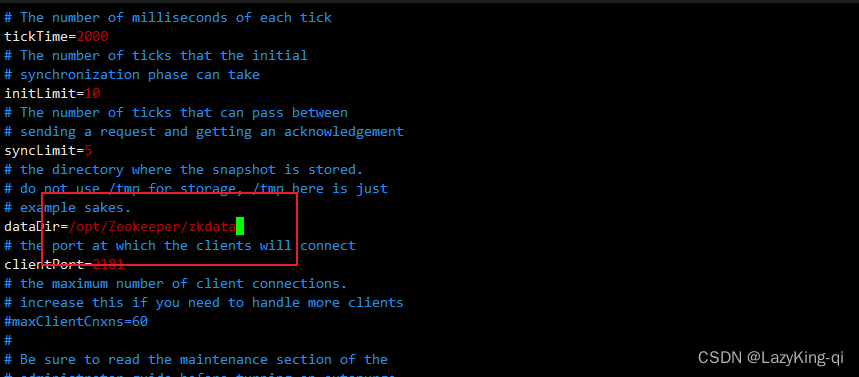
linux常用命令介绍 03 篇——常用的文本处理工具之grep和cut(以及部分正则使用)
- 1 常用命令01篇 和 02篇
- 1.1 Linux命令01篇——Linux解压缩文件常用命令
- 1.2 Linux命令02篇——linux日常常用命令介绍
- 2. 正则表达式
- 2.1 基本定义
- 2.2 正则中常用的元字符
- 3. grep 工具
- 3.1 grep 工具使用语法
- 3.2 grep工具使用例子
- 3.2.1 常用选项的使用例子(非正则)
- 3.2.2 grep中正则eg1——开头、结尾、空行 和 -v
- 3.2.3 grep中正则eg2——`*`和`.`和`.*`
- 3.2.4 grep中正则eg3——和`[]`相关的
- 4. cut 工具
- 4.1 cut 工具——语法
- 4.2 cut 工具——使用例子
- 5.
1 常用命令01篇 和 02篇
1.1 Linux命令01篇——Linux解压缩文件常用命令
- 解压缩文件常用命令——linux.
1.2 Linux命令02篇——linux日常常用命令介绍
- linux日常常用命令介绍——实用、简单明了不啰嗦.
2. 正则表达式
- 注意:不需要用正则的,可以直接看下面非正则的例子。
2.1 基本定义
- 元字符:
