文章目录
- HashMap
- put方法
- resize方法
- ConcurrentHashMap
- put方法
- initTable方法
- sizectl代表什么:
- 扩容
- 计数器
- ConcurrentHashMap的读操作会阻塞嘛
- AQS
- 唤醒线程时,AQS为什么从后往前遍历?
- AQS为什么要有一个虚拟的head节点
- AQS为什么用双向链表,(为啥不用单向链表)?
- CountDownLatch是啥?
- 锁
- synchronized锁升级的过程
- ReentrantLock
- 实现原理
- 公平锁和非公平锁的区别
- ReentrantReadWriteLock如何实现的读写锁
- 线程池
- 执行流程
- 线程池的几种状态
- 线程的几种状态
- 线程池中工作线程为什么要继承AQS?
- 线程池为什么添加空任务的非核心线程
- 在没任务时,线程池中的工作线程在干嘛?
- 工作线程出现异常会导致什么问题?
HashMap
结构,数组+链表或红黑树
变量
DEFAULT_INITIAL_CAPACITY = 1 << 4;默认容量16
MAXIMUM_CAPACITY = 1 << 30;最大容量
DEFAULT_LOAD_FACTOR = 0.75f;装载因子默认0.75
TREEIFY_THRESHOLD = 8;链表转化为树的最小长度
MIN_TREEIFY_CAPACITY = 64;整个map的数据个数大于64并且链表长度大于8才会进行链表到树的转化
UNTREEIFY_THRESHOLD = 6;树的数据个数小于6会转化为链表
int threshold;容量*装载因子,put值后如果数据个数大于threshold就进行resize
int modCount;记录修改数,用在迭代器遍历时如果删除或者添加元素判断modCount是否变化,如果变化直接抛异常
Node节点
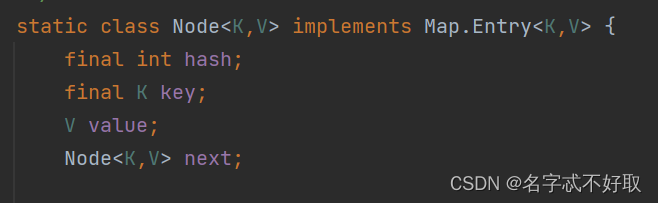
put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
resize方法
1、如果数组大小是0,初始化数组大小16,threshold值为16*装载因子
2、如果数组大小不为0,新数组的大小是旧数组大小两倍,threshold也是原来的两倍
3、遍历旧数组,把数据放入新数组中;在重新插入链表时,jdk1.7和jdk1.8有所不同:
jdk1.7采用头插法(并发下可能导致循环链表),jdk1.8采用尾插法
ConcurrentHashMap
put方法
putVal的流程
1、如果数组没初始化,先初始化大小
2、用数组大小和hash(key)值做与运算得到数组下标,如果没值直接放在这
3、如果不为null:
3.1:如果头节点的hash和hash(key)相同并且他们的key也相同,直接替换value
3.2:如果投节点是treeNode,调用树的putVal方法
3.3:对节点进行遍历
3.3.1:如果下一个节点是null,直接放
如果放完后链表长度大于8,调用转化为树的方法(并不会直接就转化为树,还要判断数组大小,
如果小于64就扩容,否则才会转化为树)
3.3.2:如果下一个节点的hash和key与要放的数据都相等,替换value就行;使用尾插法
4、放完之后判断数据个数是否大于threshold,如果大于就扩容
ConcurrentHashMap jdk1.8的putVal:
先判断Node数组是否初始化,没有就先初始化
如果计算出的下标数组元素是null,会使用cas操作去放;
如果数组元素不为null并且map在扩容,调用helpTransfer帮忙扩容
否则,使用synchronized加锁取链表或者红黑树插入
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
//初始化数组
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//如果Node数组下标位置没有元素使用cas放值
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
//结束循环
break; // no lock when adding to empty bin
}
//MOVE就是-1,表示当前节点被迁移,数组正在扩容,
else if ((fh = f.hash) == MOVED)
//协助扩容
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//使用synchronized对链表或者红黑树存入Node节点
synchronized (f) {
//如果是链表
if (tabAt(tab, i) == f) {
...
