目录
查看服务架构图-服务分布、版本信息
1:安装包下载
2:配置环境变量
3:服务配置
(1)core-site.xml
(2)配置 hadoop-env.sh
(3)HDFS 配置文件hdfs-site.xml
(4)YARN 配置文件yarn-site.xml
(5)MapReduce 配置文件mapred-site.xml
(6)配置 workers
三:启动集群
3.1:第一次启动集群
3.2:启动 HDFS
3.3:启动 YARN
3.4:启动历史服务器
四:服务管理命令
Apache Hadoop生态-目录汇总-持续更新
系统环境:centos7
Java环境:Java8
1:安装包下载
安装包下载地址:
可以去官网下载,或者通过百度网盘,上传到服务器上
链接:https://pan.baidu.com/s/1N9LTxEK2nedHdAxGIwhzeQ?pwd=yyds
提取码:yyds
2:配置环境变量
sudo vim /etc/profile.d/hadoop.sh
export HADOOP_HOME=/usr/local/hadoop3.2.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_CLASSPATH='hadoop classpath'
立即生效
source /etc/profil3:服务配置
(1)core-site.xml
创建数据目录
mkdir -p ${HADOOP_HOME}/data
sudo vim $HADOOP_HOME/etc/hadoop/core-site.xml
<!-- 指定 hdfs NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node100:8020</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 配置该root(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!-- 配置该root(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 配置该root(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
<!-- 指定hadoop数据目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.2.2/data</value>
</property>(2)配置 hadoop-env.sh
默认情况pid存储在/tmp下,时间长了会被清掉
sudo mkdir $HADOOP_HOME/pids
sudo vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
export HADOOP_SECURE_PID_DIR=${HADOOP_HOME}/pids
export HADOOP_PID_DIR=${HADOOP_HOME}/pids
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
不指定user会遇到下面的问题,不过在后面配置了kerberos同样会解决
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.(3)HDFS 配置文件hdfs-site.xml
sudo vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<!-- nn web 端访问地址 默认9870 h2版本50070-->
<property>
<name>dfs.namenode.http-address</name>
<value>node100:9870</value>
</property>
<!-- 2nn web 端访问地址 默认9868 h2版本50090-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node100:9868</value>
</property>
<!-- 测试环境指定HDFS副本的数量1 默认3-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>(4)YARN 配置文件yarn-site.xml
这里的资源根据服务器的内存进行配置, 如果机器有6G,可以设置4G,预留一些即可
<!--yarn单个容器允许分配的最大最小内存 -->
yarn.scheduler.minimum-allocation-mb 可以设置512
yarn.scheduler.maximum-allocation-mb 可以设置4G 4096
<!-- yarn容器允许管理的物理内存大小 -->
yarn.nodemanager.resource.memory-mb 可以设置4G 4096
sudo vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<!-- 环境变量的继承 3.1x需要设置 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 指定 MR 走 shuffle 默认空 mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址 默认:0.0.0.0-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node100</value>
</property>
<!-- 设置yarn任务优先级0-5 -->
<property>
<name>yarn.cluster.max-application-priority</name>
<value>5</value>
</property>
<!-- 容器最小内存,默认 1G -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<!-- 容器最大内存,默认 8G 之前是4096 -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>6144</value>
</property>
<!-- NodeManager 使用内存数,默认 8G -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>10240</value>
</property>
<!-- 关闭yarn物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node100:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- nodemanager 的 CPU 核数,不按照硬件环境自动设定时默认是 8 个 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>8</value>
</property>
<!-- 容器最大 CPU 核数,默认 4 个,修改为 2 个 -->
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>2</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/hadoop-3.2.2/etc/hadoop:/usr/local/hadoop-3.2.2/share/hadoop/common/lib/*:/usr/local/hadoop-3.2.2/share/hadoop/common/*:/usr/local/hadoop-3.2.2/share/hadoop/hdfs:/usr/local/hadoop-3.2.2/share/hadoop/hdfs/lib/*:/usr/local/hadoop-3.2.2/share/hadoop/hdfs/*:/usr/local/hadoop-3.2.2/share/hadoop/mapreduce/lib/*:/usr/local/hadoop-3.2.2/share/hadoop/mapreduce/*:/usr/local/hadoop-3.2.2/share/hadoop/yarn:/usr/local/hadoop-3.2.2/share/hadoop/yarn/lib/*:/usr/local/hadoop-3.2.2/share/hadoop/yarn/*</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.client.thread-count</name>
<value>3</value>
</property>
</configuration>(5)MapReduce 配置文件mapred-site.xml
sudo vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--运行hdfs自带wordcount功能出现错误-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.2</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.2</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.2</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node100:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node100:19888</value>
</property>
</configuration>(6)配置 workers
该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
sudo vim workers
node100三:启动集群
3.1:第一次启动集群
需要在namenode节点执行格式化操作
(注意:格式化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找不到已往数据。
如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停止 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式化。)
[root@node100 ~]# cd $HADOOP_HOME
[root@node100 hadoop-3.2.2]# hdfs namenode -format
出现如下提示表示格式化成功
2023-02-24 06:19:16,927 INFO common.Storage: Storage directory /usr/local/hadoop-3.2.2/data/dfs/name has been successfully formatted.
2023-02-24 06:19:16,999 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop-3.2.2/data/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2023-02-24 06:19:17,305 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop-3.2.2/data/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 399 bytes saved in 0 seconds .
