kettle导入树形结构数据
- 应用场景
- 工作原理
- 工作流程
应用场景
获取数据的接口传入父节点的id,返回直属的子节点列表,通过广度优先遍历一棵树。
工作原理
使用数据库存放数据,利用作业进行循环遍历数据。
数据库存放节点数据,节点数据包括节点id、父节点id、是否为父节点、是否已经同步以及其它节点数据
| 字段 | 名称 |
|---|---|
| id | 树形id |
| pid | 树形pid |
| isParent | 是否为父节点 |
| sync | 是否已同步 |
| … | 其它数据 |
工作流程
- 创建一个转换
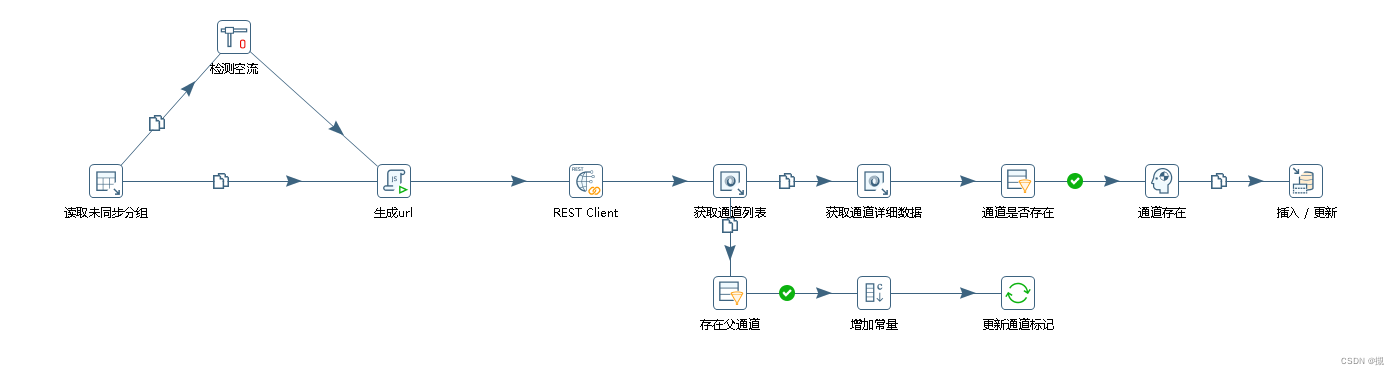
读取数据表中未同步过的分组节点,请求每个父节点的子节点列表,获取到后更新父节点的同步状态;
然后解析子节点列表,入库。 - 创建一个作业
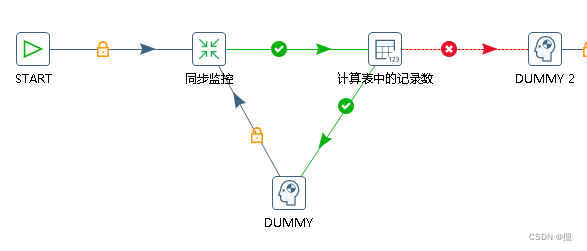
在转换步骤后添加一个“ 计算表中记录数” 的kettle对象
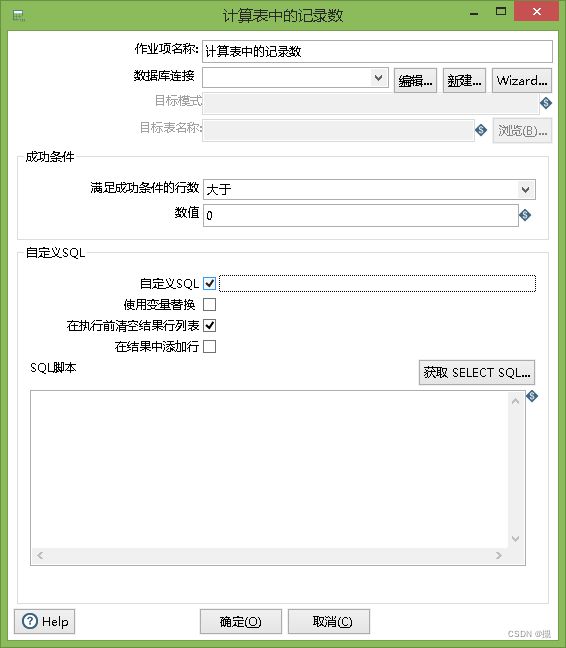
读出表中未同步数据行数判断,如果存在未同步的父节点则返回转换步骤,否则结束