Spark 应用调优
- 人数统计
- 优化
- 摇号次数分布
- 优化
- Shuffle 常规优化
- 数据分区合并
- 加 Cache
- 优化
- 中签率的变化趋势
- 中签率局部洞察
- 优化
- 倍率分析
- 优化
表信息 :
- apply : 申请者 : 事实表
- lucky : 中签者表 : 维度表
- 两张表的 Schema ( batchNum,carNum ) : ( 摇号批次,申请编号 )
- 分区键都是 batchNum
运行环境 :

配置项设置 :

优化点 :

人数统计
统计至今,参与摇号的总人次和幸运的中签者人数
val rootPath: String = _
// 申请者数据(因为倍率的原因,每一期,同一个人,可能有多个号码)
val hdfs_path_apply = s"${rootPath}/apply"
val applyNumbersDF = spark.read.parquet(hdfs_path_apply)
applyNumbersDF.count
// 中签者数据
val hdfs_path_lucky = s"${rootPath}/lucky"
val luckyDogsDF = spark.read.parquet(hdfs_path_lucky)
luckyDogsDF.count
SQL 实现 :
select
count(*)
from applyNumbersDF
select
count(*)
from luckyDogsDF
去重计数,得到实际摇号数 :
val applyDistinctDF = applyNumbersDF.select("batchNum", "carNum").distinct
applyDistinctDF.count
SQL 实现 :
select
count(distinct batchNum ,carNum)
from applyDistinctDF
优化
分析 : 共有 3 个 Actions,会触发 3 个 Spark Jobs
用 Cache 原则:
- RDD/DataFrame/Dataset 引用次数为 1,坚决不用 Cache
- 当引用次数大于 1,且运行成本占比超过 30%,考虑用 Cache
优化 :
- 利用 Cache 机制来提升执行性能
val rootPath: String = _
// 申请者数据(因为倍率的原因,每一期,同一个人,可能有多个号码)
val hdfs_path_apply = s"${rootPath}/apply"
val applyNumbersDF = spark.read.parquet(hdfs_path_apply)
// 缓存
applyNumbersDF.cache
applyNumbersDF.count
val applyDistinctDF = applyNumbersDF.select("batchNum", "carNum").distinct
applyDistinctDF.count
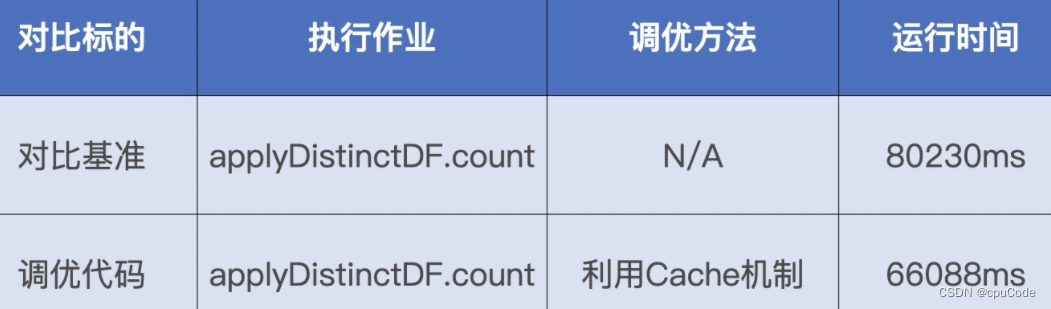
摇号次数分布
不同人群摇号次数的分布 :
- 统计所有申请者累计参与了多少次摇号
- 所有中签者摇了多少次号才能幸运地摇中签
统计所有申请者的分布情况
val result02_01 = applyDistinctDF
.groupBy(col("carNum")).agg(count(lit(1)).alias("x_axis"))
.groupBy(col("x_axis")).agg(count(lit(1)).alias("y_axis"))
.orderBy("x_axis")
result02_01.write.format("csv").save("_")
SQL 实现 :
with t1 as (
select
carNum,
count(1) as x_axis
from applyDistinctDF
group by carNum
)
select
x_axis,
count(1) as y_axis
from t1
group by x_axis
order by x_axis
优化
分析 : 共两次 Shuffle。以 carNum 做分组计数, 以 x_axis 列再次做分组计数
Shuffle 的本质 : 数据的重新分发,凡是有 Shuffle 地方就要关注数据分布
- 对过小的数据分片,要对进行合并
Shuffle 常规优化
优化点 : 减少 Shuffle 过程中磁盘与网络的请求次数
Shuffle 的常规优化:
- By Pass 排序操作 : 条件:计算逻辑不涉及聚合或排序;Reduce 的并行度 <
spark.shuffle.sort.bypassMergeThreshold - 调整读写缓冲区 : 条件 : Execution Memory 大
对读写缓冲区做调优 :
spark.shuffle.file.buffer: Map 写入缓冲区大小spark.reducer.maxSizeInFlight: Reduce 读缓冲区大小
读写缓冲区是以 Task 为粒度进行设置,所以调整这些参数时, 扩大 50%
| 默认 | 调优 |
|---|---|
| spark.shuffle.file.buffer = 32KB | spark.shuffle.file.buffer = 48 KB (32KB * 1.5) |
| spark.reducer.maxSizeInFlight = 48 MB | spark.reducer.maxSizeInFlight = 72MB ( 48MB * 1.5) |
性能对比 :

