目标
背影
BP神经网络的原理
BP神经网络的定义
BP神经网络的基本结构
BP神经网络的神经元
BP神经网络的激活函数,
BP神经网络的传递函数
麻雀算法原理
麻雀算法主要参数
麻雀算法流程图
麻雀算法优化测试函数代码
基于麻雀算法改进的BP神经网络坑基监测
数据
matlab编程实现
效果图
结果分析
展望
背影
坑基监测是很多工程安全的重要能容之一,一旦出现险情,往往来不及处理,需要有一定的提前预判,本文用基于麻雀算法改进的BP神经网络监测基坑,有一定 的提前预判能力,实现监测的智能化。
BP神经网络的原理
BP神经网络的定义
人工神经网络无需事先确定输入输出之间映射关系的数学方程,仅通过自身的训练,学习某种规则,在给定输入值时得到最接近期望输出值的结果。作为一种智能信息处理系统,人工神经网络实现其功能的核心是算法。BP神经网络是一种按误差反向传播(简称误差反传)训练的多层前馈网络,其算法称为BP算法,它的基本思想是梯度下降法,利用梯度搜索技术,以期使网络的实际输出值和期望输出值的误差均方差为最小。
BP神经网络的基本结构
基本BP算法包括信号的前向传播和误差的反向传播两个过程。即计算误差输出时按从输入到输出的方向进行,而调整权值和阈值则从输出到输入的方向进行。正向传播时,输入信号通过隐含层作用于输出节点,经过非线性变换,产生输出信号,若实际输出与期望输出不相符,则转入误差的反向传播过程。误差反传是将输出误差通过隐含层向输入层逐层反传,并将误差分摊给各层所有单元,以从各层获得的误差信号作为调整各单元权值的依据。通过调整输入节点与隐层节点的联接强度和隐层节点与输出节点的联接强度以及阈值,使误差沿梯度方向下降,经过反复学习训练,确定与最小误差相对应的网络参数(权值和阈值),训练即告停止。此时经过训练的神经网络即能对类似样本的输入信息,自行处理输出误差最小的经过非线形转换的信息。
bp神经网络的神经元
神经网络是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。
神经网络由多个神经元构成,下图就是单个神经元的图1所示:

。。。。。。。。。。。。。。。。。。。。。。。。图1 ,神经元模型
bp神经网络激活函数及公式


BP神经网络传递函数及公式
图2是Sigmoid函数和双极S函数的图像,其中Sigmoid函数的图像区域是0到1,双极S函数的区间是正负1,归一化的时候要和传递函数的区域相对应,不然,可能效果不好
神经网络就是将许多个单一的神经元联结在一起,这样,一个神经元的输出就可以是另一个神经元的输入。
例如,下图就是一个简单的神经网络:

麻雀算法SSA的原理
主要公式
在SSA中,具有较好适应度值的发现者在搜索过程中会优先获取食物。此外,因为发现者负责为整个麻雀种群寻找食物并为所有加入者提供觅食的方向。因此,发现者可以获得比加入者更大的觅食搜索范围。在每次迭代的过程中,发现者的位置更新描述如下:

其中,t代表当前迭代数,itermax是一个常数,表示最大的迭代次数。Xij表示第i个麻雀在第j维中的位置信息。α∈(0,1]是一个随机数。R2(R2∈[0,1])和ST(ST∈[0.5,1])分别表示预警值和安全值。Q是服从正态分布的随机数。L表示一个1×d的矩阵,其中该矩阵内每个元素全部为1。当R2< ST 时,这意味着此时的觅食环境周围没有捕食者,发现者可以执行广泛的搜索操作。当R2 ≥ ST,这表示种群中的一些麻雀已经发现了捕食者,并向种群中其它麻雀发出了警报,此时所有麻雀都需要迅速飞到其它安全的地方进行觅食。
加入者(追随者)的位置更新描述如下:

其中,Xp是目前发现者所占据的最优位置,Xworst则表示当前全局最差的位置。A表示一个1×d的矩阵,其中每个元素随机赋值为1或-1,并且A+=AT(AAT)-1。当i >n/2时,这表明,适应度值较低的第i个加入者没有获得食物,处于十分饥饿的状态,此时需要飞往其它地方觅食,以获得更多的能量。
当意识到危险时,麻雀种群会做出反捕食行为,其数学表达式如下:

