hive有大量内置函数,大致可分为:单行函数、聚合函数、炸裂函数、窗口函数。
查看内置函数
show functions;
查看内置函数用法
desc function upper;
查看内置函数详细信息
desc function extended upper;
一、单行函数
单行函数的特点是一进一出,输入一行,输出一行。
1.1 算数运算函数
运算符 | 描述 |
A+B | |
A-B | |
A*B | |
A/B | |
A%B | 取余 |
A&B | 按位取与 |
A|B | 按位取或 |
A^B | 按位取异或 |
~A | 按位取饭 |
1.2 数值函数
round:(可指定精度)四舍五入
select round(3.1415, 2); // 3.14
ceil / ceiling:向上取整
select ceil(3.1415, 2); // 4
floor:向下取整
select floor(3.1415, 2); // 3
cast:类型转换
语法: cast(expr as <type>)
select cast(1 as bigint)
1
1.3 字符串函数
length:字符串长度
select length('abcdefg'); // 7
reverse:字符串反转
语法: reverse(string A)
select length('abcdefg'); // gfedcba
concat:字符串连接
语法: concat(string A, string B…)
select concat('abc','def') // abcdef
concat_ws:带分隔符的字符串连接
语法: concat_ws(string SEP, string A, string B…)
select concat_ws('-','abc','def') // abc-def
substr / substring:字符串截取
语法:substr(string A, int start) | substring(string A, int start)
语法:substr(string A, int start, int len) | substring(string A, int start, int len)
# 从第二个字符串开始截取
select substr('abcdefg',2); // bcdefg
# 从倒数第二个字符串开始截取
select substr('abcdefg',-2); // fg
select substr('abcde',3,2) // cd
select substr('abcde',3,-2) // de
upper / ucase:字符串转大写
语法: upper(string A) | ucase(string A)
select upper('abcd') //ABCD
select ucase('abcd') //ABCD
lower / lcase:字符串转小写
语法: lower(string A) | lcase(string A)
select lower('ABCD') // abcd
select lcase('ABCD') // abcd
trim / ltrim / rtrim:取出空格/左空格/右空格
语法:trim(string A) / ltrim(string A) / rtrim(string A)
select trim(' abcd ') // 'abcd'
space:空格字符串函数
语法: space(int n)
select length(space(10));
10
repeat:重复字符串函数
语法: repeat(string str, int n)
select repeat('abc',5);
abcabcabcabcabc
lpad / rpad:左/右补足函数
语法: lpad(string str, int len, string pad) / rpad(string str, int len, string pad)
select lpad('abc',10,'td')
tdtdtdtabc
select rpad('abc',10,'td')
abctdtdtdt
split:分割字符串
语法: split(string str, string pat)
select split('abtcdtef','t')
["ab","cd","ef"]
replace:替换字符串
语法: replace(string str, string b, string c)
select replace('hadoop','o','O')
hadOOp
regexp_replace:正则替换
语法:regexp_replace(string A, string B, string C)
select regexp_replace('foobar', 'oo|ar', '+'); // 将oo和ar转换成+
f+b+
select regexp_replace('abc-123-abcd', '[0-9]+', '*');
select regexp_replace('abc-123-abcd', '[0-9]{1,}', '*');
select regexp_replace('abc-123-abcd', '\\d+', '*');
abc-*-abcd
regexp:正则匹配(功能与like类似)
语法: A REGEXP B
select 'footbar' REGEXP '^f.*r$';
1
instr:查询字符串起始下标
语法:instr(str, substr)
select instr('helloworld','world');
6
locate:返回第一个字符串在第二个字符串中的位置,可设置查询的起始下标
语法:locate(substr, str[, pos])
select locate('00','11002233')
3
select locate('00','11002233',3)
3
select locate('00','11002233',5)
0
json_tuple:类似于get_json_object
但它需要多个名称并返回一个元组。所有输入参数和输出列类型都是字符串。
语法:json_tuple(jsonStr, p1, p2, ..., pn)
select json_tuple('{"name":"zs","age":18,"address":"安德门"}','name','age','address')
zs,18,安德门
get_json_object:从路径中提取json对象
语法:get_json_object(json_txt, path)
select get_json_object('{"name":"zs","age":18,"address":"安德门"}','$.name') as name
zs
1.4 日期函数
unix_timestamp:获取当前 UNIX 时间戳函数
语法: unix_timestamp()
语法:unix_timestamp(string date)
select unix_timestamp()
1677138547
select unix_timestamp('2023/02/23 08-08-08','yyyy/MM/dd HH-mm-ss')
1677139688
from_unixtime:转化unix时间戳到当前市区的时间
语法:from_unixtime(bigint unixtime)
select from_unixtime(1677138547)
2023-02-23 07:49:07
current_date:当前日期
select current_date();
2023-02-23
current_timestamp:当前日期加时间,精确到毫秒
select current_timestamp();
2023-02-23 16:06:24.504000000
year:日期转年
month:日期转月
day:日期转天
hour:日期转小时
minute:日期转分钟
second:日期转秒
datediff:日期比较
语法: datediff(string enddate, string startdate)
select datediff('2012-12-08','2012-05-09');
213
date_add / date_sub:日期增加/日期减少
语法: date_add(string startdate, int days)
语法: date_sub (string startdate, int days)
select date_add('2012-12-08',10);
2012-12-18
select date_sub('2012-12-08',10);
2012-11-28
1.5 流程控制函数
case when:条件判断
语法: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
说明:如果 a 等于 b,那么返回 c;如果 a 等于 d,那么返回 e;否则返回 f
Select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end
mary
Select case 200 when 50 then 'tom' when 100 then 'mary' else 'tim' en
tim
if:条件判断,类似Java中的三目运算符
语法: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
select if(1=2,100,200);
200
1.6 集合函数
size:集合中元素的个数
# 返回每一行数据中friends集合中的个数
select size() from test;
map:创建map集合
map_keys:返回map中的key
select map_keys( map(1,'a',2,'b',3,'c'))
[1,2,3]
map_values:返回map中的value
select map_values( map(1,'a',2,'b',3,'c'))
["a","b","c"]
使用炸裂函数将map集合分成两列。
需要注意的是,explode可以使用array数组和map,但posexplode中只能添加数组,不能使用map
select explode( map(1,'a',2,'b',3,'c'))
1,a
2,b
3,c
array_contains:判断array中是否包含某个元素
sort_array:将array中的元素排序
stack:将元素转换成n行
语法:stack(n, cols...)
二、聚合函数
collect_list:收集并形成list集合,结果不去重
select id, collect_list(likes) from student group by id;
元数据:

