输入
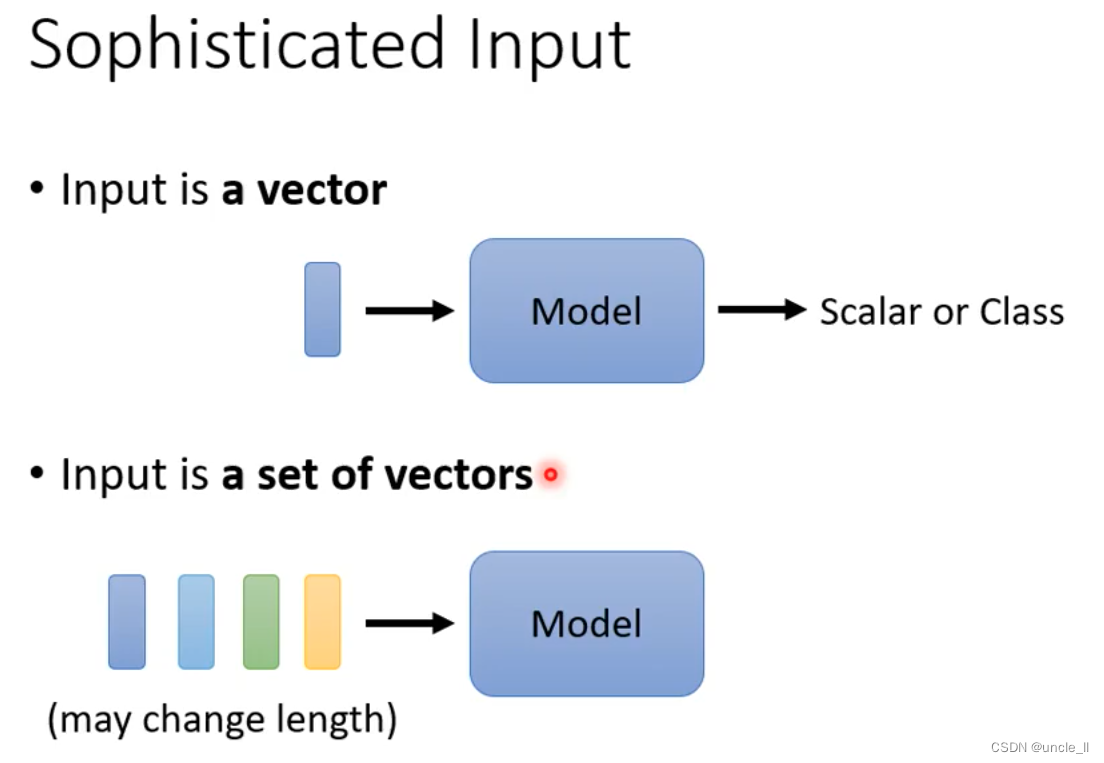
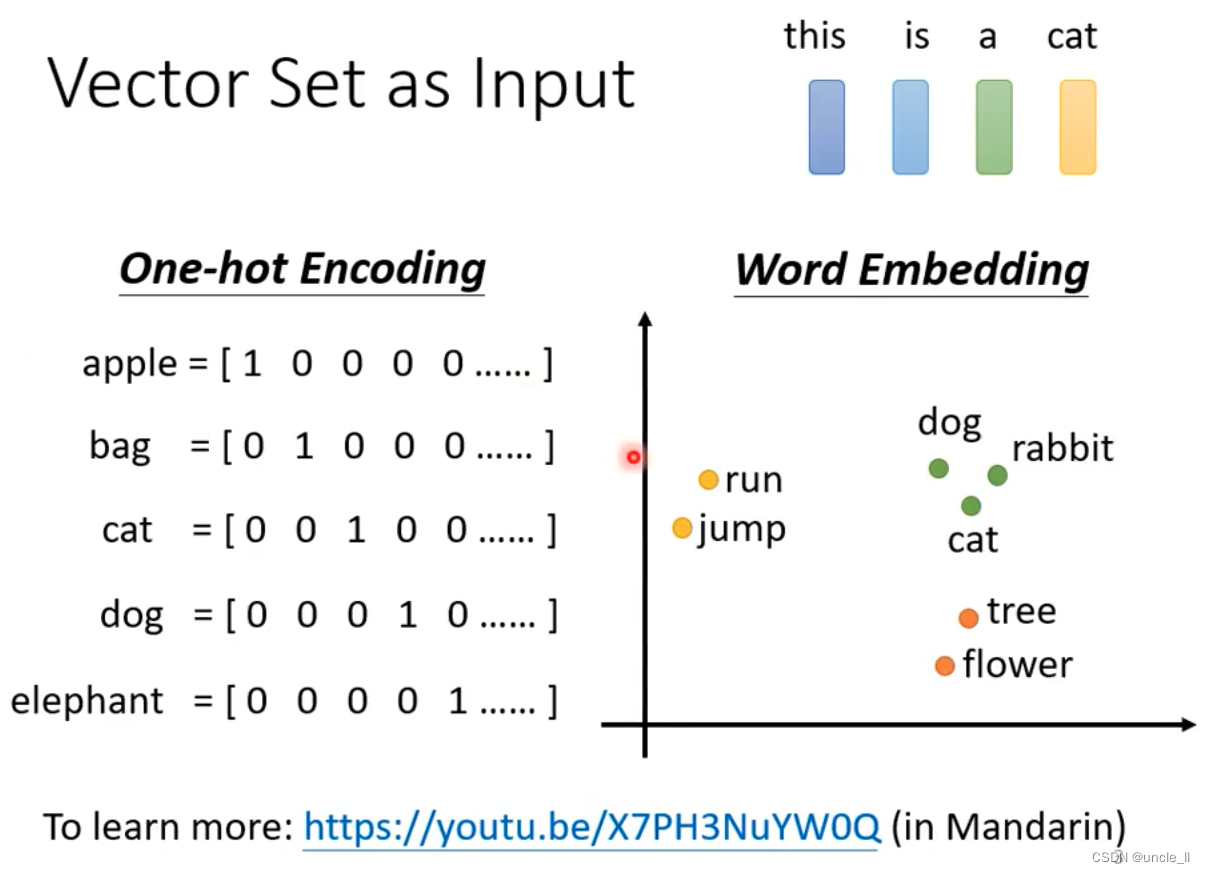
编码方式:
- one-hot:
