这篇文章所讲的事情
初探分布式数据库这种有状态服务是如何保证系统的高可用的,可能会有勘误,欢迎指导。
正文
分布式数据库在说高可用的时候,主要是在讲宕机和网络分区时,系统的高可用如何保证,这点和我们在线上应用稳定性治理中所说的高可用有些许不同,表现在线上应用稳定性治理,需要在容量,依赖,线上变更三个维度去做系统稳定性治理,而分布式数据库的高可用,是在说线上应用稳定性治理中-依赖的细分方面:宕机和网络分区场景下如何做系统高可用,即分布式数据库所说的高可用是线上应用稳定性治理的一个方面。
分布式数据库高可用实现的一般思路
分布式数据库在应对宕机和网络分区故障的思路为数据副本机制,
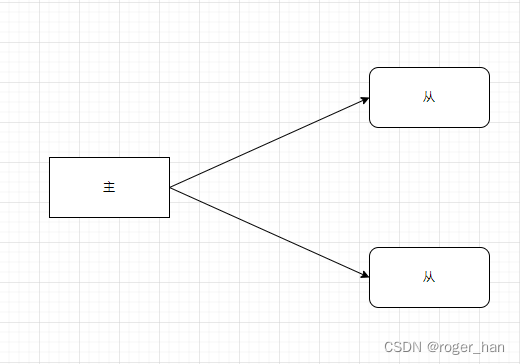
数据副本机制实现的一般思路为主从架构,
主从架构下保证数据一致的机制为复制状态机。
如下为主从架构示意图:
如下是raft算法对复制状态机的描述
复制状态机通常使用复制日志实现,每个服务器存储一个包含一系列命令的日志,其状态机按顺序执行日志中的命令。
每个日志中命令都相同并且顺序也一样,因此每个状态机处理相同的命令序列。 这样就能得到相同的状态和相同的输出序列。
复制状态机在正常情况下是能够保证主从数据一致的,但是在主宕机的情况下,如何保证集群数据的一致性,这是一个新的问题,后面会展开说。
宕机情况下的高可用
宕机情况分为两种,一种为主节点宕机,一种为从节点宕机。
主节点宕机
在多副本的情况下,主节点会是一个单点,当主节点挂掉后,整个系统将无法运行,这时候我们需要对主节点进行主从切换。
单一哨兵机制
为了实现当主节点宕机时,能够进行主从切换,引入了哨兵机制,单独部署一个哨兵服务,对整体数据库集群进行监控,当主节点挂掉后,选择从节点晋升为主节点继续提供服务,典型的例子为mysql的MHA,其整体架构如下图。
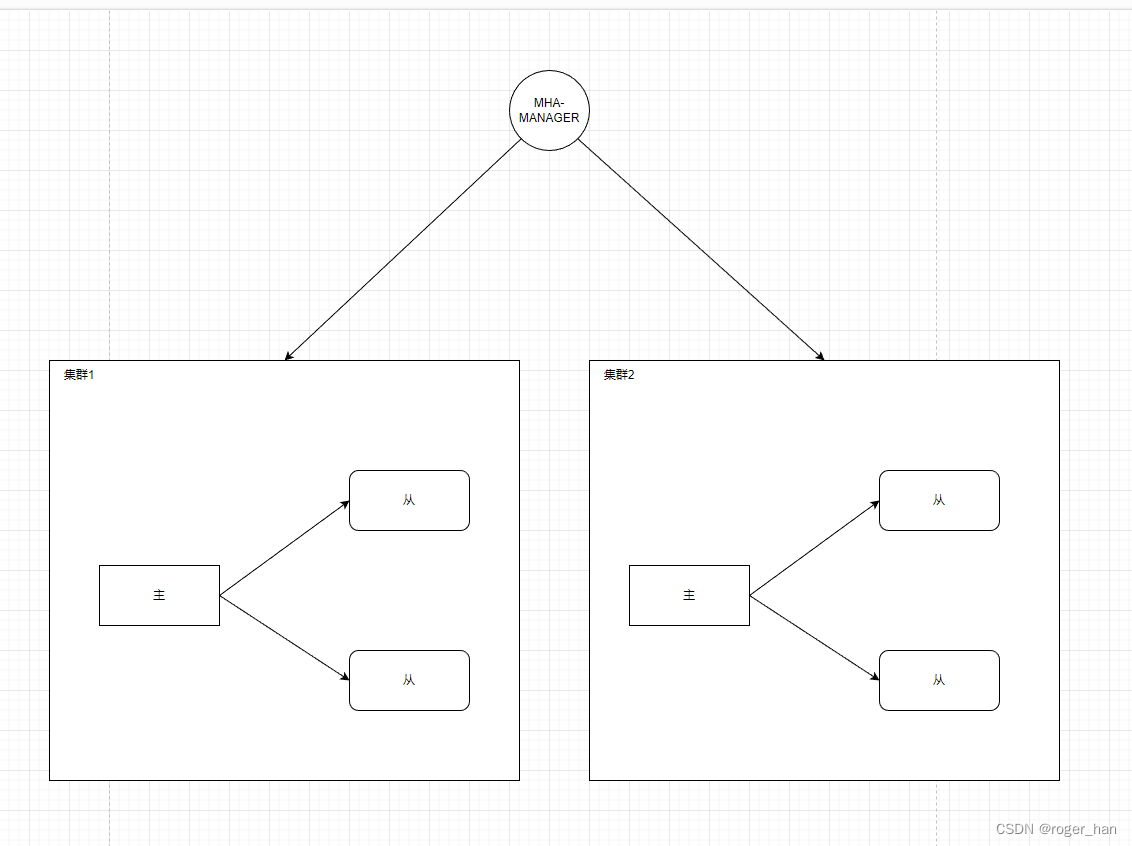
哨兵集群
但这又引入了另外一个问题:当哨兵宕机了怎么办?
解决方案是哨兵也做多副本机制,由于决策只能是一个节点进行决策,这个节点为集群中的主节点,其余节点为备份节点,所以仍然实现选主功能,典型的算法如raft,zab等。
整体架构图变成了这样:
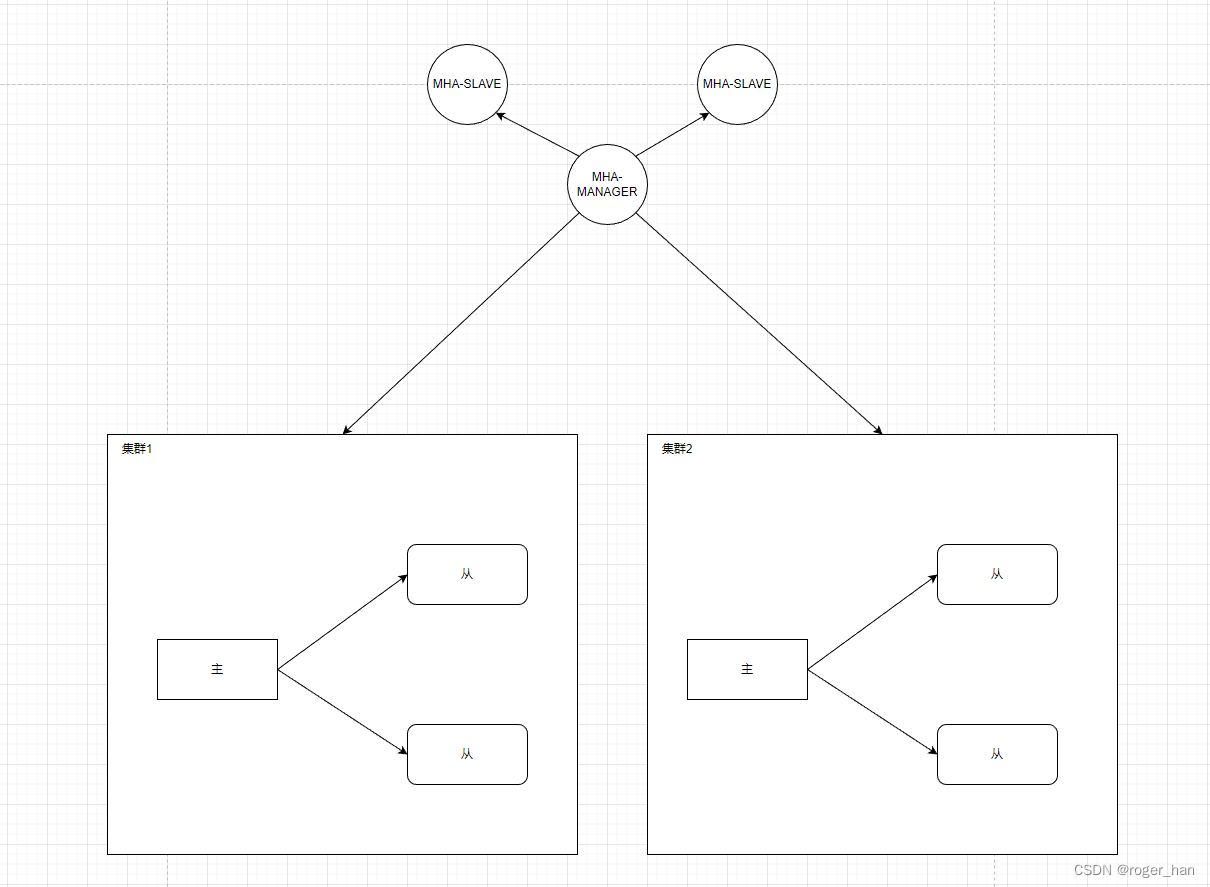
哨兵与数据库部署同一机器
这时候就出现一个非常有意思的情况,既然哨兵通过分布式共识算法实现了高可用(2n+1个节点,挂掉n个集群不受影响),那么不如直接让数据库主从实例结合分布式共识算法,不需要再部署哨兵节点,直接实现分布式数据库副本的高可用了,这就是RadonDB下的xenon做的事情,但这样做也有缺点,即这些共识协议都必须保证数据写入n+1台机器才能确认成功,写入效率上比mysql的异步复制低一些。
从节点宕机
从节点宕机的检测,仍然是由哨兵负责,哨兵会在从节点宕机后进行报警。
由于从节点为备份节点,宕机后对整个集群的影响并不大,故大多数从库宕机后,并没有让哨兵重新申请机器制作从库的需要,后续的处理是,如果从库在规定时间内(主库log存在的时间点)重新启动,则从库会继续从主库同步日志,如果从库在规定的时间内未重新启动,则需要重新制作新的从库。
网络分区
网络分区会带来两个问题,第一个是哨兵与数据库所有机器网络分区后的误判问题,第二个是哨兵与主节点网络分区后的误判导致集群主从切换,进而导致的脑裂问题。
在哨兵集群一章中,哨兵集群与数据库集群是分开部署的,如果哨兵集群与数据库集群之间的网络产生了分区,那么哨兵集群则无法探测数据库集群的状态,并认定所有机器全部死亡,这时候判断是错误的,可能主数据库还在正常运行。
解决方案正好为哨兵与数据库部署同一机器这章描述的方式一样,只要两者结合即可,且分布式共识算法的2n+1 台机器中n+1台机器选主才能成功的特性,又解决了脑裂问题。
副本数据一致性
在正常集群运行情况下,复制状态机是可以满足主从副本数据的一致性的,但是当主库出现问题而宕机,集群发生主从切换时,从库晋升,如果主库到从库是全异步复制,则会导致数据的丢失,各种分布式共识算法都要求在2n+1的集群中写入n+1台机器,才认定写入成功,则是为了避免数据库在主宕机的情况下出现数据丢失。
万能的共识算法与分布式数据库的高可用
共识算法的优点与缺点
从上面的章节中,我们看到分布式共识算法出现的频率非常高,他解决了分布式数据库中的主从切换问题(例如),还解决了主从节点的数据一致性问题,还解决了网络分区导致的脑裂问题,故我们看到一个不丢失数据的高可用的集群的最终形态(以笔者脑子里的存货所推理出来的最终形态),即以分布式共识算法为基础实现的分布式数据库,业界案例有TIDB,xenon等。
但由于分布式共识算法数据必须写入n + 1台机器才能够认为写入成功,这导致在一些高性能的数据库上,是无法采用此类算法做高可用,他们在选型上进行了trade off,例如redis cluster,其不能保证脑裂与主宕机时的数据无丢失,但其保留了自身的高性能。
共识算法在主库宕机情况下的自动容灾是如何保证数据不丢失的
大部分的共识算法是通过以下两点进行保证的
- 在2n+1的集群中,写入n+1个节点才算写入成功。
- 在2n+1的集群中,在m ( m <= n )台机器宕机的情况下,从剩下的n+1台机器中,选出拥有最新日志的那台机器做主(在剩下的n + 1台机器中,必然有一台是有最新的commit的日志的,找拥有最高的日志的节点,一定包括最新的commit日志)。
共识算法在网络分区情况下是如何避免脑裂的
主宕机的情况下,在 2n + 1 的集群中,一定有一个多数派集群,这个集群包含 n + 1 的集群机器,这个多数派集群中,所有机器都同意其作为新的主,这样才能够选主成功,故当一个2n + 1的集群分裂为n,n + 1两个集群,而主在n这个集群内,此时n集群内的主无法完成写入动作,因为一个写入动作需要 n + 1 的机器进行确认,而这时n集群只有n台机器。并且n集群内是无法选出主的,只有n+1的集群可以选出主。
参考资料
xenon
mysql高可用方案




![[ 攻防演练演示篇 ] 利用 shiro 反序列化漏洞获取主机权限](https://img-blog.csdnimg.cn/9c0f01c319d541cf85b8d74ac5eae845.png)


![[oeasy]python0100_wintel联盟_intel_微软_microsoft_msDOS_基尔代尔](https://img-blog.csdnimg.cn/img_convert/61b0b30afb84344a40c39e0fd204f742.png)