数据分区合并
优化点 : 提升 Reduce 阶段的 CPU 利用率
该数据集在内存的精确大小 :
def sizeNew(func: => DataFrame, spark: => SparkSession): String = {
val result = func
val lp = result.queryExecution.logical
val size = spark.sessionState.executePlan(lp).optimizedPlan.stats.sizeInByte
"Estimated size: " + size/1024 + "KB"
}
把 applyDistinctDF 作实参,调用 sizeNew 函数,返回大小 = 2.6 GB
- 将数据集尺寸/并行度(spark.sql.shuffle.partitions = 200) = Reduce 每个数据分片的存储大小 ( 2.6 GB / 200 = 13 MB)
- 数据分片大小在 200 MB 左右为宜,13 MB 太小
优化设置 :
- 计算集群配置 Executors core = 3 * 2 = 6,其
minPartitionNum为 6
# 开启 AQE
spark.sql.adaptive.enabled = true
# 自动分区合并
spark.sql.adaptive.coalescePartitions.enabled = true
# 合并后的大小
spark.sql.adaptive.advisoryPartitionSizeInBytes = 160MB/200MB/210MB/400MB
# 分区合并后的最小分区数
spark.sqladaptive.coalescePartitions.minPartitionNum = 6
总结 :
- 并行度过高、数据分片过小,CPU 调度开销会变大,执行性能也变差
- 检验值 : 分片粒度为 200 MB 左右时,执行性能是最优的
- 并行度过低、数据分片过大,CPU 数据处理开销也会过大,执行性能会锐减
性能对比 :

加 Cache
Cache : 避免数据集在磁盘中的重复扫描与重复计算
applyDistinctDF.cache
applyDistinctDF.count
val result02_01 = applyDistinctDF
.groupBy(col("carNum")).agg(count(lit(1)).alias("x_axis"))
.groupBy(col("x_axis")).agg(count(lit(1)).alias("y_axis"))
.orderBy("x_axis")
result02_01.write.format("csv").save("_")
性能对比 :

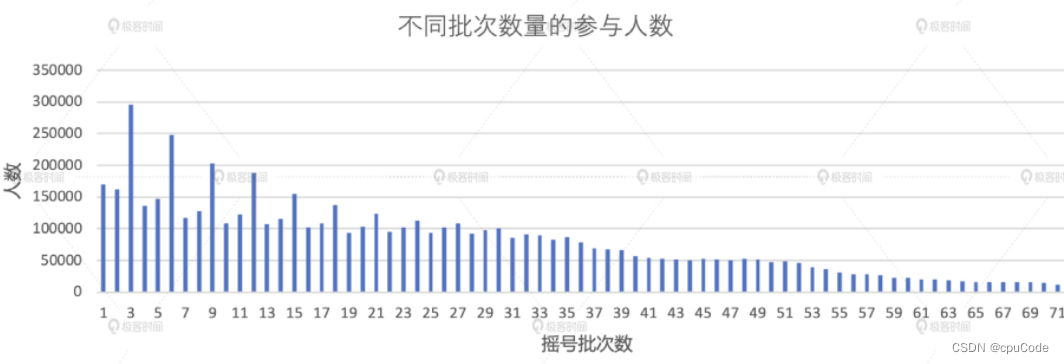
得到中签者的摇号次数
val result02_02 = applyDistinctDF
.join(luckyDogsDF.select("carNum"), Seq("carNum"), "inner")
.groupBy(col("carNum")).agg(count(lit(1)).alias("x_axis"))
.groupBy(col("x_axis")).agg(count(lit(1)).alias("y_axis"))
.orderBy("x_axis")
result02_02.write.format("csv").save("_")
SQL 实现 :
with t3 as (
select
carNum,
count(1) as x_axis
from applyDistinctDF t1 join luckyDogsDF t2
on t1.carNum = t2.carNum
group by carNum
)
select
x_axis,
count(1) as y_axis
from t3
group by x_axis
order by x_axis
优化
分析 : 计算中有一次数据关联,两次分组、聚合,排序
- applyDistinctDF 有 1.35 亿条记录
- luckyDogsDF 有 115 w条记录
- 大表 Join 小表,最先想用广播变量
用广播变量来优化大小表关联计算 :
- 估算小表在内存中的存储大小
- 设置广播阈值
spark.sql.autoBroadcastJoinThreshold
用 sizeNew 计算 luckyDogsDF ,得到大小 = 18.5MB
设置广播阈值要大于 18.5MB ,即 : 设置为 20MB :
spark.sql.autoBroadcastJoinThreshold = 20MB
性能对比 :