- word-embedding:能更明显的区分不同类别的输入
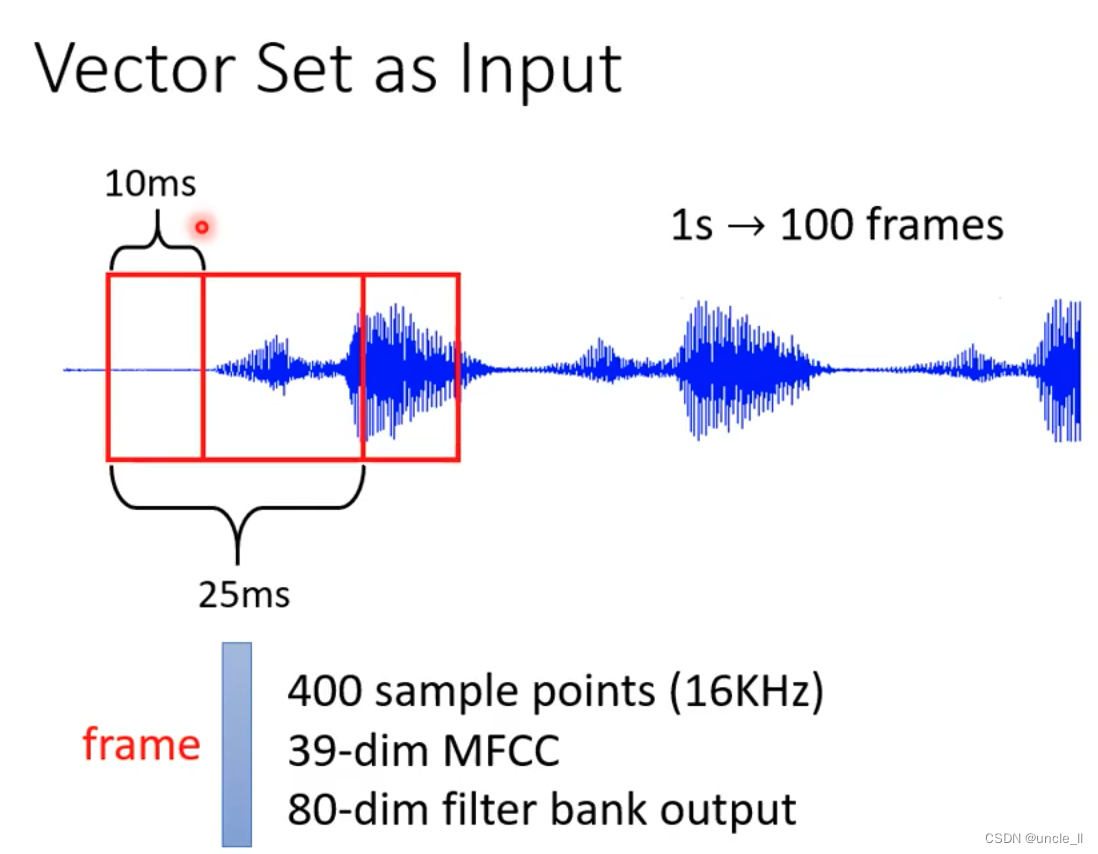
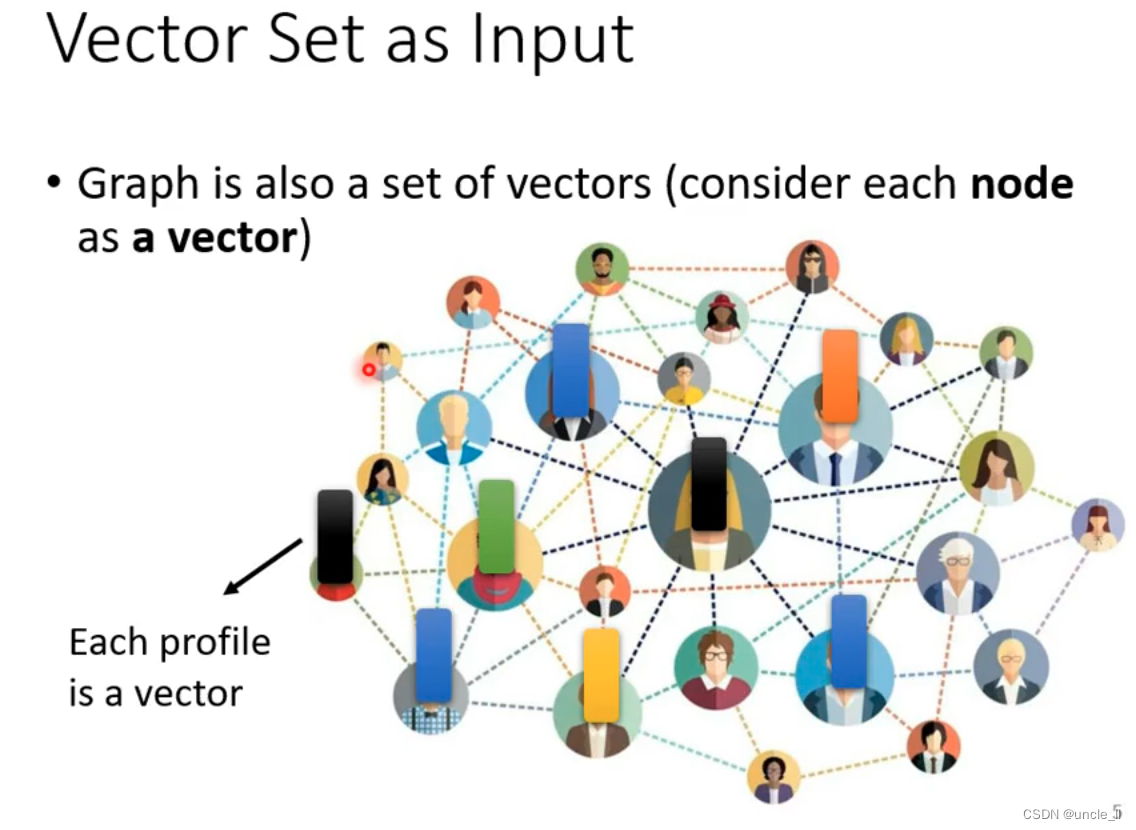
图也能看作是多个向量输入
