Flink 可以从各种来源获取数据,然后构建 DataStream 进行转换处理。一般将数据的输入来源称为数据源,而读取数据的算子就是源算子(Source)。所以,Source 就是我们整个处理程序的输入端。
Flink 代码中通用的添加 Source 的方式,是调用执行环境的 addSource()方法:
//通过调用 addSource()方法可以获取 DataStream 对象
val stream = env.addSource(...)方法传入一个对象参数,需要实现 SourceFunction 接口,返回一个 DataStream。
首先先准备数据,假设数据来源是网页的埋点数据,数据格式为(用户名,网址,时间戳)的三元组,此处用case class样例类来表示数据格式。
字段名 | 数据类型 | 说明 |
user | String | 用户名 |
url | String | 网址 |
timestamp | long | 时间戳 |
样例类代码如下:
object CC {
// 用户浏览事件 用户名 网址 时间戳
case class Event(user: String, url: String, timestamp: Long)
}从集合中读取数据
最简单的读取数据的方式,就是在代码中直接创建一个集合,然后调用执行环境的fromCollection 方法进行读取。这相当于将数据临时存储到内存中,形成特殊的数据结构后,作为数据源使用,一般用于测试。
def main(args: Array[String]): Unit = {
// 获取流执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 设置并行度为1
env.setParallelism(1)
// 读取Event集合
val stream: DataStream[Event] = env.fromCollection(List(
Event("zhangsan", "index.html", 1L),
Event("lisi", "commom.jsp", 10L),
Event("wangwu", "baidu.com", 10L)))
stream.print()
env.execute()
}从文件中读取
// 读文本文件 有界的数据流
val stream: DataStream[String] = env.readTextFile("input/words.txt")
val sum: DataStream[(String, Int)] = stream
.flatMap(_.split(" ")) // 按照空格切分扁平化
.map((_, 1)) // (word,1) 二元组
.keyBy(_._1) // 根据第一个元素聚合
.sum(1) // 按照index 1 位置求和
sum.print()从Socket中读数据
不论从集合还是文件,我们读取的其实都是有界数据。在流处理的场景中,数据往往是无界的。一个简单的例子,就是我们之前用到的读取 socket 文本流。这种方式由于吞吐量小、稳定性较差,一般也是用于测试。
// 数据源读取socket文本流数据
val stream: DataStream[String] = env.socketTextStream("192.168.0.30", 7777)从Kafka读数据
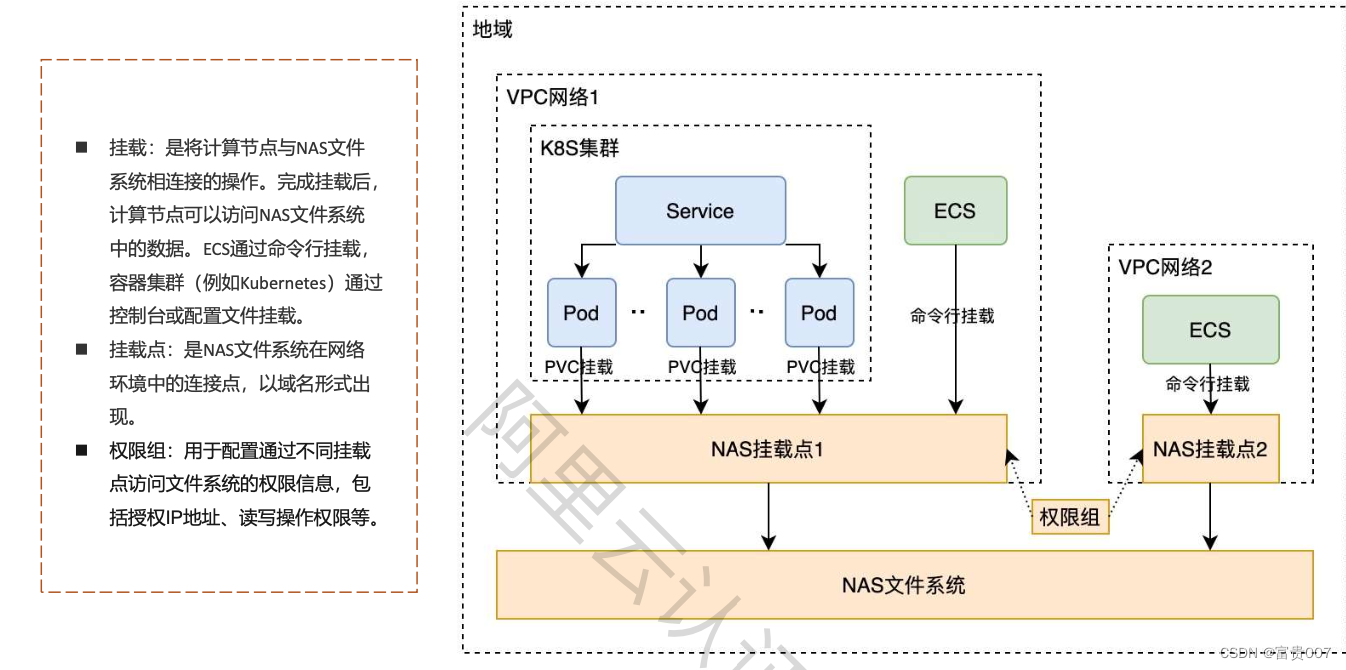
Kafka 作为分布式消息传输队列,是一个高吞吐、易于扩展的消息系统。而消息队列的传输方式,恰恰和流处理是完全一致的。所以可以说 Kafka 和 Flink 天生一对,是当前处理流式数据的双子星。在如今的实时流处理应用中,由 Kafka 进行数据的收集和传输,Flink 进行分析计算,这样的架构已经成为众多企业的首选。
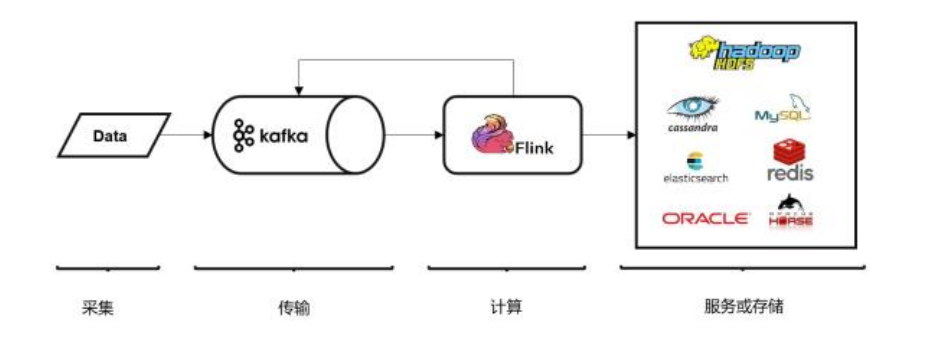
Flink 官方提供了连接工具 flink-connector-kafka,直接帮我们实现了一个消费者FlinkKafkaConsumer,它就是用来读取 Kafka 数据的 SourceFunction。所以想要以 Kafka 作为数据源获取数据,我们只需要引入 Kafka 连接器的依赖。Flink 官方提供的是一个通用的 Kafka 连接器,它会自动跟踪最新版本的 Kafka 客户端。目前最新版本只支持 0.10.0 版本以上的 Kafka。
添加pom文件配置
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>然后调用 env.addSource(),传入 FlinkKafkaConsumer 的对象实例就可以了。
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.kafka.clients.consumer.ConsumerConfig
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val props = new Properties()