}
如果是红黑树
else if (f instanceof TreeBin) {
...
}
}
if (binCount != 0) {
//如果链表长度>=8,树化
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
initTable方法
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
//如果当前数组正在被其他线程初始化,等待
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
//第一个线程cas将sizectl改为-1,进行初始化
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
//初始化数组长度
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
其实这里类似DCL,只不过这里使用的CAS而不是synchronized
sizectl代表什么:
sizeCtl是用来控制数据的一些操作的。
sizeCtl > 0:
可能是下次扩容的阈值
可能是初始化数组的长度
sizeCtl == 0:数组还没初始化,并且没设置初始长度,默认16。
sizeCtl == -1:数组正在初始化
sizeCtl < -1:数组正在扩容
扩容
什么时候会扩容?
元素个数,达到了负载因子计算的阈值,那么直接扩容
当调用putAll方法,查询大量数据时,也可能会造成直接扩容的操作,大量数据是如果插入的数据大于下次扩容的阈值,直接扩容,然后再插入
数组长度小于64,并且链表长度大于等于8时,会触发扩容
扩容流程
每个扩容的线程都需要基于oldTable的长度计算一个扩容标识戳(避免出现两个扩容线程的数组长度不一致。其次保证扩容标
识戳的16位是1,这样左移16位会得到一个负数)
第一个扩容的线程,会对sizeCtl + 2,代表当前有1个线程来扩容
除去第一个扩容的线程,其他线程会对sizeCtl + 1,代表现在又来了一个线程帮助扩容
第一个线程会初始化新数组
每个线程会领取迁移数据的任务,将oldTable中的数据迁移到newTable。默认情况下,每个线程每次领取长度为16的迁移数
据任务
当数据迁移完毕时,每个线程再去领取任务时,发现没任务可领了,退出扩容,对sizeCtl - 1
最后一个退出扩容的线程,发现-1之后,还剩1,最后一个退出扩容的线程会从头到尾再检查一次,有没有遗留的数据没有迁
移走(这种情况基本不发生),检查完之后,再-1,这样sizeCtl扣除完,扩容结束
计数器
CHM采用了LongAdder作为计数器的实现。
但是并没有直接引用LongAdder,而是仿照LongAdder源码又实现了一份。
分段存储元素个数,baseCount有,CounterCell有,调用size就是对各个位置的进行累加
private final void addCount(long x, int check) {
//每个线程操作一个countCell
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
}
ConcurrentHashMap的读操作会阻塞嘛
不会
查询数组? :就是查看元素是否在数组,在就直接返回。
查询链表?:如果没特殊情况,就在链表next,next查询即可。
扩容时?:如果当前索引位置是-1,代表当前位置数据全部都迁移到了新数组,直接去新数组查询,不管有没有扩容完。
查询红黑树?:如果有一个线程正在写入红黑树,此时读线程还能去红黑树查询吗?