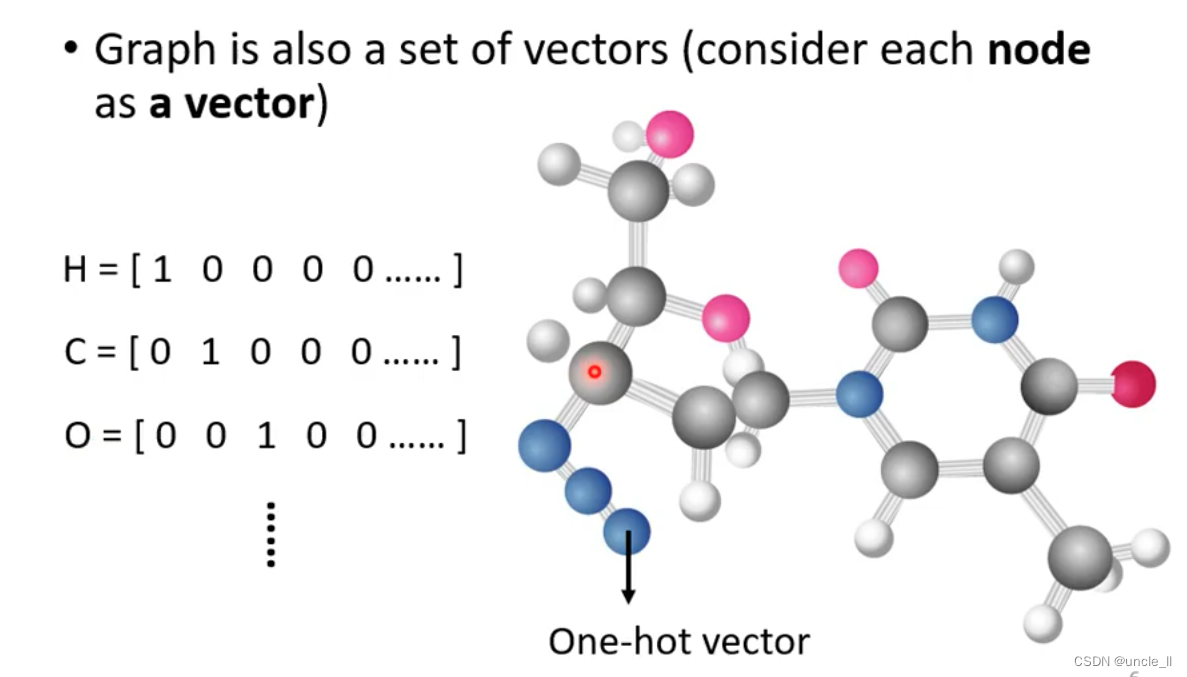
输出
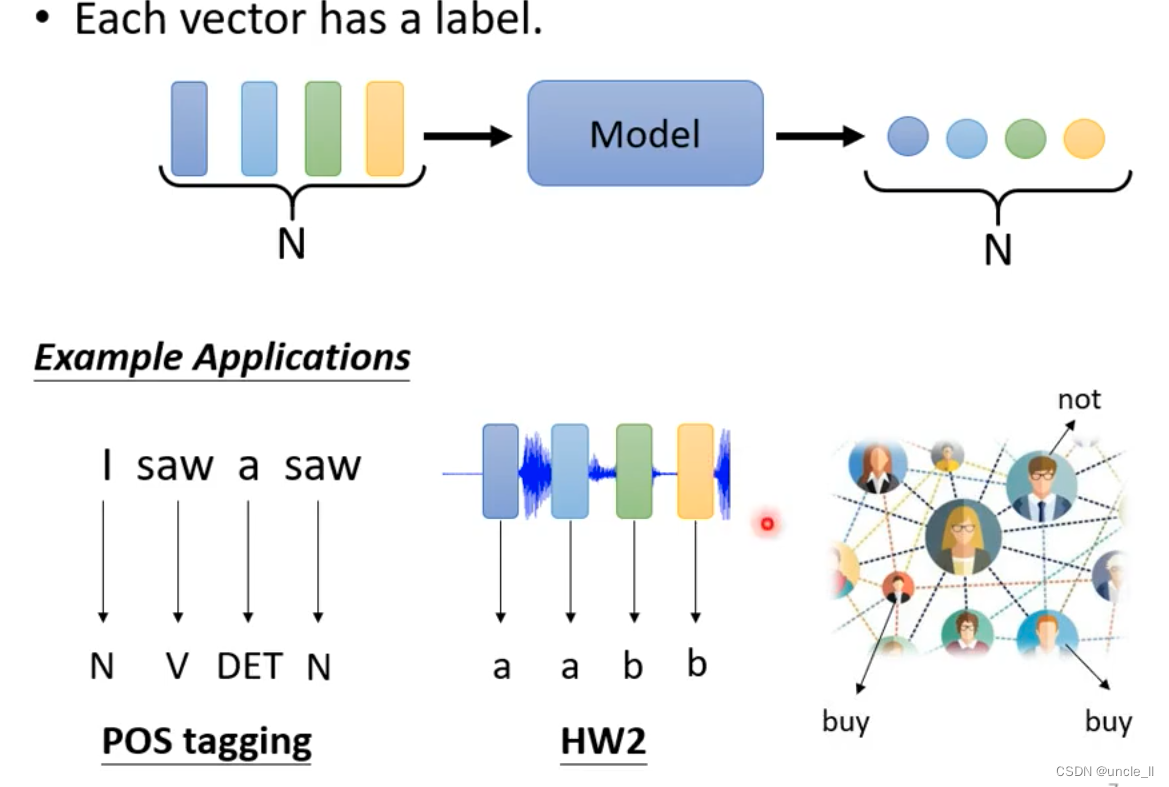
- 每个向量都有一个label
