欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
本篇概览
-
本文是《Strimzi Kafka Bridge(桥接)实战之》系列的第二篇,咱们直奔bridge的重点:常用接口,用实际操作体验如何用bridge完成常用的消息收发业务
-
官方的openapi接口文档地址 : https://strimzi.io/docs/bridge/in-development/#_openapi
-
整篇文章由以下内容构成:
- 准备工作:创建topic
- 生产消息
- 消费消息,strimzi bridge消费消息的逻辑略有些特殊,就是要提前创建strimzi bridge consumer,再通过consumer来调用拉取消息的接口
- 完成本篇实战后,相信您已经可以数量的通过http来使用kafka的服务了
准备工作:创建topic
- 遗憾的是,bridge未提供创建topic的API,所以咱们还是用命令来创建吧
- ssh登录kubernetes的宿主机
- 执行创建名为bridge-quickstart-topic的topic,共四个分区
kubectl -n aabbcc \
run kafka-producer \
-ti \
--image=quay.io/strimzi/kafka:0.32.0-kafka-3.3.1 \
--rm=true \
--restart=Never \
-- bin/kafka-topics.sh \
--bootstrap-server my-cluster-kafka-bootstrap:9092 \
--create \
--topic bridge-quickstart-topic \
--partitions 4 \
--replication-factor 1
- 检查topic创建是否成功
kubectl -n aabbcc \
run kafka-producer \
-ti \
--image=quay.io/strimzi/kafka:0.32.0-kafka-3.3.1 \
--rm=true \
--restart=Never \
-- bin/kafka-topics.sh \
--bootstrap-server my-cluster-kafka-bootstrap:9092 \
--describe \
--topic bridge-quickstart-topic
- 如下图,可见topic的创建符合预期
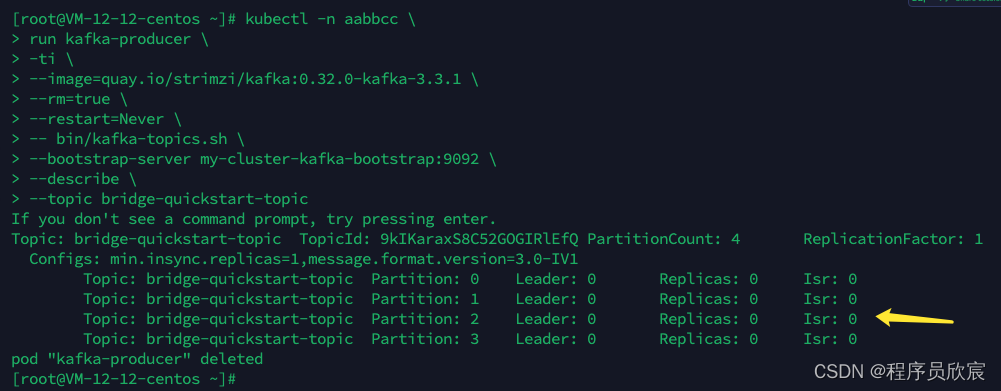
- 接下来的操作都是向bridge发送http请求完成的,我这边宿主机的IP地址是192.168.0.1,bridge的NodePort端口号31331
查看指定topic的详情
- 如下请求,可以取得topicbridge-quickstart-topic的详情
curl -X GET \
http://192.168.0.1:31331/topics/bridge-quickstart-topic
- 收到响应如下,是这个topic的详细信息
{
"name": "bridge-quickstart-topic",
"configs": {
"compression.type": "producer",
"leader.replication.throttled.replicas": "",
"message.downconversion.enable": "true",
"min.insync.replicas": "1",
"segment.jitter.ms": "0",
"cleanup.policy": "delete",
"flush.ms": "9223372036854775807",
"follower.replication.throttled.replicas": "",
"segment.bytes": "1073741824",
"retention.ms": "604800000",
"flush.messages": "9223372036854775807",
"message.format.version": "3.0-IV1",
"max.compaction.lag.ms": "9223372036854775807",
"file.delete.delay.ms": "60000",
"max.message.bytes": "1048588",
"min.compaction.lag.ms": "0",
"message.timestamp.type": "CreateTime",
"preallocate": "false",
"min.cleanable.dirty.ratio": "0.5",
"index.interval.bytes": "4096",
"unclean.leader.election.enable": "false",
"retention.bytes": "-1",
"delete.retention.ms": "86400000",
"segment.ms": "604800000",
"message.timestamp.difference.max.ms": "9223372036854775807",
"segment.index.bytes": "10485760"
},
"partitions": [
{
"partition": 0,
"leader": 0,
"replicas": [
{
"broker": 0,
"leader": true,
"in_sync": true
}
]
},
{
"partition": 1,
"leader": 0,
"replicas": [
{
"broker": 0,
"leader": true,
"in_sync": true
}
]
},
{
"partition": 2,
"leader": 0,
"replicas": [
{
"broker": 0,
"leader": true,
"in_sync": true
}
]
},
{
"partition": 3,
"leader": 0,
"replicas": [
{
"broker": 0,
"leader": true,
"in_sync": true
}
]
}
]
}
批量生产消息(同步)
- 试试bridge提供的批量生产消息的API,以下命令会生产了三条消息,第一条通过key的hash值确定分区,第二条用partition参数明确指定了分区是2,第三条的分区是按照轮询策略更新的
curl -X POST \
http://42.193.162.141:31331/topics/bridge-quickstart-topic \
-H 'content-type: application/vnd.kafka.json.v2+json' \
-d '{
"records": [
{
"key": "my-key",
"value": "sales-lead-0001"
},
{
"value": "sales-lead-0002",
"partition": 2
},
{
"value": "sales-lead-0003"
}
]
}'
- bridge响应如下,会返回每一条消息的partition和offset,这就是同步消息的特点,等到meta信息更新完毕后才会返回
{
"offsets": [{
"partition": 0,
"offset": 0
}, {
"partition": 2,
"offset": 0
}, {
"partition": 3,
"offset": 0
}]
}
批量生产消息(异步)
- 有的场景下,例如追求高QPS并且对返回的meta信息不关注,可以考虑异步的方式发送消息,也就是说bridge收到响应后立即返回200,这种异步模式和前面的同步模式只有一个参数的差别:在请求url中增加async=true即可
curl -X POST \
http://42.193.162.141:31331/topics/bridge-quickstart-topic?async=true \
-H 'content-type: application/vnd.kafka.json.v2+json' \
-d '{
"records": [
{
"key": "my-key",
"value": "sales-lead-0001"
},
{
"value": "sales-lead-0002",
"partition": 2
},
{
"value": "sales-lead-0003"
}
]
}'
- 没有响应body,请您自行请求感受一下,响应明显比同步模式快
查看partition
- 查看tipic的parition情况
curl -X GET \
http://42.193.162.141:31331/topics/bridge-quickstart-topic/partitions
- 响应
[{
"partition": 0,
"leader": 0,
"replicas": [{
"broker": 0,
"leader": true,
"in_sync": true
}]
}, {
"partition": 1,
"leader": 0,
"replicas": [{
"broker": 0,
"leader": true,
"in_sync": true
}]
}, {
"partition": 2,
"leader": 0,
"replicas": [{
"broker": 0,
"leader": true,
"in_sync": true
}]
}, {
"partition": 3,
"leader": 0,
"replicas": [{
"broker": 0,
"leader": true,
"in_sync": true
}]
}]
- 查看指定partition
curl -X GET \
http://42.193.162.141:31331/topics/bridge-quickstart-topic/partitions/0
- 响应
{
"partition": 0,
"leader": 0,
"replicas": [{
"broker": 0,
"leader": true,
"in_sync": true
}]
}
- 查看指定partition的offset情况
curl -X GET \
http://42.193.162.141:31331/topics/bridge-quickstart-topic/partitions/0/offsets
- 响应
{
"beginning_offset": 0,
"end_offset": 5
}
创建bridge consumer
- 通过bridge消费消息,有个特别且重要的前提:创建bridge consumer,只有先创建了bridge consumer,才能顺利从kafka的broker取到消息
- 以下命令创建了一个bridge consumer,各参数的含义稍后会说明
curl -X POST http://42.193.162.141:31331/consumers/bridge-quickstart-consumer-group \
-H 'content-type: application/vnd.kafka.v2+json' \
-d '{
"name": "bridge-quickstart-consumer",
"auto.offset.reset": "earliest",
"format": "json",
"enable.auto.commit": false,
"fetch.min.bytes": 16,
"consumer.request.timeout.ms": 300000
}'
- 上述请求的参数解释:
- 对应kafka的group为bridge-quickstart-consumer-group
- 此bridge consumer的name等于bridge-quickstart-consumer
- 参数enable.auto.commit表示是否自动提交offset,这里设置成false,表示无需自动提交,后面的操作中会调用API请求来更新offset
- 参数fetch.min.bytes要特别注意,其值等于16,表示唯有消息内容攒够了16字节,拉取消息的请求才能获取到消息,如果消息内容长度不到16字节,收到的响应body就是空
- 参数consumer.request.timeout.ms也要注意,这里我设置了300秒,如果超过300秒没有去拉取消息,这个消费者就会被kafka移除(被移除后如果再去拉取消息,kafka会报错:Offset commit cannot be completed since the consumer is not part of an active group for auto partition assignment; it is likely that the consumer was kicked out of the grou)
- 收到响应如下,instance_id表示这个bridge consumer的身份id,base_uri则是订阅消息时必须使用的请求地址
{
"instance_id": "bridge-quickstart-consumer",
"base_uri": "http://42.193.162.141:31331/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer"
}
如何删除bridge consumer
- 以下命令可以删除consumer,重点是将身份id放入path中
curl -X DELETE http://42.193.162.141:31331/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer
订阅指定topic的消息
- 创建bridge consumer成功后,接下来就能以这个consumer的身份去订阅kafka消息了
- 执行以下命令可以订阅topic为bridge-quickstart-topic的kafka消息,注意请求地址就是前面创建bridge consumer时返回的base_uri字段
curl -X POST http://42.193.162.141:31331/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/subscription \
-H 'content-type: application/vnd.kafka.v2+json' \
-d '{
"topics": [
"bridge-quickstart-topic"
]
}'
- 从上述请求body可以看出,此请求可以一次订阅多个topic,而且还可以使用topic_pattern(正则表达式)的形式来一次订阅多个topic
- 订阅完成后,接下来就能主动拉取消息了
拉取消息
- 在拉取消息之前,请确保已经提前生产了消息
- 执行以下命令拉取一条消息
curl -X GET http://42.193.162.141:31331/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/records \
-H 'accept: application/vnd.kafka.json.v2+json'
- 然而,当您执行了上述命令后,会发现返回body为空,别担心,这是正常的现象,按照官方的说法,拉取到的第一条消息就是空的,这是因为拉取操作出触发了rebalancing逻辑(rebalancing是kafka的概览,是处理多个partition消费的操作),再次执行上述命令去拉取消息,这下正常了,body如下
[
{
"topic": "bridge-quickstart-topic",
"key": "my-key",
"value": "sales-lead-0001",
"partition": 0,
"offset": 0
}, {
"topic": "bridge-quickstart-topic",
"key": "my-key",
"value": "sales-lead-0001",
"partition": 0,
"offset": 1
}
]
提交offset
- 前面在创建bridge consumer的时候,参数enable.auto.commit的值等于fasle,表示由调用方主动提交offset到kafka,因此在拉取到消息之后,需要手动更新kafka consumer的offset
curl -X POST http://42.193.162.141:31331/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/offsets
- 该请求无返回body,只要返回码是204就表示成功
设定offset
- 试想这样的场景:共生产了100条消息,消费者也已经将这100条全部消费完毕,现在由于某种原因,需要从91条开始,重新消费91-100这10条消息(例如需要重新计算),此时可以主动设定offset
- 先执行以下命令,生产一条消息
curl -X POST \
http://42.193.162.141:31331/topics/bridge-quickstart-topic \
-H 'content-type: application/vnd.kafka.json.v2+json' \
-d '{
"records": [
{
"value": "sales-lead-a002-01234567890123456789",
"partition": 2
}
]
}'
- 如下图红色箭头,可见当前partition已经生产了75条消息了
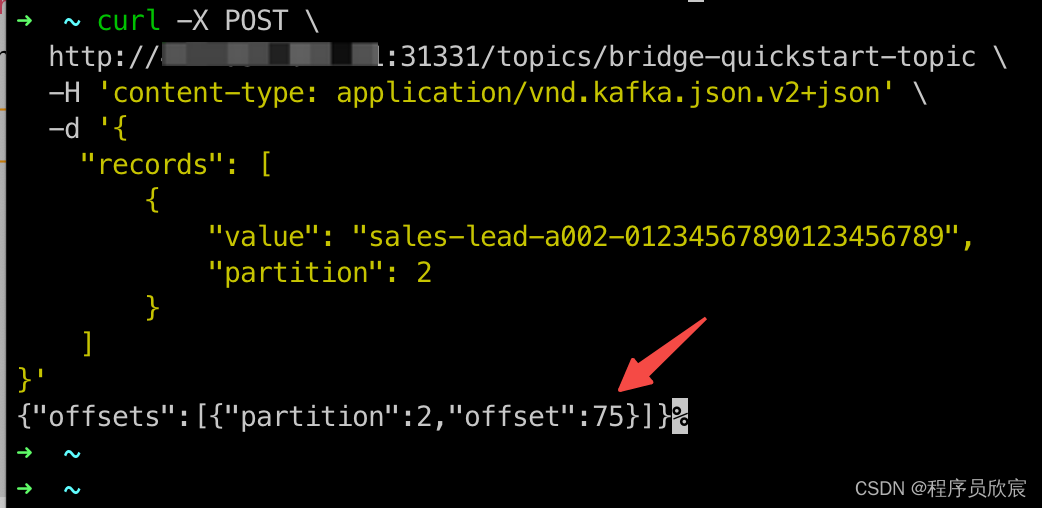
- 咱们先拉取消息,将消息都消费掉

- 由于没有新生产消息,此时再拉去应该拉取不到了
- 现在执行以下请求,就可以将offset设置到74
curl -X POST http://42.193.162.141:31331/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/positions \
-H 'content-type: application/vnd.kafka.v2+json' \
-d '{
"offsets": [
{
"topic": "bridge-quickstart-topic",
"partition": 2,
"offset": 74
}
]
}'
- 再次拉取消息,发现74和之后的所有消息都可以拉去到了(注意,包含了74)

- 至此,咱们对生产和发送消息的常用接口都已经操作了一遍,对于常规的业务场景已经够用,接下来的文章,咱们以此为基础,玩出更多花样来
你不孤单,欣宸原创一路相伴
- Java系列
- Spring系列
- Docker系列
- kubernetes系列
- 数据库+中间件系列
- DevOps系列




![[附源码]Python计算机毕业设计高校教室申请管理系统](https://img-blog.csdnimg.cn/3f30ddf1da7242269b1a175b4d47cfd7.png)
![[附源码]Python计算机毕业设计电影网站系统设计](https://img-blog.csdnimg.cn/e1bfa4d0cd7342b8836acbf189ac5c4f.png)