1--使用线程实现GPU上的矢量求和
完整代码:
# include <iostream>
# define N (33 * 1024)
__global__ void add(int* a, int* b, int* c){
int tid = threadIdx.x + blockIdx.x * blockDim.x;
while (tid < N){
c[tid] = a[tid] + b[tid];
tid += blockDim.x * gridDim.x;
}
}
int main(void){
int a[N], b[N], c[N];
int *dev_a, *dev_b, *dev_c;
// 在 GPU 分配内存
cudaMalloc( (void**)&dev_a, N * sizeof(int));
cudaMalloc( (void**)&dev_b, N * sizeof(int));
cudaMalloc( (void**)&dev_c, N * sizeof(int));
// 在 cpu 上赋值
for(int i = 0; i < N; i++){
a[i] = i;
b[i] = i * i;
}
// 将数据复制到GPU
cudaMemcpy(dev_a, a, N*sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, N*sizeof(int), cudaMemcpyHostToDevice);
add<<<128, 128>>>(dev_a, dev_b, dev_c);
cudaMemcpy(c, dev_c, N*sizeof(int), cudaMemcpyDeviceToHost);
// 验证是否正确执行
bool success = true;
for(int i = 0; i < N; i++){
if((a[i] + b[i]) != c[i]){
printf("Error: %d + %d != %d\n", a[i], b[i], c[i]);
success = false;
}
}
if(success) printf("We did it! \n");
// 释放内存
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}
核心代码分析:
add<<<128, 128>>>(dev_a, dev_b, dev_c);第一个参数 128 表示创建 128 个线程块,第二个参数 128 表示每个线程块包含 128 个线程,即创建了 128 × 128 个并行线程;
int tid = threadIdx.x + blockIdx.x * blockDim.x;计算每一个线程在所有线程中对应的索引值,threadIdx.x表示线程的索引,blockIdx.x表示线程块的索引,blockDim.x表示一个线程块的x长度;
while (tid < N){
c[tid] = a[tid] + b[tid];
tid += blockDim.x * gridDim.x;
}由于设置的线程块数目为 128,每个线程块线程的数目也是 128,共有 128 × 128 个并行线程,因此一次只能处理 128 × 128 个数据;
每次处理完 128 × 128 个数据后,索引值需要增加 128 × 128,即 tid += blockDim.x * gridDim.x;
2--使用线程实现波纹效果
完整代码:
#include "cuda.h"
#include "./common/book.h"
#include "./common/cpu_anim.h"
#define DIM 1024
#define PI 3.1415926535897932f
__global__ void kernel( unsigned char *ptr, int ticks ) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
// now calculate the value at that position
float fx = x - DIM/2;
float fy = y - DIM/2;
float d = sqrtf( fx * fx + fy * fy );
unsigned char grey = (unsigned char)(128.0f + 127.0f *