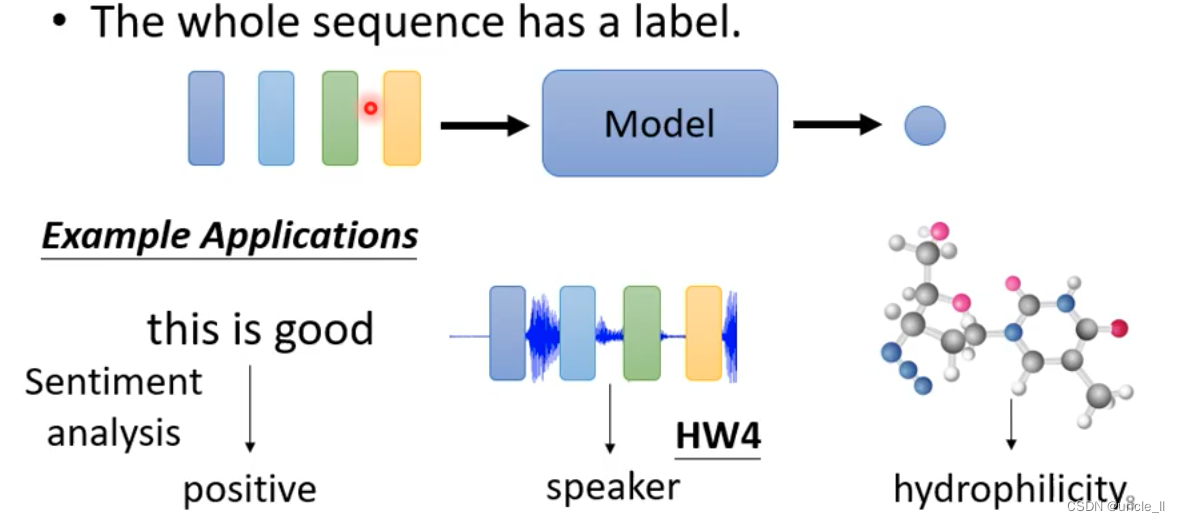
- 一整个sequence有一个label
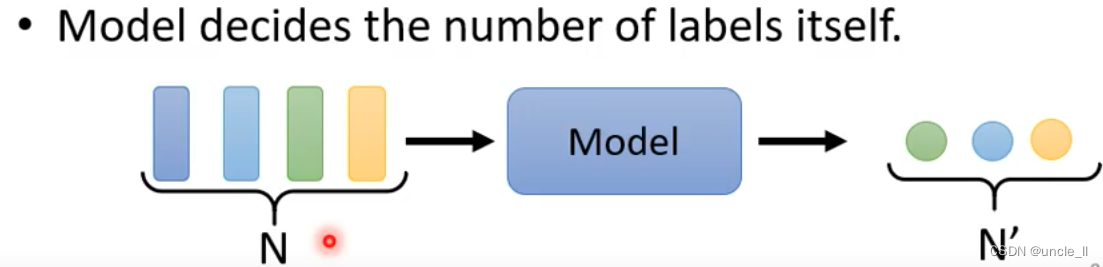