因为红黑树为了保证平衡可能会旋转, 旋转会换指针,可能会出现问题。所以在转换红黑树时,不但有一个红黑树,还会
保留一个双向链表,此时会查询双向链表,不让读线程阻塞。至于如何判断是否有线程在写,和等待写或者是读红黑树,
根据TreeBin的lockState来判断,如果是1,代表有线程正在写,如果为2,代表有写线程等待写,如果是4n,代表有多个线
程在做读操作
ConcurrentHashMap jdk1.7的putVal:
1.7中采用的是segment数组(一个segment由hashentry数组+链表)
第一次计算key的hash,找到Segment元素的位置;
判断当前Segment元素是否初始化,若没有初始化,则通过CAS进行初始化;
第二次计算key的hash,找到HashEntry数组的位置;
由于Segment继承了ReentrantLock锁,所以TryLock() 尝试获取锁,如果成功,将数据插入到HashEntry位置,如果遇到Hash冲突,则插入到链表;如果锁被其他线程获取,那么就会以自旋的方式重新获取锁,超过指定的次数之后还获取不到的话,就会挂起,等待其他线程释放锁
AQS
AQS就是一个抽象队列同步器,abstract queued sychronizer,本质就是一个抽象类
AQS中有一个核心属性state,其次还有一个双向链表(有一个虚拟head节点)以及一个单项链表。
首先state是基于volatile修饰,再基于CAS修改,同时可以保证三大特性。(原子,可见,有序)
其次还提供了一个双向链表。有Node对象组成的双向链表。
最后在Condition内部类中,还提供了一个由Node对象组成的单向链表。
AQS是JUC下大量工具的基础类,很多工具都基于AQS实现的,比如lock锁,CountDownLatch,Semaphore,线程池等等都用到了AQS
state:就是一个int类型的数值,同步状态,至于到底是什么状态,看子类实现
condition和单向链表:sync内部提供了wait方法和notify方法的使用,lock锁也需要实现这种机制,lock锁就基于AQS内部的
Condition实现了await和signal方法
sync在线程持有锁时,执行wait方法,会将线程扔到WaitSet等待池中排队,等待唤醒
lcok在线程持有锁时,执行await方法,会将线程封装为Node对象,扔到Condition单向链表中,等待唤醒
Condition在做了什么:将持有锁的线程封装为Node扔到Condition单向链表,同时挂起线程。如果线程唤醒了,就将
Condition中的Node扔到AQS的双向链表等待获取锁
唤醒线程时,AQS为什么从后往前遍历?
基于addWaiter方法中,是先将当前Node的prev指向tail的节点,再将tail指向我自己,再让prev节点指向我
如果只执行到了2步骤,此时,Node加入到了AQS队列中,但是从prev节点往后,会找不到当前节点
AQS为什么要有一个虚拟的head节点
有一个哨兵节,点更方便操作
另一个是因为AQS内部,每个Node都会有一些状态(waitStatus),这个状态不单单针对自己,还针对后续节点
1:当前节点取消了。
0:默认状态,啥事没有。
-1:当前节点的后继节点,挂起了。
-2:代表当前节点在Condition队列中(await将线程挂起了)
-3:代表当前是共享锁,唤醒时,后续节点依然需要被唤醒
如果取消虚拟的head节点,一个节点无法同时保存当前阶段状态和后继节点状态。
同时,在释放锁资源时,就要基于head节点的状态是否是-1。来决定是否唤醒后继节点。
AQS为什么用双向链表,(为啥不用单向链表)?
因为AQS中,存在取消节点的操作,节点被取消后,需要从AQS的双向链表中断开连接。还需要保证双向链表的完整性,
需要将prev节点的next指针,指向next节点,需要将next节点的prev指针,指向prev节点
如果正常的双向链表,直接操作就可以了,但是如果是单向链表,需要遍历整个单向链表才能完成的上述的操作。比较浪费资源
CountDownLatch是啥?
在多线程并形处理业务时,需要等待其他线程处理完,再做后续的合并等操作,再响应用户时,可以使用CountDownLatch做计数,等到其他线程出现完之后,主线程就会被唤醒
CountDownLatch本质其实就是一个计数器,基于AQS实现的。
CountDownLatch本身就是基于AQS实现的。
new CountDownLatch时,直接指定好具体的数值。这个数值会复制给state属性。
当子线程处理完任务后,执行countDown方法,内部就是直接给state - 1而已。
当state减为0之后,执行await挂起的线程,就会被唤醒。
CountDownLatch不能重复使用,用完就凉凉。
锁
synchronized锁升级的过程
无锁(匿名偏向):一般情况下,new出来的一个对象,是无锁状态。因为偏向锁有延迟,在启动JVM的4s中,不存在偏向锁,
但是如果关闭了偏向锁延迟的设置,new出来的对象,就是匿名偏向
偏向锁: 当某一个线程来获取这个锁资源时,此时,就会变为偏向锁,偏向锁存储线程的ID
查看对象头中的MarkWord里的线程ID,是否是当前线程,如果不是,就CAS尝试改,如果是,就拿到了锁资源
轻量级锁: 当在出现了多个线程的竞争,就要升级为轻量级锁(有可能直接从无锁变为轻量级锁,也有可能从偏向锁升级为
轻量级锁),轻量级锁的效果就是基于CAS尝试获取锁资源,这里会用到自适应自旋锁,根据上次CAS成功与否,决定这
次自旋多少次。
查看对象头中的MarkWord里的Lock Record指针指向的是否是当前线程的虚拟机栈,如果是,拿锁执行业务,如果不是
CAS,尝试修改,修改他几次,不成,再升级到重量级锁。
重量级锁: 如果到了重量级锁,那就没啥说的了,如果有线程持有锁,其他竞争的,就挂起
查看对象头中的MarkWord里的指向的ObjectMonitor,查看owner是否是当前线程,如果不是,扔到ObjectMonitor里的
EntryList中,排队,并挂起线程,等待被唤醒
ReentrantLock
实现原理
基于AQS实现的
在线程基于ReentrantLock加锁时,需要基于CAS去修改state属性,如果能从0改为1,代表获取锁资源功
如果CAS失败了,添加到AQS的双向链表中排队(可能会挂起线程),等待获取锁。
持有锁的线程,如果执行了condition的await方法,线程会封装为Node添加到Condition的单向链表中,等待被唤醒并且重新竞争锁资源
公平锁和非公平锁的区别
公平锁和非公平中的lock方法和tryAcquire方法的实现有一点不同,其他都一样
非公平锁lock:直接尝试将state从 0 ~ 1,如果成功,拿锁直接走,如果失败了,执行tryAcquire
非公平锁tryAcquire:如果当前没有线程持有锁资源,直接再次尝试将state从 0 ~ 1如果成功,拿锁直接走
公平锁lock:直接执行tryAcquire
公平锁tryAcquire:如果当前没有线程持有锁资源,先看一下,有排队的么。
如果没有排队的,直接尝试将state从 0 ~ 1
如果有排队的,第一名不是我,不抢,继续等待。
如果有排队的,我是第一名,直接尝试将state从 0 ~ 1
如果都没拿到锁,公平锁和非公平锁的后续逻辑是一样的,排队后,就不存在所谓的插队
ReentrantReadWriteLock如何实现的读写锁
ReentrantReadWriteLock也是基于AQS实现的一个读写锁,但是锁资源用state标识。
如何基于一个int来标识两个锁信息,有写锁,有读锁,怎么做的?
一个int,占了32个bit位。
在写锁获取锁时,基于CAS修改state的低16位的值。
在读锁获取锁时,基于CAS修改state的高16位的值。
写锁的重入,基于state低16直接标识,因为写锁是互斥的。
读锁的重入,无法基于state的高16位去标识,因为读锁是共享的,可以多个线程同时持有。所以读锁的重入用的是
ThreadLocal来表示,同时也会对state的高16为进行追加。
线程池
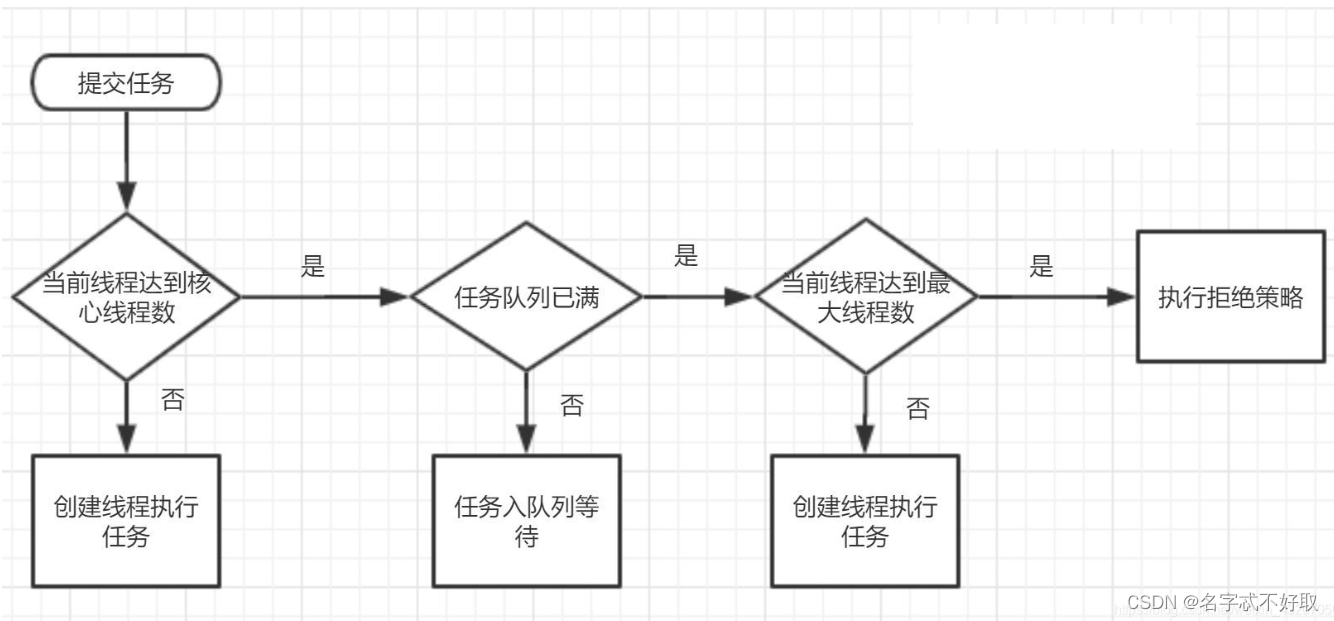
执行流程
核心线程不是new完就构建的,是懒加载的机制,添加任务才会构建核心线程
线程池的几种状态
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
RUNNING:有任务就正常接收
SHUTDOWN :不会接收任务,但会执行正在处理中的任务
STOP:不会接受新任务,立即中断正在执行任务的线程
TIDYING : 过渡状态
TERMINATED:销毁终止
线程的几种状态
NEW:线程创建好了
RUNNABLE:线程准备好可以运行
BLOCKED:竞争锁,synchronized同步代码块
WAITING:等待状态,调用Object.notifyAll()
TIMED_WAITING:超时等待,调用Object.notifyAll(1000)
TERMINATED:线程终止销毁
线程池中工作线程为什么要继承AQS?
工作线程继承AQS的目的是什么
继承AQS跟shutdown和shutdownNow有关系。
如果是shutdown,会中断空闲的工作线程,基于Worker实现的AQS中的state的值来判断能否中断工作线程。
如果工作线程的state是0,代表空闲,可以中断,如果是1,代表正在干活。
如果是shutdownNow,直接强制中断所有工作线程
当然也可以自己去维护这样一个变量,没有必要
线程池为什么添加空任务的非核心线程
避免线程池出现工作队列有任务,但是没有工作线程处理
线程池可以设置核心线程数是0个。这样,任务扔到阻塞队列,但是没有工作线程,这不凉凉了么~~
线程池中的核心线程不是一定不会被回收,线程池中有一个属性,如果设置为true,核心线程也会被干掉
在没任务时,线程池中的工作线程在干嘛?
线程会挂起,默认核心线程是WAITING状态,非核心是TIMED_WAITING
如果是核心线程,默认情况下,会在阻塞队列的位置执行take方法,直到拿到任务为止。
如果是非核心线程,默认情况下,会在阻塞队列的位置执行poll方法,等待最大空闲时间,如果没任务,
直接销毁,如果有活,那就正常干
工作线程出现异常会导致什么问题?
出现异常的工作线程不会影响到其他的工作线程
如果任务是execute方法执行的
工作线程会将异常抛出,异常会被抛到run方法中,run方法会异常结束,run方法结束,线程就嘎了
如果任务是submit方法执行的futureTask
工作线程会将异常捕获并保存到FutureTask里,可以基于futureTask的get得到异常信息,线程不会死