漏斗图
使用漏斗图显示步骤的进度。
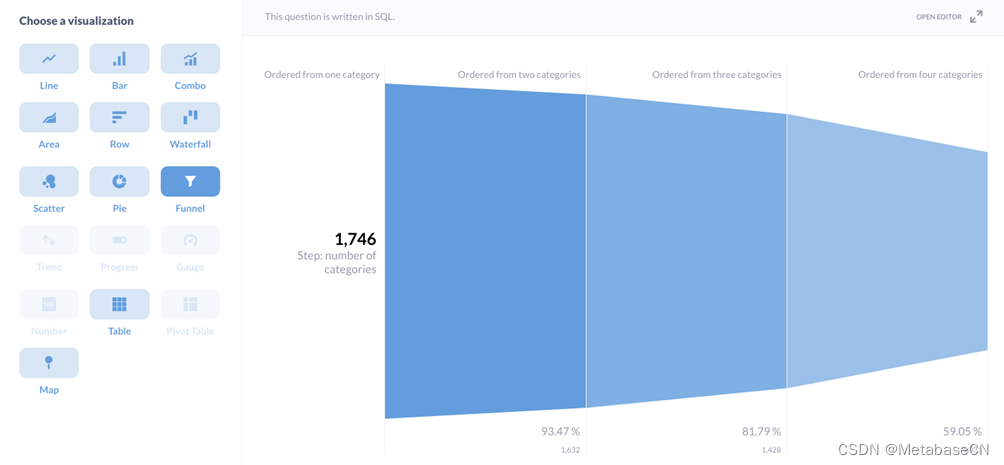
图1。我们将用示例数据库构建一个漏斗图。
漏斗图用一系列台阶显示了指标。通常,它们用于显示有多少人通过特定的序列(如网站上的结帐流程)完成。第一步是多少人访问你的网站。然后有多少人浏览了一个产品页面(步骤2),有多少人将该商品添加到购物车(步骤3),等等。
我们将介绍如何使用安装中附带的示例数据库在Metabase中构建漏斗图,以便您可以继续进行。我们将在查询生成器和sql编辑器中显示示例:
- 查询生成器
- SQl编辑器
示例数据库不包含事件;它只有四个表,包含订单、产品和客户信息。所以我们得有点创意来给漏斗图举些例子。
使用查询生成器的漏斗图示例
这是一个人为的例子。我们将假设漏斗中的步骤是产品类别(因为我们的示例数据库中没有类似于状态、页面或其他进展的内容)。这是查询编辑器,我们的疑问是:
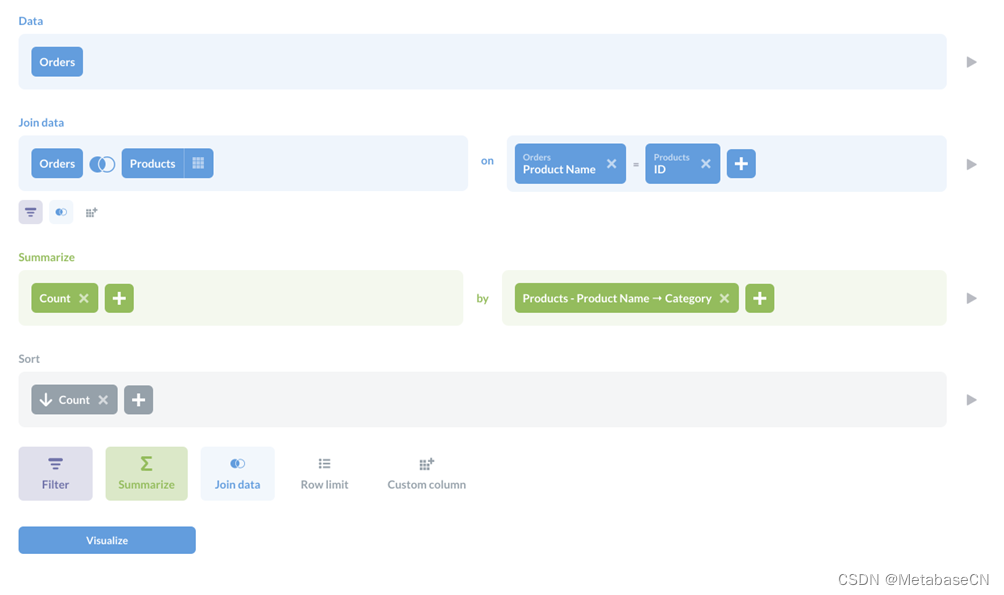
图2。漏斗图查询的查询编辑器。
我们所做的就是加入Orders和Products表格(请参见在元数据库中联接),汇总订单计数,并按产品类别对这些计数进行分组。然后我们按计数、降序对结果进行排序。为了得到漏斗图,我们点击可视化在左下角,选中漏斗。在漏斗图的设置中,在数据选项卡,可以设置台阶(在本例中,我们使用的是产品类别)和指标(订单数量)。
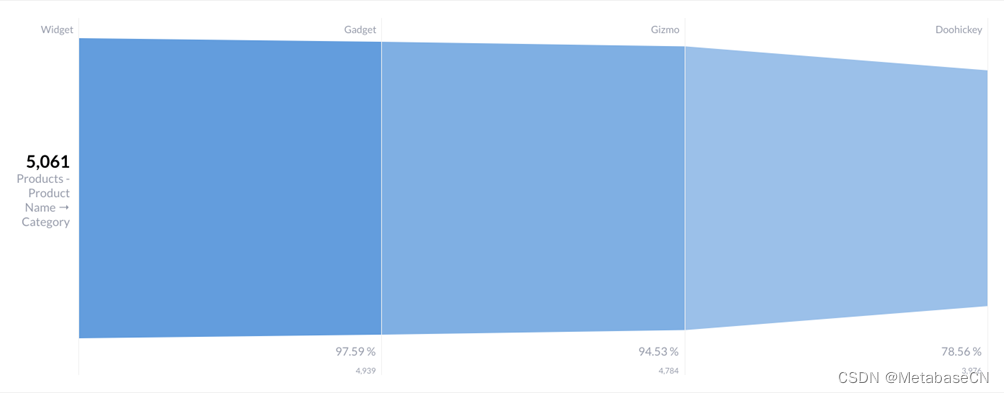
图3.(相当胖的)漏斗图,在漏斗中使用类别作为步骤。
注意在设置->显示选项卡,您可以更改漏斗式“条形图”,这是另一种有效的数据表示方式。漏斗图的优势(除了视觉隐喻之外)是Metabase还将显示通过每个步骤的度量的百分比。
使用自定义列对步骤进行排序
如果每个步骤中的计数没有自然减少,则可能需要手动对步骤进行排序,以保持步骤的实际进度。例如,如果在连续的步骤中使用相同的计数,那么这些步骤可能会在漏斗图中进行交换,就像Metabase默认按字母顺序对步骤进行排序以打破这种情况。同样地,如果你有漏斗,它可以在特定的步数上扩展(例如,新的人在中途进入漏斗),漏斗将默认为递减计数,这会扰乱你的步序。
在这些情况下,您可以创建一个额外的列来对步骤进行编号,并按步骤进行排序以实施正确的漏斗序列。以上面的查询为例,我们可以通过添加另一列来修改它以保留序列,然后按下一步.
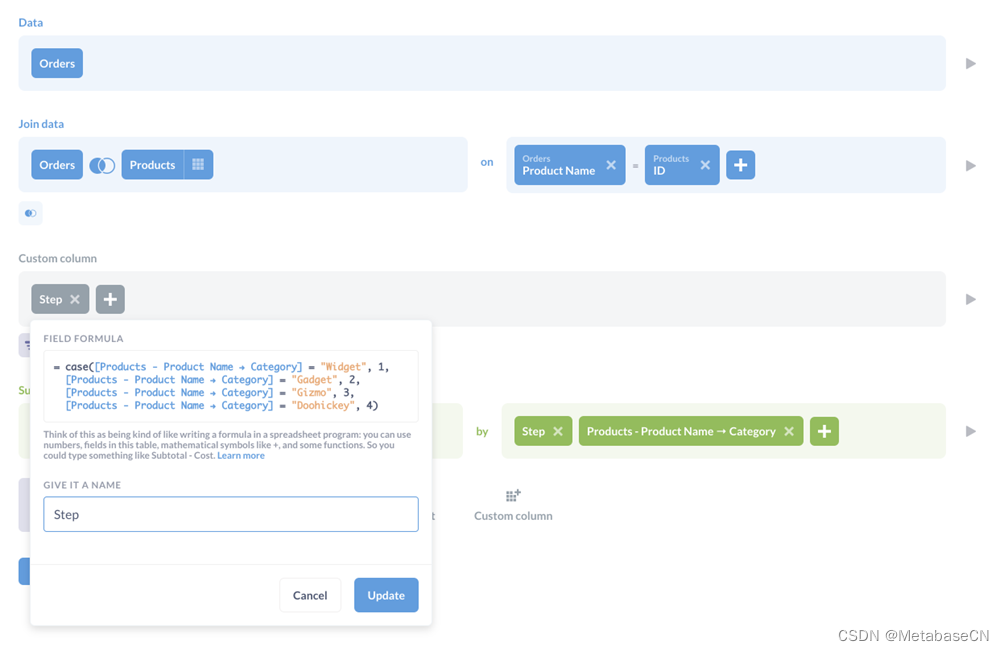
图4。使用自定义表达式创建自定义列,以指定漏斗中的步骤顺序。
下面是图4中使用的自定义表达式:
case([Products - Product Name → Category] = "Widget", 1, [Products - Product Name → Category] = "Gadget", 2, [Products - Product Name → Category] = "Gizmo", 3, [Products - Product Name → Category] = "Doohickey", 4)
基本上,我们说小部件是漏斗的第一步,小工具是第二步,依此类推。
使用SQL的漏斗图示例
另一个使用示例数据库的人为示例:假设我们了解到,拥有最高生命周期价值的客户是那些从我们所有四个产品类别下订单的客户:dooickeys、Gadgets、gizmo和Widgets。所以在这个例子中,我们想看看我们的客户是如何根据他们订购的不同种类的产品来划分的。
这里要做的一个关键区别是,我们不想看到客户的分布情况,也就是说,我们不想查看是否有多少客户从一个产品类别订购,有多少订单来自两个类别,等等。我们将把所有为任何类别下订单的客户作为第一步。下一步,我们将筛选出至少有两个产品类别、三个类别和四个类别的订单的客户。
假设我们有一个客户池,有100个客户下订单。桌子看起来像这样:
| Step: number of categories | Count of customers |
|:------------------------------|:-------------------|
| Ordered from one category | 100 |
| Ordered from two categories | 70 |
| Ordered from three categories | 40 |
| Ordered from four categories | 20 |
我们的计划是:使用通用表表达式,每次查询都会进一步细化我们的结果。那我们就UNION将所有结果放入单个结果表中。
我们将从获取从我们这里订购的所有客户开始,并将该查询放入CTE中以构建另一个子查询。在下面的代码块中,我们调用第一个子查询starting_data。若要获取客户的第一步,我们将创建一个新的子查询cat_one,它将基于starting_data.
WITH starting_data
AS (SELECT people.id,
products.category
FROM people
JOIN orders
ON people.id = orders.user_id
JOIN products
ON orders.product_id = products.id
GROUP BY people.id,
products.category
ORDER BY people.id),
cat_one
AS (SELECT id,
Count(id) AS cats
FROM starting_data
GROUP BY id
HAVING cats > 0
ORDER BY id)
在接下来的两个步骤中,我们将采用相同的方法(即,在前面的结果基础上逐步构建):
WITH starting_data
AS (SELECT people.id,
products.category
FROM people
JOIN orders
ON people.id = orders.user_id
JOIN products
ON orders.product_id = products.id
GROUP BY people.id,
products.category
ORDER BY people.id),
cat_one
AS (SELECT id,
Count(id) AS cats
FROM starting_data
GROUP BY id
HAVING cats >= 0
ORDER BY id),
-- People who ordered from at least two categories
cat_two
AS (SELECT id,
Count(id) AS cats
FROM cat_one
GROUP BY id
HAVING cats > 1
ORDER BY id),
-- People who ordered from at least three categories
cat_three
AS (SELECT id,
Count(id) AS cats
FROM cat_one
GROUP BY id
HAVING cats > 2
ORDER BY id),
-- People who ordered from at least four categories
cat_four
AS (SELECT id,
Count(id) AS cats
FROM cat_one
GROUP BY id
HAVING cats > 3
ORDER BY id)
现在我们有了四个结果:cat_one, cat_two, cat_three, cat_four,我们需要将这些结果合并到一个结果表中。我们将使用UNION合并结果。
-- Now we union these four results to produce a single table
-- that we'll use to build our funnel chart. The table will have two columns:
-- the Step: number of categories (our step),
-- and the count of customers (our measure).
SELECT 'Ordered from one category' AS "Step: number of categories",
Count(*) AS Customers
FROM cat_one
UNION
SELECT 'Ordered from two categories' AS "Step: number of categories",
Count(*) AS Customers
FROM cat_two
UNION
SELECT 'Ordered from three categories' AS "Step: number of categories",
Count(*) AS Customers
FROM cat_three
UNION
SELECT 'Ordered from four categories' AS "Step: number of categories",
Count(*) AS Customers
FROM cat_four
ORDER BY customers DESC
漏斗图查询
以下是完整的查询:
WITH starting_data
AS (SELECT people.id,
products.category
FROM people
JOIN orders
ON people.id = orders.user_id
JOIN products
ON orders.product_id = products.id
GROUP BY people.id,
products.category
ORDER BY people.id),
cat_one
AS (SELECT id,
Count(id) AS cats
FROM starting_data
GROUP BY id
HAVING cats >= 0
ORDER BY id),
-- People who ordered from at least two categories
cat_two
AS (SELECT id,
Count(id) AS cats
FROM cat_one
GROUP BY id
HAVING cats > 1
ORDER BY id),
-- People who ordered from at least three categories
cat_three
AS (SELECT id,
Count(id) AS cats
FROM cat_one
GROUP BY id
HAVING cats > 2
ORDER BY id),
-- People who ordered from at least four categories
cat_four
AS (SELECT id,
Count(id) AS cats
FROM cat_one
GROUP BY id
HAVING cats > 3
ORDER BY id)
-- Now we union these four results to produce a single table
-- that we'll use to build our funnel chart. The table will have two columns:
-- the Step: number of categories (our step),
-- and the count of customers (our measure).
SELECT 'Ordered from one category' AS "Step: number of categories",
Count(*) AS Customers
FROM cat_one
UNION
SELECT 'Ordered from two categories' AS "Step: number of categories",
Count(*) AS Customers
FROM cat_two
UNION
SELECT 'Ordered from three categories' AS "Step: number of categories",
Count(*) AS Customers
FROM cat_three
UNION
SELECT 'Ordered from four categories' AS "Step: number of categories",
Count(*) AS Customers
FROM cat_four
ORDER BY customers DESC
这将产生:
| Step: number of categories | CUSTOMERS |
|-------------------------------|-----------|
| Ordered from one category | 1,746 |
| Ordered from two categories | 1,632 |
| Ordered from three categories | 1,428 |
| Ordered from four categories | 1,031 |
现在我们要做的就是点击可视化在左下角选择漏斗.
如果你打开设置选项卡,您可以更改台阶或者测量。在显示选项卡,您可以将图表从漏斗更改为条形图(尽管如前所述,您将丢失视觉隐喻和度量相对于第一步的百分比)。
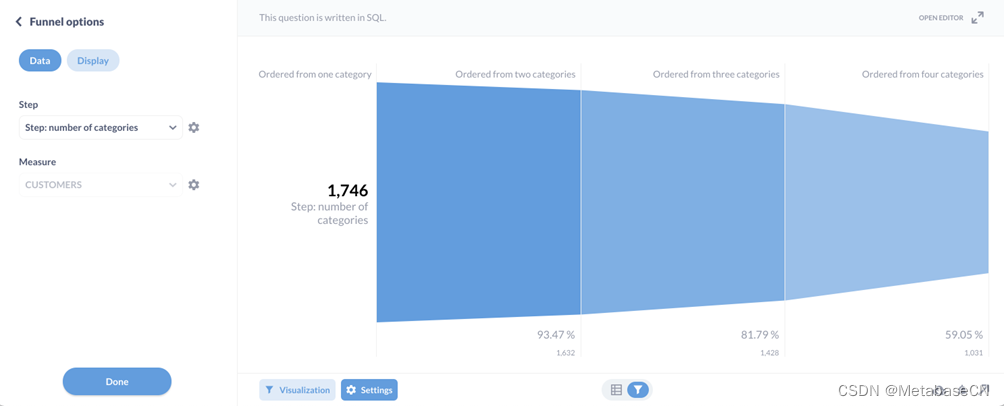
图5漏斗选项数据选项卡用于设置台阶和测量.
在SQL中保持步骤的排序
像上面的查询生成器,要强制执行步骤顺序,您可以添加一个附加列(我们将其称为“step”:
SELECT 'Ordered from one category' AS "Step: number of categories",
Count(*) AS Customers,
1 as step
FROM cat_one
UNION
SELECT 'Ordered from two categories' AS "Step: number of categories",
Count(*) AS Customers,
2 as step
FROM cat_two
UNION
SELECT 'Ordered from three categories' AS "Step: number of categories",
Count(*) AS Customers,
3 as step
FROM cat_three
UNION
SELECT 'Ordered from four categories' AS "Step: number of categories",
Count(*) AS Customers,
4 as step
FROM cat_four
ORDER BY step