- 模型自己决定有多少个label(sequence to sequence)
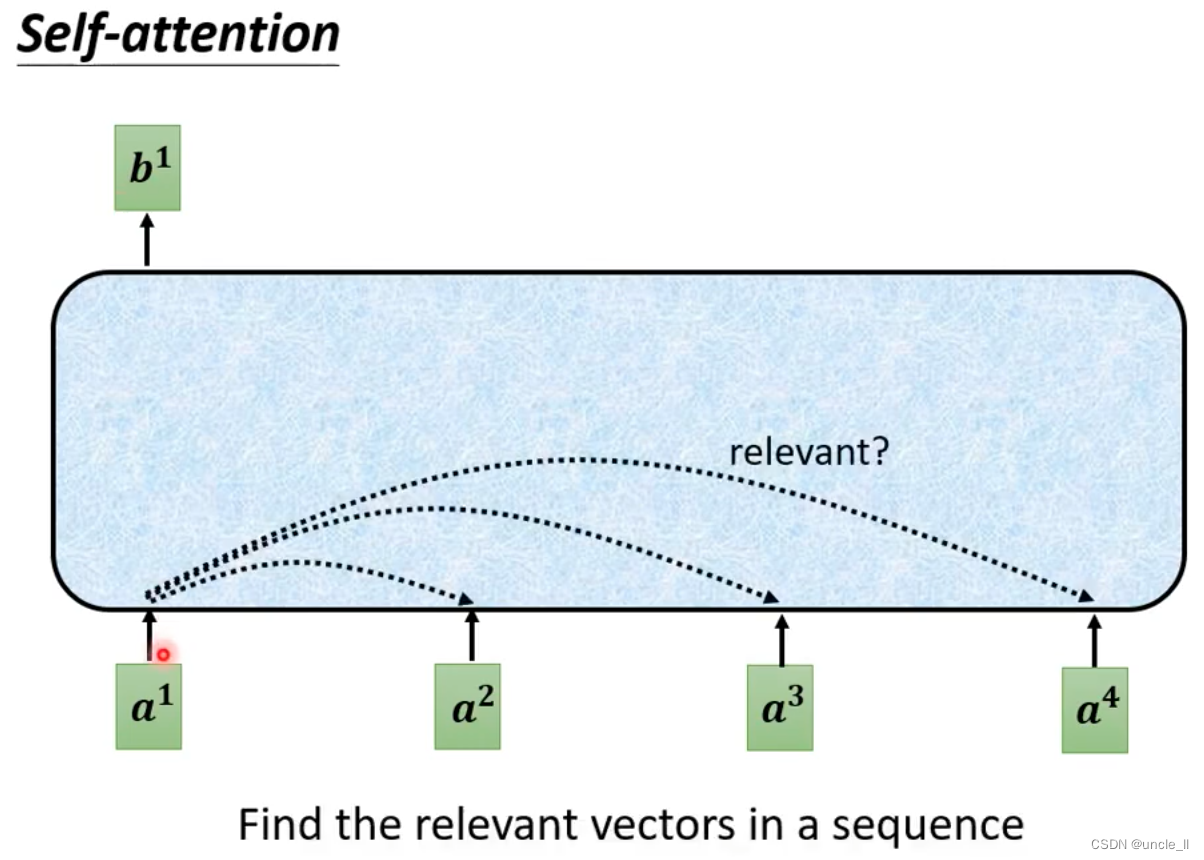
重点介绍每个vector有一个label
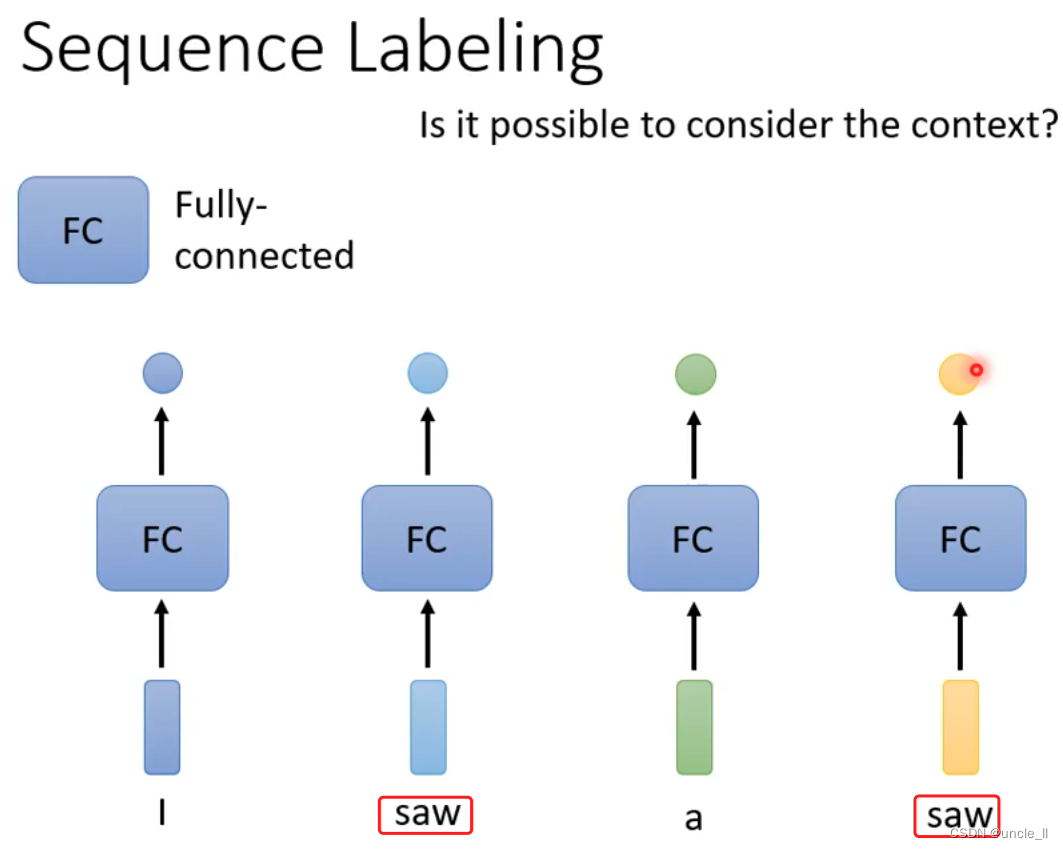
- saw词性第一个和第二个不同,但是网络无法识别
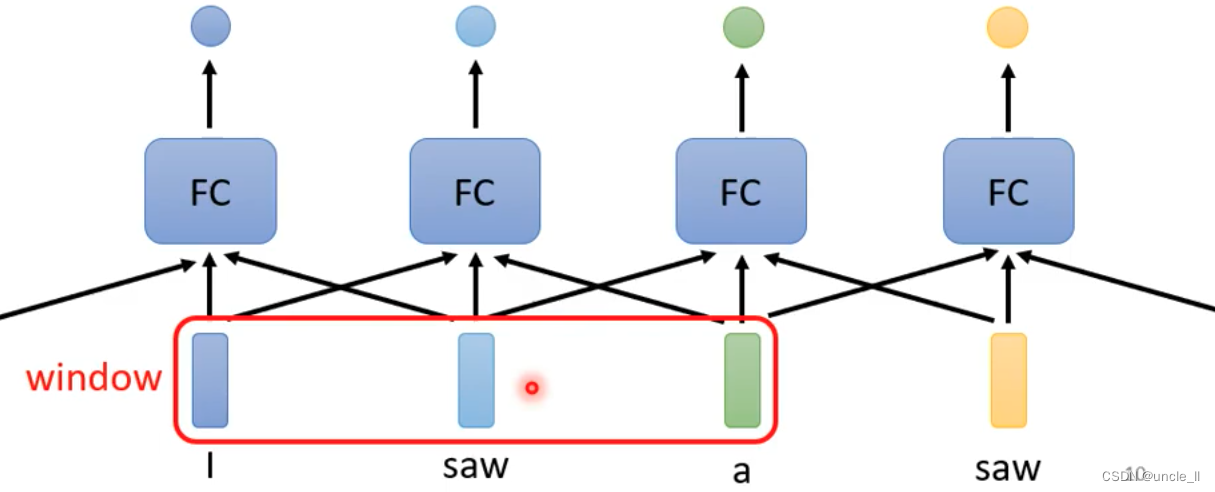
- 通过联系上下文解决
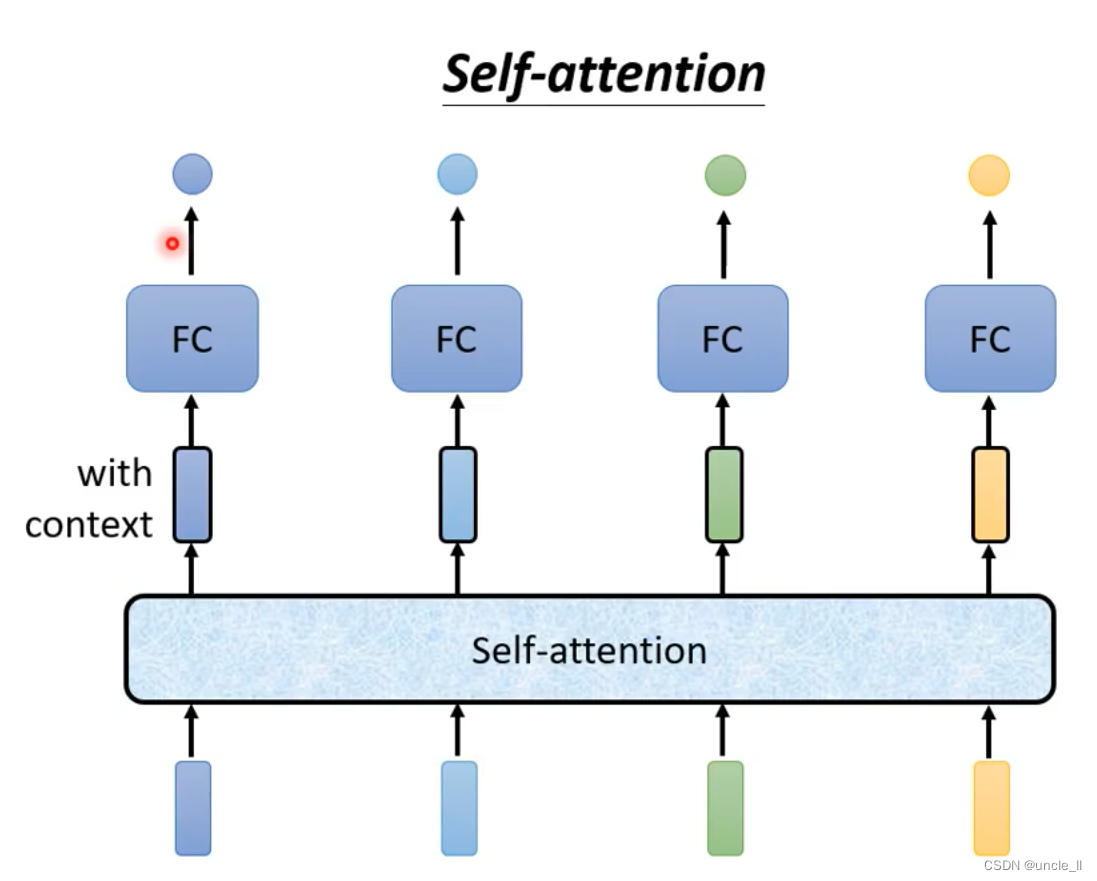
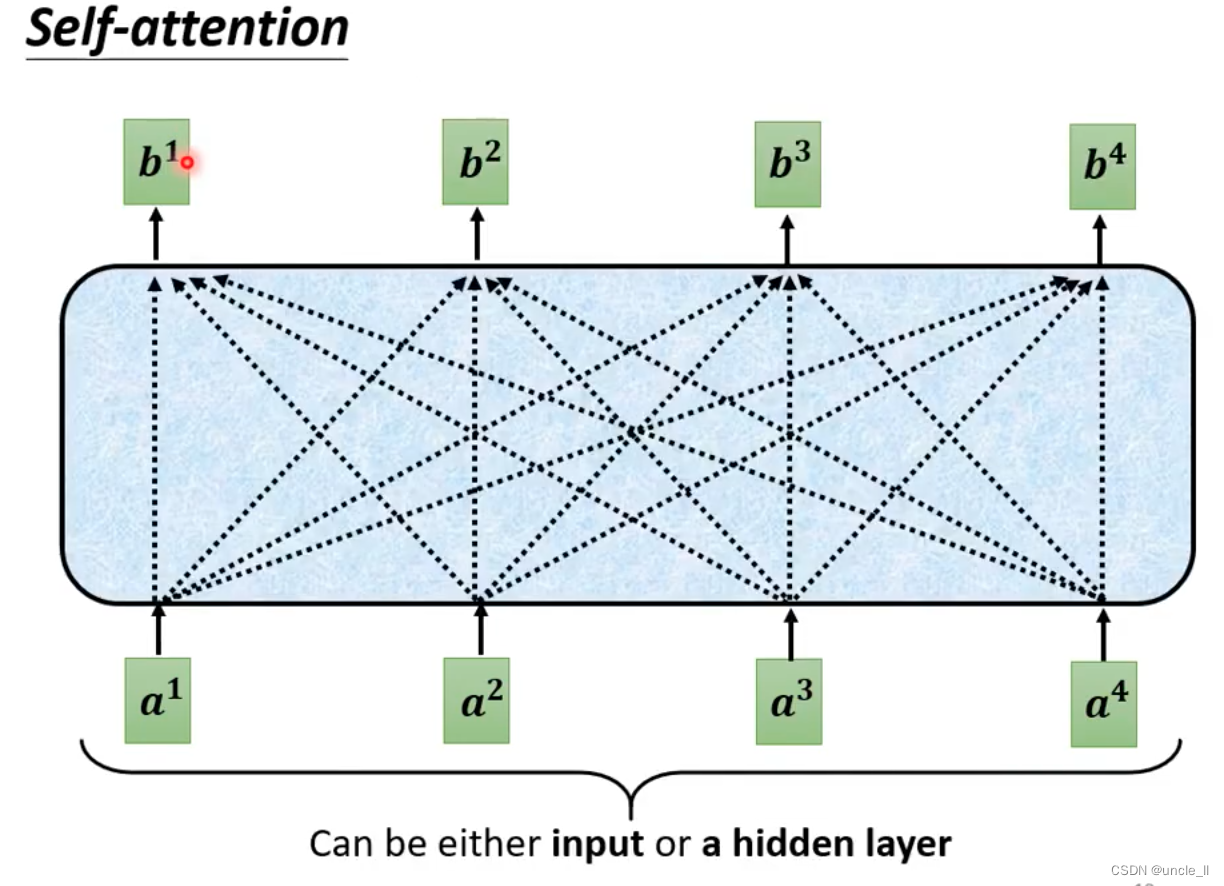
self-attention不只是只能做一次,能做很多次
