1、Transformation转换算子
RDD整体上分为Value类型、双Value类型和Key-Value类型
1.1,Value类型
1.1.1,map()映射
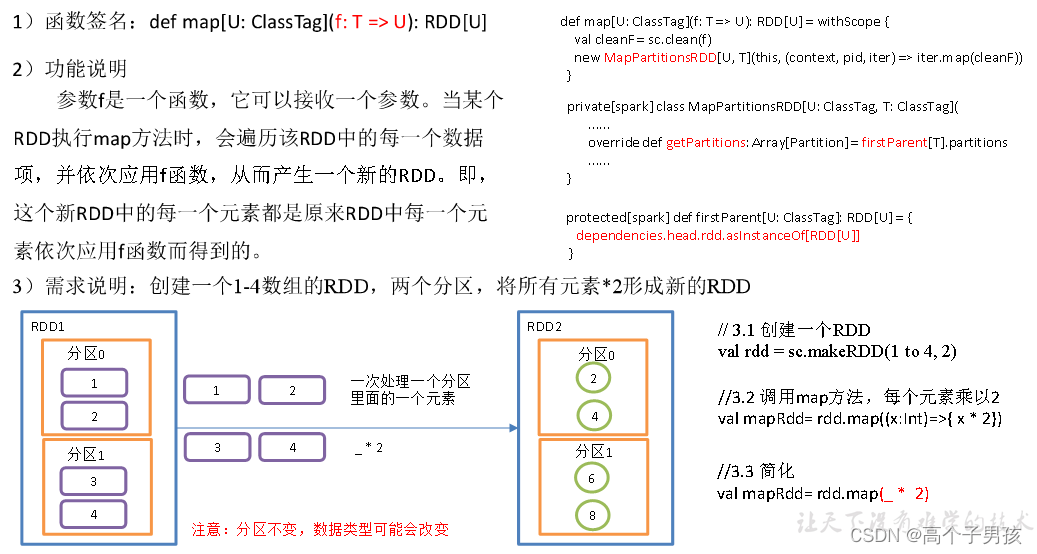
object value01_map {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc = new SparkContext(conf)
//3具体业务逻辑
// 3.1 创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4,2)
// 3.2 调用map方法,每个元素乘以2
val mapRdd: RDD[Int] = rdd.map(_ * 2)
// 3.3 打印修改后的RDD中数据
mapRdd.collect().foreach(println)
//4.关闭连接
sc.stop()
}
}1.1.2、mapPartitions()以分区为单位执行Map
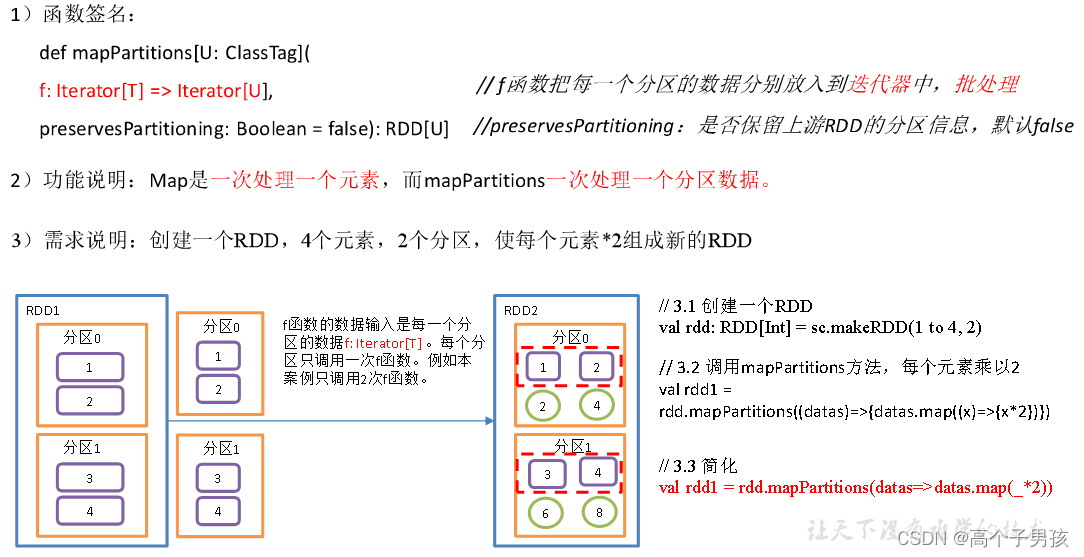
object value02_mapPartitions {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc = new SparkContext(conf)
//3具体业务逻辑
// 3.1 创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4, 2)
// 3.2 调用mapPartitions方法,每个元素乘以2
val rdd1 = rdd.mapPartitions(x=>x.map(_*2))
// 3.3 打印修改后的RDD中数据
rdd1.collect().foreach(println)
//4.关闭连接
sc.stop()
}
}1.1.3,map()和mapPartitions()区别
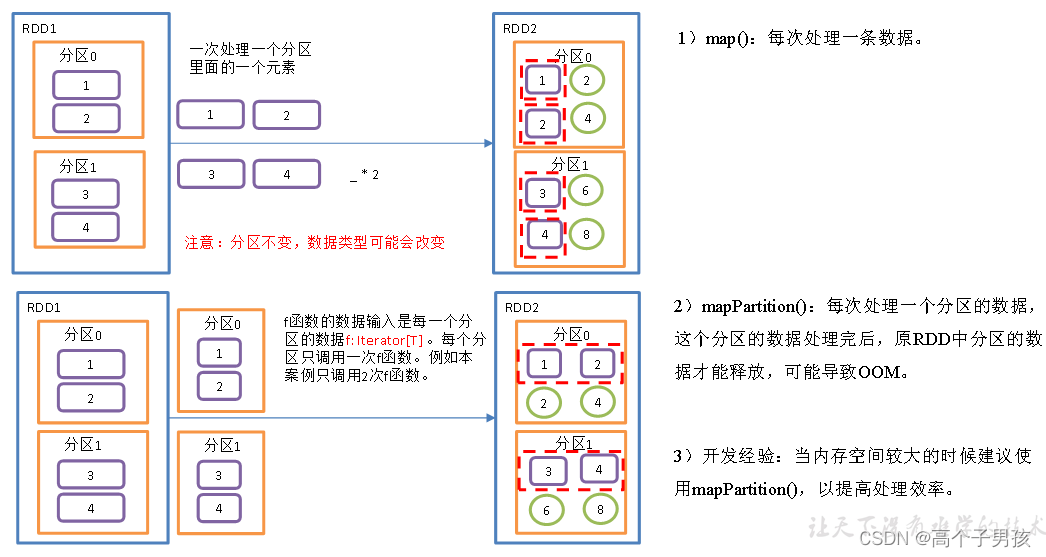
1.1.4,mapPartitionsWithIndex()带分区号
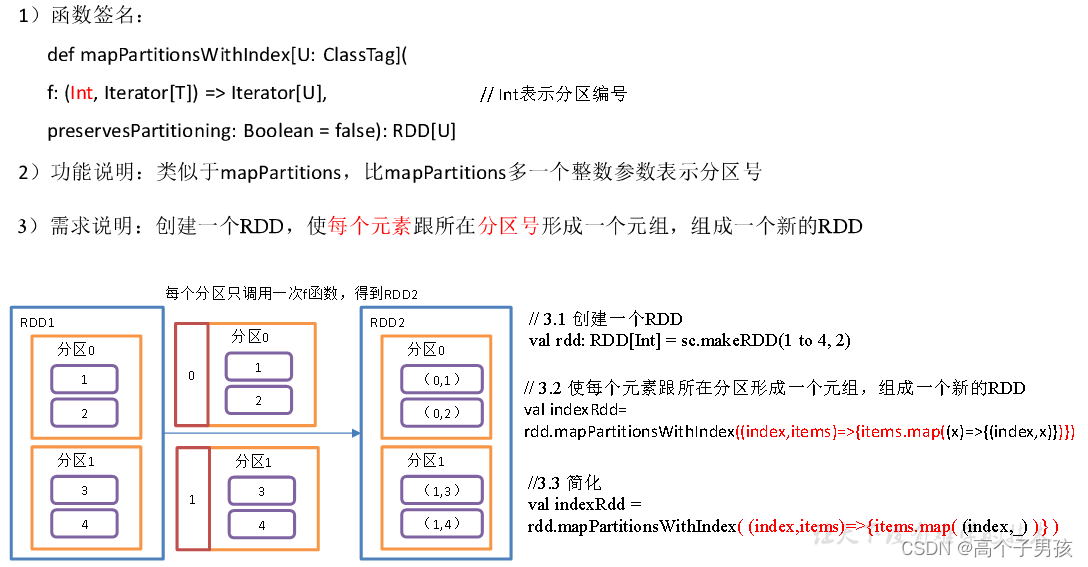
object value03_mapPartitionsWithIndex {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc = new SparkContext(conf)
//3具体业务逻辑
// 3.1 创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4, 2)
// 3.2 创建一个RDD,使每个元素跟所在分区号形成一个元组,组成一个新的RDD
val indexRdd = rdd.mapPartitionsWithIndex( (index,items)=>{items.map( (index,_) )} )
//扩展功能:第二个分区元素*2,其余分区不变
// 3.3 打印修改后的RDD中数据
indexRdd.collect().foreach(println)
//4.关闭连接
sc.stop()
}
}1.1.5,flatMap()压平
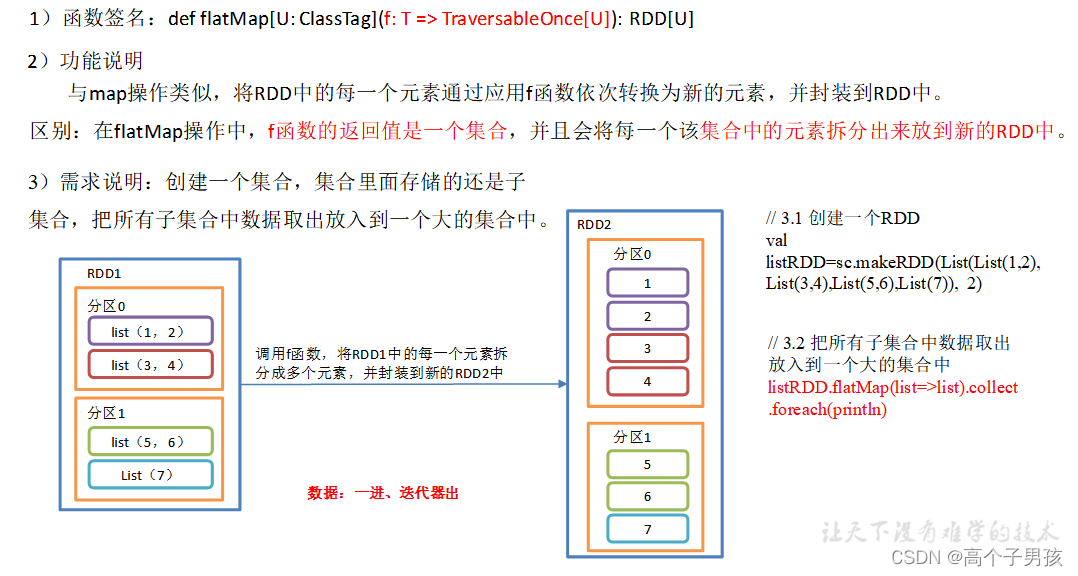
object value04_flatMap {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc = new SparkContext(conf)
//3具体业务逻辑
// 3.1 创建一个RDD
val listRDD=sc.makeRDD(List(List(1,2),List(3,4),List(5,6),List(7)), 2)
// 3.2 把所有子集合中数据取出放入到一个大的集合中
listRDD.flatMap(list=>list).collect.foreach(println)
//4.关闭连接
sc.stop()
}
}1.1.6,glom()分区转换数组
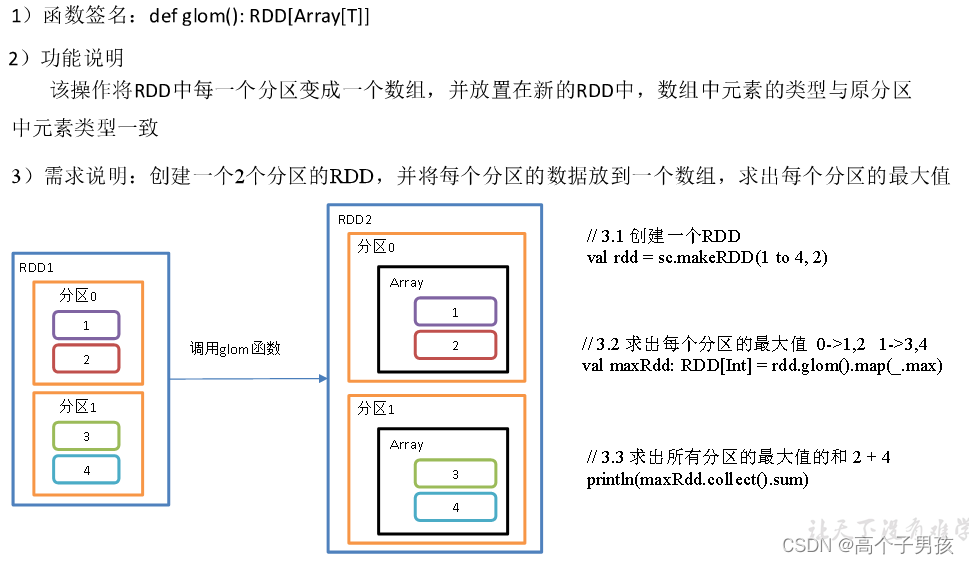
object value05_glom {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc = new SparkContext(conf)
//3具体业务逻辑
// 3.1 创建一个RDD
val rdd = sc.makeRDD(1 to 4, 2)
// 3.2 求出每个分区的最大值 0->1,2 1->3,4
val maxRdd: RDD[Int] = rdd.glom().map(_.max)
// 3.3 求出所有分区的最大值的和 2 + 4
println(maxRdd.collect().sum)
//4.关闭连接
sc.stop()
}
}
1.1.7,groupBy()分组
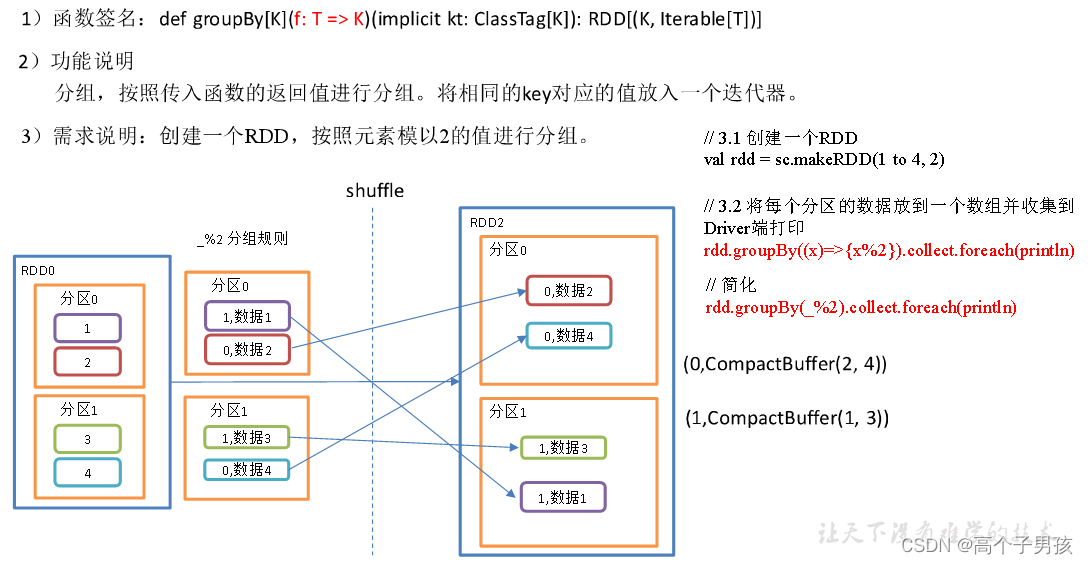
object value06_groupby {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc = new SparkContext(conf)
//3具体业务逻辑
// 3.1 创建一个RDD
val rdd = sc.makeRDD(1 to 4, 2)
// 3.2 将每个分区的数据放到一个数组并收集到Driver端打印
rdd.groupBy(_ % 2).collect().foreach(println)
