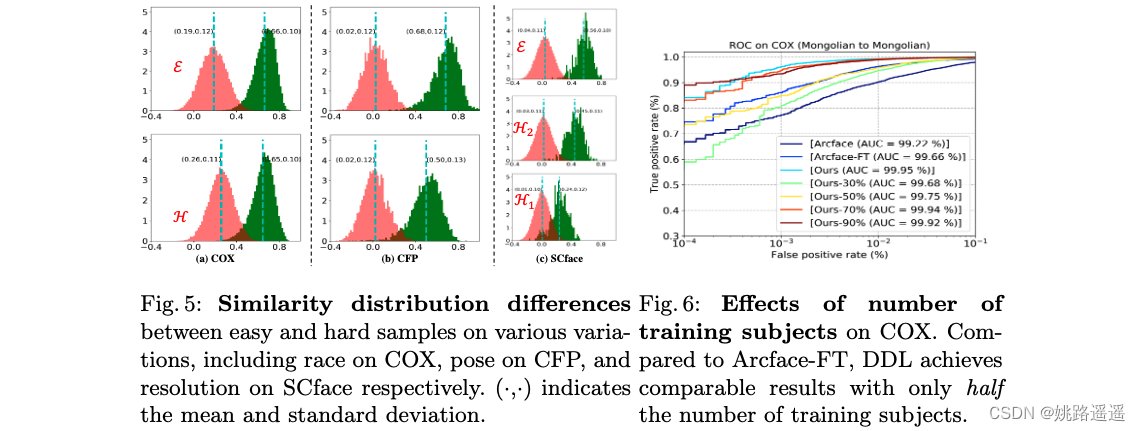
人生苦短,我用python
首先,我和大家一样喜欢看小姐姐~
其次,看美丽的事物会让人更加有动力去…
我编不下去了哈哈哈,我就是爱看充满美感的人儿~
更多python好看的:点击此处跳转文末名片获取

环境
- Python
- pycharm
模块使用
第三方模块
- requests
内置模块
- re
- json

如何安装python第三方模块:
-
win + R 输入 cmd 点击确定,
输入安装命令 pip install 模块名 (pip install requests) 回车 -
在pycharm中点击Terminal(终端) 输入安装命令
代码实现步骤: <基本四大步骤>
-
发送请求, 对于视频播放详情页url地址发送请求
-
获取数据, 获取网页源代码 <获取服务器返回response响应数据>
-
解析数据, 提取我们想要数据内容 <m3u8文件>
-
发送请求, 对于m3u8文件url发送请求
-
获取数据, 获取服务器返回response响应数据
-
解析数据, 提取所有ts文件内容 <视频片段url>
-
保存数据, 保存视频内容到本地
-
多个视频采集
-
多页数据采集
-
根据关键词视频下载
-
根据关键词视频下载

代码展示
更多python好看的:点击此处跳转文末名片获取
import time
import requests
import re
import json
import pprint
for page in range(3, 29):
print(f'正在采集第{page}页的数据')
time.sleep(1)
link = 'https://www.****.cn/u/29946310'
data = {
'quickViewId': 'ac-space-video-list',
'reqID': page+1,
'ajaxpipe': '1',
'type': 'video',
'order': 'newest',
'page': page,
'pageSize': '20',
't': '1653659024877',
}
headers = {
'referer': 'https://***/u/29946310',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36'
}
response = requests.get(url=link, params=data, headers=headers)
ac_id_list = re.findall('atomid.*?:.*?"(\d+).*?"', response.text)
print(ac_id_list)
for ac_id in ac_id_list:
url = f'https://***/v/ac{ac_id}'
headers = {
'referer': f'https://***/u/{ac_id}',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
title = re.findall('<title >(.*?) - 弹幕视频网 - 认真你就输啦 \(\?ω\?\)ノ- \( ゜- ゜\)つロ</title>', response.text)[0]
html_data = re.findall('window.pageInfo = window.videoInfo = (.*?);', response.text)[0]
json_data = json.loads(html_data)
m3u8_url = json.loads(json_data['currentVideoInfo']['ksPlayJson'])['adaptationSet'][0]['representation'][0]['backupUrl'][0]
m3u8_data = requests.get(url=m3u8_url, headers=headers).text
m3u8_data = re.sub('#E.*', '', m3u8_data).split()
print(title)
print(m3u8_url)
最后
人生中,很多东西在得到的同时,其实也在失去。
小时候,渴望长大,但长大后却发现遗失了童年;
长大后,渴望甜蜜,但走进围城后往往怀念曾经的自由;
生命的旅途,风景无限,但心再也回不到最初。
不如现在学习,补充自己。