元字符就是那些在正则表达式中具有特殊意义的专用字符。
如:*、?、.(点)等 - 前导字符:
前导字符就是位于元字符前面的字符。如:- 在
bind*中,*前面的字符d就是前导字符 - 在
sprin.*中,.前面的字符n就是前导字符
- 在
2.2 正则中常用的元字符
| 元字符 | 作用 | 示例 |
|---|---|---|
^ | 以关键字开头 | grep '^www.' aa.txt |
$ | 以关键字结尾 | grep '0.0.1$' redis_test.conf |
^$ | 匹配空行 | ①grep '^$' aa.txt ② grep -n '^$' aa.txt |
* | 前导字符出现 0次 或 连续多次 | ①grep 'heo*' aa.txt ② grep '^hello*' aa.txt |
. | 匹配除了换行符以外的任意单个字符 (位置前后均可放) | ①grep 'hell.' aa.txt ② grep '.hell' aa.txt |
.* | 匹配关键字后面任意长度的任意字符 (位置前后均可放) | ①grep 'hell.*' aa.txt ② grep '.*hell' aa.txt ③ grep '.*hell$' aa.txt ④ grep '^hell.*' aa.txt |
[] | 匹配括号里任意单个字符或一组单个字符 | |
[^] | 匹配不包含括号里任一单个字符 或一组单个字符 | |
^[]( []$) | 匹配以括号里任意单个字符 或一组单个字符开头(结尾) | ①grep ^[hel] aa.txt② grep [hel]$ aa.txt |
^[^] ( [^]$) | 匹配不以括号里任意单个字符 或一组单个字符开头(结尾) |
3. grep 工具
3.1 grep 工具使用语法
- grep 是行过滤工具,用于根据关键字进行过滤。
- 语法:
grep [选项] ‘关键字’ 文件名 - 常见选项
-i :不区分大小写 -n :显示行号 -w :按完整单词搜索(单词有误,可能搜索不到) -o :只打印出匹配搜索的关键字 -c :统计匹配关键字出现的行的的次数(行的次数) -A :显示匹配行及后面多少行 -B :显示匹配行及前面多少行 -C :显示匹配行前后多少行 ^key :以关键字开头 key$ :以关键字结尾 -v :查找不包含指定内容的行,反向选择 ^$ :匹配空行 -e :使用正则匹配 -E :使用扩展正则匹配 -r :逐层遍历目录查找 -l :只列出匹配的文件名 -L :列出不匹配的文件名
3.2 grep工具使用例子
3.2.1 常用选项的使用例子(非正则)
- 直接搜索(redis_test.conf 文件中 搜索关键字 redis.io)
grep 'redis.io' redis_test.conf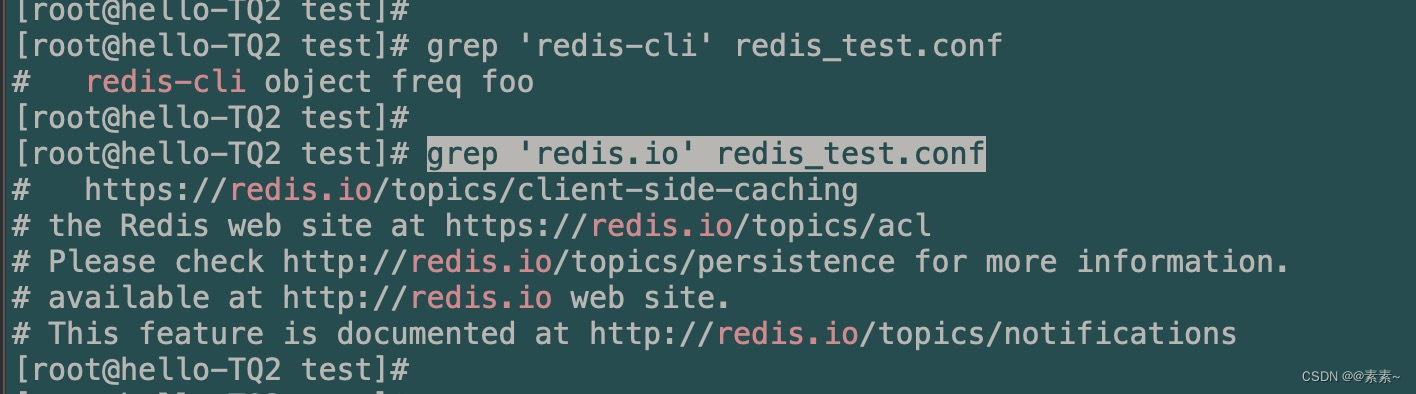
- 不区分大小写搜索
-igrep -i 'Redis.io' redis_test.conf - 搜索并查出关键字所在的行号
grep -n 'redis.io' redis_test.conf grep -n -i 'Redis.io' redis_test.conf grep -ni 'Redis.io' redis_test.conf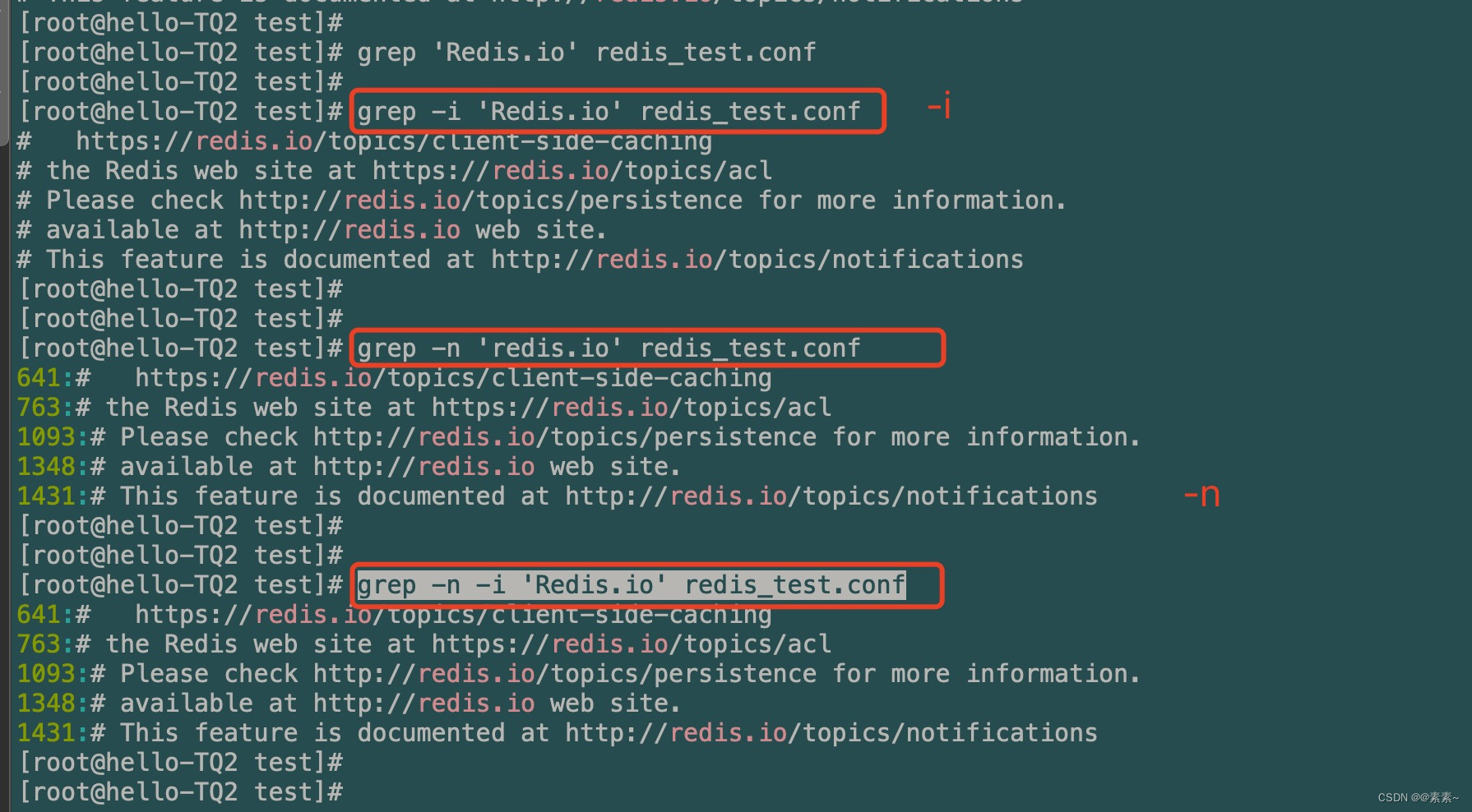
- 按完整单词搜索(单词拼错可能搜索不出来),用
-wgrep -w 'binding' redis_test.conf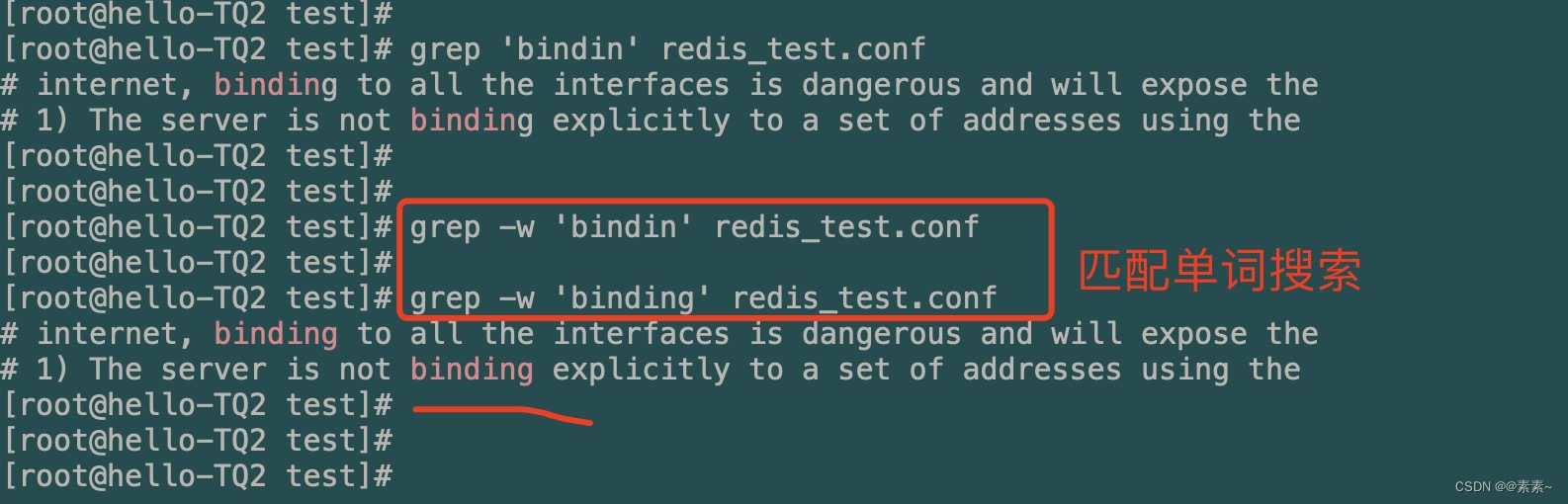
- 只打印出搜索的关键字,用
-ogrep -o ' maxmemory ' redis_test.conf grep -no ' maxmemory ' redis_test.conf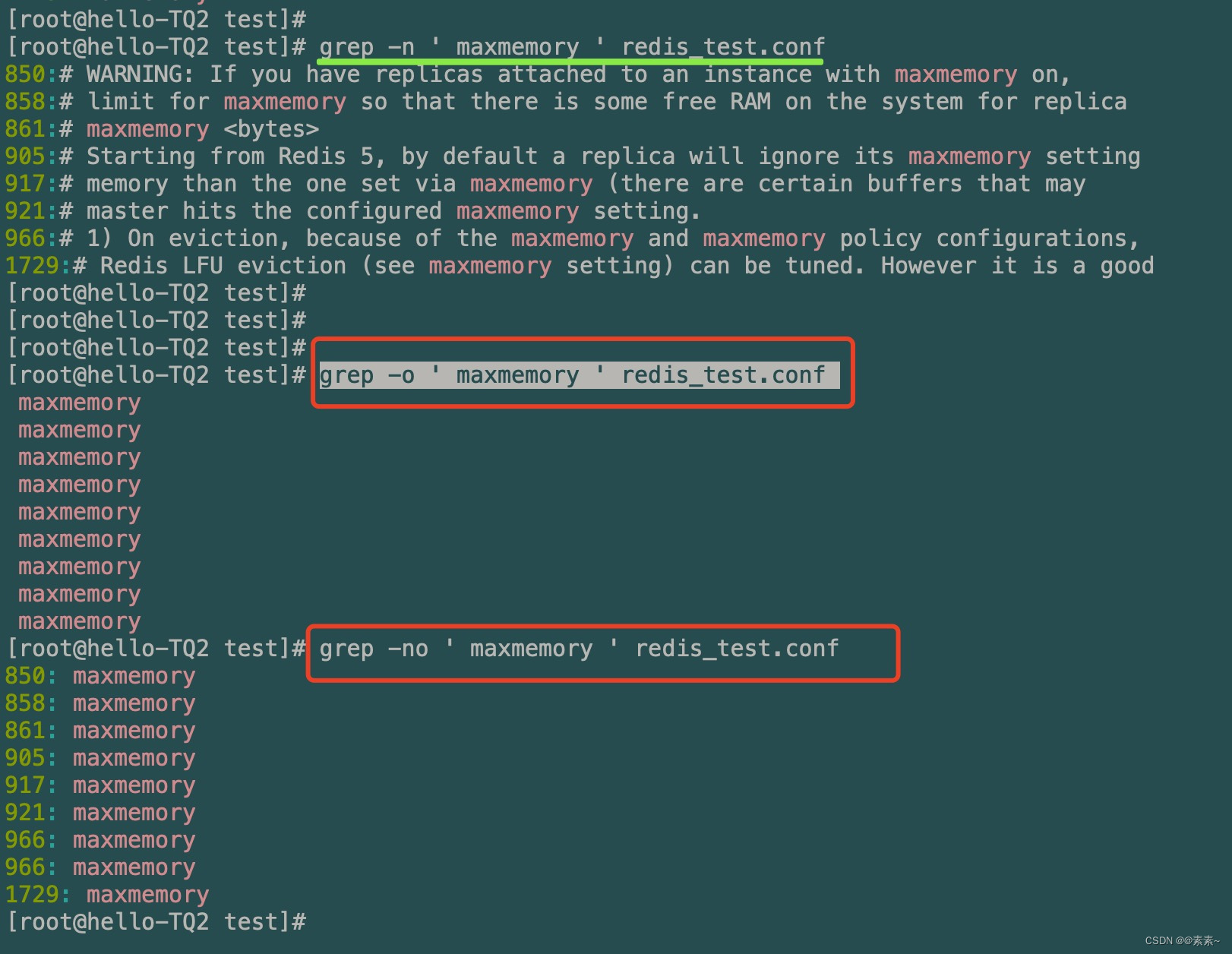
- 统计匹配关键字出现的行的的次数(注意是:行的次数)
grep -c 'maxmemory2' redis_test.conf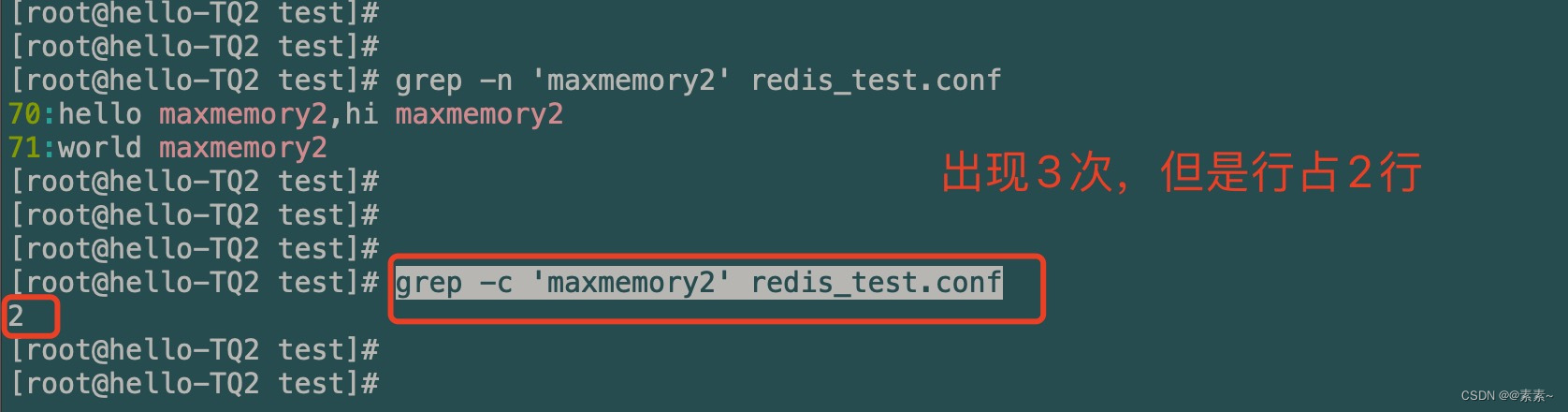
- 前后n行的内容也打印(-A 、-B、 -C)
- 后面 n 行用:
-Agrep -A 5 '192.168.1.100' redis_test.conf - 前面 n 行用:
-Bgrep -B 5 '192.168.1.100' redis_test.conf - 前后各 n 行用:
-Cgrep -C 2 '192.168.1.100' redis_test.conf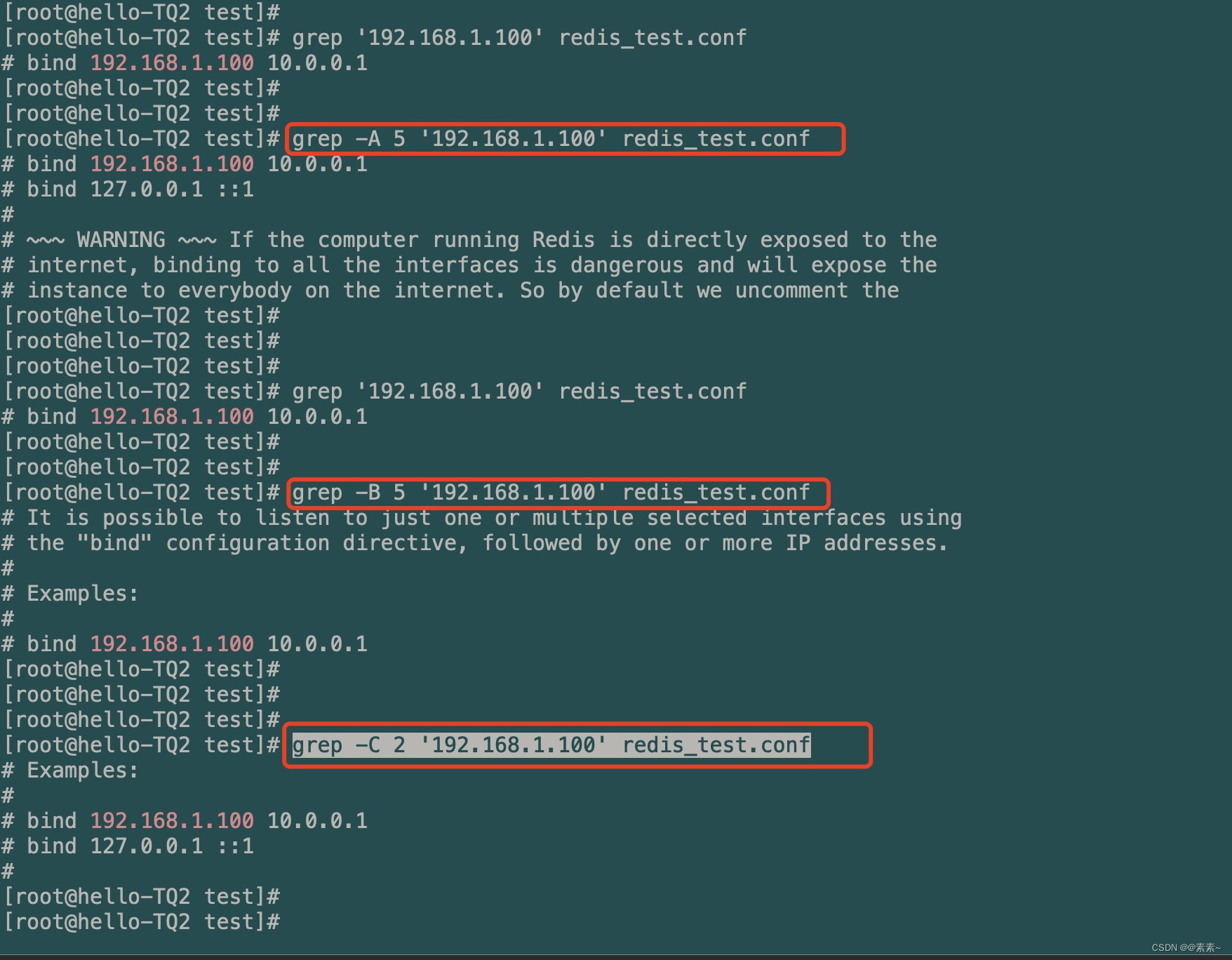
- 后面 n 行用:
- 关于 -v 的取反操作的例子,看下面的 《3.2.2.1 简单正则例子(开头、结尾、空行)》,放这里了
3.2.2 grep中正则eg1——开头、结尾、空行 和 -v
- 搜索以关键字开头的行
- 以关键字
^# bind开头的:^keygrep '^# bind' redis_test.conf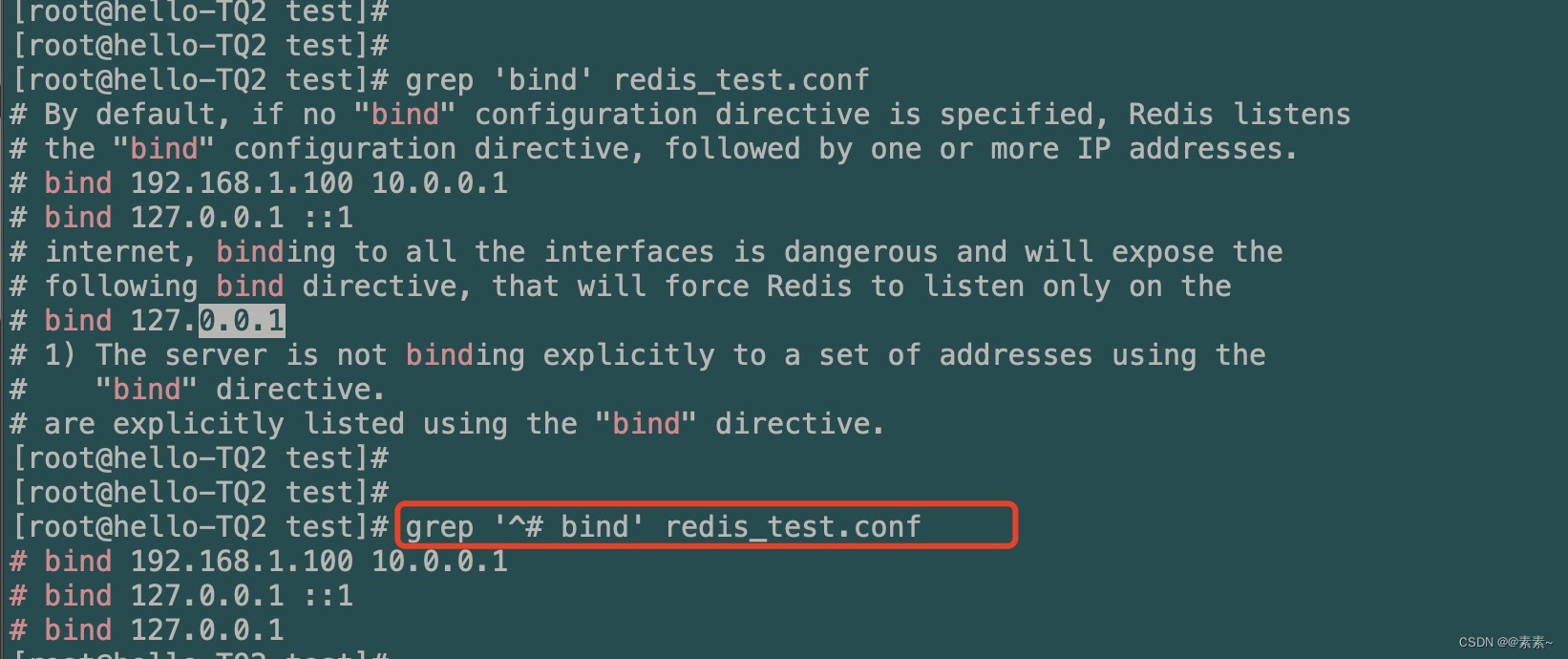
- 以关键字
- 搜索以关键字结尾的行
- 以关键字
0.0.1结尾的:key$grep '0.0.1$' redis_test.conf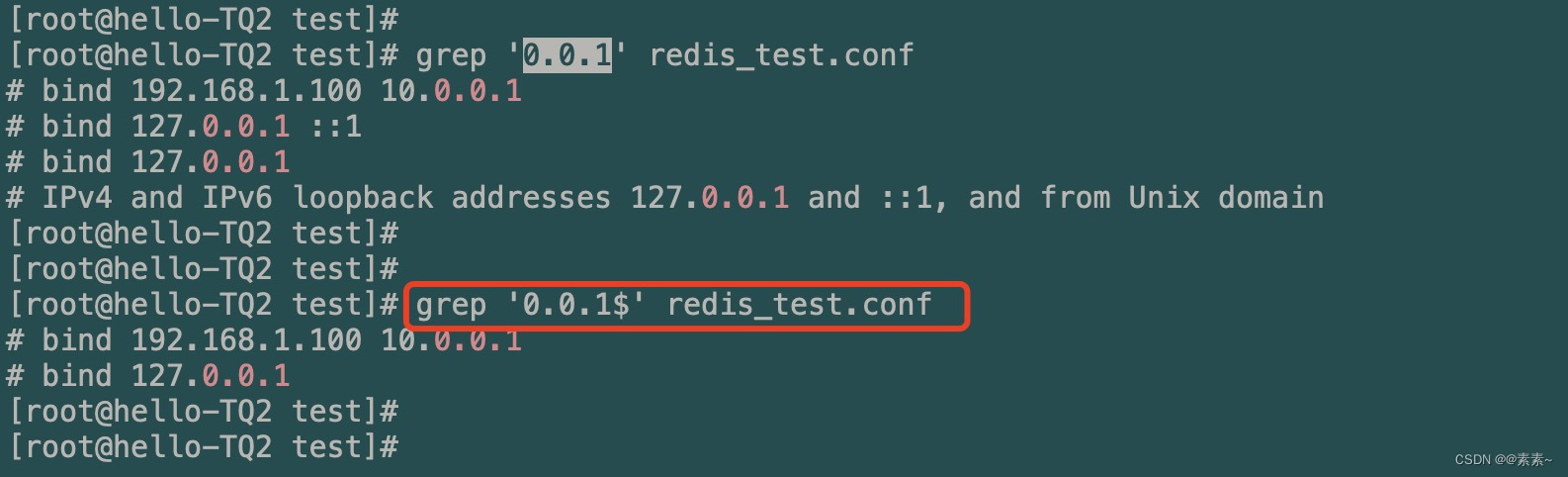
- 以关键字
- 关于
-v(取反操作)- 搜索不含关键字key的行,比如,搜索不含
bind的行grep -v 'bind' redis_test.conf - 搜索不以key关键字开头的,比如 搜索不以
# bind开头的:grep -v '^# bind' redis_test.conf - 搜索不以key关键字结尾的,比如搜索不以
0.0.1结尾的:grep -v '0.0.1$' redis_test.conf
- 搜索不含关键字key的行,比如,搜索不含
- 匹配空行,用
^$grep '^$' aa.txt grep -n '^$' aa.txt grep -nv '^$' aa.txt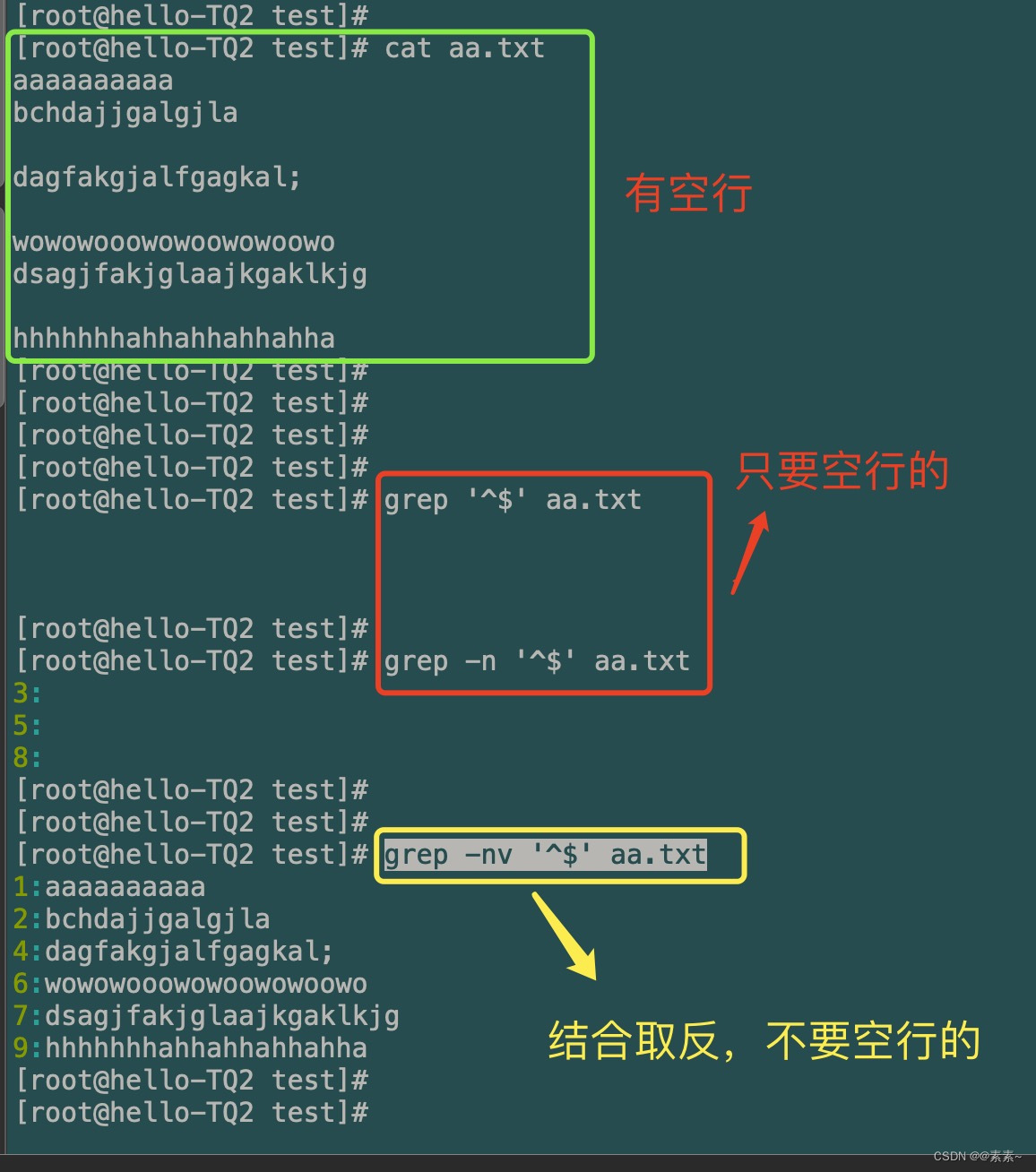
3.2.3 grep中正则eg2——*和.和.*
-
*:前导字符出现 0次 或连续多次。- 什么意思呢?比如解释下面的搜索命令
对于第一个命令,它搜索的结果就是:搜索关键字grep 'heo*' aa.txt grep '^hello*' aa.txthe并且后面紧跟的前导字符o出现0次或连续多次,其实你可以理解为这个搜索等价于grep 'he' aa.txt,就是直接搜索he,区别就是上面的搜索o会高亮。 - 演示示例如下,可对比看看
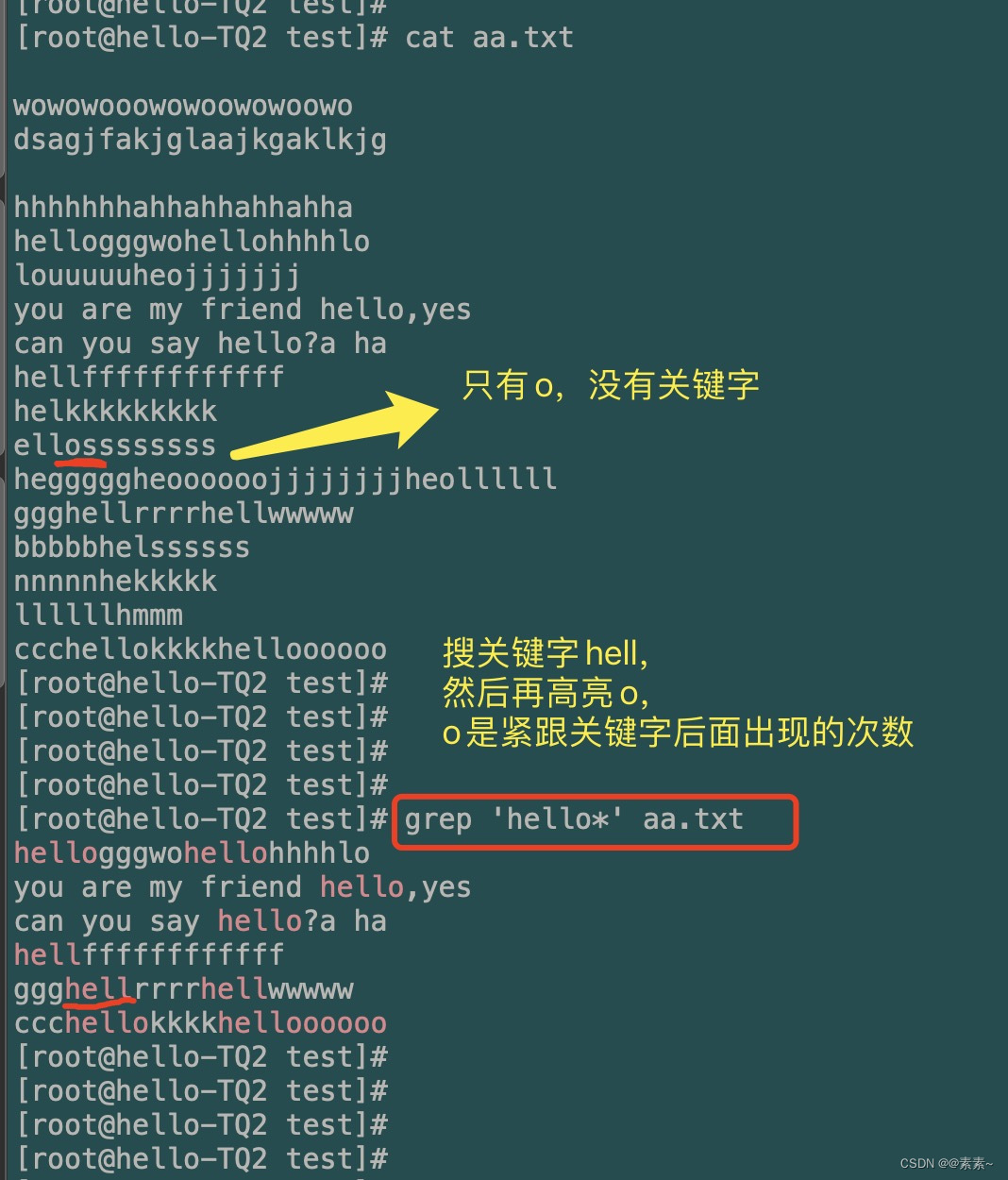
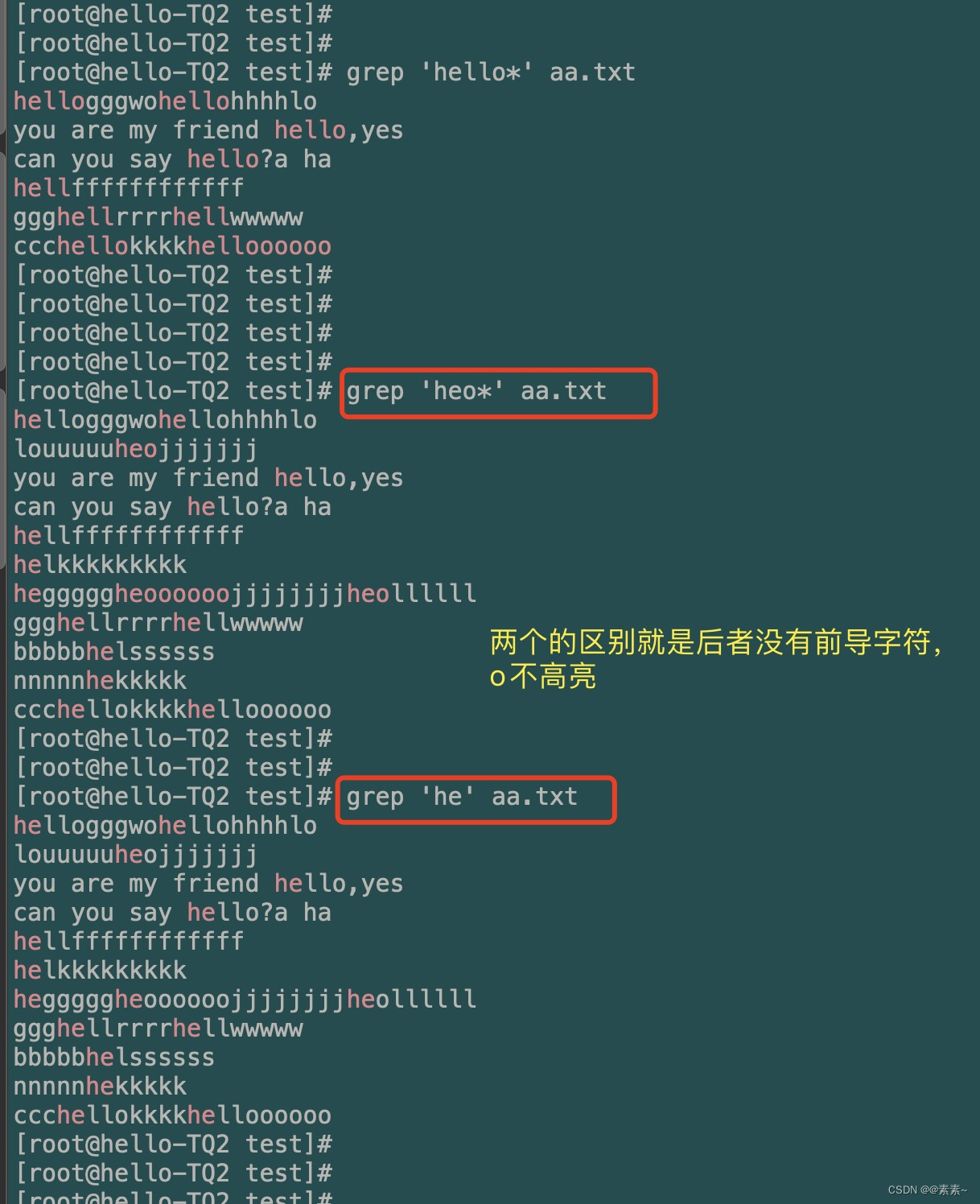
- 什么意思呢?比如解释下面的搜索命令
-
.:匹配除了换行符以外的任意单个字符。