其中,其中Xbest是当前的全局最优位置。β作为步长控制参数,是服从均值为0,方差为1的正态分布的随机数。K∈[-1,1]是一个随机数,fi则是当前麻雀个体的适应度值。fg和fw分别是当前全局最佳和最差的适应度值。ε是最小的常数,以避免分母出现零。
为简单起见,当fi >fg表示此时的麻雀正处于种群的边缘,极其容易受到捕食者的攻击。fi = fg时,这表明处于种群中间的麻雀意识到了危险,需要靠近其它的麻雀以此尽量减少它们被捕食的风险。K表示麻雀移动的方向同时也是步长控制参数。
麻雀算法SSA的主要参数:
一、种群个数popsize,既算法中麻雀的个数;
二、最大迭代次数maxgen,既算法迭代gen次后停止迭代;
三、种群维度dim,既需要优化的自变量个数;
四、种群位置pop,既每个麻雀的对应的自变量的值,一个麻雀对应一组自变量,相当于一个解;
五、发现者比例P_percent,既麻雀算法发现者占所有麻雀的比例;
六、安全值ST,既这意味着此时的觅食环境周围没有捕食者;
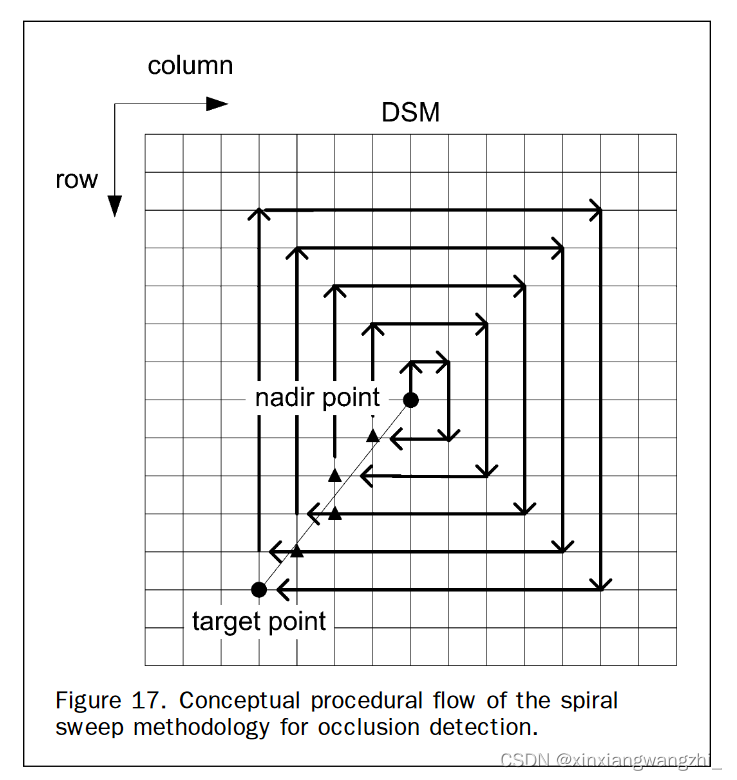
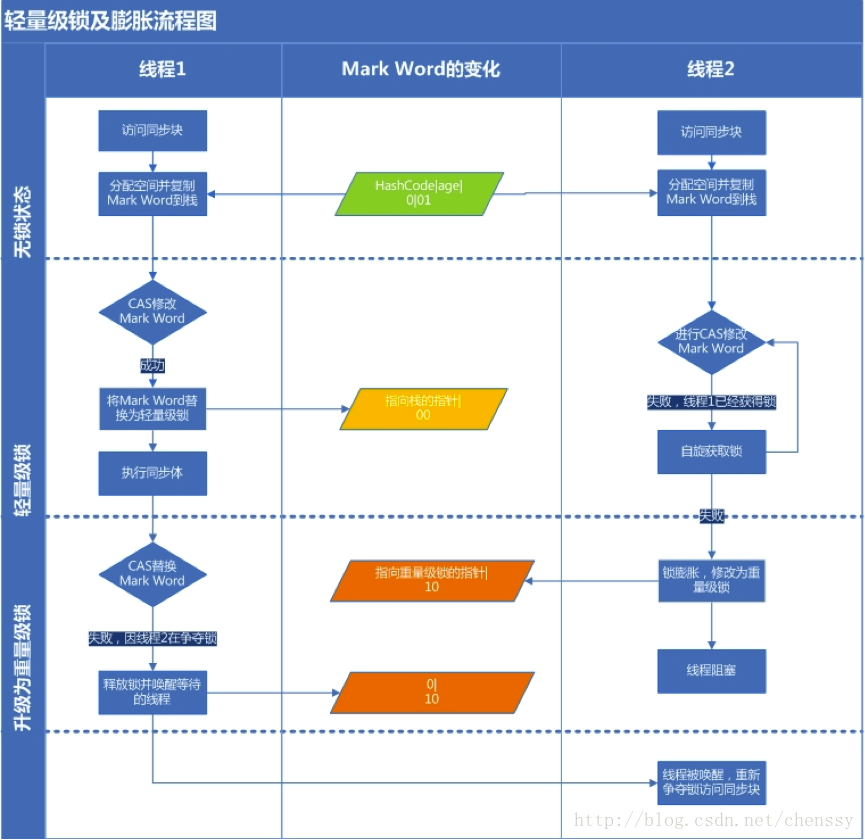
麻雀算法流程图