2023-02-24 06:19:17,335 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2023-02-24 06:19:17,350 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2023-02-24 06:19:17,351 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node100/192.168.1.100
************************************************************/3.2:启动 HDFS
[root@node100 hadoop-3.2.2]# start-dfs.sh
[root@node100 hadoop-3.2.2]# jps
3633 DataNode
3858 SecondaryNameNode
4131 Jps
3494 NameNode查看页面 hdfs集群 http://node100:9870
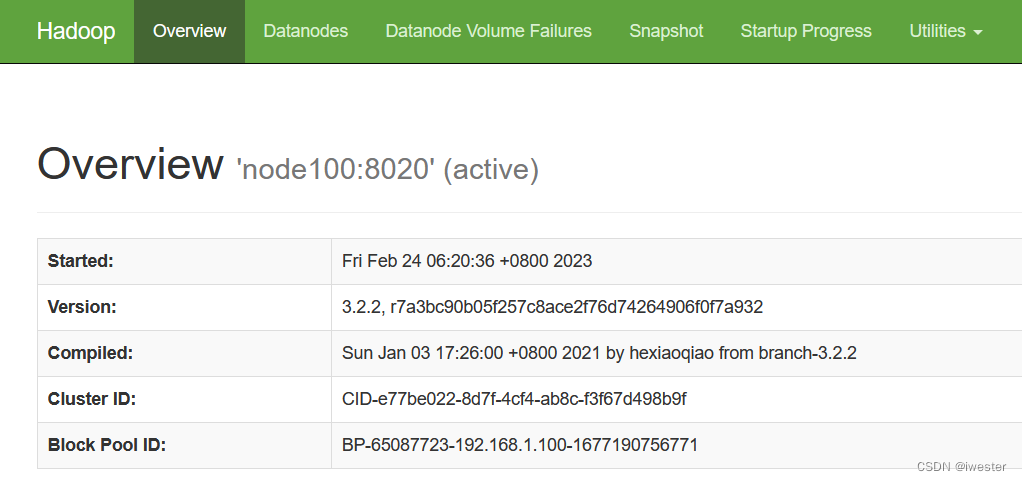
3.3:启动 YARN
[root@node100 hadoop-3.2.2]# start-yarn.sh
[root@node100 hadoop-3.2.2]# jps
多出
4322 ResourceManager
4464 NodeManager查看yarn集群 http://node100:8088/cluster
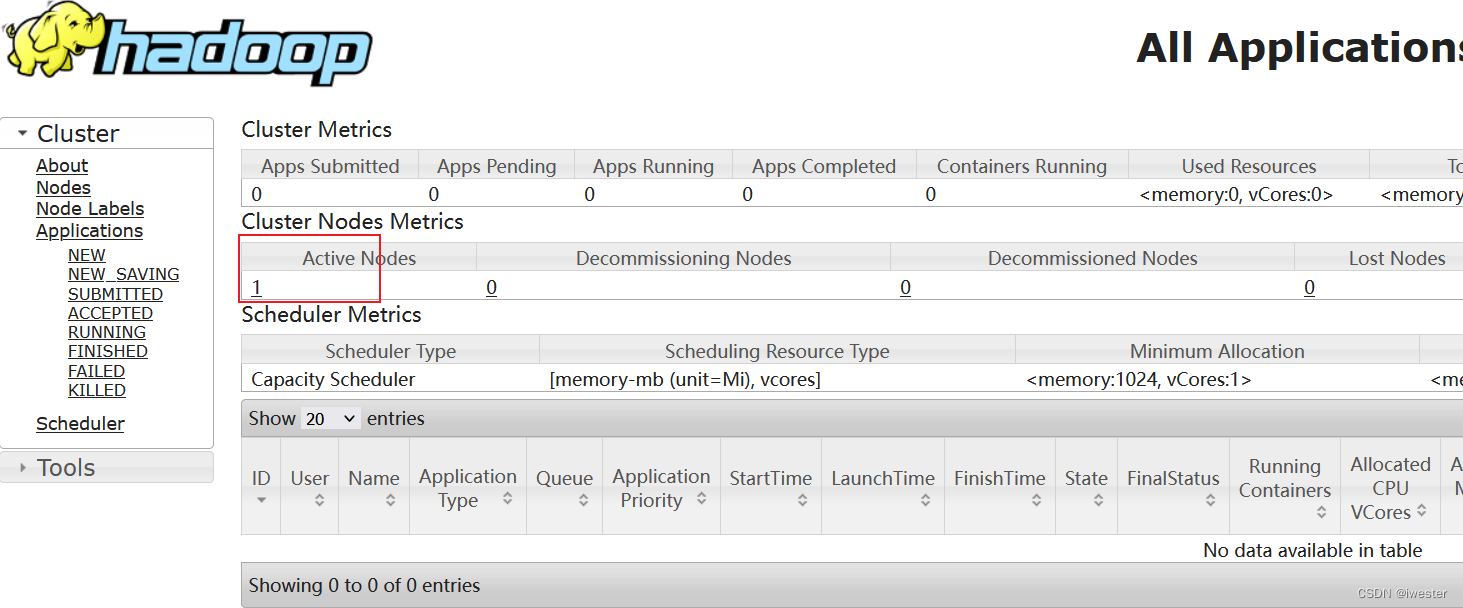
3.4:启动历史服务器
[root@node100 hadoop-3.2.2]# mapred --daemon start historyserver
[root@node100 hadoop-3.2.2]# jps
多出
4928 JobHistoryServer查看历史服务web http://node100:19888/jobhistory
四:服务管理命令
整体启动/关闭
启动hdfs+yarn
[root@node100 hadoop-3.2.2]# start-all.sh
关闭hdfs+yarn
[root@node100 hadoop-3.2.2]# stop-all.sh(1)整体启动/停止 HDFS
start-dfs.sh/stop-dfs.sh(2)整体启动/停止 YARN
start-yarn.sh/stop-yarn.sh(3)分别启动/停止 HDFS 组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode(4)启动/停止 YARN
yarn --daemon start/stop resourcemanager/nodemanager