第一个命令是:好比,忘了一个单词,只记得前几个字母hell,那就按这个方式去搜索,会把以关键字为hell开头的匹配搜索出来。看下面的例子,一看秒懂:grep 'hell.' aa.txt grep '.ello' aa.txt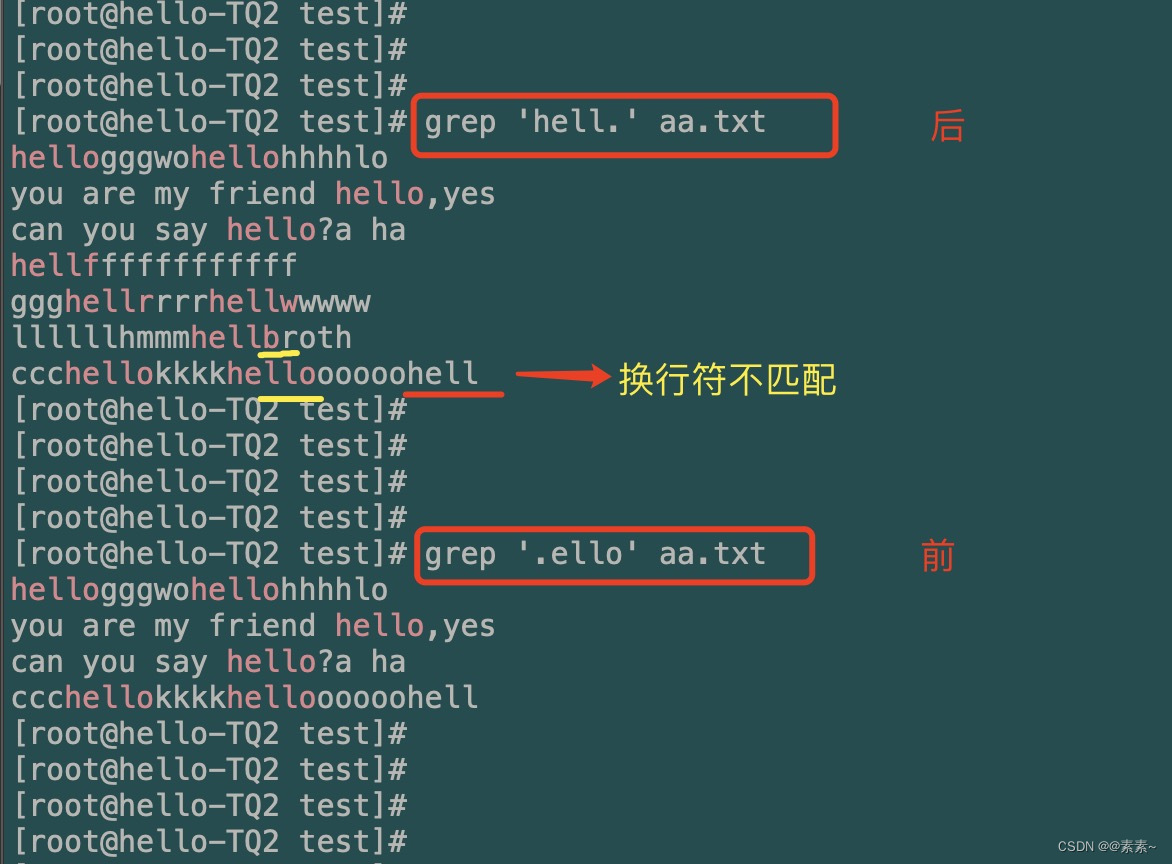
-
.*:匹配关键字后面任意长度的任意字符。
看图,秒懂:grep 'hell.*' aa.txt grep '.*hell' aa.txt grep '.*hell$' aa.txt grep '^hell.*' aa.txt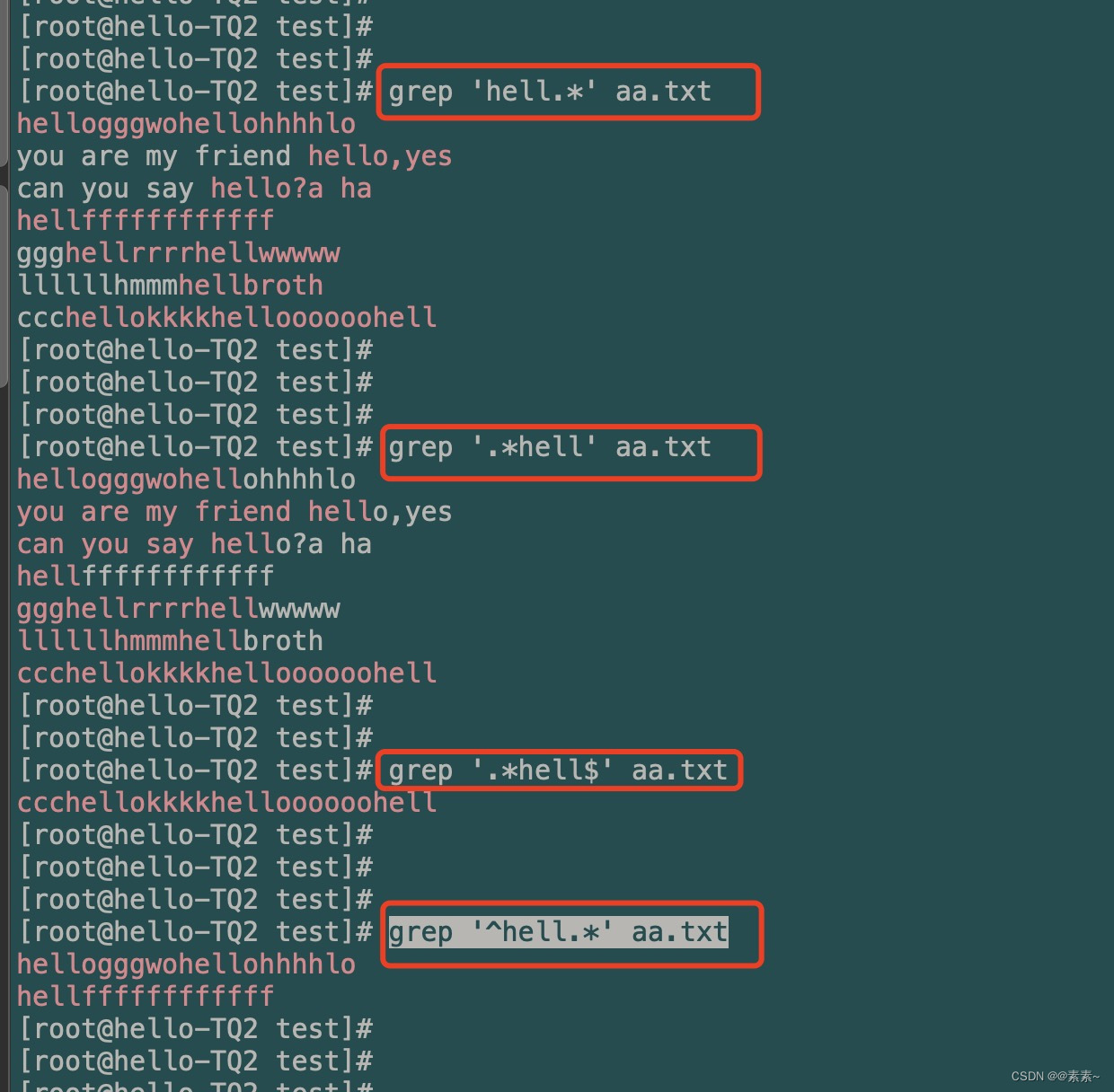
3.2.4 grep中正则eg3——和[]相关的
[]:匹配括号里任意单个字符或一组单个字符grep [hel] aa.txt[^]:匹配不包含括号里任一单个字符或一组单个字符grep [^hel] aa.txt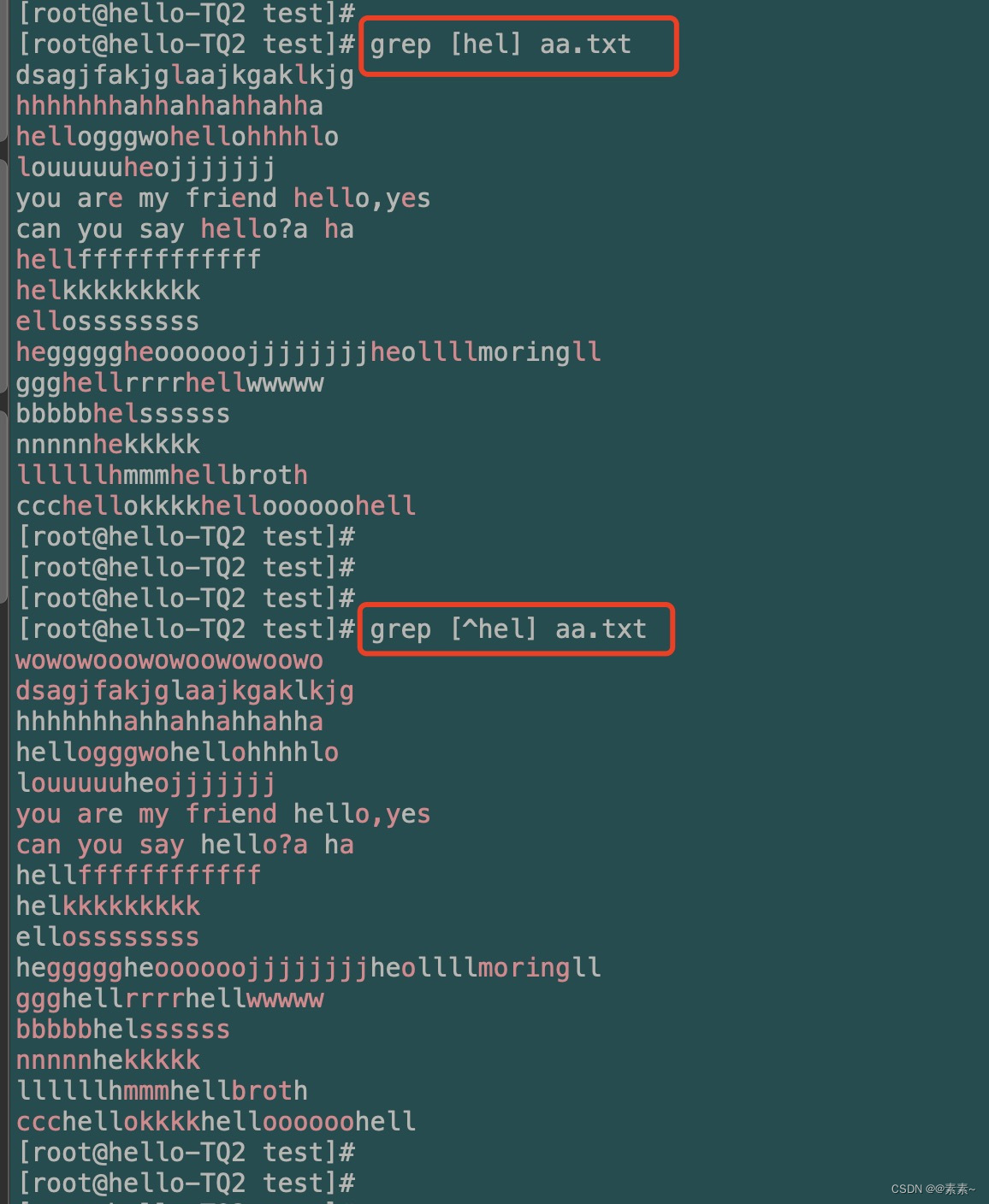
^[]或者[]$:匹配以括号里任意单个字符或一组单个字符开头grep ^[hel] aa.txt grep [hel]$ aa.txt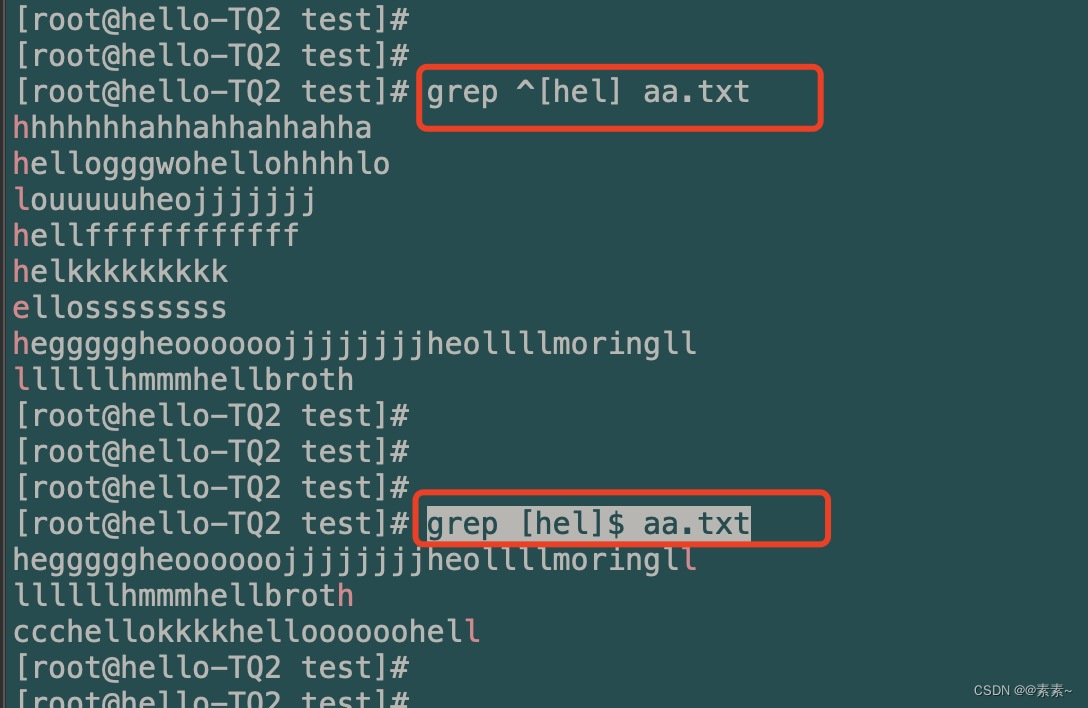
^[^]或者[^]$:匹配不以括号里任意单个字符或一组单个字符开头
都一样,这两就不说了。
4. cut 工具