处理后:
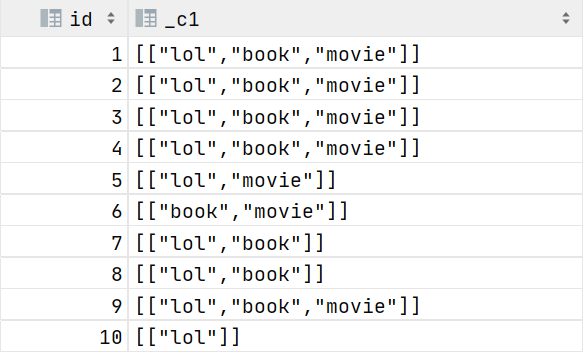
collect_set:收集并形成set集合,结果去重
select collect_set(likes) from student group by address;

三、炸裂函数
UDTF(Table-Generating Function)定义:接收一行数据,输出一行或多行数据。
常用UDTF——explode(array<T> a)
语法:
select explode( array("a", "b", "c") ) as items;
a
b
c
功能:
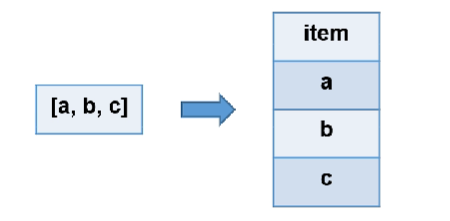
常用UDTF——posexplode(array<T> a)
语法:
select posexplode( array("a", "b", "c") ) as (pos, items);
0,a
1,b
2,c
功能:

常用UDTF——inline(array<struct<f1:T1,...,fn:Tn>> a)
语法:
select inline( array(named_struct("id",1,"name","zs"),
named_struct("id",2,"name","ls"),
named_struct("id",3,"name","ww") ) ) as (id,name);
1,zs
2,ls
3,ww
功能:

lateral view
定义:lateral view通常与UDTF配合使用。lateral view可以将UDTF应用到源表的每行数据,将每行数据转换为一行或多行,并将源表中每行的输出结果与该行连接起来,形成一个虚拟表。
功能:
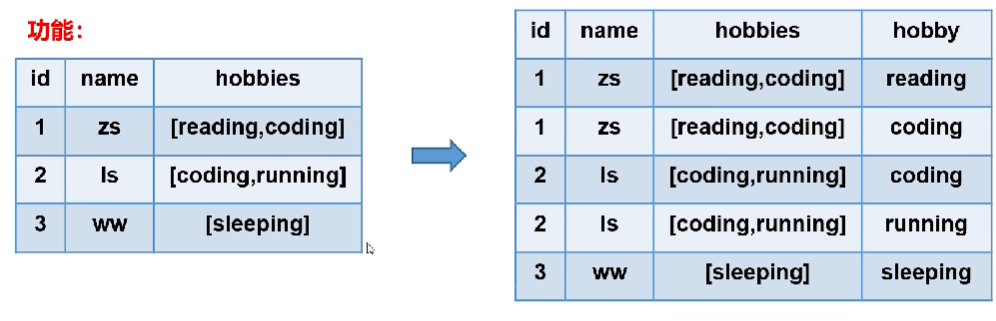

使用炸裂函数explode之后,数据由4行变成5行

语法:
select
name,work_place,view1,gender_age
from employee
lateral view explode(work_place) tmp as view1

select
name,work_place,view1,skills_score,skill,score
from employee
lateral view explode(work_place) w as view1
lateral view explode(skills_score) w as skill,score

案例演示
建表语句:
create table movie_info(
movie string,
category string
)
row format delimited fields terminated by '\t';装载语句:
insert into table movie_info
values
("《疑犯追踪》","悬疑,动作,科幻,剧情"),
("《lie》","悬疑,警匪,动作,心理,剧情"),
("《战狼2》","战争,动作,灾难");需求说明1:根据上述电影信息报,统计各分类的电影数量。
查看元数据:
select * from movie_info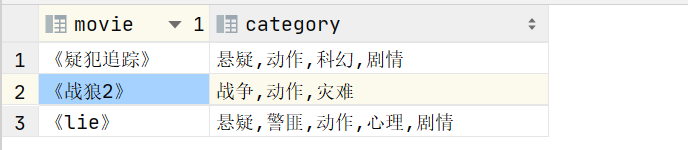
step1:将category数据转换为list集合
select
movie,
split(category,',') as type
from movie_info
step2:将转换后的集合拆分成多行,使用炸裂函数。此时的数据有重复
select
explode(split(category,',')) as type
from movie_info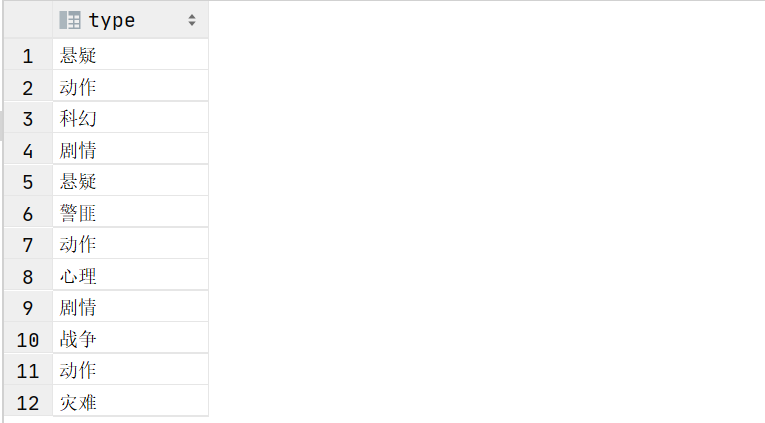
step3:CTAS建表,按type分组并求和
with t1 as (
select explode(split(category,',')) as type from movie_info
)
select type,count(1) count from t1 group by type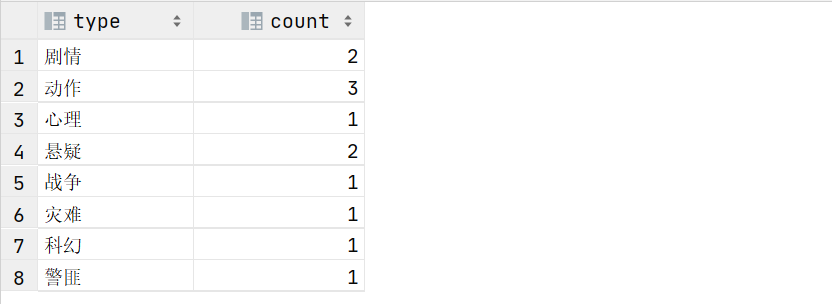
四、窗口函数
聚合函数
定义:窗口函数能为每行数据划分一个窗口,然后对窗口范围内的数据进行计算,最后将计算结果返回给该行数据。
语法:窗口函数的语法中主要包括“窗口”和“函数”两部分。其中“窗口”用于定义计算范围,“函数”用于定义计算逻辑。
select
order_id,
order_date,
amount,
函数(amount) over (窗口范围) total_amount
from order_info;
语法——函数
绝大多数的聚合函数都可以配合窗口函数使用。如min(),max(),sum(),count(),avg()等。
窗口范围的定义分为两种类型,一种是基于行的,一种是基于值的。
基于行