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.0.30:9092")
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "flink_test")
val stream = env.addSource(new FlinkKafkaConsumer[String]("mytest", new SimpleStringSchema(), props))
stream.print()
env.execute()
}创建 FlinkKafkaConsumer 时需要传入三个参数:
第一个参数 topic,定义了从哪些主题中读取数据。可以是一个 topic,也可以是 topic列表,还可以是匹配所有想要读取的 topic 的正则表达式。当从多个 topic 中读取数据时,Kafka 连接器将会处理所有 topic 的分区,将这些分区的数据放到一条数据流中去。
第二个参数是一个 DeserializationSchema 或者 KeyedDeserializationSchema。Kafka 消息被存储为原始的字节数据,所以需要反序列化成 Java 或者 Scala 对象。上面代码中使用的 SimpleStringSchema,是一个内置的 DeserializationSchema,它只是将字节数组简单地反序列化成字符串。DeserializationSchema 和 KeyedDeserializationSchema 是公共接口,所以我们也可以自定义反序列化逻辑。
第三个参数是一个 Properties 对象,设置了 Kafka 客户端的一些属性。
自定义源算子(Source)
接下来我们创建一个自定义的数据源,实现 SourceFunction 接口。主要重写两个关键方法:run()和 cancel()。
run()方法:使用运行时上下文对象(SourceContext)向下游发送数据;
cancel()方法:通过标识位控制退出循环,来达到中断数据源的效果。
代码如下:
package com.myproject.entity
import com.myproject.entity.CC.Event
import org.apache.flink.streaming.api.functions.source.SourceFunction
import scala.util.Random
class ClickSource extends SourceFunction[Event] {
var running = true
override def run(ctx: SourceFunction.SourceContext[Event]): Unit = {
val random = new Random()
val users = List("zhangsan", "lisi", "wangwu", "laoliu")
val urls = List("baidu.com", "sohu.com/index.html", "sina.cn", "12306.com","https://zhuanlan.zhihu.com")
// 用标志位作为循环判断条件,不停地发出数据
while (running) {
val event = Event(users(random.nextInt(users.length)), urls(random.nextInt(urls.length)), System.currentTimeMillis())
// 调用ctx的方法向下游发送数据
ctx.collect(event)
// 每隔1s发送一条数据
Thread.sleep(1000)
}
}
override def cancel(): Unit = {
running = false
}
}这个数据源,我们后面会频繁使用,之后的代码若涉及 ClickSource()数据源,使用上面的代码就可以了。
下面的代码我们来读取一下自定义的数据源。有了自定义的 Source,接下来只要调用addSource()就可以了:
package com.myproject.analyse
import com.myproject.entity.ClickSource
import org.apache.flink.streaming.api.scala._
object DiySourceStreaming {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val lineDS = env.addSource(new ClickSource)
lineDS.print()
env.execute()
}
}








![【洛谷 P1044】[NOIP2003 普及组] 栈 题解(递归+记忆化搜索)](https://img-blog.csdnimg.cn/img_convert/7346d2e21fd71fd7ac38fcf158828860.png)