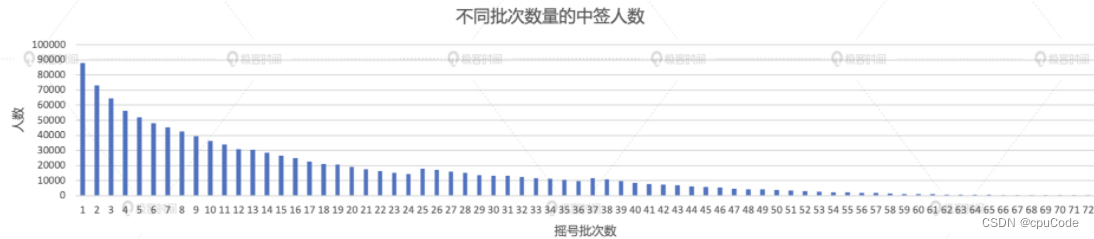
中签率的变化趋势
计算中签率,分别统计每个摇号批次中的申请者和中签者人数
// 统计每批次申请者的人数
val apply_denominator = applyDistinctDF
.groupBy(col("batchNum"))
.agg(count(lit(1)).alias("denominator"))
// 统计每批次中签者的人数
val lucky_molecule = luckyDogsDF
.groupBy(col("batchNum"))
.agg(count(lit(1)).alias("molecule"))
val result03 = apply_denominator
.join(lucky_molecule.select, Seq("batchNum"), "inner")
.withColumn("ratio", round(col("molecule")/ col("denominator"), 5))
.orderBy("batchNum")
result03.write.format("csv").save("_")
SQL 实现 :
with t1 as (
select
batchNum,
count(1) as denominator
from applyDistinctDF
group by batchNum
),
t2 as (
select
batchNum,
count(1) as molecule
from luckyDogsDF
group by batchNum
)
select
batchNum,
round(molecule/denominator, 5) as ratio
from t1 join t2 on t1.batchNum = t2.batchNum
order by batchNum
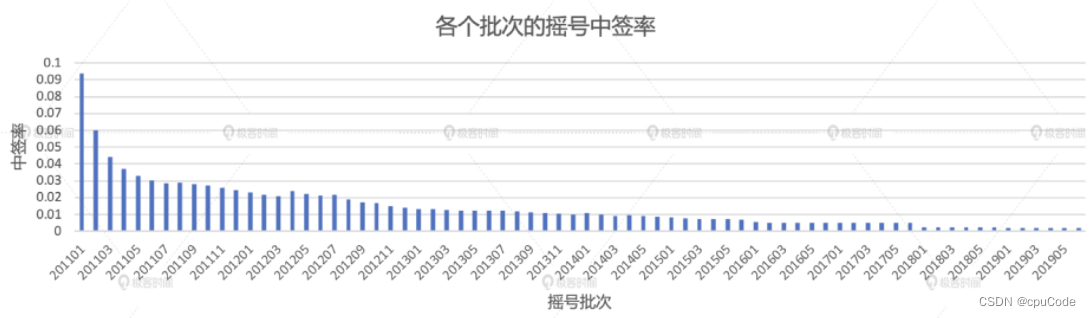
中签率局部洞察
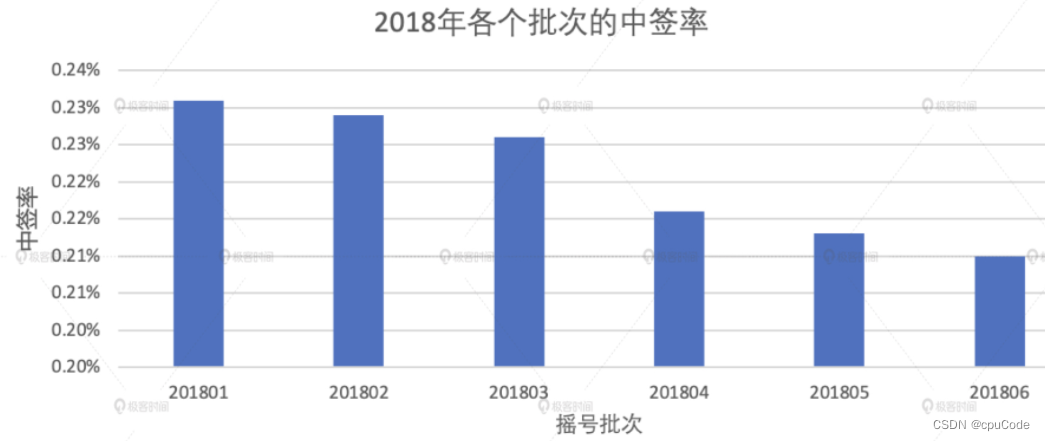
统计 2018 年的中签率
// 筛选出2018年的中签数据,并按照批次统计中签人数
val lucky_molecule_2018 = luckyDogsDF
.filter(col("batchNum").like("2018%"))
.groupBy(col("batchNum"))
.agg(count(lit(1)).alias("molecule"))
// 通过与筛选出的中签数据按照批次做关联,计算每期的中签率
val result04 = apply_denominator
.join(lucky_molecule_2018, Seq("batchNum"), "inner")
.withColumn("ratio", round(col("molecule")/ col("denominator"), 5))
.orderBy("batchNum")
result04.write.format("csv").save("_")
SQL 实现 :
with t1 as (
select
batchNum,
count(1) as molecule
from luckyDogsDF
where batchNum like '2018%'
group by batchNum
)
select
batchNum,
round(molecule/denominator, 5)
from apply_denominator t2 on t1.batchNum = t2.batchNum
order by batchNum
优化
DPP 的条件 :
- 事实表必须是分区表,且分区字段(可以是多个)必须包含 Join Key
- DPP 仅支持等值 Joins,不支持大于、小于这种不等值关联关系
- 维表过滤后的数据集,要小于广播阈值,调整
spark.sql.autoBroadcastJoinThreshold
DPP 优化 :
- 降低事实表 applyDistinctDF 的磁盘扫描量
applyDistinctDF.select("batchNum", "carNum").distinct
applyDistinct.count
性能对比 :

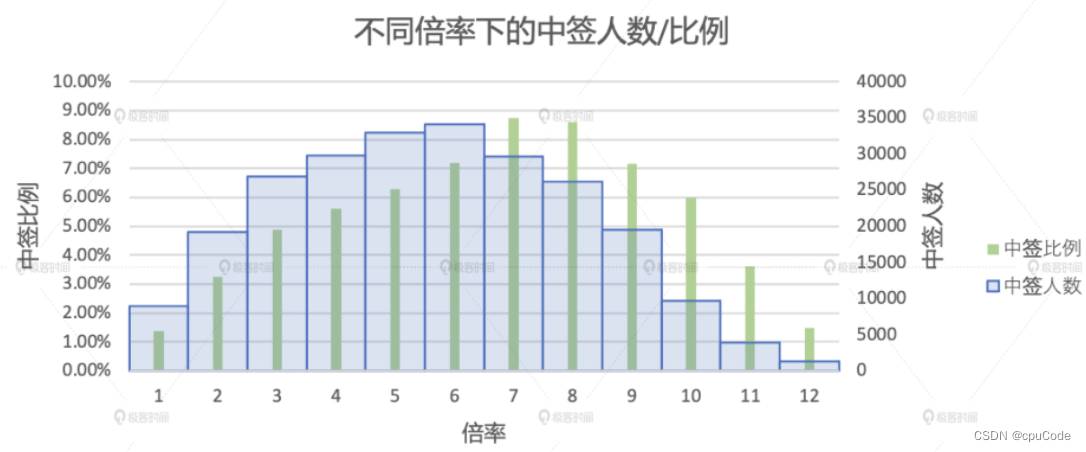
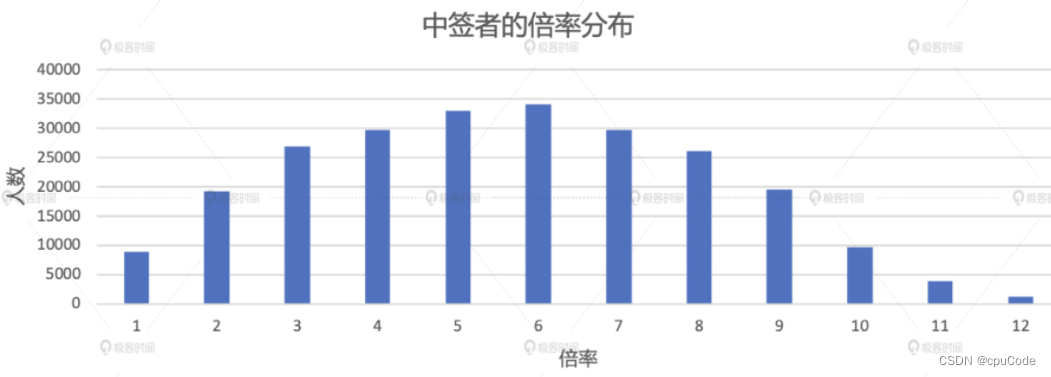
倍率分析
倍率的分布情况 :
- 不同倍率下的中签人数
- 不同倍率下的中签比例
2016 年后的不同倍率下的中签人数 :
val result05_01 = applyNumbersDF
.join(luckyDogsDF.filter(col("batchNum") >= "201601").select("carNum"), Seq("carNum"), "inner")
.groupBy(col("batchNum"), col("carNum")).agg(count(lit(1)).alias("multiplier"))
.groupBy("carNum").agg(max("multiplier").alias("multiplier"))
.groupBy("multiplier").agg(count(lit(1)).alias("cnt"))
.orderBy("multiplier")
result05_01.write.format("csv").save("_")
with t3 as (
select
batchNum,
carNum,
count(1) as multiplier
from applyNumbersDF t1
join luckyDogsDF t2 on t1.carNum = t2.carNum
where t2.batchNum >= '201601'
group by batchNum, carNum
),
t4 as (
select
carNum,
max(multiplier) as multiplier
from t3
group by carNum
)
select
multiplier,
count(1) as cnt
from t4
group by multiplier
order by multiplier;
优化
关联中的 Join Key 是 carNum (非分区键),所以无法用 DPP 机制优化
将大表 Join 小表 , SMJ 转 BHJ :
- 计算 luckyDogsDF 的内存大小,确保 < 广播阈值,利用 Spark SQL 的静态优化机制将 SMJ 转为 BHJ
- 确保过滤后 luckyDogsDF < 广播阈值,利用 Spark SQL 的 AQE 机制动态将 SMJ 转为 BHJ
# 静态BHJ
spark.sql.autoBroadcastJoinThreshold = 20MB
# AQE 动态BHJ
spark.sql.autoBroadcastJoinThreshold = 10MB
性能对比 :

计算不同倍率人群的中签比例
// Step01: 过滤出2016-2019申请者数据,统计出每个申请者在每期内的倍率,并在所有批次中选取
val apply_multiplier_2016_2019 = applyNumbersDF
.filter(col("batchNum") >= "201601")
.groupBy(col("batchNum"), col("carNum")).agg(count(lit(1)).alias("multiplier"))
.groupBy("carNum").agg(max("multiplier").alias("multiplier"))
.groupBy("multiplier").agg(count(lit(1)).alias("apply_cnt"))
// Step02: 将各个倍率下的申请人数与各个倍率下的中签人数左关联,并求出各个倍率下的中签率
val result05_02 = apply_multiplier_2016_2019
.join(result05_01.withColumnRenamed("cnt", "lucy_cnt"), Seq("multiplier"), "left")
.na.fill(0)
.withColumn("ratio", round(col("lucy_cnt")/ col("apply_cnt"), 5))
.orderBy("multiplier")
result05_02.write.format("csv").save("_")
SQL 实现 :
with t5 as (
select
batchNum,
carNum
count(1) as multiplier
from applyNumbersDF
where batchNum >= '201601'
group by batchNum, carNum
),
t6 as (
select
carNum,
max(multiplier) as multiplier
from t1
group by carNum
),
t7 as (
select
multiplier,
count(1) as apply_cnt
from t2
group by multiplier
)
select
multiplier,
round(coalesce(lucy_cnt, 0)/ apply_cnt, 5) as ratio
from t7 left
left join t5 on t5.multiplier = t7.multiplier
order by multiplier;