cos(d/10.0f - ticks/7.0f) /
(d/10.0f + 1.0f));
ptr[offset*4 + 0] = grey;
ptr[offset*4 + 1] = grey;
ptr[offset*4 + 2] = grey;
ptr[offset*4 + 3] = 255;
}
struct DataBlock {
unsigned char *dev_bitmap;
CPUAnimBitmap *bitmap;
};
void generate_frame( DataBlock *d, int ticks ) {
dim3 blocks(DIM/16, DIM/16);
dim3 threads(16, 16);
kernel<<<blocks, threads>>>( d->dev_bitmap, ticks );
HANDLE_ERROR( cudaMemcpy( d->bitmap->get_ptr(),
d->dev_bitmap,
d->bitmap->image_size(),
cudaMemcpyDeviceToHost ) );
}
void cleanup( DataBlock *d ) {
HANDLE_ERROR( cudaFree( d->dev_bitmap ) );
}
int main( void ) {
DataBlock data;
CPUAnimBitmap bitmap( DIM, DIM, &data );
data.bitmap = &bitmap;
HANDLE_ERROR( cudaMalloc( (void**)&data.dev_bitmap,
bitmap.image_size() ) );
bitmap.anim_and_exit( (void (*)(void*,int))generate_frame,
(void (*)(void*))cleanup );
}CMakeLists.txt:
cmake_minimum_required(VERSION 3.14)
project(Test1 LANGUAGES CUDA) # 添加支持CUDA语言
add_executable(main Test0307_2.cu)
target_link_libraries(main -lglut -lGLU -lGL)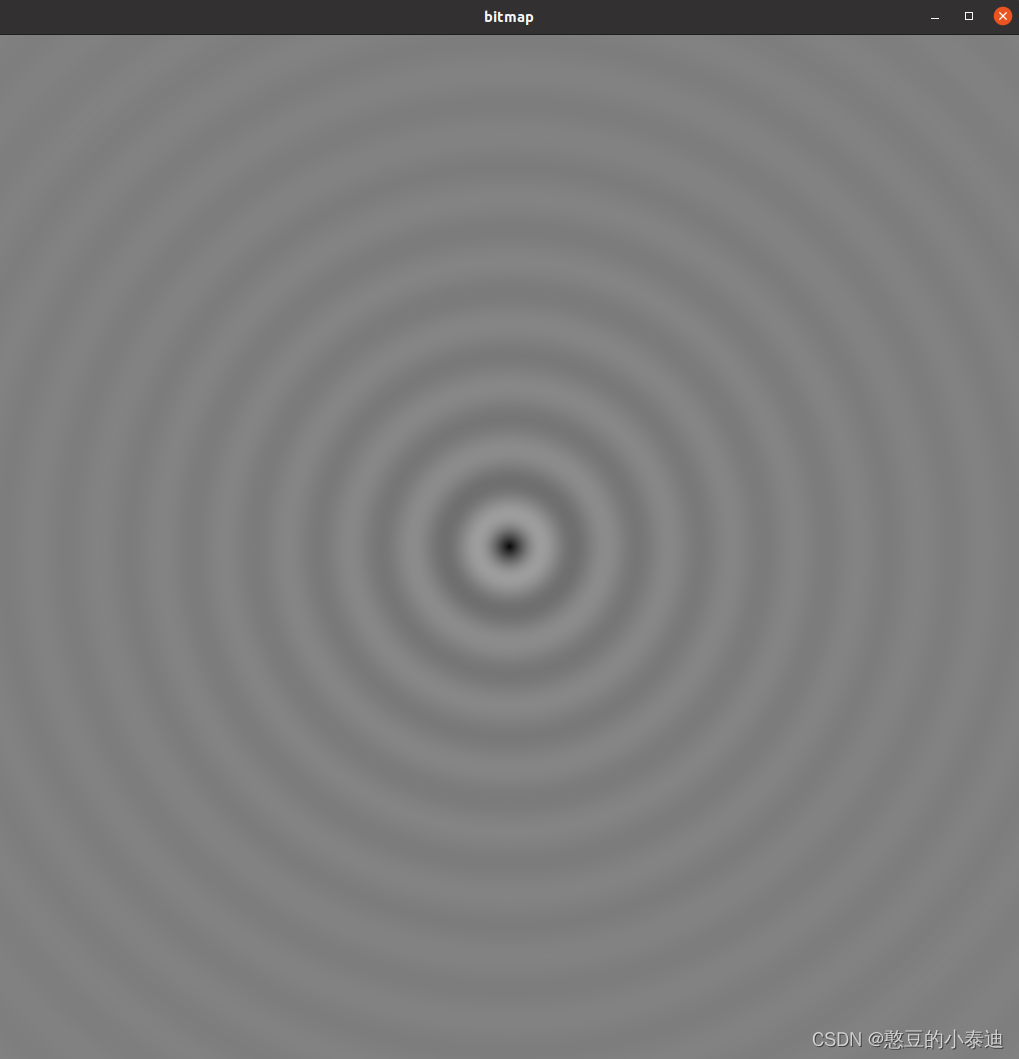
核心代码分析:
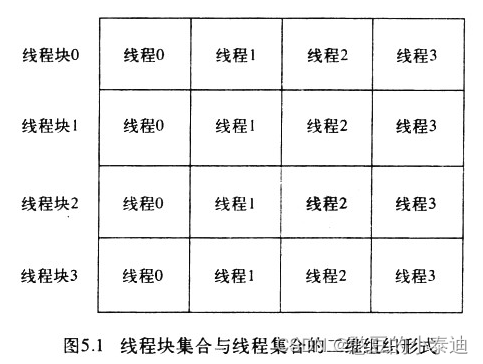
dim3 blocks(DIM/16, DIM/16);
dim3 threads(16, 16);
kernel<<<blocks, threads>>>( d->dev_bitmap, ticks );创建二维索引值的线程块和创建二维索引值的线程;
每一个线程有唯一的索引 (x, y);
在上述代码中,一副图像共有 DIM × DIM个像素,创建了 DIM/16 × DIM/16 个线程块,每一个线程块包含 16 × 16 个线程,一共有DIM × DIM个并行线程;因此每一个线程对应一个像素,每一个线程处理一个像素;
__global__ void kernel( unsigned char *ptr, int ticks ) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
// 生成波纹的代码
float fx = x - DIM/2;
float fy = y - DIM/2;
float d = sqrtf( fx * fx + fy * fy );
unsigned char grey = (unsigned char)(128.0f + 127.0f *
cos(d/10.0f - ticks/7.0f) /
(d/10.0f + 1.0f));
ptr[offset*4 + 0] = grey;
ptr[offset*4 + 1] = grey;
ptr[offset*4 + 2] = grey;
ptr[offset*4 + 3] = 255;
}每一个线程的索引 (x, y) 通过以下代码进行计算:
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;其偏移量通过以下代码进行计算:
int offset = x + y * blockDim.x * gridDim.x;
未完待续!