基于行排序,sum求和按照行数进行相加。
基于值
在基于值的窗口函数中,order by的作用不是排序,而是基于哪个字段的值划分窗口。
[num] preceding和[num] following指的是在当前值的基础上进行加减。所以此时字段必须是整数类型。

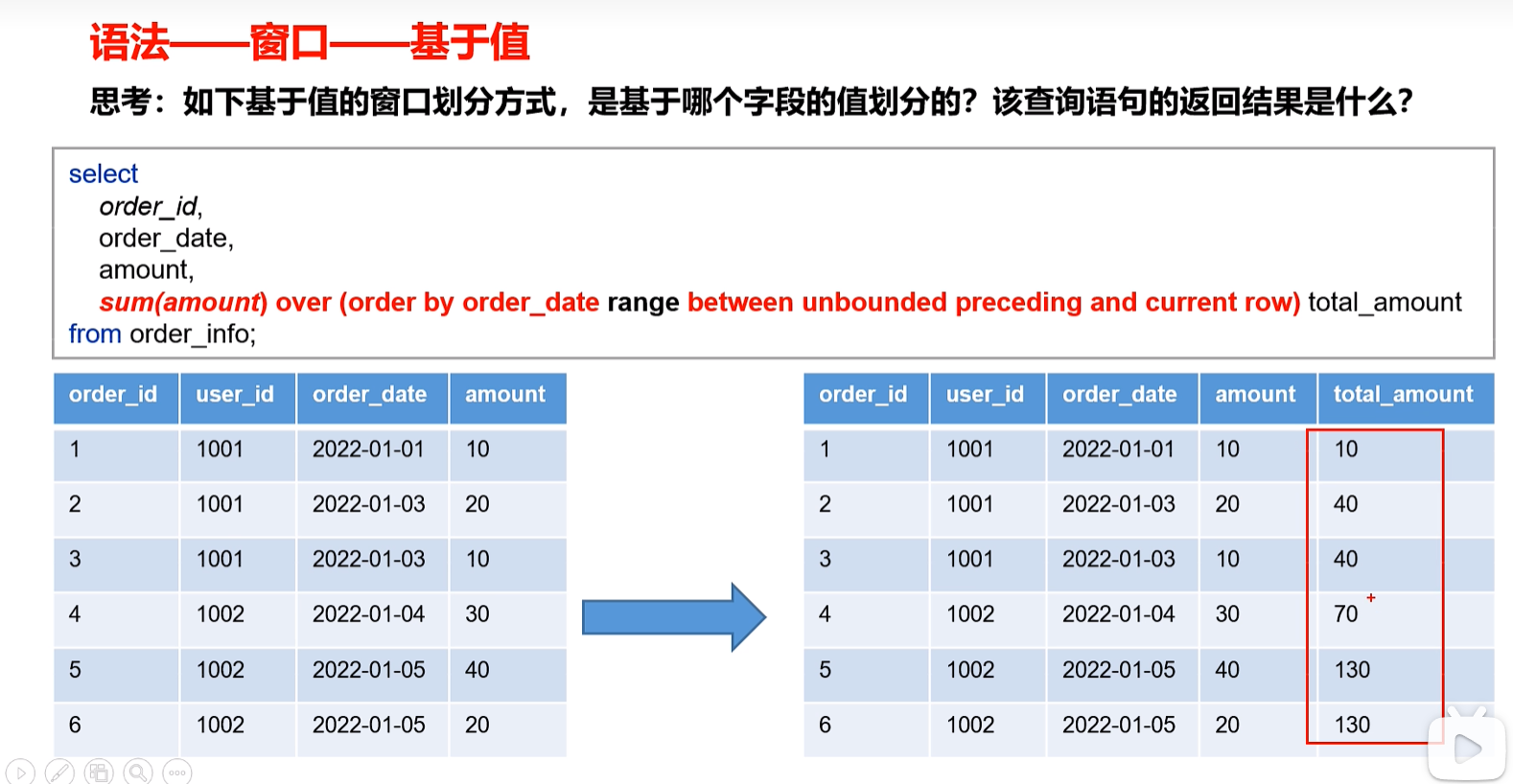
基于值排序,相同的order_date值作为一条数据进行相加。
语法——窗口——分区
定义窗口范围时,可以指定分区字段,每个分区单独划分窗口。
select
order_id,
order date.
amount,
sum(amount) over (partition by user id order by order date rows between unbounded preceding and current row tota amount)
from order info;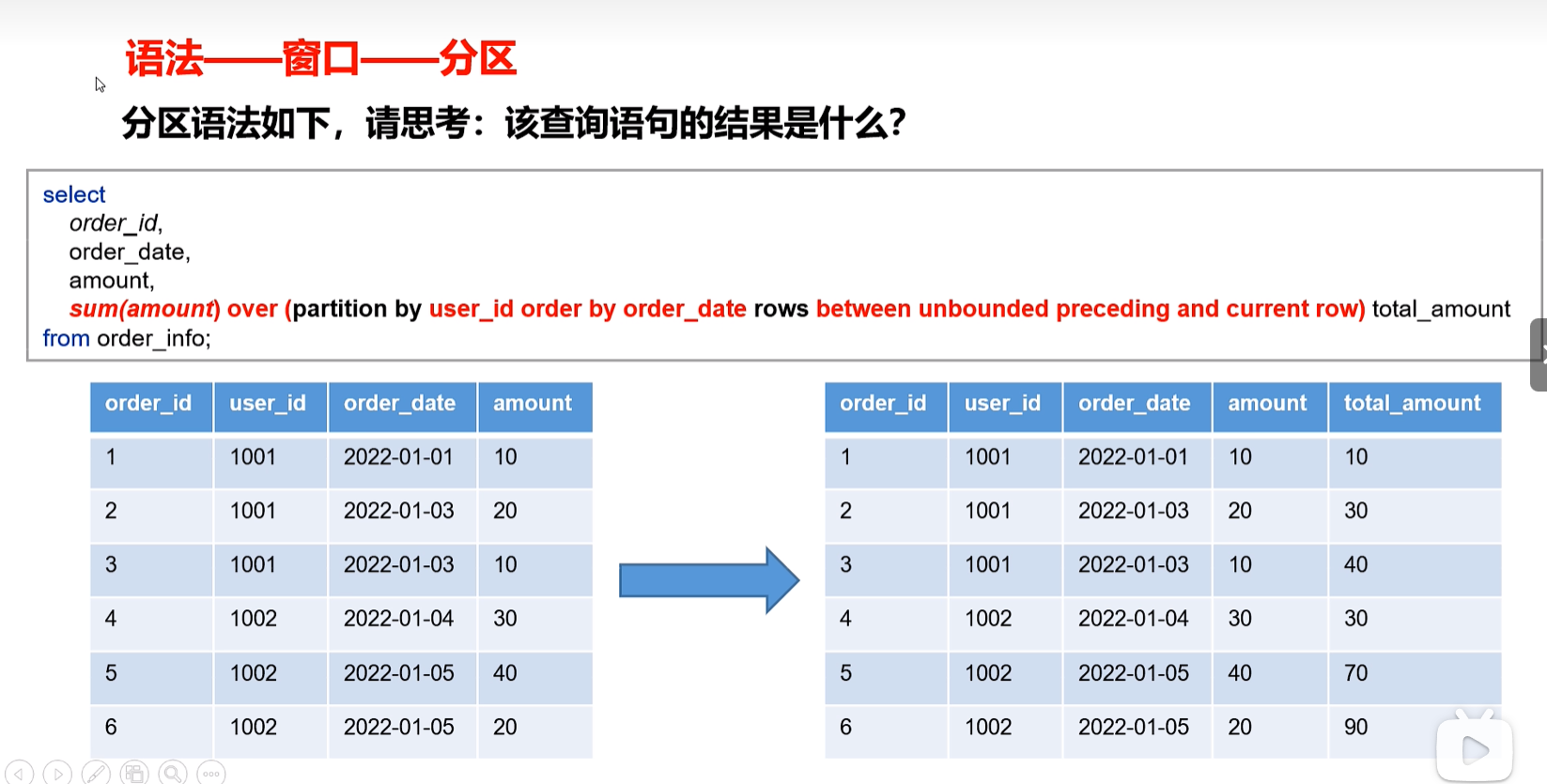
语法——窗口——缺省
over()中的三部分内容partition by、order by、(rows l range) between ... and均可省略不写。
partition by省略不写,表示不分区
order by 省略不写,表示不排序
(rows range) between ... and ... 省略不写,则使用其默认值,默认值如下若over()中包含order by,则默认值为range between unbounded preceding and current row若over()中不包含order by,则默认值为rows between unbounded preceding and unbounded following
跨行取值函数
lead和leg
功能:获取当前行的上/下边某行、某个字段的值。
select
order_id,
user id.
order_date
amount,
lag(order date,1, "1970-01-017 over (partition by user id order by order date) last date,
lead(order_date,1, 9999-12-31 over (partiion by user id order by order_date) next_date
from order info: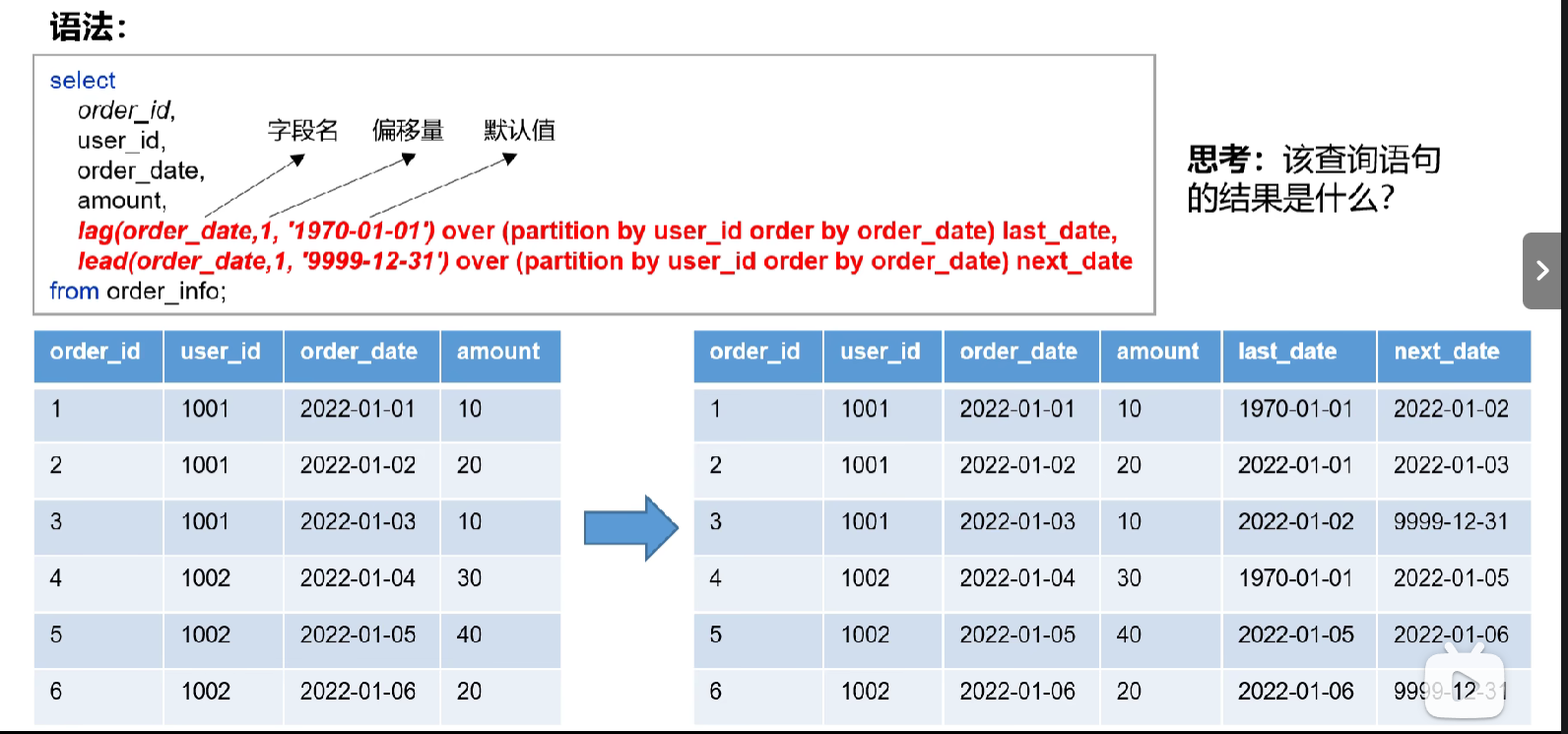
select nams,orderdate,cost
,lag(orderdate,1) over (partition by nams order by orderdate) as row1
,lag(orderdate,2) over (partition by nams order by orderdate) as row2
,lag(orderdate,1,'1900-01-01') over (partition by nams order by orderdate) as row3
,lead(orderdate,1) over (partition by nams order by orderdate) as row4
,lead(orderdate,2) over (partition by nams order by orderdate) as row5
,lead(orderdate,2,'9999-12-30') over (partition by nams order by orderdate) as row6
from t_window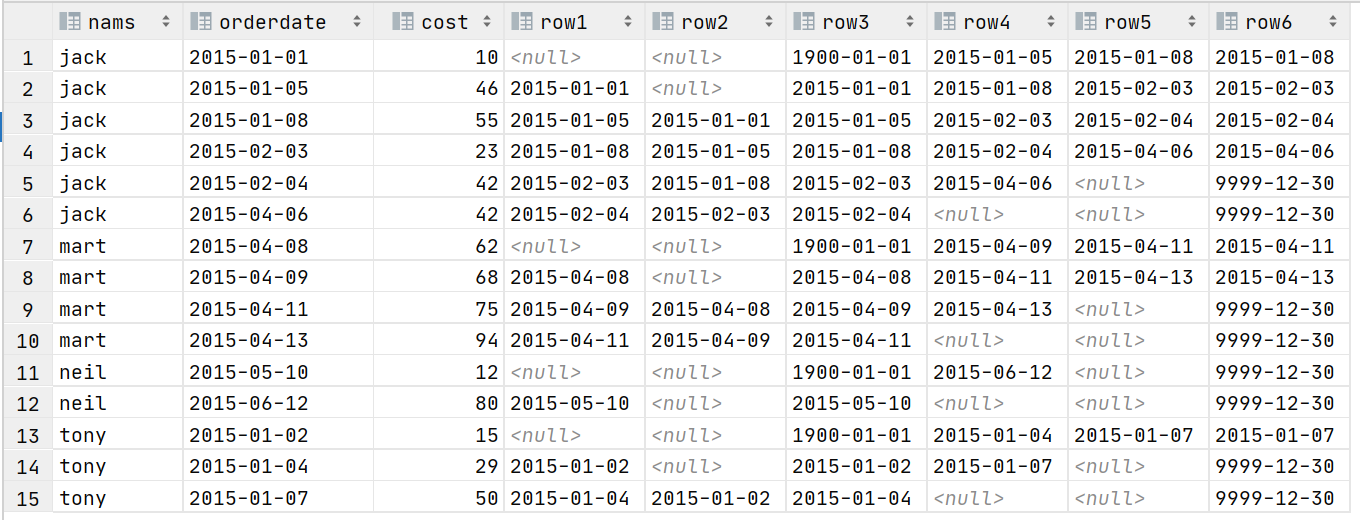
注:lag和lead函数不支持自定义窗口。
first_value和last_value
功能:获取窗口内某一列的第一个值/最后一个值
语法:
select nams,orderdate,cost
,first_value(orderdate) over (partition by nams order by orderdate) as row1
,last_value(orderdate) over (partition by nams order by orderdate) as row2
,max(cost) over (partition by nams order by orderdate) as maxcost
from t_window
排名函数rank、dense_rank、row_number
功能:计算排名
语法:

select nams,orderdate,cost
,row_number() over (partition by nams order by cost desc) as row1
,rank() over (partition by nams order by cost desc) as row2
,dense_rank() over (partition by nams order by cost desc) row3
from t_window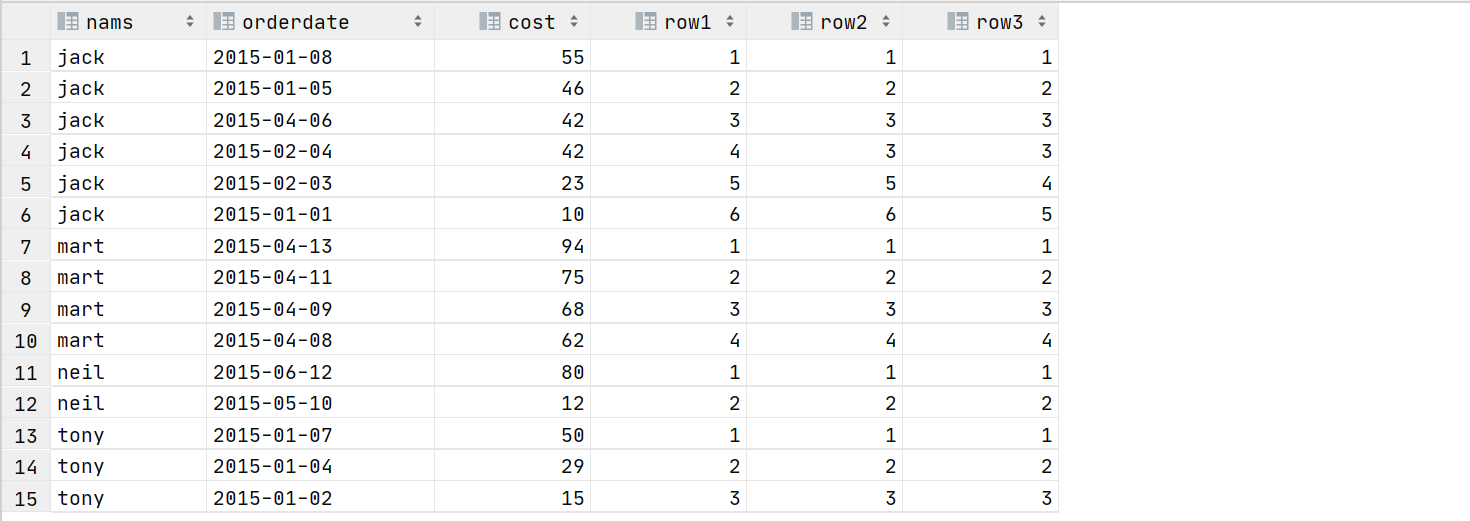
注:排名函数不支持自定义窗口。
案例演示
表结构:

建表语句:
create table order_info(
order_id string,
user_id string,
user_name string,
order_date string,
order_amount int
)装载语句:
insert overwrite table order_info
values ('1','1001','小元','2022-01-01','10'),
('2','1002','小海','2022-01-02','15'),
('3','1001','小元','2022-02-03','23'),
('4','1002','小海','2022-01-04','29'),
('5','1001','小元','2022-01-05','46'),
('6','1001','小元','2022-04-06','42'),
('7','1002','小海','2022-01-07','50'),
('8','1001','小元','2022-01-07','50'),
('9','1003','小辉','2022-04-08','62'),
('10','1003','小辉','2022-04-09','62'),
('11','1004','小猛','2022-05-10','12'),
('12','1003','小辉','2022-04-11','75'),
('13','1004','小猛','2022-06-12','80'),
('14','1003','小辉','2022-04-13','94')需求说明1:统计每个用户截至每次下单的累积下单总额
期望结果
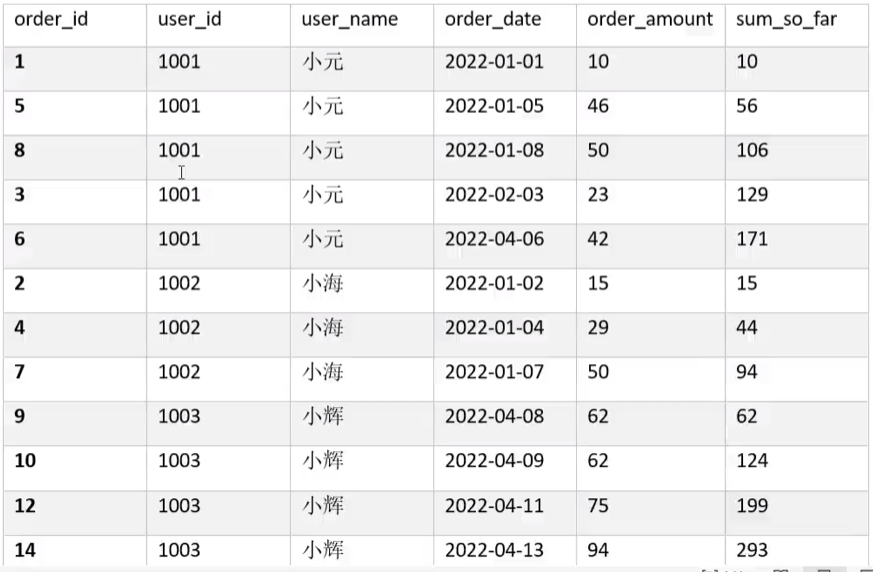
select
order_id,user_id,user_name,order_date
,order_amount
,sum(order_amount) over (partition by user_id order by order_date rows between unbounded preceding and current row )
from order_info
需求说明2:统计每个用户截至每次下单当月累积下单总额
期望结果

select
order_id,user_id,user_name,order_date
,order_amount
,sum(order_amount) over (partition by user_id,substring(order_date,1,7) order by order_date rows between unbounded preceding and current row )
from order_info;
需求说明3:统计每个用户每次下单距离上次下单相隔的天数(每次下单按0天算)
期望结果

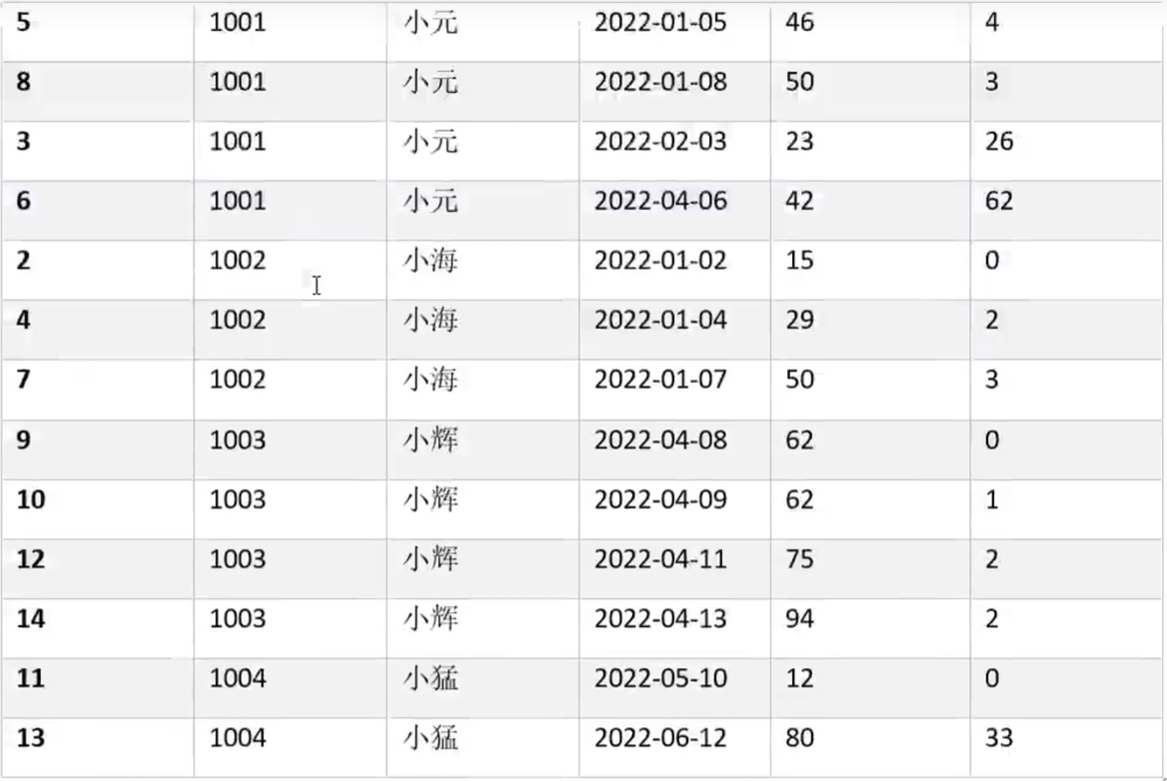
with t1 as (
select
order_id,user_id,user_name,order_date date1
,order_amount
,lag(order_date,1,order_date) over (partition by user_id order by order_date) date2
from order_info)
select order_id,user_id,user_name,date1 order_date,datediff(date1,date2) diff from t1
需求说明4:查询所有下单记录以及每个下单记录所在月份的首/末次下单日期
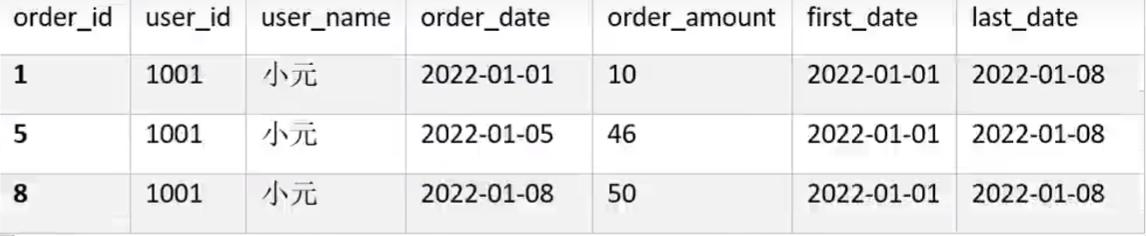
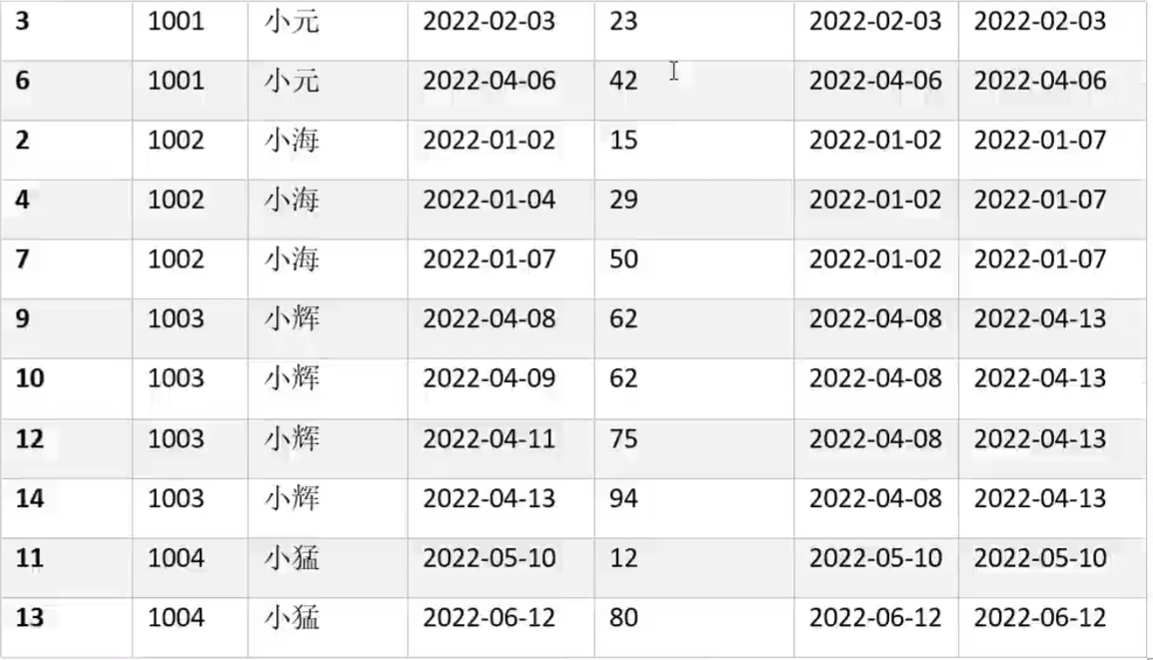
select
order_id,user_id,user_name,order_date date1
,order_amount
,first_value(order_date) over (partition by user_name,month(order_date) order by order_date) first_value
,last_value(order_date) over (partition by user_name,month(order_date) order by order_date) last_value
from order_info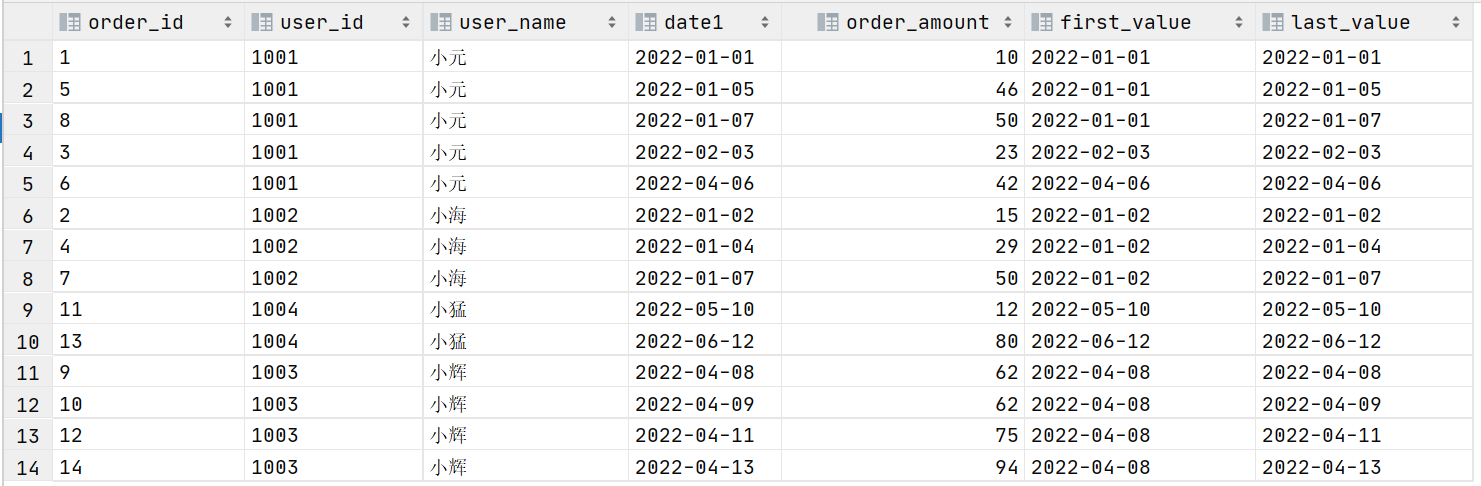
需求说明5:为每个用户的所有下单记录按照订单金额进行排名

select
order_id,user_id,user_name,order_date,order_amount
,rank() over (partition by user_id order by order_amount desc) rk
,dense_rank() over (partition by user_id order by order_amount desc) drk
,row_number() over (partition by user_id order by order_amount desc) rn
from order_info
五、自定义函数UDF
hive自带了一些函数,比如max/min等。但是数量有限,自己可以通过UDF来方便的扩展。
当hive提供的内置函数无法满足业务需求时,就可以考虑用户自定义函数UDF
根据用户自定义函数类别分为以下三种:
UDF(User-Defined-Function)
一进一出
UDAF(User-Defined Aggregation Function)
用户自定义聚合函数,多进一出
类似于:count/max/min
UDTF(User-Defined Table-Generating Function)
用户自定义表生成函数,一进多出。
如lateral view explode()
导入依赖
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.1.0</version>
</dependency>实现功能
UDF
// 将传入的字符串首字母变成大写字母
public class InitialString extends UDF {
public String evaluate(final String txt){
return txt.trim().substring(0,1).toUpperCase()+txt.trim().substring(1);
}
public static void main(String[] args) {
InitialString ls = new InitialString();
String s = ls.evaluate("hello");
System.out.println(s);
}
}// 传入字符串,根据要求进行截取
public class ThreeUDF extends UDF {
public String evalute(String line,String key){
String[] infos=line.split("\\|");
if(infos.length!=2 || StringUtils.isBlank(infos[1])){
return "";
}
if(key.equals("phone")){
return infos[0];
}else{
JSONObject obj = new JSONObject(infos[1]);
if(key.equals("name") && obj.has("name"))
return obj.getString("name");
else if(key.equals("age") && obj.has("age"))
return obj.getString("age");
else if(key.equals("address") && obj.has("address"))
return obj.getString("address");
}
return "";
}
public static void main(String[] args) {
LowerUDF.ThreeUDF threeUDF = new LowerUDF.ThreeUDF();
String phone = threeUDF.evalute("15828932432|{\"name\":\"zs\",\"age\":\"18\",\"address\":\"安德门\"}", "address");
System.out.println(phone);
}
}UDTF——行转列
public class ScoreUDTF extends GenericUDTF {
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
ArrayList<String> colName = Lists.newArrayList();
colName.add("id");
colName.add("name");
colName.add("score");
LinkedList<ObjectInspector> resType = Lists.newLinkedList();
// id的类型是int类型,name类型是string类型
resType.add(PrimitiveObjectInspectorFactory.javaIntObjectInspector);
resType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
resType.add(PrimitiveObjectInspectorFactory.javaIntObjectInspector);
// 返回内容为:列名和列的数据类型
return ObjectInspectorFactory.getStandardStructObjectInspector(colName,resType);
}
// ("1,2,3,4,5","zs,li,ww,as,zh","90,12,23,49,59")
private Object[] obj = new Object[3];
@Override
public void process(Object[] objects) throws HiveException {
if(objects == null || objects.length != 3)
return;
String[] ids = objects[0].toString().split(",");
String[] names = objects[1].toString().split(",");
String[] scores = objects[2].toString().split(",");
for (int i = 0; i < ids.length; i++) {
obj[0] = Integer.parseInt(ids[i]);
obj[1] = names[i];
obj[2] = Integer.parseInt(scores[i]);
forward(obj);
}
}
@Override
public void close() throws HiveException {
}
}输入:select scoreudtf("1,2,3","ls,za,se","90,80,77");
输出: