klee内存模型
- 一.LLVM基础
- 二.Klee中相关的类
- 2.1.基础类
- 2.2.内存管理相关类
- 三.示例
- 3.1.示例1
- 3.2.示例2
- 3.3.示例3
- 3.4.示例4
这篇blog主要通过一些简单的示例来了解以下klee对内存的建模方式。
首先一个C语言程序在运行时,内存主要包括:
-
代码段,程序计数器
PC就指向代码段中下一个要指向的指令的值。 -
全局变量段,这些数据会在程序结束后由操作系统自动释放,包括。
-
data段: 初始化过的全局变量+静态变量。
-
bss段:存放未初始化过的全局+静态变量段。
-
-
常量段(只读)。
-
栈。
-
堆。
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int a = 0; // 全局初始化区(data段)
char *p1; // 全局未初始化区(bss段)
int main()
{
int b; // 栈区
char s[] = "abc"; // abc\n在栈区,s指向abc\n的首地址
char *p2; // p2指针栈区
char *p3 = "123456"; // 123456\0 在常量区,p3在栈上,体会与 char s[]="abc"; 的不同
static int c = 0; // c存放在data段
p1 = (char *)malloc(10), // malloc的数组在堆区,p1在bss段,p1指向堆区。
p2 = (char *)malloc(20); // p2在栈段,数据在堆区,p2指向堆区。
// 123456\0 放在常量区,但编译器可能会将它与p3所指向的"123456"优化成一个地方
strcpy(p1, "123456");
}
一.LLVM基础
这一部分主要介绍一些LLVM指令的基础,关于各个指令的功能可以参考官方文档。
int cus_add(int a, int b) {
return a + b;
}
int main() {
int a = 10, b = 9;
int c = cus_add(a, b);
return 0;
}
LLVM IR为:
; ModuleID = 'test.c'
source_filename = "test.c"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @cus_add(i32 %a, i32 %b) #0 {
entry:
%a.addr = alloca i32, align 4
%b.addr = alloca i32, align 4
store i32 %a, i32* %a.addr, align 4
store i32 %b, i32* %b.addr, align 4
%0 = load i32, i32* %a.addr, align 4
%1 = load i32, i32* %b.addr, align 4
%add = add nsw i32 %0, %1
ret i32 %add
}
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main() #0 {
entry:
%retval = alloca i32, align 4
%a = alloca i32, align 4
%b = alloca i32, align 4
%c = alloca i32, align 4
store i32 0, i32* %retval, align 4
store i32 10, i32* %a, align 4
store i32 9, i32* %b, align 4
%0 = load i32, i32* %a, align 4
%1 = load i32, i32* %b, align 4
%call = call i32 @cus_add(i32 %0, i32 %1)
store i32 %call, i32* %c, align 4
ret i32 0
}
attributes #0 = { noinline nounwind optnone uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
!llvm.module.flags = !{!0}
!llvm.ident = !{!1}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{!"clang version 11.0.0"}
在LLVM中,每个指令为1个Instruction对象。其中:
-
Instruction类继承自Value类。在上面的IR可以看到几乎每条指令都定义1个变量(除了store指令),因此变量直接用定义它的指令标识。比如main函数的%a变量就用%a = alloca i32, align 4指令对应的指针标识。 -
每个指令都有对应的操作数,操作数为
Value*类型,表示定义该操作数的指令,比如%call = call i32 @cus_add(i32 %0, i32 %1)的2个操作数就是%0 = load i32, i32* %a, align 4和%1 = load i32, i32* %b, align 4对应的指针。 -
在LLVM IR中,存在顶层变量(top-level variable)和取地址变量(address-taken variable),这在SVF wiki中也有提到:
-
取地址变量主要是
alloca等指令定义的变量,这些变量会实际分配内存空间,klee在运行过程中会为这些变量分配内存对象(MemoryObject)。 -
顶层变量包括所有指令定义的变量,不过像
%0 = load i32, i32* %a, align 4这种变量,klee在运行过程中并不会分配内存对象。
-
在LLVM中,Constant类型为IR中出现的常量,比如上面IR中出现的 i32 0, i32 10, i32 9。需要注意的是,Function是 Constant 的子类,可以说函数也被当作常量来对待。
二.Klee中相关的类
2.1.基础类
首先,klee涉及到的基础类包括:
-
KModule类,这个类是对LLVM Module类的封装。一个
Module对应一个编译出来的bc文件,如果符号执行的时候需要链接其它Module,klee会先将多个Module链接成1个Module(参考main函数第1351行和Executor.cpp 519行)。其成员变量中constants,constantMap,constantTable负责记录常量信息,相当于内存区域的常量段。
-
KConstant是对LLVM Constant类的包装。其成员变量中:
-
id为该常量在Module中出现的顺序。比如上面Module的main函数中依次出现常量i32 0、i32 10和i32 9。那么创建了3个KConstant中i32 0的id为0,i32 10的id为1,i32 9对应的id为2(id是大致推断,不一定完全正确,考虑到Function也属于常量)。 -
ki为第一遇到该常量对象的llvm指令对应的KInstruction指针。比如i32 10对应的指令是store i32 10, i32* %a, align 4.
-
-
KFunction是对LLVM Function类的包装。成员变量中:
-
numArgs为该函数的形参数量。 -
numInstructions为该函数指令数量。 -
numRegisters是形参 + 指令的数量(首先假设每个指令都会对应1个变量)。 -
instructions为该函数包含的指令(用KInstruction类表示)。
-
-
KInstruction,这个类是对LLVM Instruction类的封装。其成员变量中:
-
inst是对应LLVMInstruction指针。 -
operands为该指令包含的操作数对应的索引。索引定义为(参考getOperandNum函数):-
如果操作数是函数形参,那么为参数顺序。比如
cus_add中store i32 %a, i32* %a.addr, align 4中%a为函数第一个形参,因此%a对应的operand为0。 -
如果操作数是局部变量,那么为该操作数指令出现的顺序,这个顺序是从参数数量开始计数的。比如
cus_add中%add = add nsw i32 %0, %1的%0对应的operand是6,因为该函数有2个参数,%0在第5个指令被定义。 -
如果操作数是常量,返回对应- (常量表中的索引 + 2)。这么做是因为非负索引对应形参和局部变量,-1预留给其它情况。需要注意的是函数定义
Function也算常量,会出现在常量表中。 -
其它情况返回-1。
-
-
klee在开始符号执行之前会扫描一遍需要分析的 Module,初始化指令和常量信息(参考Executor::setModule函数543行和KModule::manifest函数)。
2.2.内存管理相关类
-
MemoryManager类,该类负责管理符号内存,其成员变量中:
-
objects为已经分配的内存对象集合。 -
deterministicSpace为符号内存空间首地址,默认初始化100MB。 -
nextFreeSlot为符号内存空间下一个可用空间起始地址。它和deterministicSpace只负责指示内存空间,在deterministicSpace的堆空间中并不会被实际写入值。
-
-
MemoryObject类,该类表示一个符号内存对象,其成员变量中:
-
address为该内存对象的首地址。 -
size为内存对象的大小。 -
allocSite为分配该内存对象的指令。(alloca指令) -
内存对象的比较可以参考compare函数。
-
-
ObjectState类记录了一个内存对象的状态,包括每个byte对应的状态,已经该内存对象是否只读标识
readOnly。 -
AddressSpce类管理已分配的内存对象以及对应的状态。
-
StackFrame类为符号栈帧,runFunctionAsMain函数在新建起始状态时会为
main函数分配一个符号栈帧(参考ExecutionState构造函数),需要注意的是stackFrame是ExecutionState的成员变量,意味着每个状态都会保存一个符号栈帧。每个栈帧记录着:-
caller:调用该函数的指令。比如main函数调用cus_add会为cus_add建立一个新的栈帧,该栈帧的caller为main函数中%call = call i32 @cus_add(i32 %0, i32 %1)指令。而main函数对应的栈帧caller为nullptr。 -
kf:该栈帧对应被调用的函数,main函数调用cus_add时新建的栈帧kf指向cus_add函数。 -
allocas为该栈帧中分配的内存对象。一般分配的局部内存对象通过Executor::bindObjectInState添加到对应栈帧的allocas,并为该对象赋予一个状态。 -
locals为该栈帧中所有顶层变量(同时是局部变量)的值,每个local对应1个IR。初始化为locals分配的空间为numRegisters。每个local存储一个顶层变量(包括形参)对应的值的表达式(ref<Expr>类型)。
-
三.示例
这部分主要通过几个示例来说明klee运行过程中符号内存的变化状态。klee中符号执行的worklist算法在Executor::run函数中,核心代码为:
while (!states.empty() && !haltExecution) {
ExecutionState &state = searcher->selectState(); // 根据搜索策略选择状态
KInstruction *ki = state.pc; // 将要执行的指令
stepInstruction(state); // 更新pc的信息
executeInstruction(state, ki); // 执行指令
updateStates(&state); // 更新状态列表
}
其中executeInstruction是这一部分的重点,不同的指令有不同的执行方式。
3.1.示例1
示例1沿用前面的 cus_add 代码,该程序不包括外部输入、全局变量、数组等。涉及到的LLVM指令仅有 alloca,store,load,call,同时由于不存在分支语句,因此不会发生fork,整个符号执行过程状态列表始终只有1个状态。
int cus_add(int a, int b) {
return a + b;
}
int main() {
int a = 10, b = 9;
int c = cus_add(a, b);
return 0;
}
LLVM IR为:
; ModuleID = 'test.c'
source_filename = "test.c"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @cus_add(i32 %a, i32 %b) #0 {
entry:
%a.addr = alloca i32, align 4
%b.addr = alloca i32, align 4
store i32 %a, i32* %a.addr, align 4
store i32 %b, i32* %b.addr, align 4
%0 = load i32, i32* %a.addr, align 4
%1 = load i32, i32* %b.addr, align 4
%add = add nsw i32 %0, %1
ret i32 %add
}
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main() #0 {
entry:
%retval = alloca i32, align 4
%a = alloca i32, align 4
%b = alloca i32, align 4
%c = alloca i32, align 4
store i32 0, i32* %retval, align 4
store i32 10, i32* %a, align 4
store i32 9, i32* %b, align 4
%0 = load i32, i32* %a, align 4
%1 = load i32, i32* %b, align 4
%call = call i32 @cus_add(i32 %0, i32 %1)
store i32 %call, i32* %c, align 4
ret i32 0
}
attributes #0 = { noinline nounwind optnone uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
!llvm.module.flags = !{!0}
!llvm.ident = !{!1}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{!"clang version 11.0.0"}
该示例不需要关注klee中全局变量初始化的部分,这里将要执行 main 函数第1条指令时符号内存处于刚初始化完成的状态。下面一条一条指令来看。
-
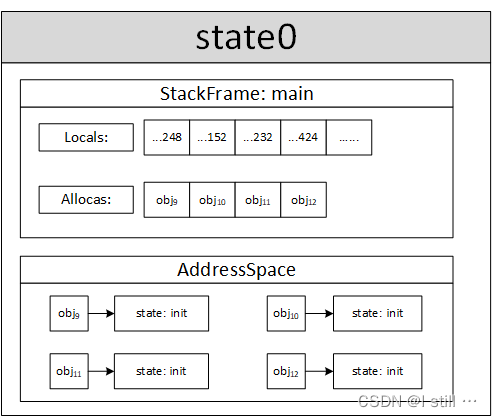
%retval = alloca i32, align 4,执行alloca指令。对应代码为case::Alloca和executeAlloc函数。主要完成:-
该指令新分配了一个内存对象(对应代码),
size为4(32位4字节),allocSite为%retval = alloca i32, align 4,dump出来可以发现,该对象的id为9(后面就叫9号对象),address为93926455853248(不同的环境运行结果可能不同)。 -
9号对象会被赋予一个新的对象状态(由
state.addressSpace管理,对应代码)并添加进main函数栈帧的allocas域。 -
将9号对象的地址写入
main函数栈帧中该指令对应的局部变量域(对应代码),具体来说,%retval = alloca i32, align 4对应的register索引为0(没有形参),9号对象的地址为93926455853248,因此main函数栈帧的locals[0]写入了93926455853248(这里地址值对应的类型是ref<Expr>而不是int或者Constant类型)。
-
-
%a = alloca i32, align 4,该指令符号执行后分配的内存对象id = 10,size = 4,address=93926455853152,allocSite为%a = alloca i32, align 4。main函数栈帧allocas域添加了10号对象,locals[1]写入93926455853152(%a = alloca i32, align 4对应的索引为1)。 -
%b = alloca i32, align 4,该指令符号执行后分配的内存对象id = 11,size = 4,address=93926455853232,allocSite为%b = alloca i32, align 4。main函数栈帧allocas域添加了11号对象,locals[2]写入93926455853232。 -
%c = alloca i32, align 4,该指令符号执行后分配的内存对象id = 12,size = 4,address=93926455853424,allocSite为%c = alloca i32, align 4。main函数栈帧allocas域添加了12号对象,locals[3]写入93926455853424。
图中 stackframe 中 locals 的4个值为4个地址,allocas 为4个分配的内存对象,这4个对象在 addressSpace 中还没被写入值,为初始状态。
-
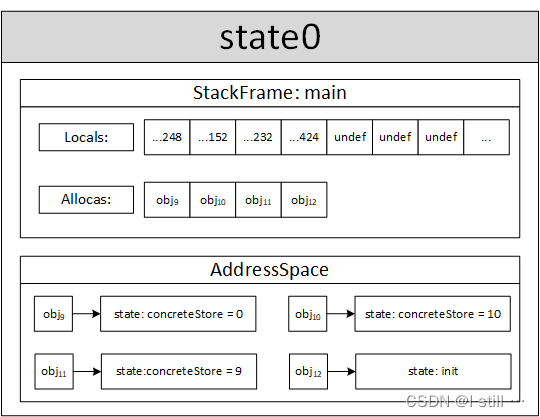
store i32 0, i32* %retval, align 4,执行store指令(对应代码参考case::Store和executeMemoryOperation函数)。-
首先读取将要写入的地址和写入的值(参考eval函数),
store指令第0个操作数是写入的值、第1个操作数是写入的地址。这里写入的数value是常量、因此value对应的数从常量表中获取,而地址base是局部变量域,对应的指令是%retval = alloca i32, align 4,索引是0,所以base为locals[0].value、即93926455853248(ref<Expr>类型)。 -
接下来获取写入地址后通过约束求解找出地址空间中可能的1个内存对象(参考代码executeMemoryOperation第4163行)。求解内存对象由
addressSpace负责,它通过二分查找找出地址空间离base最相近的一个内存对象并返回。在这个示例中,该store指令需要写入的内存对象mo是9号对象。 -
接下来符号执行器会求解出写入的地址相对该对象基址的偏移offset(这里的几个读写偏移都是0),并检查是否发生越界读写(这部分内容暂时不关注),这段代码并没有发生越界读写。
-
如果该内存对象可写,那么
addressSpace会为该对象创建一个新的内存状态,并将value(常量0)写入该状态,此时9号对象对应的值变成了常量0。
-
-
store i32 10, i32* %a, align 4指令执行完毕后10号对象被赋予了新的状态,值为常量10。 -
store i32 9, i32* %b, align 4指令执行完毕后11号对象被赋予了新的状态,值为常量11。
下图中 locals 中 store 指令对应的3个值是undef,而9、10、11号对象已被赋值。
-
%0 = load i32, i32* %a, align 4对应Load指令,load指令第0个操作数是加载的地址。这里-
从操作数为
%a = alloca i32, align 4,读取之后的base为93926455853152,addressSpace求解的结果为10号对象。 -
跟
store指令一样,load指令也会计算地址相对内存对象基址偏移以及检查是否发生溢出读。这里偏移是0,同时并没有溢出读。 -
从10号对象对应的对象状态中读取该对象的值。读取出来的值应为常量10。
-
将变量
%0的值设置为常量10。具体来说,%0 = load i32, i32* %a, align 4对应的register索引为7,main的栈帧locals[7]写入了常量10。
-
-
%1 = load i32, i32* %b, align 4执行结束后,locals[8]写入了常量9。

-
%call = call i32 @cus_add(i32 %0, i32 %1),call指令对应的处理代码为case::Call-
首先获取被调用的函数,这里
f指向cus_add函数定义。不过某些情况下f可能会返回nulptr,这种情况出现在函数指针调用时。 -
然后加载参数的值。这里的参数为
%0和%1,也就是分别从main栈帧locals[7]和locals[8]读取常量10和常量9放入参数列表arguments。接着处理函数调用。 -