// 3.3 创建一个RDD
val rdd1: RDD[String] = sc.makeRDD(List("hello","hive","hadoop","spark","scala"))
// 3.4 按照首字母第一个单词相同分组
rdd1.groupBy(str=>str.substring(0,1)).collect().foreach(println)
sc.stop()
}
}groupBy会存在shuffle过程
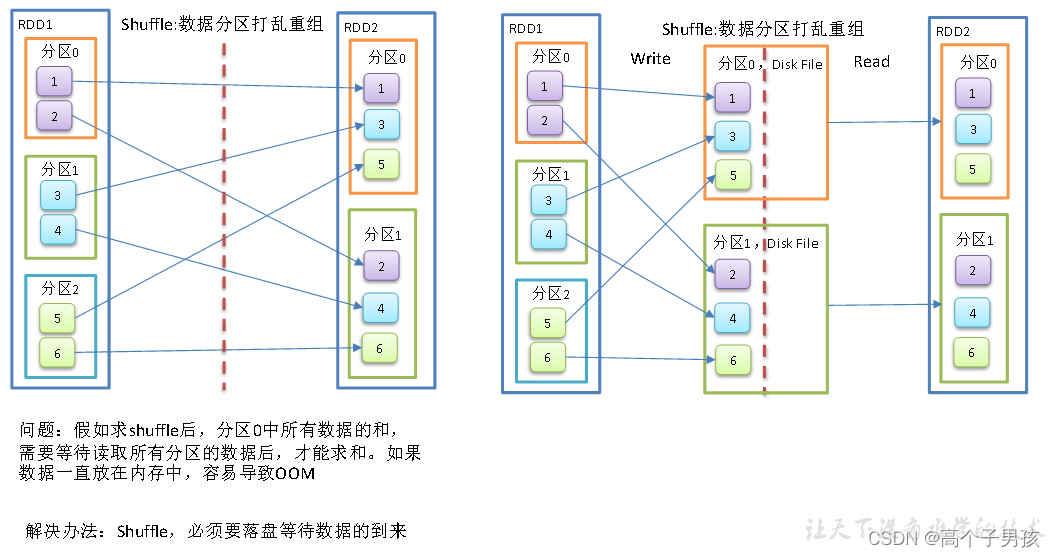
shuffle:将不同的分区数据进行打乱重组的过程
shuffle一定会落盘。可以在local模式下执行程序,通过4040看效果。
1.1.8,GroupBy之WordCount
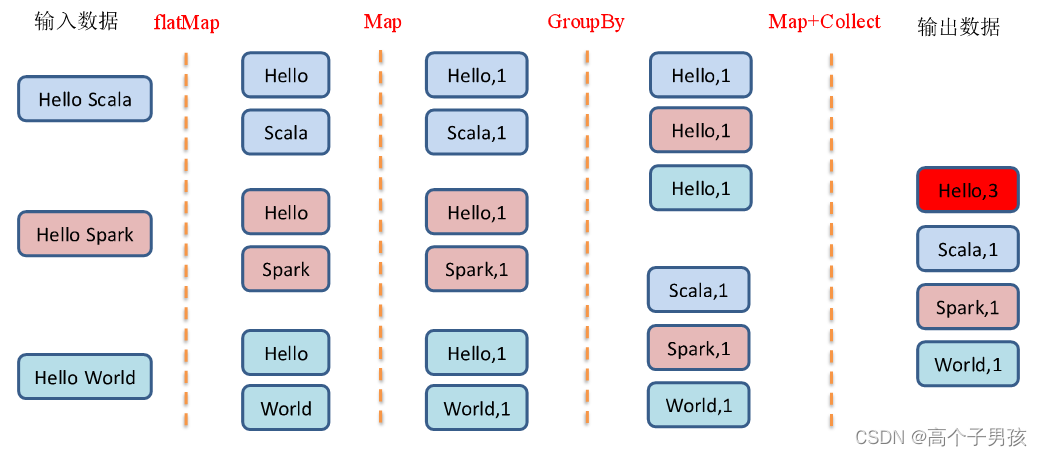
object value06_groupby {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc = new SparkContext(conf)
//3具体业务逻辑
// 3.1 创建一个RDD
val strList: List[String] = List("Hello Scala", "Hello Spark", "Hello World")
val rdd = sc.makeRDD(strList)
// 3.2 将字符串拆分成一个一个的单词
val wordRdd: RDD[String] = rdd.flatMap(str=>str.split(" "))
// 3.3 将单词结果进行转换:word=>(word,1)
val wordToOneRdd: RDD[(String, Int)] = wordRdd.map(word=>(word, 1))
// 3.4 将转换结构后的数据分组
val groupRdd: RDD[(String, Iterable[(String, Int)])] = wordToOneRdd.groupBy(t=>t._1)
// 3.5 将分组后的数据进行结构的转换
val wordToSum: RDD[(String, Int)] = groupRdd.map {
case (word, list) => {
(word, list.size)
}
}
wordToSum.collect().foreach(println)
sc.s扩展复杂版WordCount
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("Hello Scala", 2), ("Hello Spark", 3), ("Hello World", 2)))
1.1.9,filter()过滤
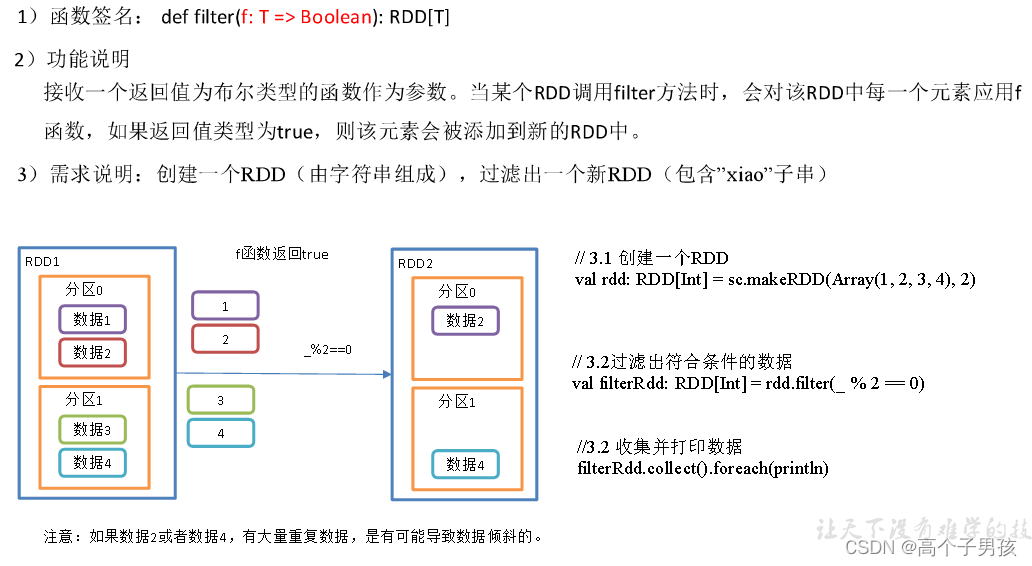
object value07_filter {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3.创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4),2)
//3.1 过滤出符合条件的数据
val filterRdd: RDD[Int] = rdd.filter(_ % 2 == 0)
//3.2 收集并打印数据
filterRdd.collect().foreach(println)
//4 关闭连接
sc.stop()
}
}
1.1.10,sample()采样

object value08_sample {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
// 3.1 创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 10)
// 3.2 打印放回抽样结果
rdd.sample(true, 0.4, 2).collect().foreach(println)
// 3.3 打印不放回抽样结果
rdd.sample(false, 0.2, 3).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
1.1.11,distinct()去重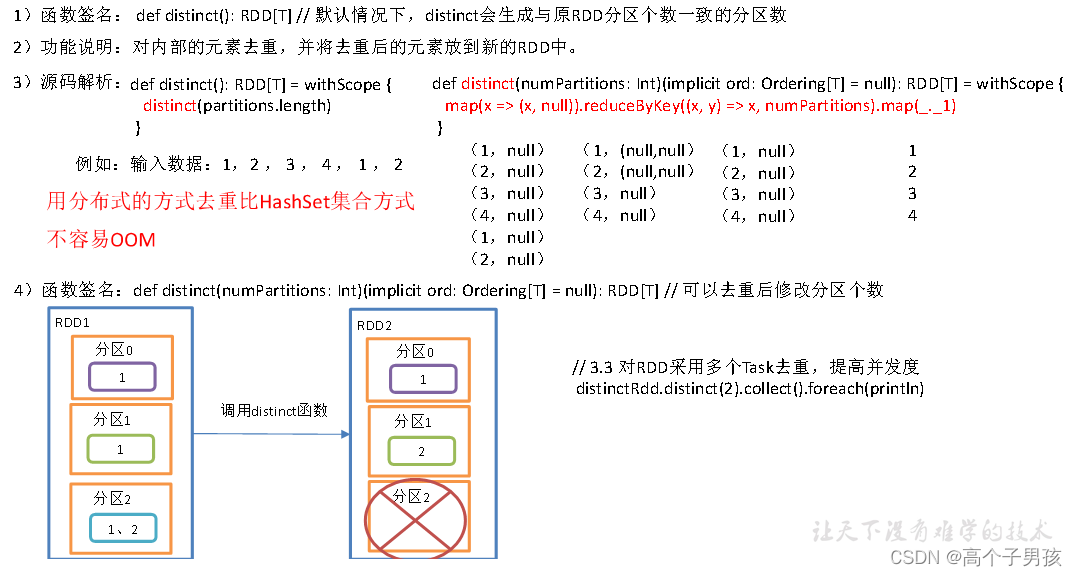
object value09_distinct {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
// 3.1 创建一个RDD
val distinctRdd: RDD[Int] = sc.makeRDD(List(1,2,1,5,2,9,6,1))
// 3.2 打印去重后生成的新RDD
distinctRdd.distinct().collect().foreach(println)
// 3.3 对RDD采用多个Task去重,提高并发度
distinctRdd.distinct(2).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
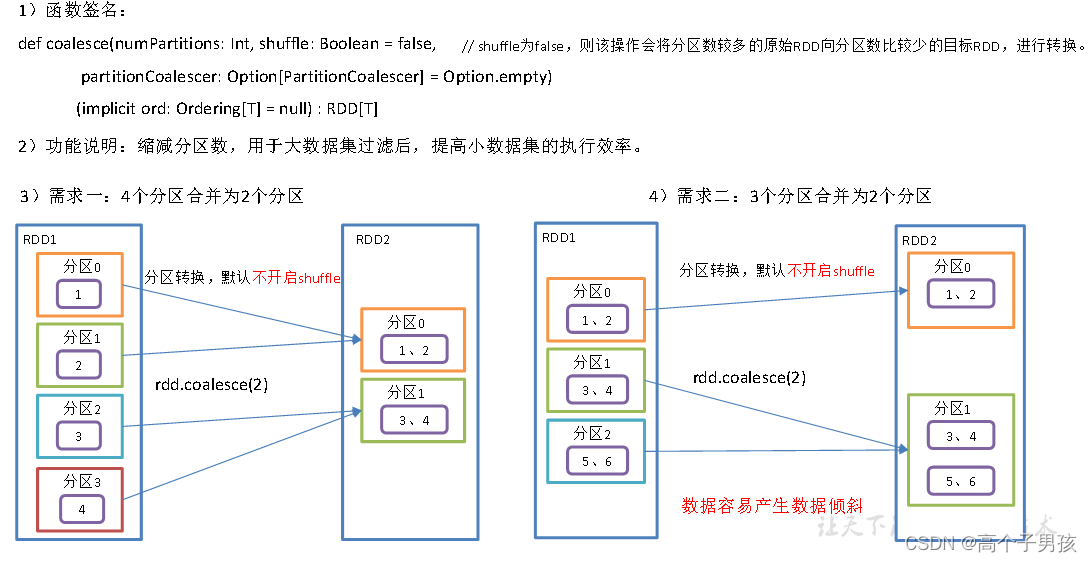
1.1.12,coalesce()重新分区
Coalesce算子包括:配置执行Shuffle和配置不执行Shuffle两种方式。
1、不执行Shuffle方式
object value10_coalesce {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3.创建一个RDD