基于麻雀算法改进 的B神经网络坑基监测
神经网络参数
三层神经网络,传递函数logsig , tansig,训练函数自适应动量因子梯度下降函数,学习率0.1,学习目标0.001,最大迭代次数1000
麻雀算法的主要参数
MATLAB编程代码
% 清空环境
clc
clear
close all
warning off
%读取数据
[num ,ax,ay]= xlsread(‘基坑监测数据改后.xls’);
num(:,[3 6]) = [];
npan =2;%选择第一列数据
if npan<5
num1 = num(:,npan);
n1 = length(num1);
m1 = 5;
num2 = zeros(n1-m1,m1+1);
for ii = 1:n1-m1
num2(ii,:) = num1(ii:ii+m1)‘;
end
else
num1 = num(1:2:end,npan);
n1 = length(num1);
m1 = 5;
num2 = zeros(n1-m1,m1+1);
for ii = 1:n1-m1
num2(ii,:) = num1(ii:ii+m1)’;
end
end
%节点个数
inputnum=m1;
hiddennum=10;
outputnum=1;
m = round(0.8*length(num2));
n = randperm(length(num2));
%训练数据和预测数据
input_train=num2(n(1:m),1:m1)‘;
input_test=num2(m+1:end,1:m1)’;
output_train=num2(n(1:m),m1+1)‘;
output_test=num2(m+1:end,m1+1)’;
%选连样本输入输出数据归一化
[inputn,inputps]=mapminmax(input_train);
[outputn,outputps]=mapminmax(output_train);
%构建网络
% net=newff(inputn,outputn,hiddennum);
net = newff(minmax(inputn),[10,1],{‘logsig’,‘tansig’},‘traingdx’);
[BPoutput,errorb] = bpp(input_train,input_test,output_train,output_test);
% 参数初始化
dim=inputnumhiddennum+hiddennum+hiddennumoutputnum+outputnum;
maxgen=30; % 进化次数
sizepop=20; %种群规模
popmax=5;
popmin=-5;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
P_percent = 0.2; % The population size of producers accounts for “P_percent” percent of the total population size
pNum = round( sizepop * P_percent ); % The population size of the producers
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
for i=1:sizepop
pop(i,:)=5*rands(1,dim);
% V(i,:)=rands(1,21);
fitness(i)=fun(pop(i,:),inputnum,hiddennum,outputnum,net,inputn,outputn);
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
pFit = fitness;
[ fMin, bestI ] = min( fitness ); % fMin denotes the global optimum fitness value
bestX = pop( bestI, : ); % bestX denotes the global optimum position corresponding to fMin
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%麻雀搜索算法 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
for t = 1 : maxgen
[ ans, sortIndex ] = sort( pFit );% Sort.
[fmax,B]=max( pFit );
worse= pop(B,:);
r2=rand(1);
if(r2<0.8)
for i = 1 : pNum % Equation (3)
r1=rand(1);
pop( sortIndex( i ), : ) = pop( sortIndex( i ), : )*exp(-(i)/(r1*maxgen));
fitness(sortIndex( i ))=fun(pop(sortIndex( i ),:),inputnum,hiddennum,outputnum,net,inputn,outputn);
end
else
for i = 1 : pNum
pop( sortIndex( i ), : ) = pop( sortIndex( i ), : )+randn(1)*ones(1,dim);
fitness(sortIndex( i ))=fun(pop(sortIndex( i )😅,inputnum,hiddennum,outputnum,net,inputn,outputn);
end
end
[ fMMin, bestII ] = min( fitness );
bestXX = pop( bestII, : );
for i = ( pNum + 1 ) : sizepop % Equation (4)
A=floor(rand(1,dim)*2)*2-1;
if( i>(sizepop/2))
pop( sortIndex(i ), : )=randn(1)*exp((worse-pop( sortIndex( i ), : ))/(i)^2);
else
pop( sortIndex( i ), : )=bestXX+(abs(( pop( sortIndex( i ), : )-bestXX)))*(A'*(A*A')^(-1))*ones(1,dim);
end
fitness(sortIndex( i ))=fun(pop(sortIndex( i ),:),inputnum,hiddennum,outputnum,net,inputn,outputn);
end
c=randperm(numel(sortIndex));
b=sortIndex(c(1:3));
for j = 1 : length(b) % Equation (5)
if( pFit( sortIndex( b(j) ) )>(fMin) )
pop( sortIndex( b(j) ), : )=bestX+(randn(1,dim)).*(abs(( pop( sortIndex( b(j) ), : ) -bestX)));
else
pop( sortIndex( b(j) ), : ) =pop( sortIndex( b(j) ), : )+(2*rand(1)-1)*(abs(pop( sortIndex( b(j) ), : )-worse))/ ( pFit( sortIndex( b(j) ) )-fmax+1e-50);
end
fitness(sortIndex( i ))=fun(pop(sortIndex( i ),:),inputnum,hiddennum,outputnum,net,inputn,outputn);
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
for i = 1 : sizepop
if ( fitness( i ) < pFit( i ) )
pFit( i ) = fitness( i );
pop(i,:) = pop(i,:);
end
if( pFit( i ) < fMin )
fMin= pFit( i );
bestX =pop( i, : );
end
end
yy(t)=fMin;
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%% 迭代寻优
x=bestX
%% 结果分析
plot(yy)
title(['适应度曲线 ’ ‘终止代数=’ num2str(maxgen)]);
xlabel(‘进化代数’);ylabel(‘适应度’);
%% 把最优初始阀值权值赋予网络预测
% %用麻雀搜索算法优化的BP网络进行值预测
w1=x(1:inputnumhiddennum);
B1=x(inputnumhiddennum+1:inputnumhiddennum+hiddennum);
w2=x(inputnumhiddennum+hiddennum+1:inputnumhiddennum+hiddennum+hiddennumoutputnum);
B2=x(inputnumhiddennum+hiddennum+hiddennumoutputnum+1:inputnumhiddennum+hiddennum+hiddennumoutputnum+outputnum);
net.iw{1,1}=reshape(w1,hiddennum,inputnum);
net.lw{2,1}=reshape(w2,outputnum,hiddennum);
net.b{1}=reshape(B1,hiddennum,1);
net.b{2}=B2;
%% 训练
%网络进化参数
net.trainParam.epochs=5000;
net.trainParam.lr=0.1;
net.trainParam.goal=0.00001;
%网络训练
[net,tr]=train(net,inputn,outputn);
%%预测
%数据归一化
inputn_test=mapminmax(‘apply’,input_test,inputps);
an=sim(net,inputn_test);
test_simu=mapminmax(‘reverse’,an,outputps);
error=test_simu-output_test;
figure
plot(test_simu,‘r-o’)
hold on
plot(BPoutput,‘b-s’)
hold on
plot(output_test,‘k-*’)
hold off
xlabel(‘样本’)
ylabel(‘土体倾斜’)
ylim([32 40])
legend(‘ssa-bp’,‘bp’,‘实际值’)
figure
plot(error)
title(‘仿真预测误差’,‘fontsize’,12);
xlabel(‘仿真次数’,‘fontsize’,12);ylabel(‘误差百分值’,‘fontsize’,12);
效果图


结果分析
从效果图上看,麻雀算法改进的BP神经网络能够实现对基坑数据的预测,意味能提前预判存在的风险,提前采取预防和纠正措施,比传统的实时监测更有实用意义,对风险管控更好,有疑问或者其他应用方面,欢迎大家扫描下面的二维码
展望
针对神经网络供工具箱,可以自己写函数的代入并原本的工具箱函数,可以有很多种改进方法