目录
一.priority_queue的使用
1.1、基本介绍
1.2、优先级队列的定义
1.3、基本操作(常见接口的使用)
1.4、重写仿函数支持自定义数据类型
二.priority_queue的模拟实现
2.1、构造&&重要的调整算法
2.2、常见接口的实现
push()
pop()
top()
empty()、size()
三.利用仿函数改进调整算法
一.priority_queue的使用
1.1、基本介绍
我们之前讲过数据结构中的队列,它具有先进先出的特性(FIFO).添加元素时只能在队尾插入,删除元素时只能删除队首的元素.
而优先级队列,它并不满足先进先出的特性,倒像是数据结构中的“堆”. 优先级队列每次出队时只能是队列中优先级最高的元素,而不是队首的元素。
这个优先级可以通过元素的大小,或者赋值运算符重载等进行比较. 例如定义元素越大,优先级越高,那么每次出队的时候一定是队列中最大的元素,因为它的优先级最高.并且重新进行维护.
经过上述的说明,是不是和我们所说的“堆”很相似,优先级队列的内部确实是由堆结构实现.
下面是官方文档的一段介绍:
1. 优先队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的。
2. 此上下文类似于堆,在堆中可以随时插入元素,并且只能检索最大堆元素(优先队列中位于顶部的元素)。
3. 优先队列被实现为容器适配器,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从特定容器的“尾部”弹出,其称为优先队列的顶部。
1.2、优先级队列的定义
首先,使用优先级队列,需要包含头文件<queue>,priority_queue的定义如下:
template <class T, class Container = vector<T>, class Compare = less<typename Container::value_type> > class priority_queue;第一个模板参数为为class T,代表每个元素的类型.
第二个模板参数为class Container,缺省值为vector<T>,代表存储这些数据的容器,可以是vector,deque等,但不能是list,因为它的内部空间不连续.
第三个模板参数为class Compare,缺省值为less<T>,其中less是个仿函数,是降序排序,既优先级最大的是容器中最大的元素.又叫比较函数.
当然可以升序排序,把less改为greater即可.
less 和 greater使用的前提是建立在这些数据类型是C++基本的数据类型.
例如下面这段代码:
//不写后面两个参数默认为vector,less
priority_queue<int> pq1;
//建立一个优先级队列(大堆),数据类型是int,利用vector容器实现,less(降序)实现
priority_queue<int, vector<int>, less<int>> pq2;
//建立一个优先级队列(小堆),数据类型是int,利用vector容器实现,greater(降序)实现
priority_queue<int, vector<int>, greater<int>> pq3;1.3、基本操作(常见接口的使用)
它的操作与基本队列操作一样,主要有以下接口:
top() :返回元素中第一个元素的引用(优先级最高的元素都会被放到顶部,既第一个元素).
push():插入一个元素,并重新维护堆,无返回值.
pop() :删除优先级最高的元素,并重新维护堆无返回值
size() :返回容器中有效元素的数量,返回队列的大小
empty() :检测容器是否为空.返回“true”或者“false”.
代码示例:
int main()
{
//不写后面两个参数默认为vector,less
priority_queue<int> pq1;
//push的使用
pq1.push(1);
pq1.push(2);
pq1.push(3);
pq1.push(4);
pq1.push(5);
//push完之后,维护也完毕,此时优先级最高的是元素是5,排在第一位
cout << pq1.top() << endl;//优先级最高的一位,所以应该是5
//pop的使用:删除一个优先级最高的元素5,此时重新调整,优先级最高的元素应该为4
pq1.pop();
cout << pq1.top() << endl;
//size()的使用,删除了一个元素,此时应该还有四个元素
cout << pq1.size() << endl;
return 0;
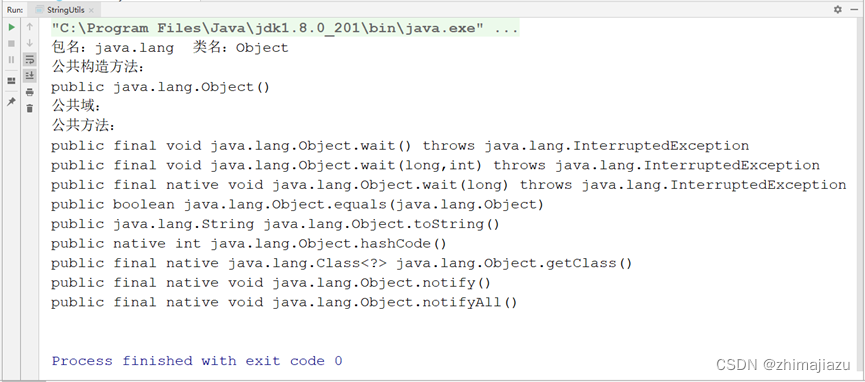
}执行结果:

正如我们预料所得.
1.4、重写仿函数支持自定义数据类型
仿函数是通过重载‘()’运算符来进行模拟函数操作的类.
通俗点说,仿函数是一个能行使函数功能类,然后类里必须实现“()”运算符重载.
比如我们要根据类里的某一个成员大小进行比较,因为是一个类,它不是C++里的基本数据类型,所以需要我们自己重新仿函数来支持它.
看下面这段程序
class Data
{
public:
Data(int i, int d)
:id(d)
, data(d)
{}
int GetData() const
{
return data;
}
private:
int id;
int data;
};
//仿函数,从小到大排序,既大的优先级最高
class cmp
{
public:
bool operator() (Data& d1, Data& d2)
{
return d1.GetData() < d2.GetData();
}
};
int main()
{
//首先创建三个data类型数据
Data* d1 = new Data(0, 1);
Data* d2 = new Data(0, 2);
Data* d3 = new Data(0, 3);
//创建优先级队列,比较函数为cmp仿函数,并将数据全部push
priority_queue<Data,vector<Data>,cmp> pq;
pq.push(*d1);
pq.push(*d2);
pq.push(*d3);
//全部输出出来
while(!pq.empty())
{
cout << (pq.top().GetData()) << endl;
pq.pop();
}
return 0;
}二.priority_queue的模拟实现
2.1、构造&&重要的调整算法
priority_queue的底层结构就是堆,所以模拟实现只需要对堆封装即可.
所以其中大部分都是与之前堆的数据结构相关的一些方法.
我们知道priority_queue有三个参数来构造,所以我们也使用三个模板参数.
模板如下:
template<class T,class Container = vector<T>,class Compare = less<T>>
然后一个类须有成员变量,这个类里只有一个成员变量:
Container _con; 利用第二个模板参数既容器类型的构造了一个变量,这样就可以对里面的所有数据进行操作了.
准备就绪后,开始写构造函数,主要有两种:无参构造以及迭代器构造.
无参构造:其实可以不用写,但是由于有迭代器构造函数的存在,系统便不能再调用默认构造函数,所以必须自己手写一下无参的构造函数.
priority_queue()
{}迭代器构造
和之前的迭代器构造方法一样,看一下便知.
priority_queue(InputIterator first, InputIterator last)
{
while (first != last)
{
_con.push_back(*first);
++first;
}于此同时,我们构造好数据后,还需要进行建堆,具体的建堆代码如下,和之前堆的数据结构中建堆的方法类似.
for (int i = (_con.size() - 1 - 1) / 2; i >= 0; i--)//[_con.size()-1]是最后一个元素的下标,再-1然后/2是计算中间的元素,既最后一个结点的父节点
{
adjust_down(i);
}既从数据中间的一个元素开始,每次进行向下调整算法,完毕之后--,指向下一个数据继续进行调整,如此直到第一个元素,建堆便完成.
提到了向下调整算法,这个方法在我之前堆的文章中有详细介绍过,大家可以去看之前的文章进行理解.
.
void adjust_down(size_t parent)
{
size_t child = parent * 2 + 1;
while (child < _con.size())
{
if (child + 1 < _con.size() && _con[child] < _con[child + 1])
++child;
if (_con[child] > _con[parent])
{
swap(_con[child], _con[parent]);
parent = child;
child = 2 * parent + 1;
}
else
break;
}
}大概总固体思路是:先根据根节点找到孩子结点,然后判断左右两个孩子结点中的哪个大,默认是孩子结点是左孩子结点,如果右孩子结点比左孩子结点大,那么直接++即可,就是右孩子结点.
然后再判断,如果孩子结点的值大于父节点的值,则交换,并且更新父节点和孩子结点的值.
与此对应的是,既然有向下调整算法,那么也会有向上调整算法.
前面的文章也有写到过,不再详述.
void adjust_up(size_t child)
{
size_t parent = (child - 1) / 2;
while (child > 0)
{
if (_con[child] > _con[parent])
{
swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
break;
}
}这个是传入孩子结点,我们根据公式求出父亲结点,公式就是代码中所写的那一个.
然后判断,符合条件更新父节点和子结点即可.
两大基础调整算法写完,那后面的就非常轻松了
2.2、常见接口的实现
这些接口都可以复用之前的调整算法.
push()
这个就是将数据插入,并且重新调整堆的结构.
void push(const T& x)
{
_con.push_back(x);
adjust_up(_con.size()-1);//传入最后一个数据的下标
}对于push_back(),有人可能有疑问包括我就是,我没有实现push_back(),但为什么可以直接写呢?
其实我们能用优先级队列的容器就那么几种,vector,deque等等,都是一些内部存储空间连续的,而这些容器都具有push_back()这个接口,所以到时候模板实例化的时候便可以用了.
pop()
先把首尾元素进行交换,然后删除最后一个元素,再进行向下调整.
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
adjust_down(0);
}top()
返回优先级最高既堆顶的元素,既容器的首元素.由于堆顶特性,堆中
const T& top()
{
return _con[0];
}empty()、size()
这些都是容器中所对应拥有的函数,直接返回即可.
bool empty() const
{
return _con.empty();
}
size_t size() const
{
return _con.size();
}三.利用仿函数改进调整算法
通过我们上面写的向上调整,向下调整算法,发现有一个比较麻烦的地方
就是它其中的每次比较都是大于,既每次都是大顶堆
但是如果我们想要小顶堆怎么办?只能一点一点的改大小于符号 ,很容易就会混和忘记,非常的不方便.
这个时候我们便可以使用仿函数来解决这个问题.这个时候便用到刚开始写的三个模板参数中的第三个参数了.
可以先写两个仿函数,一个用来构造小顶堆,另外的是大顶堆.
template<class T>
class less
{
public:
bool operator()(const T& l, const T& r)
{
return l < r;
}
};
template<class T>
class greater
{
public:
bool operator()(const T& l, const T& r)
{
return l > r;
}
};我们再把它应用到那两个调整算法里面.
adjust_up
最开始需要用仿函数构造一个对象,才可以使用.
Compare com;原来其中的:
if (_con[child] > _con[parent])改为:
if (com(_con[child] , _con[parent]))adjust_down
最开始需要用仿函数构造一个对象,才可以使用.
Compare com;原来其中的:
if (child + 1 < _con.size() && _con[child] < _con[child + 1]) if (_con[child] > _con[parent])改为:
if (child + 1 < _con.size() && com(_con[child] , _con[child + 1])) if (com(_con[child] , _con[parent]))这样就改进完成了.以后想要改变大小顶堆时,只需要将Compare后面的仿函数改成自己需要的即可.
这就是优先级队列的所有内容了,包括使用及实现.
由于文章代码比较散乱,这里直接放上总代码方便参观.
#pragma once
#include<iostream>
#include<vector>
using namespace std;
namespace hyx
{
//大堆
template<class T,class Container = vector<T>,class Compare = less<T>>
class priority_queue
{
template<class T>
class less
{
public:
bool operator()(const T& l, const T& r)
{
return l < r;
}
};
template<class T>
class greater
{
public:
bool operator()(const T& l, const T& r)
{
return l > r;
}
};
public:
priority_queue()
{}
template<class InputIterator>
priority_queue(InputIterator first, InputIterator last)
{
while (first != last)
{
_con.push_back(*first);
++first;
}
//建堆
for (int i = (_con.size() - 1 - 1) / 2; i >= 0; i--)
{
adjust_down(i);
}
}
void adjust_up(size_t child)
{
Compare com;
size_t parent = (child - 1) / 2;
while (child > 0)
{
if (com(_con[child] , _con[parent]))
{
swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
break;
}
}
void adjust_down(size_t parent)
{
Compare com;
size_t child = parent * 2 + 1;
while (child < _con.size())
{
if (child + 1 < _con.size() && com(_con[child] , _con[child + 1]))
++child;
if (com(_con[child] , _con[parent]))
{
swap(_con[child], _con[parent]);
parent = child;
child = 2 * parent + 1;
}
else
break;
}
}
void push(const T& x)
{
_con.push_back(x);
adjust_up(_con.size()-1);
}
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
adjust_down(0);
}
const T& top()
{
return _con[0];
}
bool empty() const
{
return _con.empty();
}
size_t size() const
{
return _con.size();
}
private:
Container _con;
};
}