//val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4), 4)
//3.1 缩减分区
//val coalesceRdd: RDD[Int] = rdd.coalesce(2)
//4. 创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4, 5, 6), 3)
//4.1 缩减分区
val coalesceRdd: RDD[Int] = rdd.coalesce(2)
//5 打印查看对应分区数据
val indexRdd: RDD[Int] = coalesceRdd.mapPartitionsWithIndex(
(index, datas) => {
// 打印每个分区数据,并带分区号
datas.foreach(data => {
println(index + "=>" + data)
})
// 返回分区的数据
datas
}
)
indexRdd.collect()
//6. 关闭连接
sc.stop()
}
}2、执行Shuffle方式
//3. 创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4, 5, 6), 3)
//3.1 执行shuffle
val coalesceRdd: RDD[Int] = rdd.coalesce(2, true)3、Shuffle原理
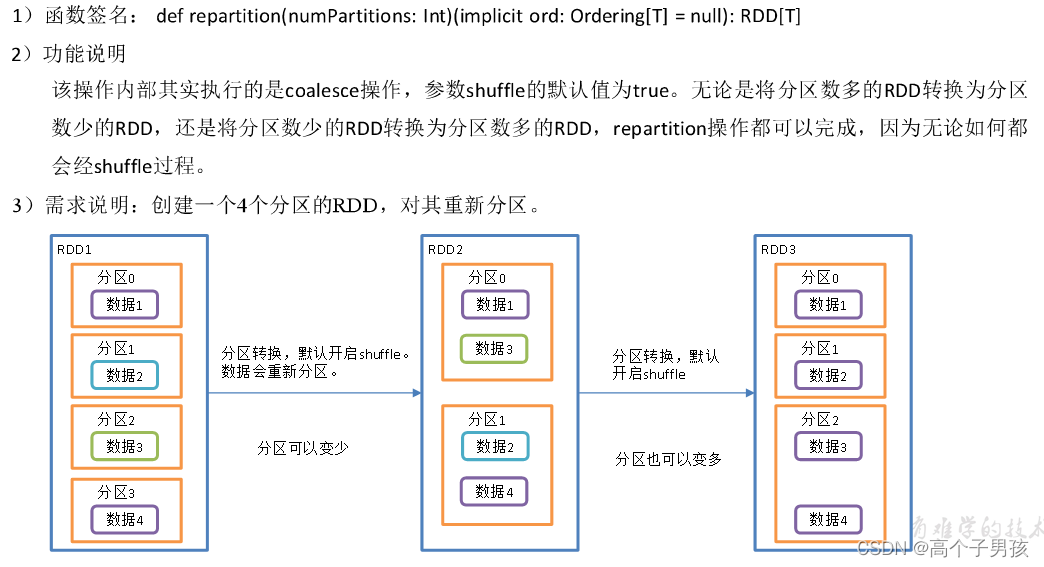
1.1.13,repartition()重新分区(执行Shuffle)
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object value11_repartition {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3. 创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4, 5, 6), 3)
//3.1 缩减分区
//val coalesceRdd: RDD[Int] = rdd.coalesce(2,true)
//3.2 重新分区
val repartitionRdd: RDD[Int] = rdd.repartition(2)
//4 打印查看对应分区数据
val indexRdd: RDD[Int] = repartitionRdd.mapPartitionsWithIndex(
(index, datas) => {
// 打印每个分区数据,并带分区号
datas.foreach(data => {
println(index + "=>" + data)
})
// 返回分区的数据
datas
}
)
indexRdd.collect()
//6. 关闭连接
sc.stop()
}
}
1.1.14,coalesce和repartition区别
1)coalesce重新分区,可以选择是否进行shuffle过程。由参数shuffle: Boolean = false/true决定。
2)repartition实际上是调用的coalesce,进行shuffle。源码如下:
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
3)coalesce一般为缩减分区,如果扩大分区,不使用shuffle是没有意义的,repartition扩大分区执行shuffle。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object value11_repartition {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3. 创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11), 3)
//3.1 合并分区(没有shuffle)
// coalesce一般为缩减分区,如果扩大分区,不使用shuffle是没有意义的
//val pRdd: RDD[Int] = rdd.coalesce(4)
//3.2 重新分区(有shuffle)
val pRdd: RDD[Int] = rdd.repartition(4)
//4 打印查看对应分区数据
val indexRdd: RDD[Int] = pRdd.mapPartitionsWithIndex(
(index, datas) => {
// 打印每个分区数据,并带分区号
datas.foreach(data => {
println(index + "=>" + data)
})
// 返回分区的数据
datas
}
)
indexRdd.collect()
//6. 关闭连接
sc.stop()
}
}1.1.15,sortBy()排序
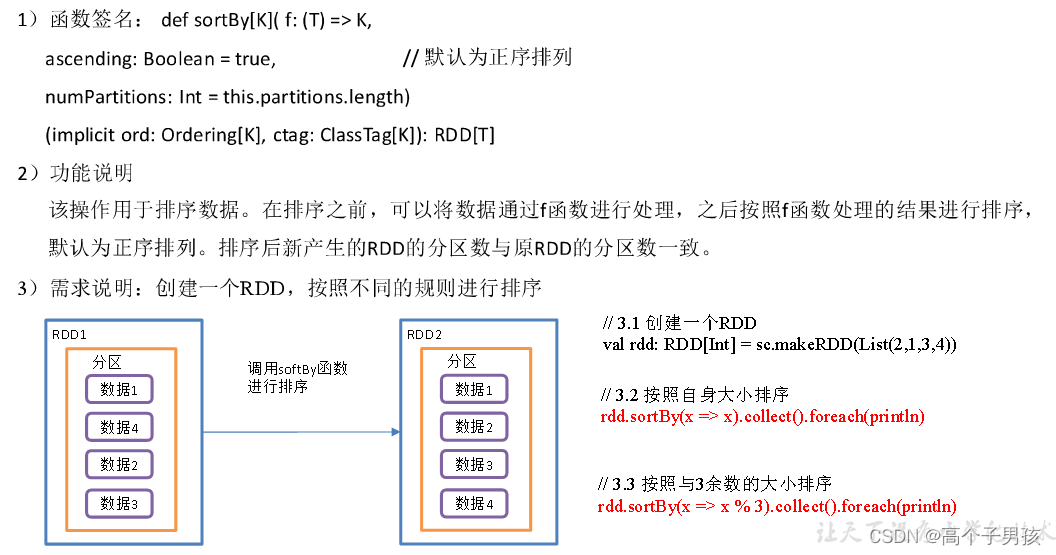
object value12_sortBy {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
// 3.1 创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(2, 1, 3, 4, 6, 5))
// 3.2 默认是升序排
val sortRdd: RDD[Int] = rdd.sortBy(num => num)
sortRdd.collect().foreach(println)
// 3.3 配置为倒序排
val sortRdd2: RDD[Int] = rdd.sortBy(num => num, false)
sortRdd2.collect().foreach(println)
// 3.4 创建一个RDD
val strRdd: RDD[String] = sc.makeRDD(List("1", "22", "12", "2", "3"))
// 3.5 按照字符的int值排序
strRdd.sortBy(num => num.toInt).collect().foreach(println)
// 3.5 创建一个RDD
val rdd3: RDD[(Int, Int)] = sc.makeRDD(List((2, 1), (1, 2), (1, 1), (2, 2)))
// 3.6 先按照tuple的第一个值排序,相等再按照第2个值排
rdd3.sortBy(t=>t).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
1.1.16,pipe()调用脚本
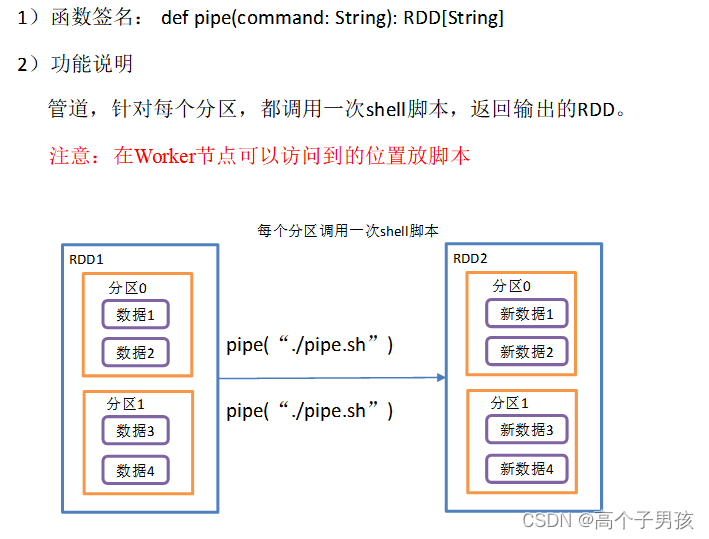
1.2,双Value类型交互
1.2.1,union()并集
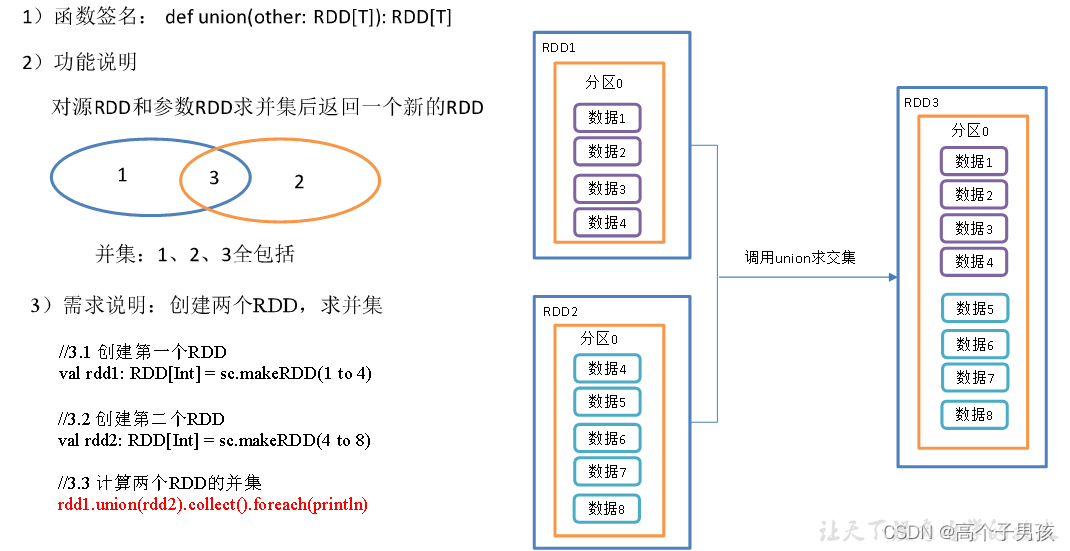
object DoubleValue01_union {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd1: RDD[Int] = sc.makeRDD(1 to 4)
//3.2 创建第二个RDD
val rdd2: RDD[Int] = sc.makeRDD(4 to 8)
//3.3 计算两个RDD的并集
rdd1.union(rdd2).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
1.2.2,subtract ()差集
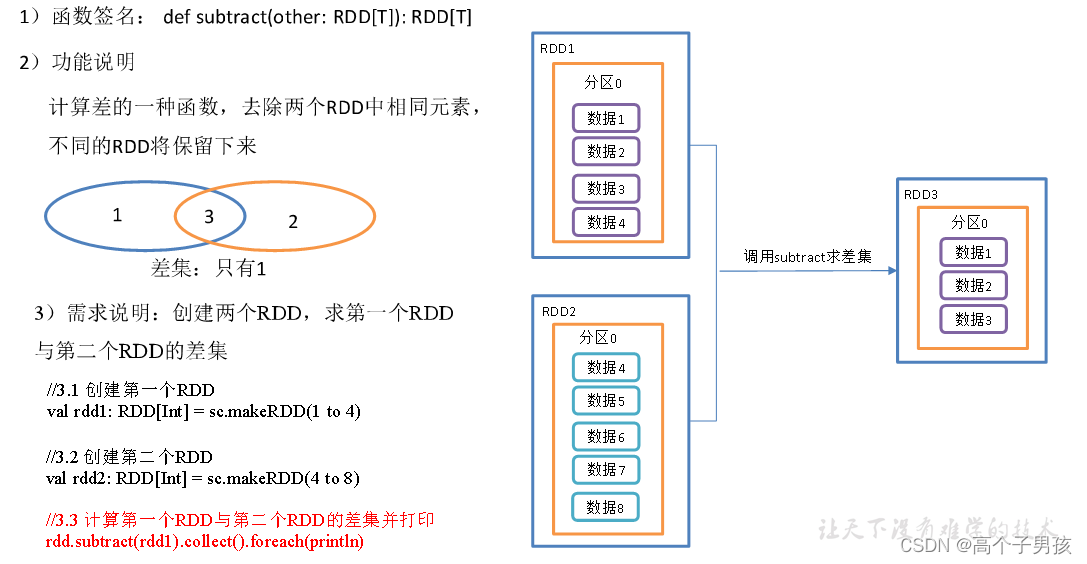
object DoubleValue02_subtract {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4)
//3.2 创建第二个RDD
val rdd1: RDD[Int] = sc.makeRDD(4 to 8)
//3.3 计算第一个RDD与第二个RDD的差集并打印
rdd.subtract(rdd1).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
1.2.3,intersection()交集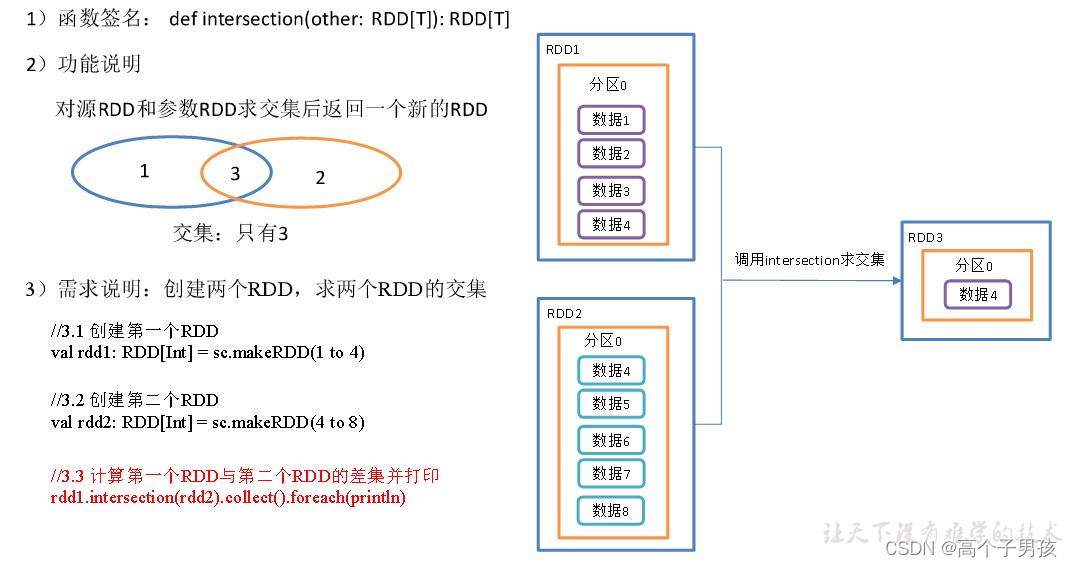
object DoubleValue03_intersection {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd1: RDD[Int] = sc.makeRDD(1 to 4)
//3.2 创建第二个RDD
val rdd2: RDD[Int] = sc.makeRDD(4 to 8)
//3.3 计算第一个RDD与第二个RDD的差集并打印
rdd1.intersection(rdd2).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
1.2.4, zip()拉链
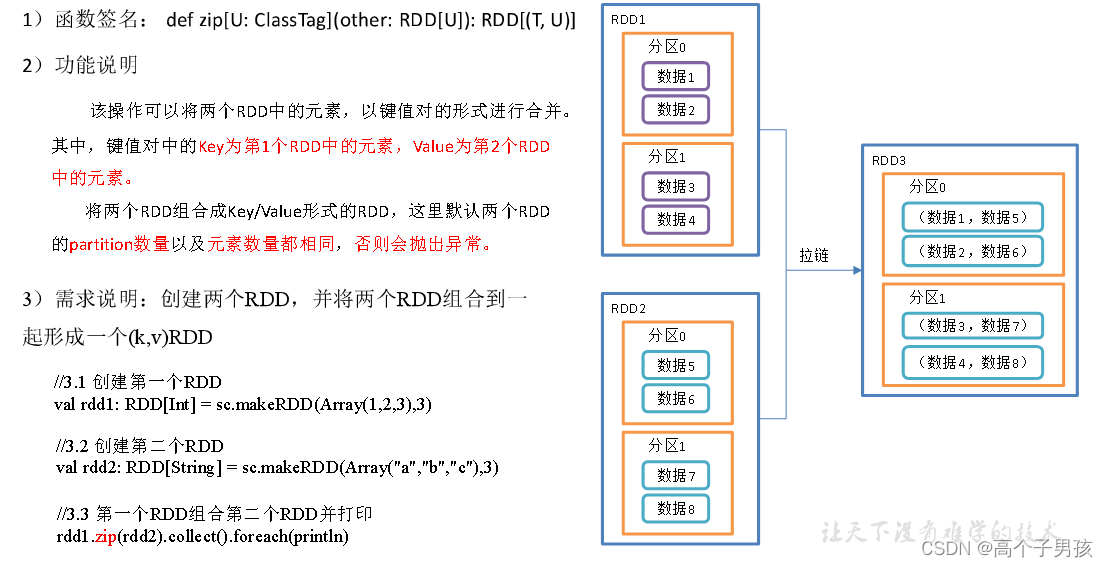
object DoubleValue04_zip {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd1: RDD[Int] = sc.makeRDD(Array(1,2,3),3)
//3.2 创建第二个RDD
val rdd2: RDD[String] = sc.makeRDD(Array("a","b","c"),3)
//3.3 第一个RDD组合第二个RDD并打印
rdd1.zip(rdd2).collect().foreach(println)
//3.4 第二个RDD组合第一个RDD并打印
rdd2.zip(rdd1).collect().foreach(println)
//3.5 创建第三个RDD(与1,2分区数不同)
val rdd3: RDD[String] = sc.makeRDD(Array("a","b"),3)
//3.6 元素个数不同,不能拉链
// Can only zip RDDs with same number of elements in each partition
rdd1.zip(rdd3).collect().foreach(println)
//3.7 创建第四个RDD(与1,2分区数不同)
val rdd4: RDD[String] = sc.makeRDD(Array("a","b","c"),2)
//3.8 分区数不同,不能拉链
// Can't zip RDDs with unequal numbers of partitions: List(3, 2)
rdd1.zip(rdd4).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}1.3,Key-Value类型
1.3.1,partitionBy()按照K重新分区
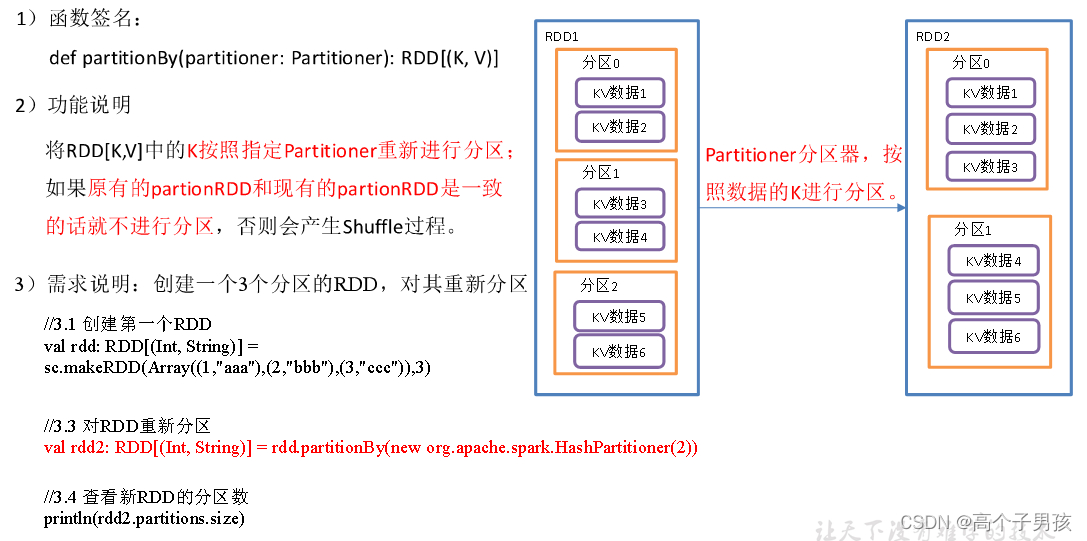
object KeyValue01_partitionBy {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1,"aaa"),(2,"bbb"),(3,"ccc")),3)
//3.2 对RDD重新分区
val rdd2: RDD[(Int, String)] = rdd.partitionBy(new org.apache.spark.HashPartitioner(2))
//3.3 查看新RDD的分区数
println(rdd2.partitions.size)
//4.关闭连接
sc.stop()
}
}HashPartitioner源码解读
class HashPartitioner(partitions: Int) extends Partitioner {
require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.")
def numPartitions: Int = partitions
def getPartition(key: Any): Int = key match {
case null => 0
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
override def equals(other: Any): Boolean = other match {
case h: HashPartitioner =>
h.numPartitions == numPartitions
case _ =>
false
}
override def hashCode: Int = numPartitions
}自定义分区器
object KeyValue01_partitionBy {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "aaa"), (2, "bbb"), (3, "ccc")), 3)
//3.2 自定义分区
val rdd3: RDD[(Int, String)] = rdd.partitionBy(new MyPartitioner(2))
//4 打印查看对应分区数据
val indexRdd: RDD[(Int, String)] = rdd3.mapPartitionsWithIndex(
(index, datas) => {
// 打印每个分区数据,并带分区号
datas.foreach(data => {
println(index + "=>" + data)
})
// 返回分区的数据
datas
}
)
indexRdd.collect()
//5.关闭连接
sc.stop()
}
}
// 自定义分区
class MyPartitioner(num: Int) extends Partitioner {
// 设置的分区数
override def numPartitions: Int = num
// 具体分区逻辑
override def getPartition(key: Any): Int = {
if (key.isInstanceOf[Int]) {
val keyInt: Int = key.asInstanceOf[Int]
if (keyInt % 2 == 0)
0
else
1
}else{
0
}
}
}
1.3.2,reduceByKey()按照K聚合V
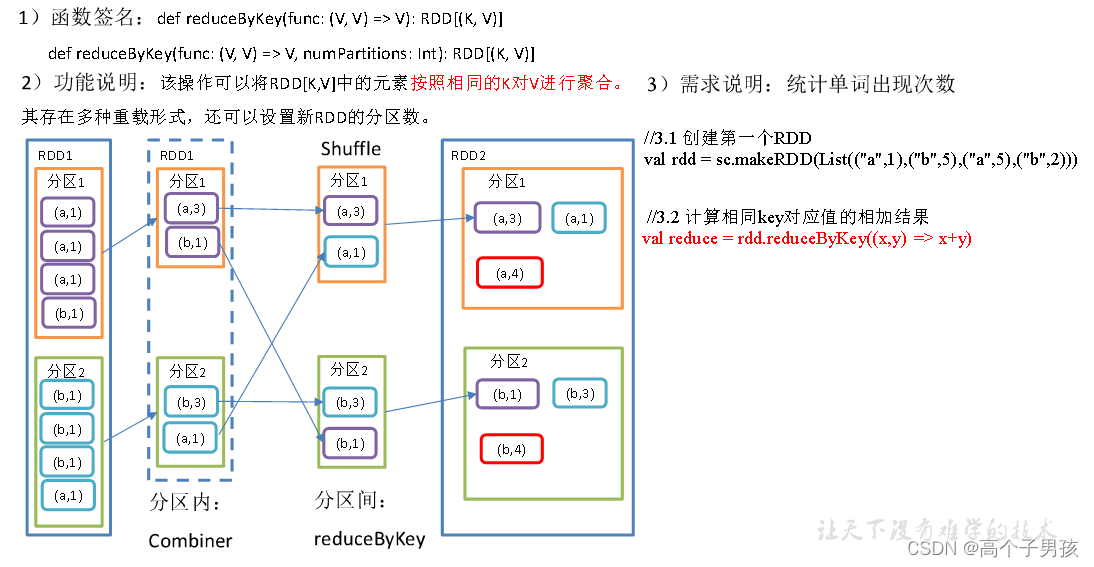
object KeyValue02_reduceByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd = sc.makeRDD(List(("a",1),("b",5),("a",5),("b",2)))
//3.2 计算相同key对应值的相加结果
val reduce: RDD[(String, Int)] = rdd.reduceByKey((x,y) => x+y)
//3.3 打印结果
reduce.collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
1.3.3,groupByKey()按照K重新分组
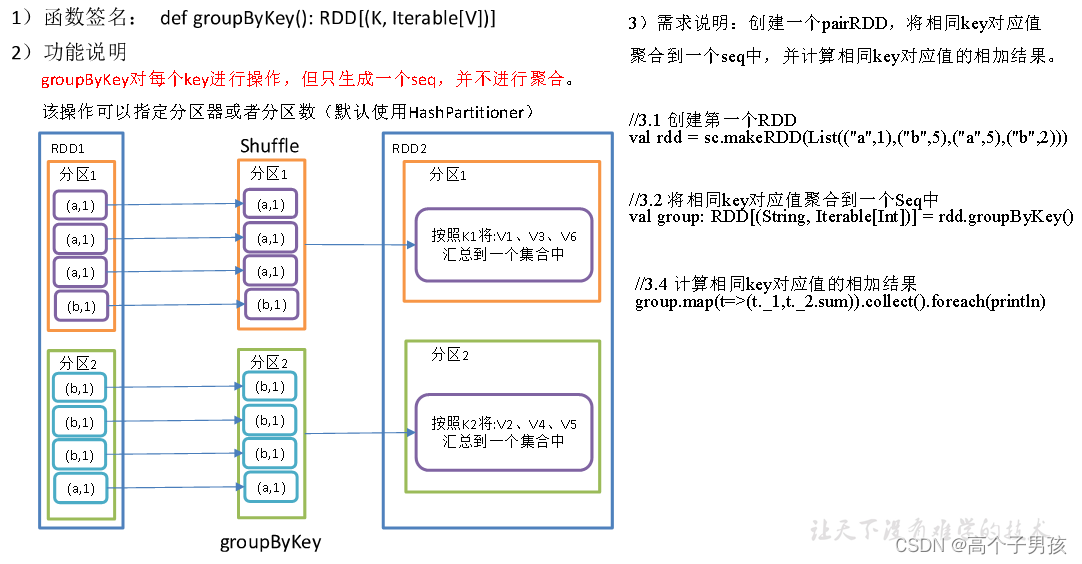
object KeyValue03_groupByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd = sc.makeRDD(List(("a",1),("b",5),("a",5),("b",2)))
//3.2 将相同key对应值聚合到一个Seq中
val group: RDD[(String, Iterable[Int])] = rdd.groupByKey()
//3.3 打印结果
group.collect().foreach(println)
//3.4 计算相同key对应值的相加结果
group.map(t=>(t._1,t._2.sum)).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
1.3.4,reduceByKey和groupByKey区别
1)reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[k,v]。
2)groupByKey:按照key进行分组,直接进行shuffle。
3)开发指导:在不影响业务逻辑的前提下,优先选用reduceByKey。求和操作不影响业务逻辑,求平均值影响业务逻辑。
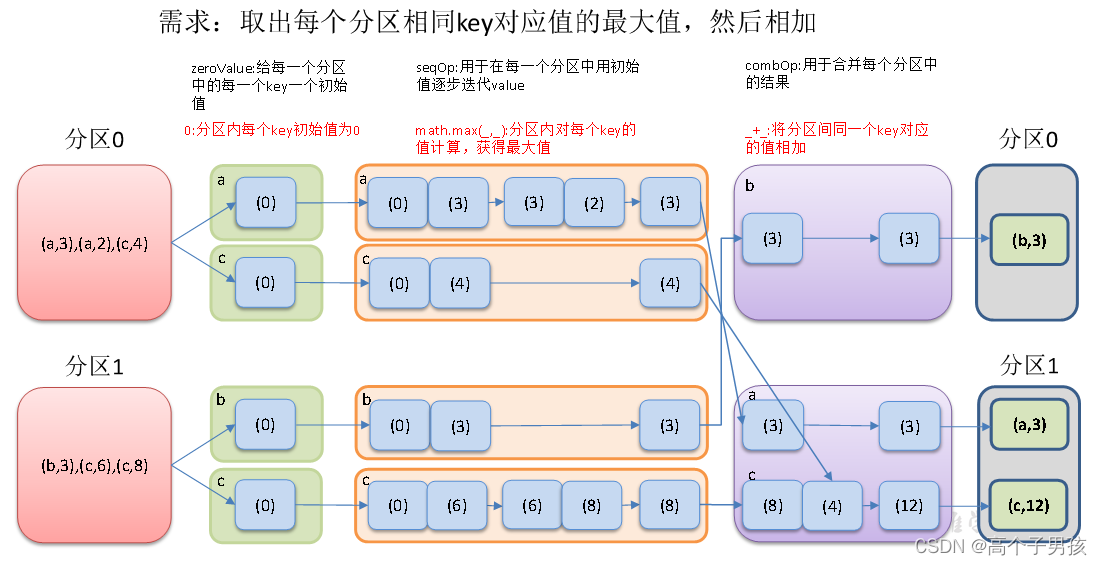
1.3.5,aggregateByKey()按照K处理分区内和分区间逻辑
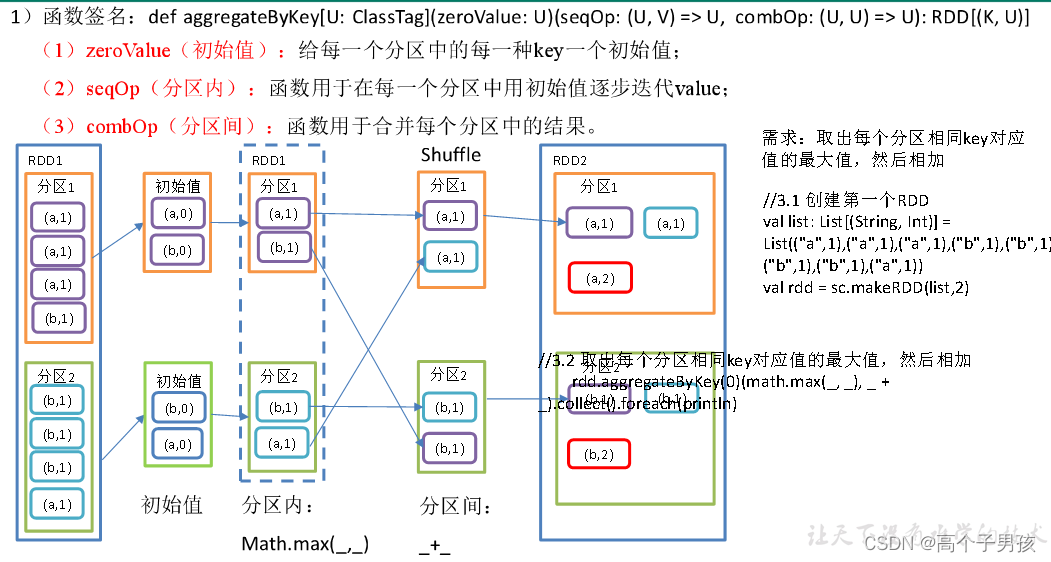
object KeyValue04_aggregateByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a", 3), ("a", 2), ("c", 4), ("b", 3), ("c", 6), ("c", 8)), 2)
//3.2 取出每个分区相同key对应值的最大值,然后相加
rdd.aggregateByKey(0)(math.max(_, _), _ + _).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
1.3.6,foldByKey()分区内和分区间相同的aggregateByKey()
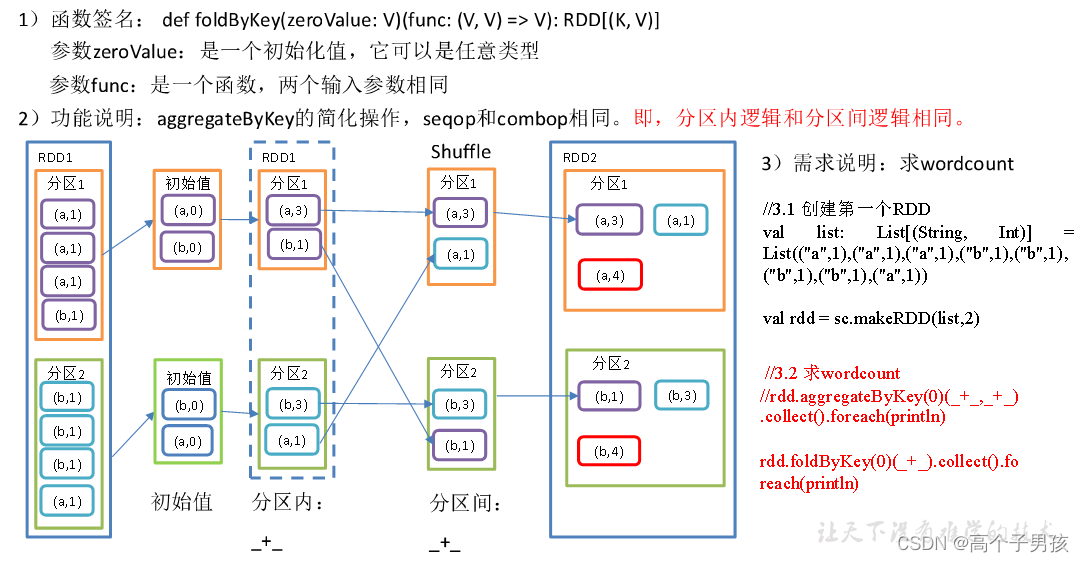
object KeyValue05_foldByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val list: List[(String, Int)] = List(("a",1),("a",1),("a",1),("b",1),("b",1),("b",1),("b",1),("a",1))
val rdd = sc.makeRDD(list,2)
//3.2 求wordcount
//rdd.aggregateByKey(0)(_+_,_+_).collect().foreach(println)
rdd.foldByKey(0)(_+_).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
1.3.7,combineByKey()转换结构后分区内和分区间操作

3)需求说明:创建一个pairRDD,根据key计算每种key的均值。(先计算每个key对应值的总和以及key出现的次数,再相除得到结果)
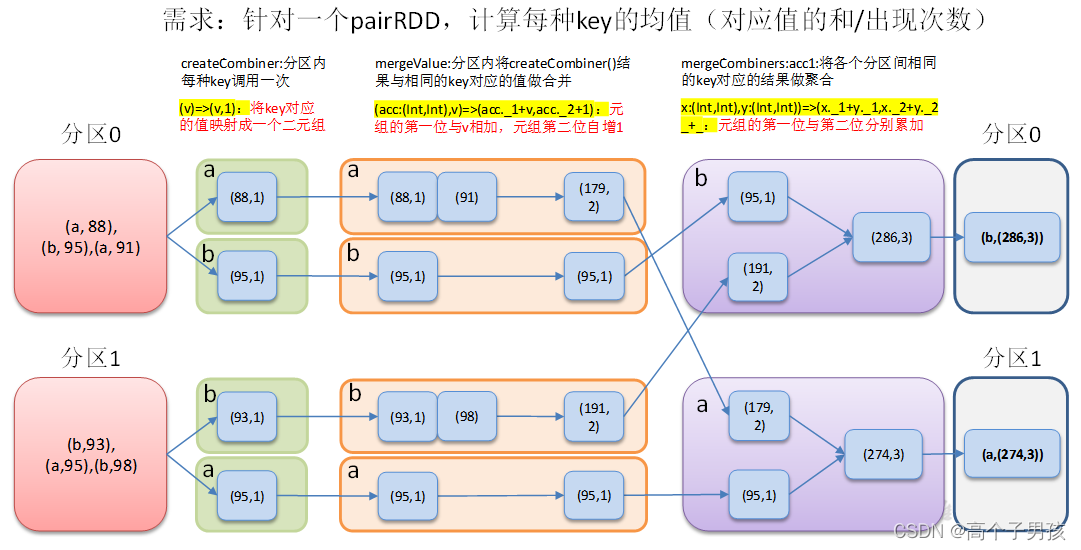
object KeyValue06_combineByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3.1 创建第一个RDD
val list: List[(String, Int)] = List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98))
val input: RDD[(String, Int)] = sc.makeRDD(list, 2)
//3.2 将相同key对应的值相加,同时记录该key出现的次数,放入一个二元组
val combineRdd: RDD[(String, (Int, Int))] = input.combineByKey(
(_, 1),
(acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1),
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2)
)
//3.3 打印合并后的结果
combineRdd.collect().foreach(println)
//3.4 计算平均值
combineRdd.map {
case (key, value) => {
(key, value._1 / value._2.toDouble)
}
}.collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
1.3.8,reduceByKey、aggregateByKey、foldByKey、combineByKey

1.3.9,sortByKey()按照K进行排序
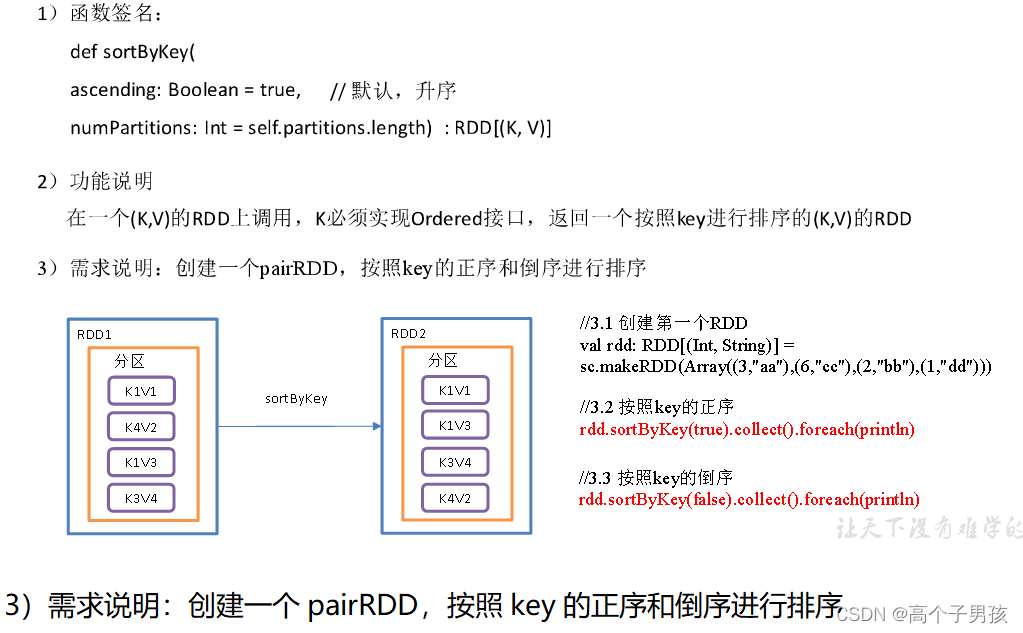
object KeyValue07_sortByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
//3.2 按照key的正序(默认顺序)
rdd.sortByKey(true).collect().foreach(println)
//3.3 按照key的倒序
rdd.sortByKey(false).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}1.3.10,mapValues()只对V进行操作

object KeyValue08_mapValues {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (1, "d"), (2, "b"), (3, "c")))
//3.2 对value添加字符串"|||"
rdd.mapValues(_ + "|||").collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
1.3.11,join()连接 将相同key对应的多个value关联在一起
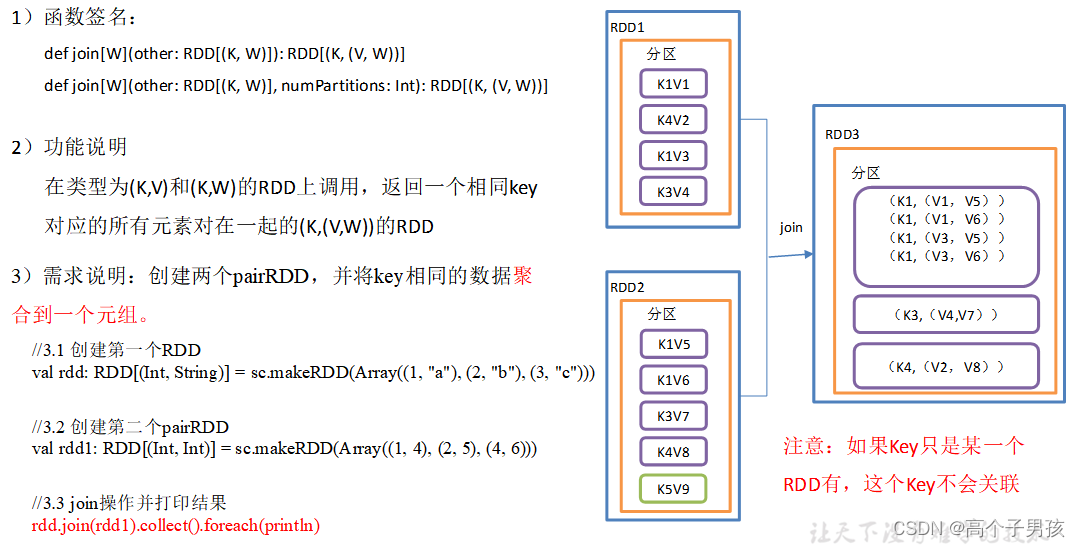
需求说明:创建两个pairRDD,并将key相同的数据聚合到一个元组。
object KeyValue09_join {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (2, "b"), (3, "c")))
//3.2 创建第二个pairRDD
val rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1, 4), (2, 5), (4, 6)))
//3.3 join操作并打印结果
rdd.join(rdd1).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
1.3.12,cogroup() 类似全连接,但是在同一个RDD中对key聚合
操作两个RDD中的KV元素,每个RDD中相同key中的元素分别聚合成一个集合。
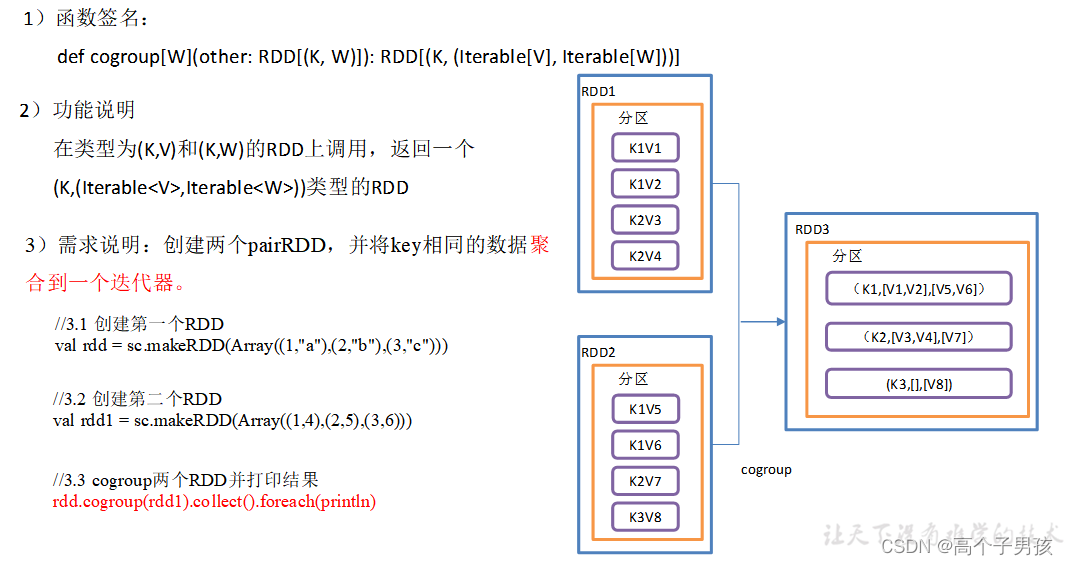
object KeyValue10_cogroup {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1,"a"),(2,"b"),(3,"c")))
//3.2 创建第二个RDD
val rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1,4),(2,5),(3,6)))
//3.3 cogroup两个RDD并打印结果
rdd.cogroup(rdd1).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}2 Action行动算子
行动算子是触发了整个作业的执行。因为转换算子都是懒加载,并不会立即执行。
2.1,reduce()聚合
1)函数签名:def reduce(f: (T, T) => T): T
2)功能说明:f函数聚集RDD中的所有元素,先聚合分区内数据,再聚合分区间数据。

3)需求说明:创建一个RDD,将所有元素聚合得到结果
object action01_reduce {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 聚合数据
val reduceResult: Int = rdd.reduce(_+_)
println(reduceResult)
//4.关闭连接
sc.stop()
}
}
2.2,collect()以数组的形式返回数据集
1)函数签名:def collect(): Array[T]
2)功能说明:在驱动程序中,以数组Array的形式返回数据集的所有元素。
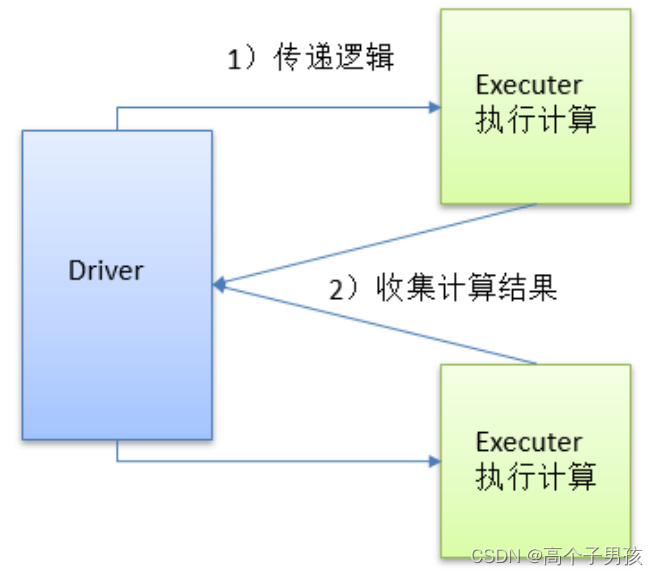
注意:所有的数据都会被拉取到Driver端,慎用
3)需求说明:创建一个RDD,并将RDD内容收集到Driver端打印
object action02_collect {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 收集数据到Driver
rdd.collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
2.3,count()返回RDD中元素个数
1)函数签名:def count(): Long
2)功能说明:返回RDD中元素的个数
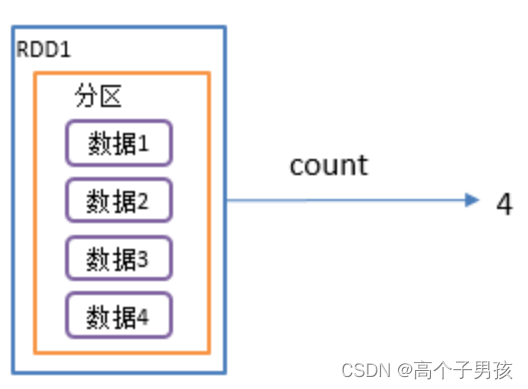
3)需求说明:创建一个RDD,统计该RDD的条数
object action03_count {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 返回RDD中元素的个数
val countResult: Long = rdd.count()
println(countResult)
//4.关闭连接
sc.stop()
}
}
2.4,first()返回RDD中的第一个元素
1)函数签名: def first(): T
2)功能说明:返回RDD中的第一个元素
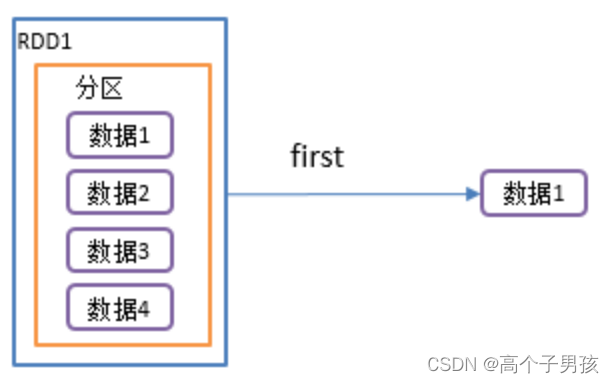
3)需求说明:创建一个RDD,返回该RDD中的第一个元素
object action04_first {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 返回RDD中元素的个数
val firstResult: Int = rdd.first()
println(firstResult)
//4.关闭连接
sc.stop()
}
}
2.5,take()返回由RDD前n个元素组成的数组
1)函数签名: def take(num: Int): Array[T]
2)功能说明:返回一个由RDD的前n个元素组成的数组
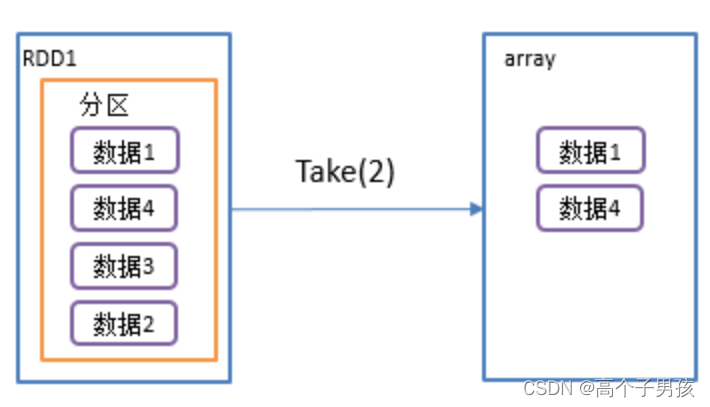
3)需求说明:创建一个RDD,统计该RDD的条数
object action05_take {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 返回RDD中元素的个数
val takeResult: Array[Int] = rdd.take(2)
println(takeResult)
//4.关闭连接
sc.stop()
}
}
2.6,takeOrdered()返回该RDD排序后前n个元素组成的数组
1)函数签名: def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]
2)功能说明:返回该RDD排序后的前n个元素组成的数组
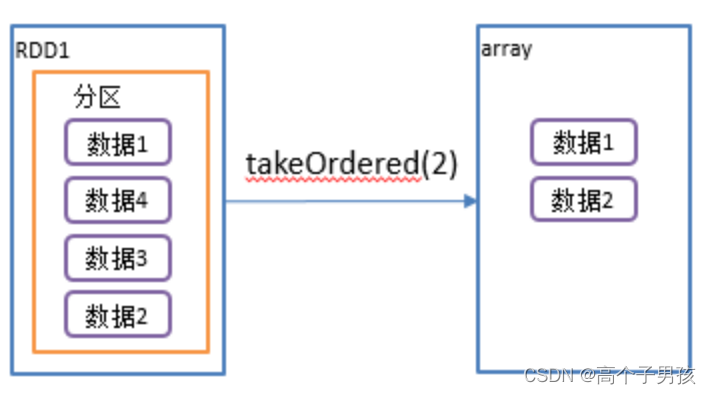
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T] = withScope {
......
if (mapRDDs.partitions.length == 0) {
Array.empty
} else {
mapRDDs.reduce { (queue1, queue2) =>
queue1 ++= queue2
queue1
}.toArray.sorted(ord)
}
}3)需求说明:创建一个RDD,获取该RDD排序后的前2个元素
object action06_takeOrdered{
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,3,2,4))
//3.2 返回RDD中元素的个数
val result: Array[Int] = rdd.takeOrdered(2)
println(result)
//4.关闭连接
sc.stop()
}
}2.7,aggregate()案例
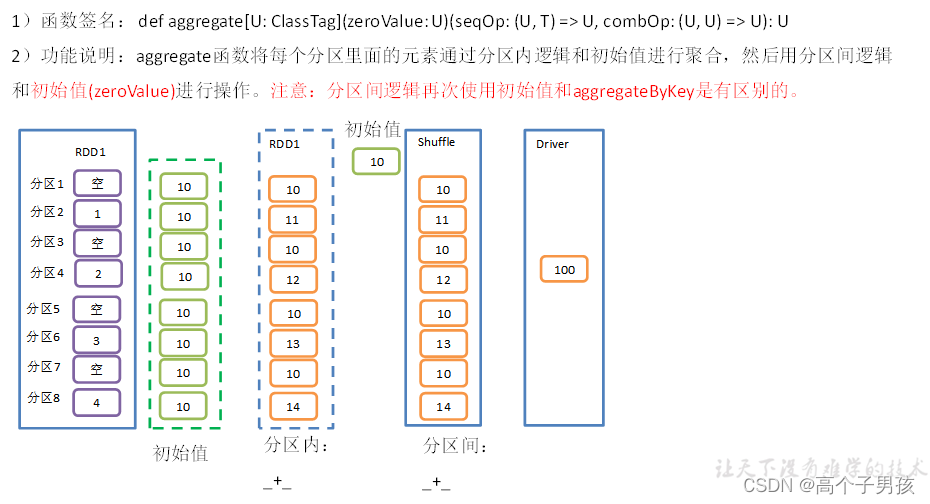
3)需求说明:创建一个RDD,将所有元素相加得到结果
object action07_aggregate {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),8)
//3.2 将该RDD所有元素相加得到结果
//val result: Int = rdd.aggregate(0)(_ + _, _ + _)
val result: Int = rdd.aggregate(10)(_ + _, _ + _)
println(result)
//4.关闭连接
sc.stop()
}
}
2.8,fold()案例
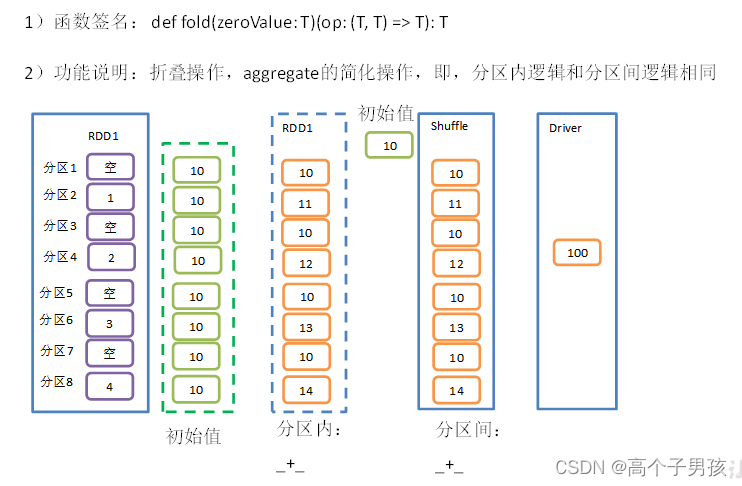
3)需求说明:创建一个RDD,将所有元素相加得到结果
object action08_fold {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
//3.2 将该RDD所有元素相加得到结果
val foldResult: Int = rdd.fold(0)(_+_)
println(foldResult)
//4.关闭连接
sc.stop()
}
}
2.9,countByKey()统计每种key的个数
1)函数签名:def countByKey(): Map[K, Long]
2)功能说明:统计每种key的个数
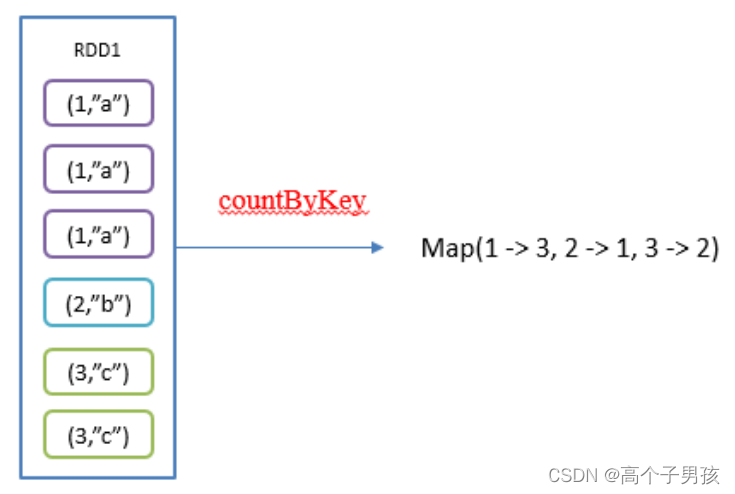
3)需求说明:创建一个PairRDD,统计每种key的个数
object action09_countByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(List((1, "a"), (1, "a"), (1, "a"), (2, "b"), (3, "c"), (3, "c")))
//3.2 统计每种key的个数
val result: collection.Map[Int, Long] = rdd.countByKey()
println(result)
//4.关闭连接
sc.stop()
}
}
2.10,save相关算子
1)saveAsTextFile(path)保存成Text文件
(1)函数签名
(2)功能说明:将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本
2)saveAsSequenceFile(path) 保存成Sequencefile文件
(1)函数签名
(2)功能说明:将数据集中的元素以Hadoop Sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。
注意:只有kv类型RDD有该操作,单值的没有
3)saveAsObjectFile(path) 序列化成对象保存到文件
(1)函数签名
(2)功能说明:用于将RDD中的元素序列化成对象,存储到文件中。
4)代码实现
object action10_save {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
//3.2 保存成Text文件
rdd.saveAsTextFile("output")
//3.3 序列化成对象保存到文件
rdd.saveAsObjectFile("output1")
//3.4 保存成Sequencefile文件
rdd.map((_,1)).saveAsSequenceFile("output2")
//4.关闭连接
sc.stop()
}
}2.11,foreach(f)遍历RDD中每一个元素
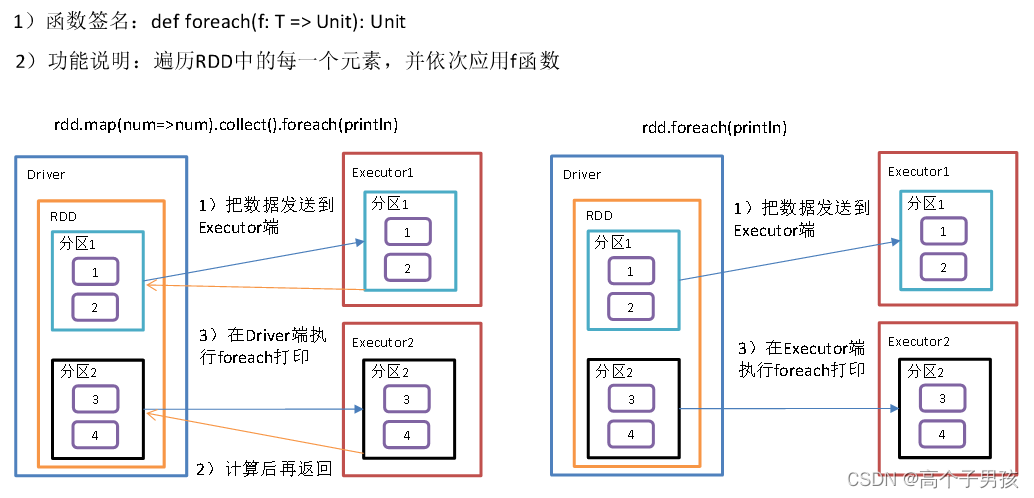
3)需求说明:创建一个RDD,对每个元素进行打印
object action11_foreach {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
// val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 收集后打印
rdd.map(num=>num).collect().foreach(println)
println("****************")
//3.3 分布式打印
rdd.foreach(println)
//4.关闭连接
sc.stop()
}
}