- cut工具是列截取工具,用于列的截取。
4.1 cut 工具——语法
- 语法:
cut 选项 文件名 - 常用选项:
-c :以字符为单位进行分割截取 -d :自定义分隔符,默认为制表符\t -f :与 -d 一起使用,指定截取哪个区域
4.2 cut 工具——使用例子
-c:- 语法:
cut -c startCol,endCol http.txt # 截取startCol列 到 endCol列的字符 cut -c startCol- http.txt # 截取startCol开始的所有列 - 使用例子:
cut -c 1,2 http.txt cut -c 2,3 http.txt cut -c 2- http.txt | head -2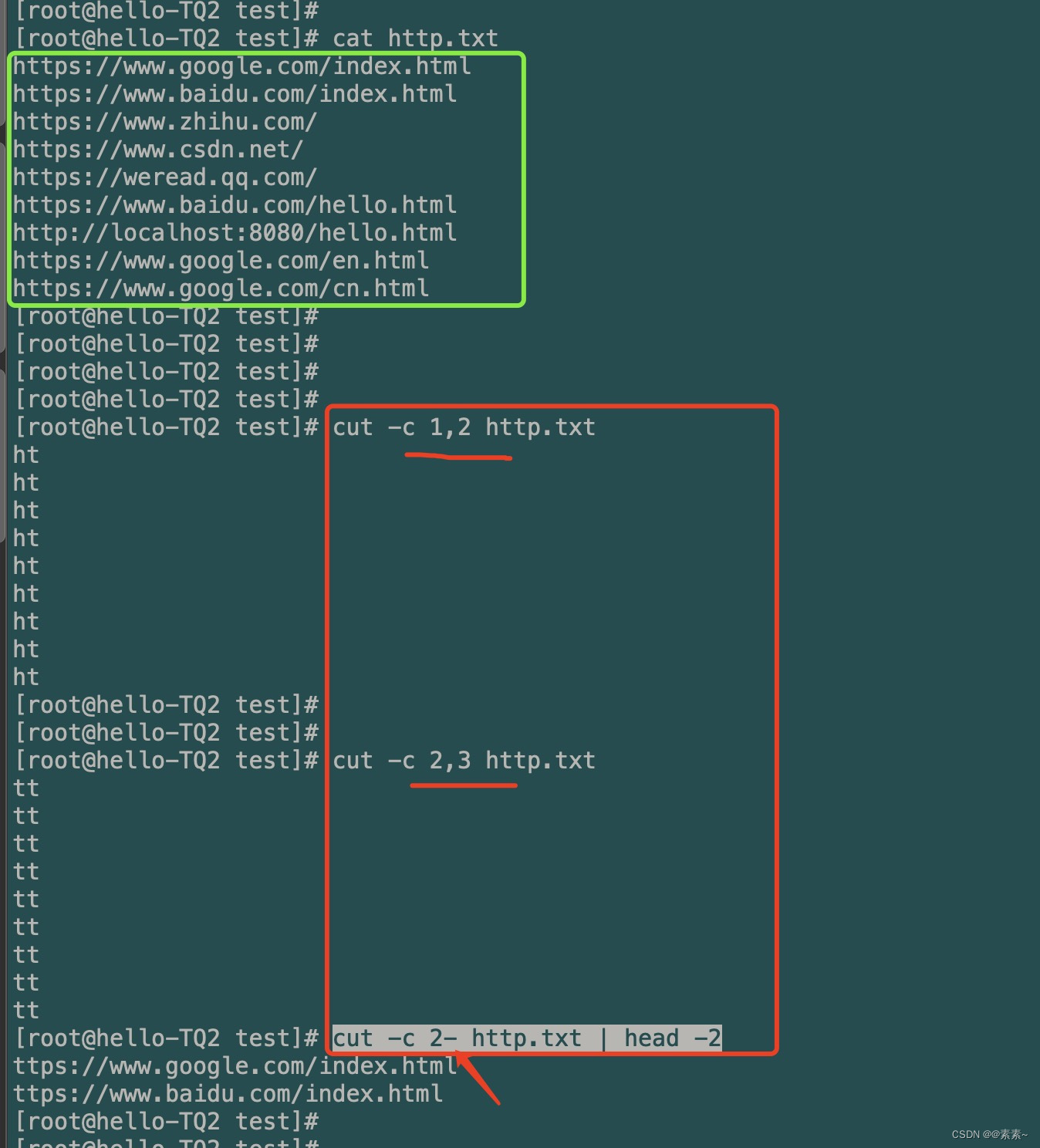
- 语法:
-d与-f:- 语法:
cut -d: -f1 http.txt # 以:号进行分割列,并截取分割后的第一段列 cut -d. -f1,3 http.txt # 以.号进行分割列,并截取分割后的第一至第三段列 - 使用例子
cut -d. -f1 http.txt cut -d. -f1,3 http.txt | head -2 cut -d: -f1 http.txt | head -2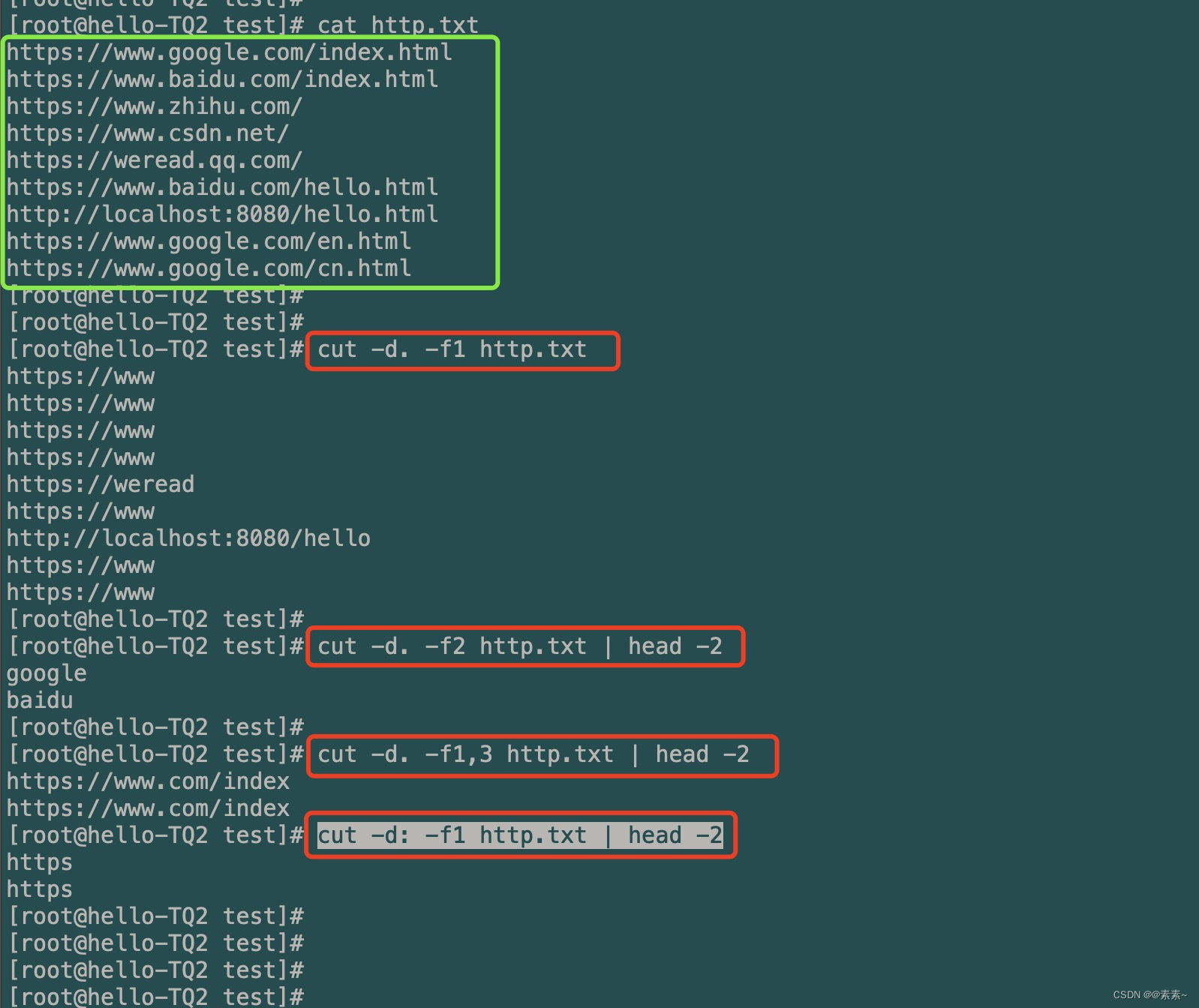
- 语法: