本文详细解读了OpenAI公司在2018年6月发布的论文《Improving Language Understanding by Generative Pre-Training》,它其中介绍的算法也就是后来人们说的GPT。本文借鉴了李沐的这个视频,感兴趣的同学可以移步观看大神的讲解。
目录
- 引言
- GPT方法
- 无监督预训练
- 有监督微调
- 子任务的描述
- 实验
- 参考文献
引言
在Transformer方法推出的1年后,OpenAI公司发布了GPT系列的第一篇论文,采用生成-判别模型架构,在多个自然语言处理(NLP)任务上实现了较高的精度。
总体而言,GPT方法在很大程度上解决了数据量不足给NLP任务带来的局限;也避免了在不同NLP子任务的解决上,需要不断调整模型的麻烦。
GPT方法
GPT的基本思路是:在有标注的数据集下训练得到一个初始模型,随后在有标注的子任务数据集下,精调得到用于各任务的子模型。在微调时,GPT使用了两个优化的目标函数。
无监督预训练
给定一个语言序列
U
=
{
u
1
,
…
,
u
n
}
\mathcal U=\left\{u_1, \dots, u_n\right\}
U={u1,…,un},GPT采用标准的语言模型,即最大化如下的目标函数:
L
1
(
U
)
=
∑
i
log
P
(
u
i
∣
u
i
−
k
,
…
,
u
i
−
1
;
Θ
)
L_1(\mathcal U)=\sum_i\text{log}P\left( u_i\vert u_{i-k},\dots,u_{i-1};\Theta\right)
L1(U)=i∑logP(ui∣ui−k,…,ui−1;Θ)
其中
k
k
k是上下文窗口的尺寸,条件概率
P
P
P是通过参数为
Θ
\Theta
Θ的神经网络建模得到的。
简单来说,上面描述的条件概率,是在给定描述模型和位置 i i i之前的 k k k个词后,第 i i i个位置出现词 u i u_i ui的概率。将所有概率加起来,就得到了目标函数。这里的窗口尺寸 k k k其实可以理解为模型接受的输入序列的长度。当 k k k越大时,模型可以消化更多的信息,但是模型也更加复杂。因此,如果希望模型能力很强,这里的 k k k可能要取到几十、几百,甚至上千。
注: 目标函数中采用的是所有 log P i \text{log} P_i logPi的和,但是联合概率应该是所有概率的积。这里是相加的原因是,公式中采用了log变换,那么log结果的和也就是所有幂的乘积。不清楚具体变换的同学可以移步这个视频。
具体上,GPT中采用的模型( Θ \Theta Θ)是Transforer的解码器。Transformer包含两个结构:编码器和解码器。其中,编码器可以看到整个序列中的所有信息;但由于掩码的存在,解码器只能看到非掩码遮盖部分的信息,被遮盖的位置则都是0。由于在语言处理中,模型是只能看到当前词之前的信息的,因此GPT只能采用解码器部分,而不能采用编码器。
更多关于Transformer的介绍,可以移步这篇文章(还在写,挖个坑)详细了解。
有监督微调
精调模型是在有标号的数据集上进行的。具体来说,就是给定一段输入序列和对应的标号,将前面预训练好的模型的最后一层的输出拿出来,经过一个输出层,得到序列最后位置处的估计概率。数学上,这个概率可以表示为:
P
(
y
∣
x
1
,
…
,
x
m
)
=
softmax
(
h
l
m
W
y
)
P\left(y\vert x^1,\dots,x^m\right) = \text{softmax}\left(h_l^mW_y\right)
P(y∣x1,…,xm)=softmax(hlmWy)
其中,
x
1
,
…
,
x
m
x^1,\dots,x^m
x1,…,xm是输入,
y
y
y是标签,
h
l
m
h_l^m
hlm是预训练模型最后一层对位置
m
m
m处的预测结果。
此时,目标函数就是:
L
2
(
C
)
=
∑
x
,
y
log
P
(
y
∣
x
1
,
…
,
x
m
)
L_2\left(\mathcal C\right)=\sum_{x,y}\text{log} P\left(y\vert x^1,\dots,x^m\right)
L2(C)=x,y∑logP(y∣x1,…,xm)
GPT作者发现,在精调过程中引入预训练的目标函数,同样可以增加模型的精度。因此,微调过程最终的目标函数是两个目标函数的加权求和:
L
c
(
C
)
=
L
2
(
C
)
+
λ
×
L
1
(
C
)
L_c\left(\mathcal C\right)=L_2\left(\mathcal C \right) + \lambda\times L_1\left(\mathcal C\right)
Lc(C)=L2(C)+λ×L1(C)
子任务的描述
在知道了目标函数之后,剩下的问题就是如何将NLP中的各种任务,表示成序列对应的标号。在GPT中,这种表示逻辑可以由下图进行表示。
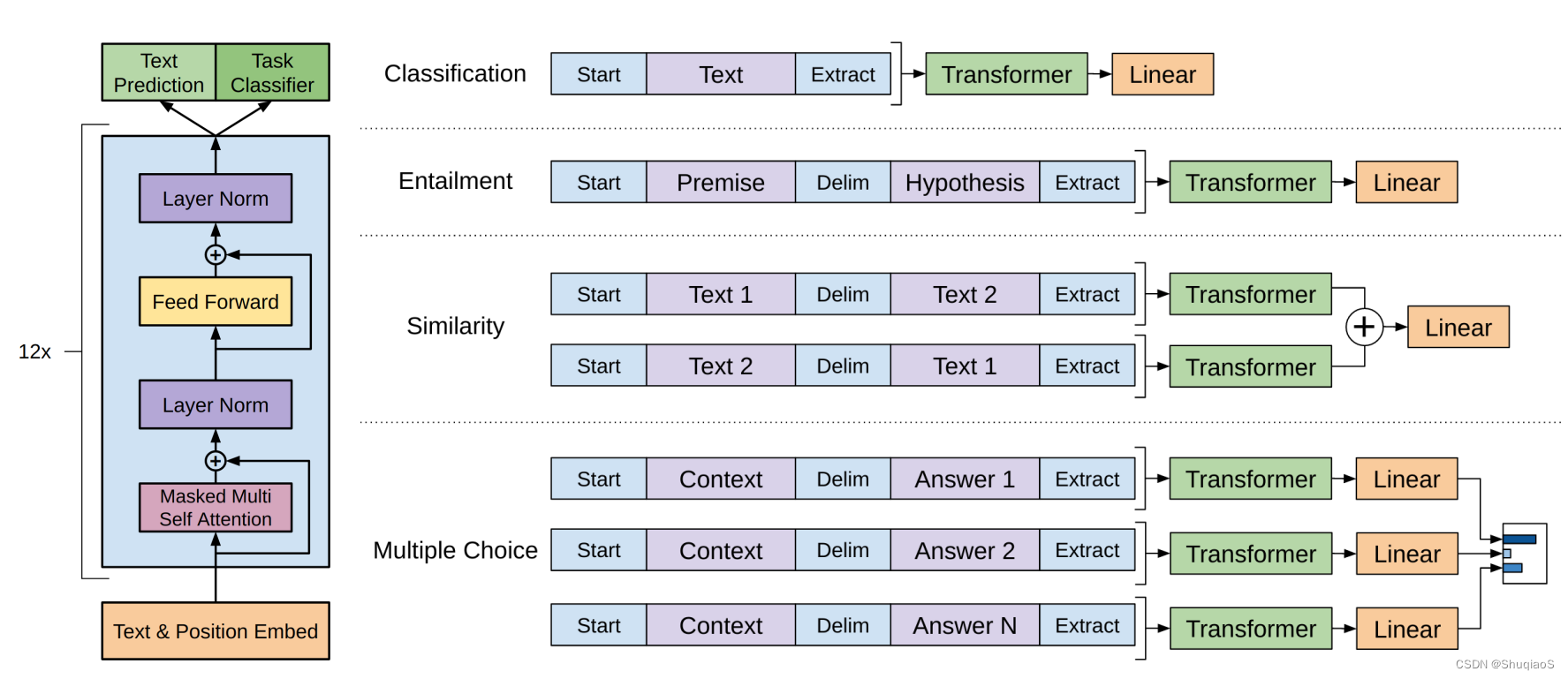
图中给出了4个常见的NLP子任务和其对应的标注方法。从图中可以看出无论是对什么任务,其输入可能被分割成1个、2个甚至多个字段,后面的输出层的结构也可能随任务发生变化,但是其中的transformer部分,一旦训练好了就不需要改变了。这也是GPT与其他NLP方法的一个核心区别。
实验
论文的实验部分本文简要带过,感兴趣的同学请移步论文原文。
这里只提醒大家注意以下几点:
- GPT是在BooksCorpus数据集上训练得到的。这个数据集包含了7000余本未发表的各领域书籍。
- GPT使用了12层的Transformer解码器,每一维是768。
参考文献
- 李沐. GPT,GPT-2,GPT-3 论文精读【论文精读】
- The Math Sorcerer. How to Combine Two Logarithms into a Single Logarithm using Properties of Logs






![buu [BJDCTF2020]signin 1](https://img-blog.csdnimg.cn/4a19b6d279d74e9c9c2acdda469e70a6.png)