调用的函数分为在当前模块中定义好的和没定义好的,像链接库中的函数如何运行klee没用
--link-llvm-lib进行链接的话那么这些函数会被视为未定义。Function类有1个成员函数isDeclaration对未定义的函数返回true,定义好的返回false。这里cus_add已定义好,那么klee会为cus_add创建一个新的符号栈帧,caller设置为%call = call i32 @cus_add(i32 %0, i32 %1)指令。 -
将下一个要执行的指令设置为
cus_add的第一条指令。 -
Function还有1个成员函数isVarArg返回该函数是否有可变参数,这里cus_add并没有可变参数,直接跳过。 -
接着将函数调用参数压入
cus_add的栈帧。具体来说,cus_add的两个形参对应的register索引为0,1。所以cus_add栈帧的locals[0]设置为10,locals[1]设置为9。
-
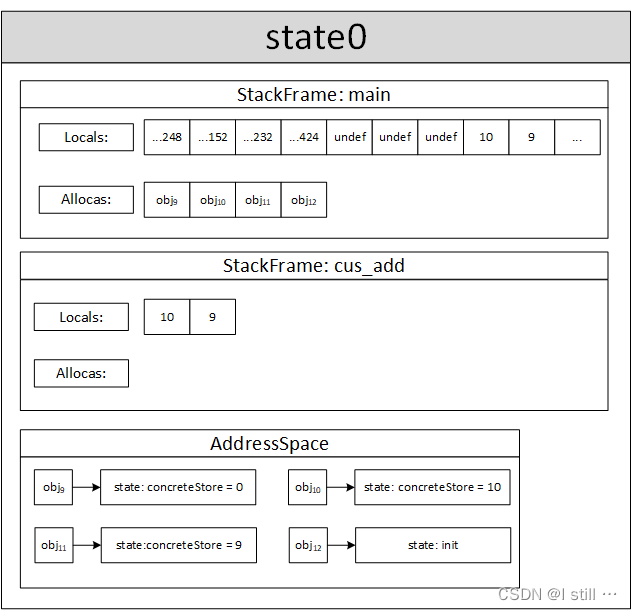
-
%a.addr = alloca i32, align 4,为形参a分配地址,创建内存对象18号(dump出来的结果),地址为93926455853064。 -
%b.addr = alloca i32, align 4,为形参b分配地址,创建内存对象19号,地址为93926455853176。 -
store i32 %a, i32* %a.addr, align 4从locals[0]中读取输入参数10,写入18号对象(为18号创建新的内存对象,concreteStore为10)。 -
store i32 %b, i32* %b.addr, align 4从locals[1]中读取输入参数9,写入19号对象。 -
%0 = load i32, i32* %a.addr, align 4从93926455853064对应的内存对象也就是18号对象中读取数值10,存入locals[6]。 -
%1 = load i32, i32* %b.addr, align 4从93926455853176对应的内存对象也就是19号对象中读取数值9,存入locals[7]。 -
%add = add nsw i32 %0, %1从locals[6]和locals[7]中读取数值10和9,进行加法运算后计算出数值19,存入locals[8]。
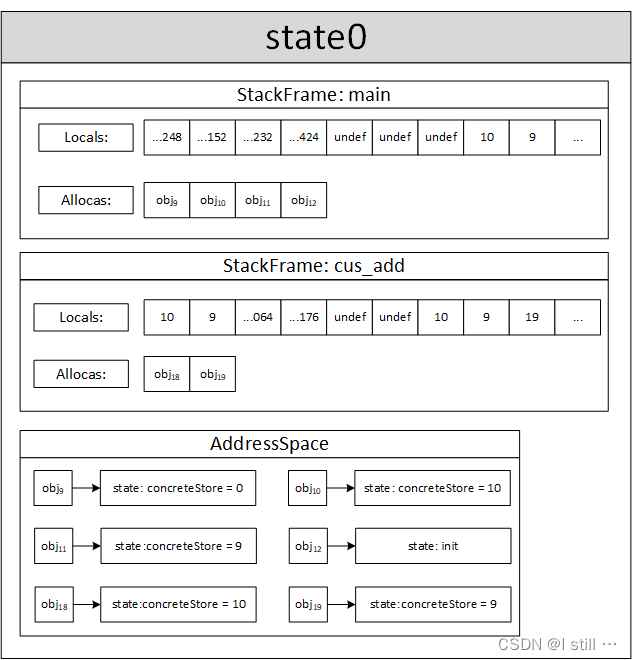
-
ret i32 %add,执行该指令时-
klee会获取该栈帧对应的caller:
%call = call i32 @cus_add(i32 %0, i32 %1)。 -
接着计算返回值(如果是
void返回0,不是返回操作数),这里返回值对应%add为19。 -
如果是
main函数返回,那么结束当前状态的执行。 -
返回的不是
main函数,弹出栈帧。 -
如果
caller不是invoke指令,那么将pc设置为caller下一条指令(这里暂时不考虑invoke指令)。 -
将返回值写入
caller对应的locals域。具体来说,将19写入main函数栈帧的locals[9]。
-
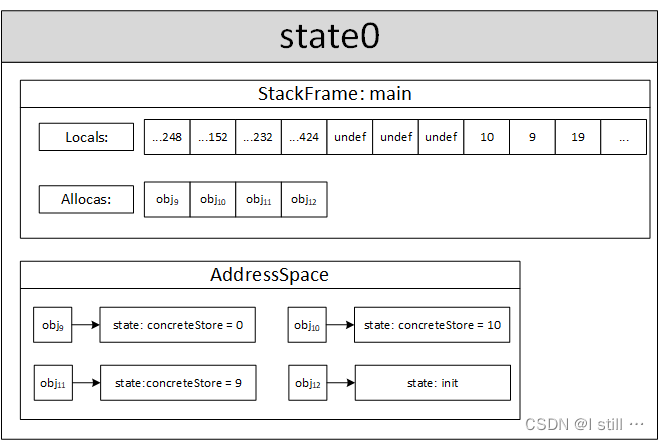 -
- store i32 %call, i32* %c, align 4,将19写入12号内存对象。
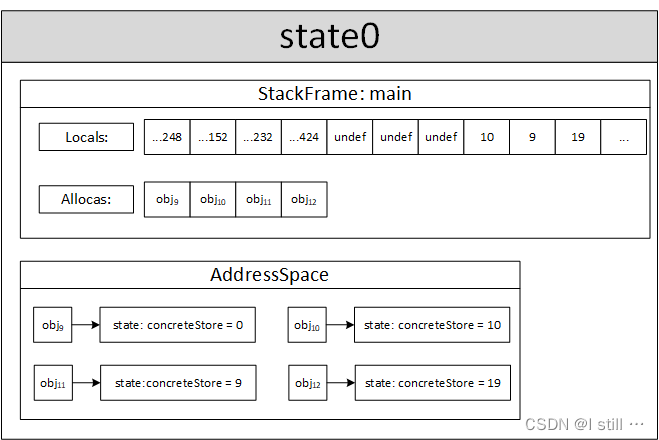
ret i32 0终结state0的执行,生成测试用例。
3.2.示例2
int b = 10;
int main(){
int a = 10;
int arr[10] = {1, 2, 3};
int arr2[10][20];
arr2[2][3] = 1;
}
LLVM IR为
; ModuleID = 'test.c'
source_filename = "test.c"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
@b = dso_local global i32 10, align 4
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main() #0 {
entry:
%a = alloca i32, align 4
%arr = alloca [10 x i32], align 16
%arr2 = alloca [10 x [20 x i32]], align 16
store i32 10, i32* %a, align 4
%0 = bitcast [10 x i32]* %arr to i8*
call void @llvm.memset.p0i8.i64(i8* align 16 %0, i8 0, i64 40, i1 false)
%1 = bitcast i8* %0 to [10 x i32]*
%2 = getelementptr inbounds [10 x i32], [10 x i32]* %1, i32 0, i32 0
store i32 1, i32* %2, align 16
%3 = getelementptr inbounds [10 x i32], [10 x i32]* %1, i32 0, i32 1
store i32 2, i32* %3, align 4
%4 = getelementptr inbounds [10 x i32], [10 x i32]* %1, i32 0, i32 2
store i32 3, i32* %4, align 8
%arrayidx = getelementptr inbounds [10 x [20 x i32]], [10 x [20 x i32]]* %arr2, i64 0, i64 2
%arrayidx1 = getelementptr inbounds [20 x i32], [20 x i32]* %arrayidx, i64 0, i64 3
store i32 1, i32* %arrayidx1, align 4
ret i32 0
}
; Function Attrs: argmemonly nounwind willreturn writeonly
declare void @llvm.memset.p0i8.i64(i8* nocapture writeonly, i8, i64, i1 immarg) #1
attributes #0 = { noinline nounwind optnone uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #1 = { argmemonly nounwind willreturn writeonly }
!llvm.module.flags = !{!0}
!llvm.ident = !{!1}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{!"clang version 11.0.0"}
示例2相比示例1多出了 getelementptr 指令和全局变量。
-
getelementptr指令解析将要进行读写操作的地址。 -
对于全局变量,每个
ExecutionState的成员变量globalObjects会保存其对应的内存对象,globalAddress将全局变量映射为对应的地址。
上述示例中:
-
%a = alloca i32, align 4,%arr = alloca [10 x i32], align 16,%arr2 = alloca [10 x [20 x i32]], align 16执行完毕后会在main的栈帧中分配3个内存对象,id分别为12,13,14。大小分别为4,40,800。地址分别为94089196921224,94089216691728,94089216566144。 -
store i32 10, i32* %a, align 4将10写入12号对象。 -
%0 = bitcast [10 x i32]* %arr to i8*和call void @llvm.memset.p0i8.i64(i8* align 16 %0, i8 0, i64 40, i1 false)初始化arr数组。 -
%2 = getelementptr inbounds [10 x i32], [10 x i32]* %1, i32 0, i32 0解析出arr[0]的地址,其偏移为0。store i32 1, i32* %2, align 16将1写入到13号对象0-3字节。 -
%3 = getelementptr inbounds [10 x i32], [10 x i32]* %1, i32 0, i32 1解析出arr[1]的地址,其偏移为4(4字节)。store i32 2, i32* %3, align 4将2写入到13号对象4-7字节。 -
%4 = getelementptr inbounds [10 x i32], [10 x i32]* %1, i32 0, i32 2解析出arr[2]的地址,偏移为8。store i32 3, i32* %4, align 8将3写入到13号对象8-11字节。 -
%arrayidx = getelementptr inbounds [10 x [20 x i32]], [10 x [20 x i32]]* %arr2, i64 0, i64 2解析出arr2[2]的基地址,其相对arr2偏移了160(2 * 4 * 20)。 -
%arrayidx1 = getelementptr inbounds [20 x i32], [20 x i32]* %arrayidx, i64 0, i64 3解析出arr2[2][3]的基地址,其相对arr2[2]偏移了12。 -
store i32 1, i32* %arrayidx1, align 4将1写入14号对象172-175字节。
3.3.示例3
前2个示例都是具体值的写入,不涉及到外部输入参数(符号输入)。
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
int main(int argc, char **argv) {
assert(argc == 2);
int a, b;
a = atoi(argv[1]);
if (a == 0)
b = 1;
else
b = 2;
b += 1;
return 0;
}
LLVM IR为
; ModuleID = 'test.c'
source_filename = "test.c"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
@.str = private unnamed_addr constant [10 x i8] c"argc == 2\00", align 1
@.str.1 = private unnamed_addr constant [7 x i8] c"test.c\00", align 1
@__PRETTY_FUNCTION__.main = private unnamed_addr constant [23 x i8] c"int main(int, char **)\00", align 1
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main(i32 %argc, i8** %argv) #0 {
entry:
%retval = alloca i32, align 4
%argc.addr = alloca i32, align 4
%argv.addr = alloca i8**, align 8
%a = alloca i32, align 4
%b = alloca i32, align 4
store i32 0, i32* %retval, align 4
store i32 %argc, i32* %argc.addr, align 4
store i8** %argv, i8*** %argv.addr, align 8
%0 = load i32, i32* %argc.addr, align 4
%cmp = icmp eq i32 %0, 2
br i1 %cmp, label %if.then, label %if.else
if.then: ; preds = %entry
br label %if.end
if.else: ; preds = %entry
call void @__assert_fail(i8* getelementptr inbounds ([10 x i8], [10 x i8]* @.str, i64 0, i64 0), i8* getelementptr inbounds ([7 x i8], [7 x i8]* @.str.1, i64 0, i64 0), i32 6, i8* getelementptr inbounds ([23 x i8], [23 x i8]* @__PRETTY_FUNCTION__.main, i64 0, i64 0)) #3
unreachable
if.end: ; preds = %if.then
%1 = load i8**, i8*** %argv.addr, align 8
%arrayidx = getelementptr inbounds i8*, i8** %1, i64 1
%2 = load i8*, i8** %arrayidx, align 8
%call = call i32 @atoi(i8* %2) #4
store i32 %call, i32* %a, align 4
%3 = load i32, i32* %a, align 4
%cmp1 = icmp eq i32 %3, 0
br i1 %cmp1, label %if.then2, label %if.else3
if.then2: ; preds = %if.end
store i32 1, i32* %b, align 4
br label %if.end4
if.else3: ; preds = %if.end
store i32 2, i32* %b, align 4
br label %if.end4
if.end4: ; preds = %if.else3, %if.then2
%4 = load i32, i32* %b, align 4
%add = add nsw i32 %4, 1
store i32 %add, i32* %b, align 4
ret i32 0
}
; Function Attrs: noreturn nounwind
declare dso_local void @__assert_fail(i8*, i8*, i32, i8*) #1
; Function Attrs: nounwind readonly
declare dso_local i32 @atoi(i8*) #2
attributes #0 = { noinline nounwind optnone uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #1 = { noreturn nounwind "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #2 = { nounwind readonly "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #3 = { noreturn nounwind }
attributes #4 = { nounwind readonly }
!llvm.module.flags = !{!0}
!llvm.ident = !{!1}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{!"clang version 11.0.0"}
运行参数为 --sym-args 1 1 1(最少输入1个参数,最多输入1个参数,每个参数最多1字节)。
这个示例与之前不同的地方在于 a 的值受输入影响了,在符号执行的过程中。如果 atoi 不能转化成 int 或者为空字符串,那么返回值为0。因此在 atoi 中也会发生fork,这里我们只考虑正常返回整数的状态。
-
store i32 %call, i32* %a, align 4处。写入对应内存对象的值为(Extract w32 0 (ZExt w64 (Extract w8 0 (Add w32 4294967248 (SExt w32 (Read w8 0 arg00)))))),这是1个kquery语句。翻译过来是argv[1][0] - 48(0的ascill码为48)。 -
在
br i1 %cmp1, label %if.then2, label %if.else3处%cmp1读取出来的值是(Eq 0 ( Extract w32 0 (ZExt w64 (Extract w8 0 (Add w32 4294967248 (SExt w32 (Read w8 0 arg00)))))),翻译过来是argv[1][0] - 48 == 0。
3.4.示例4
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
int main(int argc, char **argv) {
assert(argc == 4);
int a[100] = {0};
int i = atoi(argv[1]);
int j = atoi(argv[2]);
int val = atoi(argv[3]);
a[i] = val;
int k = a[j];
return 0;
}
LLVM IR为
; ModuleID = 'test.c'
source_filename = "test.c"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
@.str = private unnamed_addr constant [10 x i8] c"argc == 4\00", align 1
@.str.1 = private unnamed_addr constant [7 x i8] c"test.c\00", align 1
@__PRETTY_FUNCTION__.main = private unnamed_addr constant [23 x i8] c"int main(int, char **)\00", align 1
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main(i32 %argc, i8** %argv) #0 {
entry:
%retval = alloca i32, align 4
%argc.addr = alloca i32, align 4
%argv.addr = alloca i8**, align 8
%a = alloca [100 x i32], align 16
%i = alloca i32, align 4
%j = alloca i32, align 4
%val = alloca i32, align 4
%k = alloca i32, align 4
store i32 0, i32* %retval, align 4
store i32 %argc, i32* %argc.addr, align 4
store i8** %argv, i8*** %argv.addr, align 8
%0 = load i32, i32* %argc.addr, align 4
%cmp = icmp eq i32 %0, 4
br i1 %cmp, label %if.then, label %if.else
if.then: ; preds = %entry
br label %if.end
if.else: ; preds = %entry
call void @__assert_fail(i8* getelementptr inbounds ([10 x i8], [10 x i8]* @.str, i64 0, i64 0), i8* getelementptr inbounds ([7 x i8], [7 x i8]* @.str.1, i64 0, i64 0), i32 6, i8* getelementptr inbounds ([23 x i8], [23 x i8]* @__PRETTY_FUNCTION__.main, i64 0, i64 0)) #4
unreachable
if.end: ; preds = %if.then
%1 = bitcast [100 x i32]* %a to i8*
call void @llvm.memset.p0i8.i64(i8* align 16 %1, i8 0, i64 400, i1 false)
%2 = load i8**, i8*** %argv.addr, align 8
%arrayidx = getelementptr inbounds i8*, i8** %2, i64 1
%3 = load i8*, i8** %arrayidx, align 8
%call = call i32 @atoi(i8* %3) #5
store i32 %call, i32* %i, align 4
%4 = load i8**, i8*** %argv.addr, align 8
%arrayidx1 = getelementptr inbounds i8*, i8** %4, i64 2
%5 = load i8*, i8** %arrayidx1, align 8
%call2 = call i32 @atoi(i8* %5) #5
store i32 %call2, i32* %j, align 4
%6 = load i8**, i8*** %argv.addr, align 8
%arrayidx3 = getelementptr inbounds i8*, i8** %6, i64 3
%7 = load i8*, i8** %arrayidx3, align 8
%call4 = call i32 @atoi(i8* %7) #5
store i32 %call4, i32* %val, align 4
%8 = load i32, i32* %val, align 4
%9 = load i32, i32* %i, align 4
%idxprom = sext i32 %9 to i64
%arrayidx5 = getelementptr inbounds [100 x i32], [100 x i32]* %a, i64 0, i64 %idxprom
store i32 %8, i32* %arrayidx5, align 4
%10 = load i32, i32* %j, align 4
%idxprom6 = sext i32 %10 to i64
%arrayidx7 = getelementptr inbounds [100 x i32], [100 x i32]* %a, i64 0, i64 %idxprom6
%11 = load i32, i32* %arrayidx7, align 4
store i32 %11, i32* %k, align 4
ret i32 0
}
; Function Attrs: noreturn nounwind
declare dso_local void @__assert_fail(i8*, i8*, i32, i8*) #1
; Function Attrs: argmemonly nounwind willreturn writeonly
declare void @llvm.memset.p0i8.i64(i8* nocapture writeonly, i8, i64, i1 immarg) #2
; Function Attrs: nounwind readonly
declare dso_local i32 @atoi(i8*) #3
attributes #0 = { noinline nounwind optnone uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #1 = { noreturn nounwind "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #2 = { argmemonly nounwind willreturn writeonly }
attributes #3 = { nounwind readonly "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #4 = { noreturn nounwind }
attributes #5 = { nounwind readonly }
!llvm.module.flags = !{!0}
!llvm.ident = !{!1}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{!"clang version 11.0.0"}
klee运行的参数为 --sym-args 3 3 1 (即输入最少3个参数,最多3个参数,每个参数1字节)。
需要说明的是这里面 atoi 会涉及到2种数值计算方式,其中 i 为单个ascii码字符:
-
atoi(i) = i - 48,字符0-9对应编码48-57。 -
atoi(i) = (i | 32) - 87,字符a-f对应编码97-102,A-F对应编码65-70,这种计算方式将a-f, A-F映射为10-15。
同时klee中的符号表达式都是kquery语句,关于kquery语法可参考klee tutorial,这里由于 atoi 中对应很多情况,所以会fork很多状态,在其中一个状态:
-
通过
%arrayidx5 = getelementptr inbounds [100 x i32], [100 x i32]* %a, i64 0, i64 %idxprom加载a[i]时处理的地址为(Add w64 94052992415840 (Mul w64 4 (SExt w64 (Extract w32 0 (ZExt w64 (Extract w8 0 (Add w32 4294967209 (Or w32 (SExt w32 (Read w8 0 arg00)) 32))))))))。翻译过来就是94052992415840 + 4 * atoi(argv[1][0]),94052992415840为a的基地址。 -
此时如果
val被atoi成功赋值,那么store i32 %9, i32* %arrayidx5, align 4写入的值是(Extract w32 0 (ZExt w64 (Extract w8 0 (Add w32 4294967248 (SExt w32 (Read w8 0 arg02)))))),表示atoi(argv[3][0])。 -
通过
%arrayidx7 = getelementptr inbounds [100 x i32], [100 x i32]* %a, i64 0, i64 %idxprom6获取的地址为(Add w64 94052992415840 (Mul w64 4 (SExt w64 (Extract w32 0 (ZExt w64 (Extract w8 0 (Add w32 4294967209 (Or w32 (SExt w32 (Read w8 0 arg01)) 32)))))))),即94052992415840 + 4 * atoi(argv[2][0])。 -
在之后
%11 = load i32, i32* %arrayidx7, align 4读取a[j]的值的kquery表达式简化后为(ReadLSB w32 N0 U0:[(Add w32 3 N1)=(Extract w8 24 N2),(Add w32 2 N1)=(Extract w8 16 N2),(Add w32 1 N1)=(Extract w8 8 N2),N1=(Extract w8 0 N2)] @ const_arr169),这个表达式的值有点复杂,其中:-
N0:(Extract w32 0 (Mul w64 4 (SExt w64 (Extract w32 0 (ZExt w64 (Extract w8 0 (Add w32 4294967209 (Or w32 (SExt w32 (Read w8 0 arg01)) 32))))))))表示4 * atoi(argv[2][0]),也就是a[j]相对a的偏移。 -
N1:(Extract w32 0 (Mul w64 4 (SExt w64 (Extract w32 0 (ZExt w64 (Extract w8 0 (Add w32 4294967209 (Or w32 (SExt w32 (Read w8 0 arg00)) 32)))))))))表示4 * atoi(argv[1][0]),也就是a[i]相对a的偏移。 -
N2:(Extract w32 0 (ZExt w64 (Extract w8 0 (Add w32 4294967209 (Or w32 (SExt w32 (Read w8 0 arg02)) 32)))))),表示atoi(argv[3][0]),也就是val的值。 -
整个kquery表达式的意思就是在
N1(*(a+i))开始的4个字节被N2(val)进行赋值的情况下,读取N0(*(a+j))开始的4个字节的值。
-
打印出每个Memory Object的值,其中一个状态下为:
%retval = alloca i32, align 4的值为(value为0)
MemoryObject ID: 6898
Root Object: 0x0
Size: 4
Bytes:
[0] concrete? 1 known-sym? 0 unflushed? 1 = 0 # concrete表示该byte是否是确定值,known-sym表示该byte是否确定是符号值,= 号后面为该byte的值。
[1] concrete? 1 known-sym? 0 unflushed? 1 = 0
[2] concrete? 1 known-sym? 0 unflushed? 1 = 0
[3] concrete? 1 known-sym? 0 unflushed? 1 = 0
%argc.addr = alloca i32, align 4的值为(value为4,即参数数量,我设置输入3个符号参数)
MemoryObject ID: 6899
Root Object: 0x0
Size: 4
Bytes:
[0] concrete? 1 known-sym? 0 unflushed? 1 = 4
[1] concrete? 1 known-sym? 0 unflushed? 1 = 0
[2] concrete? 1 known-sym? 0 unflushed? 1 = 0
[3] concrete? 1 known-sym? 0 unflushed? 1 = 0
%argv.addr = alloca i8**, align 8(value为argv基地址,该地址的值为确定值)
MemoryObject ID: 6900
Root Object: 0x0
Size: 8
Bytes:
[0] concrete? 1 known-sym? 0 unflushed? 1 = 16
[1] concrete? 1 known-sym? 0 unflushed? 1 = 72
[2] concrete? 1 known-sym? 0 unflushed? 1 = 220
[3] concrete? 1 known-sym? 0 unflushed? 1 = 250
[4] concrete? 1 known-sym? 0 unflushed? 1 = 198
[5] concrete? 1 known-sym? 0 unflushed? 1 = 85
[6] concrete? 1 known-sym? 0 unflushed? 1 = 0
[7] concrete? 1 known-sym? 0 unflushed? 1 = 0
%a = alloca [100 x i32], align 16的值有些特殊,因为a[i]可以写入任意一个地址。打印出的值如下,其中每一个byte[i]的表达式为(ReadLSB w32 i [(Add w32 3 N1)=(Extract w8 24 N2),(Add w32 2 N1)=(Extract w8 16 N2),(Add w32 1 N1)=(Extract w8 8 N2),N1=(Extract w8 0 N2)] @ const_arr169)。
MemoryObject ID: 6901
Root Object: 0x55c6f94d6500
Size: 400
Bytes:
[0] concrete? 0 known-sym? 0 unflushed? 0 = (ReadLSB w32 0 xxx)
[1] concrete? 0 known-sym? 0 unflushed? 0 = (ReadLSB w32 1 xxx)
xxx
Updates:
[(Add w32 3 N1)] = (Extract w8 24 N2)
[(Add w32 2 N1)] = (Extract w8 16 N2)
[(Add w32 1 N1)] = (Extract w8 8 N2)
[N1] = (Extract w8 0 N2)
%i = alloca i32, align 4
MemoryObject ID: 6902
Root Object: 0x0
Size: 4
Bytes:
[0] concrete? 0 known-sym? 1 unflushed? 1 = N0_0 # 简化表示,kquery表达式太占空间了,这里_0表示第0-第7字节组成的值
[1] concrete? 0 known-sym? 1 unflushed? 1 = N0_8
[2] concrete? 0 known-sym? 1 unflushed? 1 = N0_16
[3] concrete? 0 known-sym? 1 unflushed? 1 = N0_24
%j 的值和 %i 类似,%k 的值在前面已经dump过了。总之,收到符号输入影响的变量其值对应的kqeury表达式都会包含 arg。