题和一组从训练数据集中提取的上下文问答三元组组成,这些三元组在语义上与当前图像问题对最相似,一个 GPT-3 的输入 prompts 示例如下

- 基于以上输入 GPT-3 可以得到一个初步答案,为了从GPT-3的隐含知识及其原理中获得更深入的见解,设计了另一个提示来查询GPT-3,以获取它生成的候选答案背后的支持证据
- 更具体地说,对于每个图像问题对(vi,qi),以及 GPT-3 生成的一个暂定答案,我们构建如下形式的提示:“(问题qi)?(答案a)。这是因为”来询问 GPT-3 回复这个答案的支持证据。最终将GPT-3中的初步答案和相应的支持证据整合为隐式知识源
KAT 模型
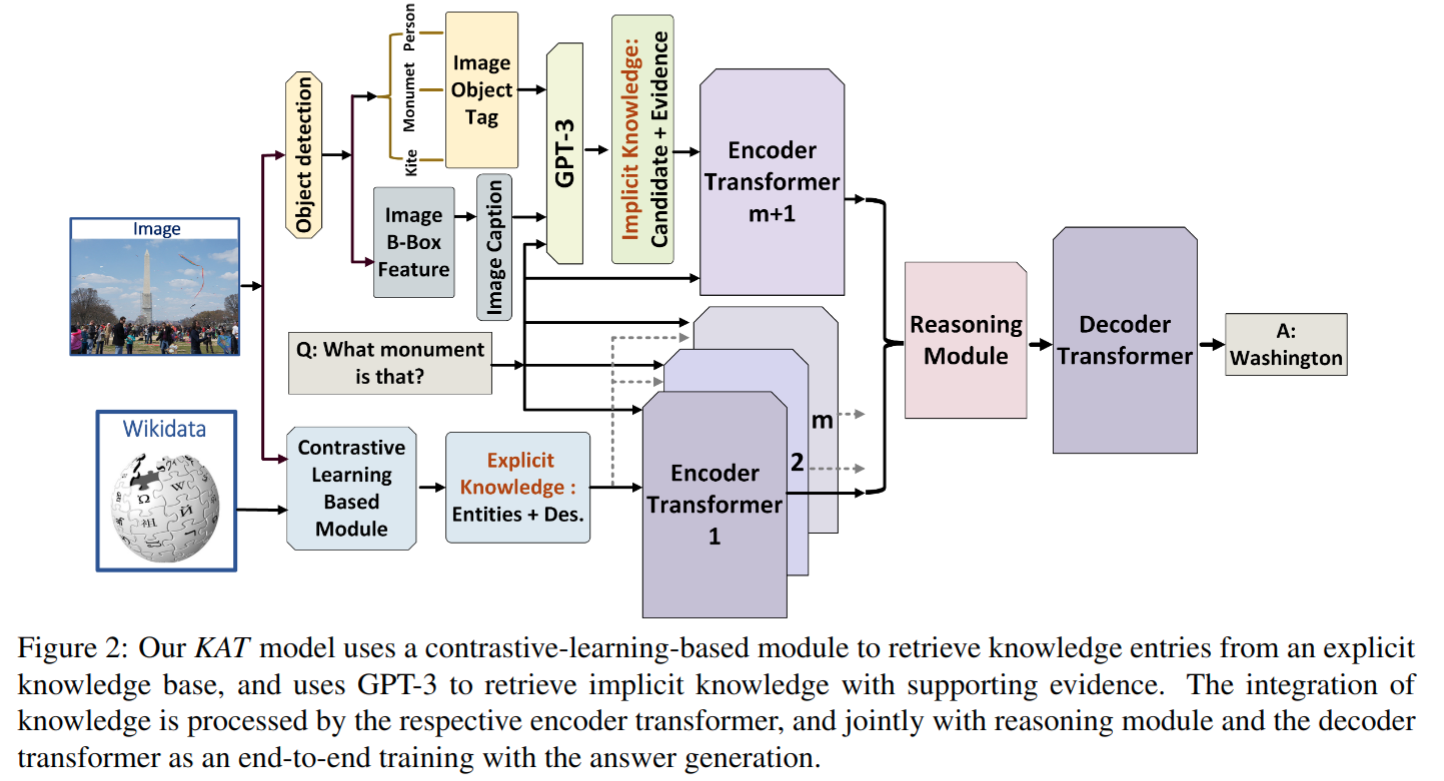
- 以上显式知识检索可能有噪声或者不相关的,另外隐式知识检索中的 GPT-3 提供的支持性证据是通用的或与图像内容无关。不同知识的简单 concat 可能会在模型训练期间引入噪声,这里的模型实现是知识推理模块分别对每个问题和知识对进行编码,在生成答案时,对显性和隐性知识结合起来进行推理
- encoder:
- 我们将问题与每个知识连接起来
- 显式:question:、entity: and description
- 隐式:question:,candidate: and evidence
- 使用 an embedding layer 和一些 encoder layers 来分别对问题知识对进行编码
- 对来自最后一个编码器层的每个问题知识对的 token embeddings 取平均,分别得到:
- 显式知识:Xexp ∈ Rm×d,d 是 embedding 维度
- 隐式知识:Ximp∈Rp×d,d 是 embedding 维度
- 我们将问题与每个知识连接起来
- Reasoning Module
- Xexp 和 Ximp concat 后作为输入 X,之前 self-attention 层输出 H 也作为输入,基于 cross attention 提取特征
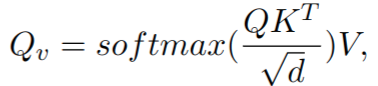
其中 K、V 来源于 X,Q 来源于 H
- Xexp 和 Ximp concat 后作为输入 X,之前 self-attention 层输出 H 也作为输入,基于 cross attention 提取特征
- Decoder:一系列 decoder layer 组成,训练 loss 为 ce loss
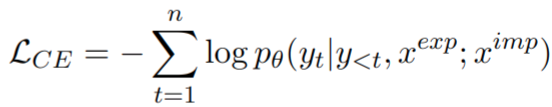
实验结果
数据集
OK-VQA:最大的基于知识的VQA数据
- 这些问题都是由Amazon Mechanical Turkers众包的,需要图像以外的外部知识才能正确回答
- 该数据集包含14031张图片和14055个问题,涉及各种知识类别
实现细节
- knowledge reasoning 使用预训练的 T5 模型:base (220M) 和 large (770M)
- 在 OK-VQA 上 finetune
- 考虑到计算资源限制,检索实体数目设置为 40
- 16 张 V100 训练,batch size 32
- 评测:
- 用规范化后的 gt 来评估模型,规范化步骤包括小写和删除文章、标点符号和重复空格
- 用3种不同的随机种子训练模型,并使用平均结果提交排行榜
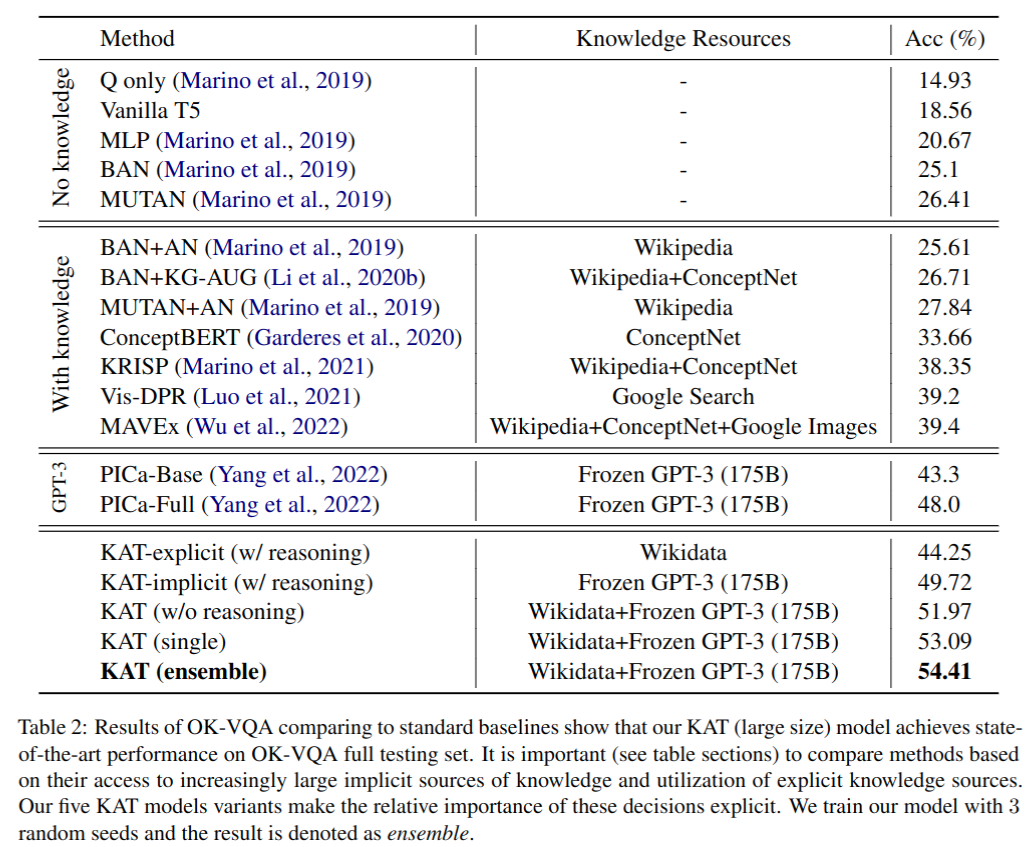
与 SOTA 方法对比
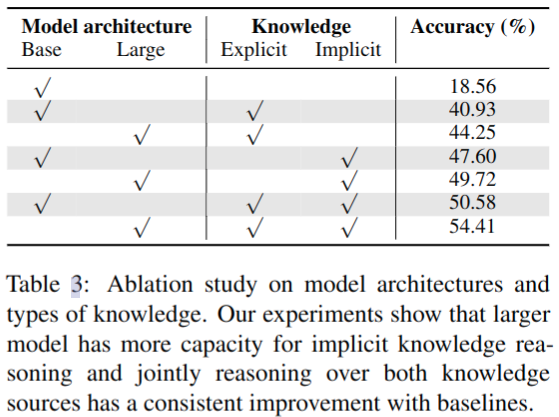
消融实验
-
知识检索方法:large 和 base 差距 4 个点左右;显式知识或者隐式知识单独引入都涨点明显
-
Knowledge Reasoning 模块设计:看起来模型结构设计的影响和知识库引入相比并不大

-
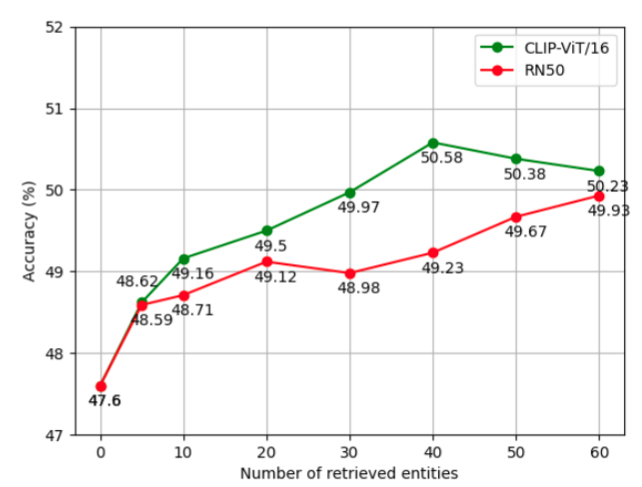
显式知识利用的检索数目影响,可以看到在 40 时精度最高
OK-VQA 数据集上的问答示例

Thoughts
- 显式和隐式知识结合 ppl 看起来挺简洁的,知识检索模块利用更新的技术应该还有提升空间