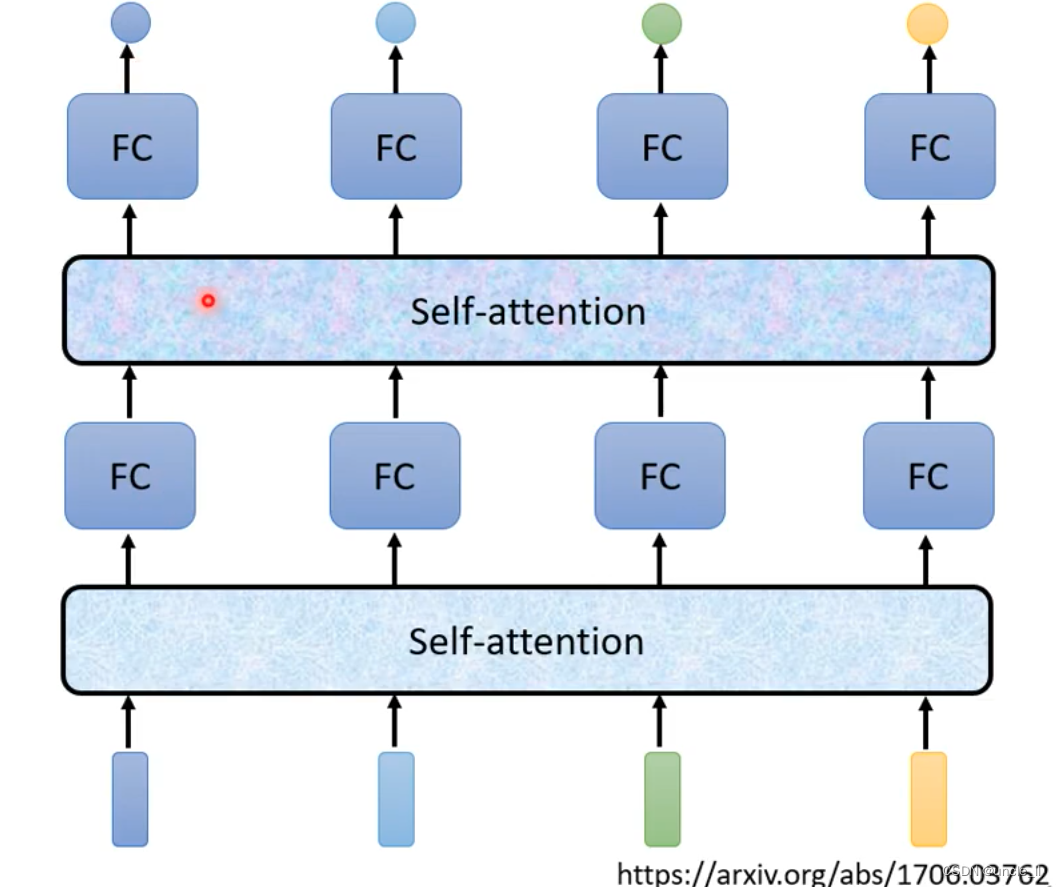
- 文章: attention is all you need - transformer
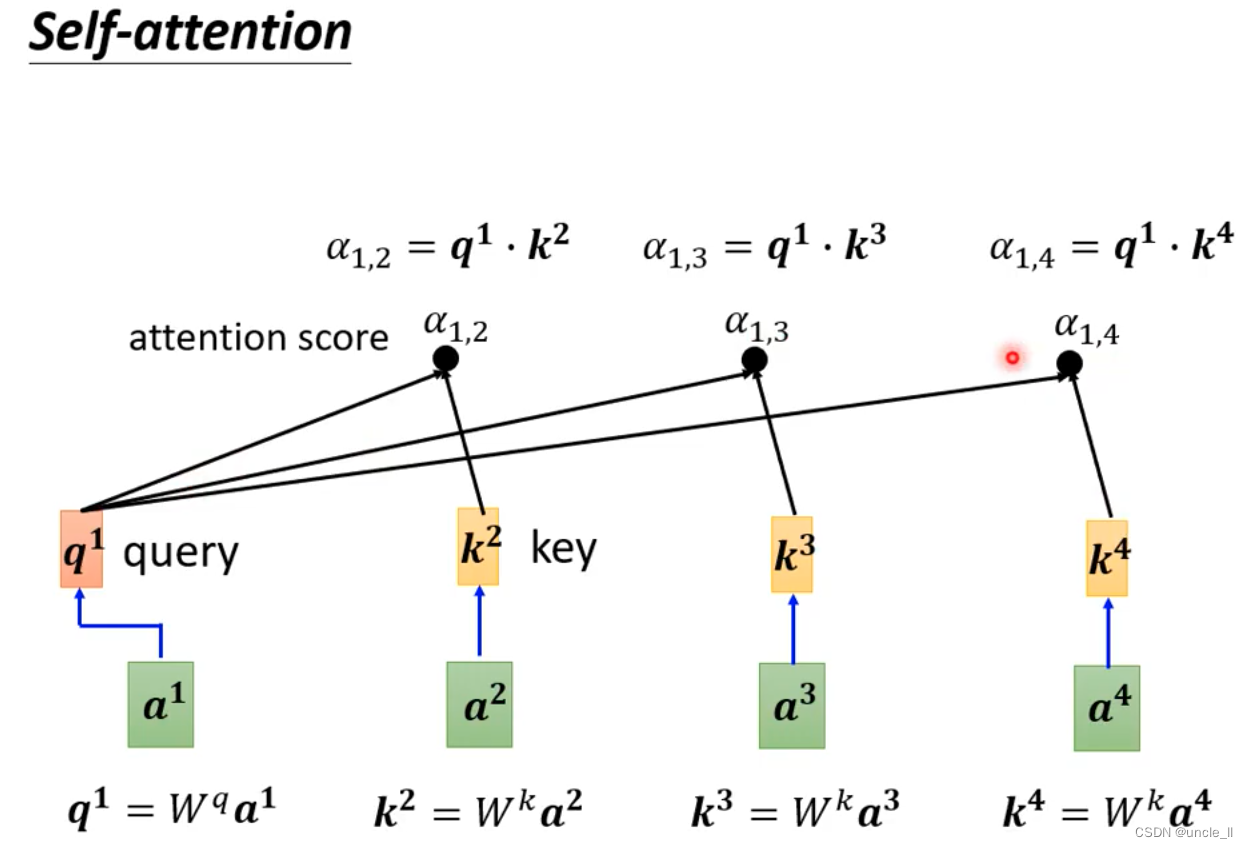
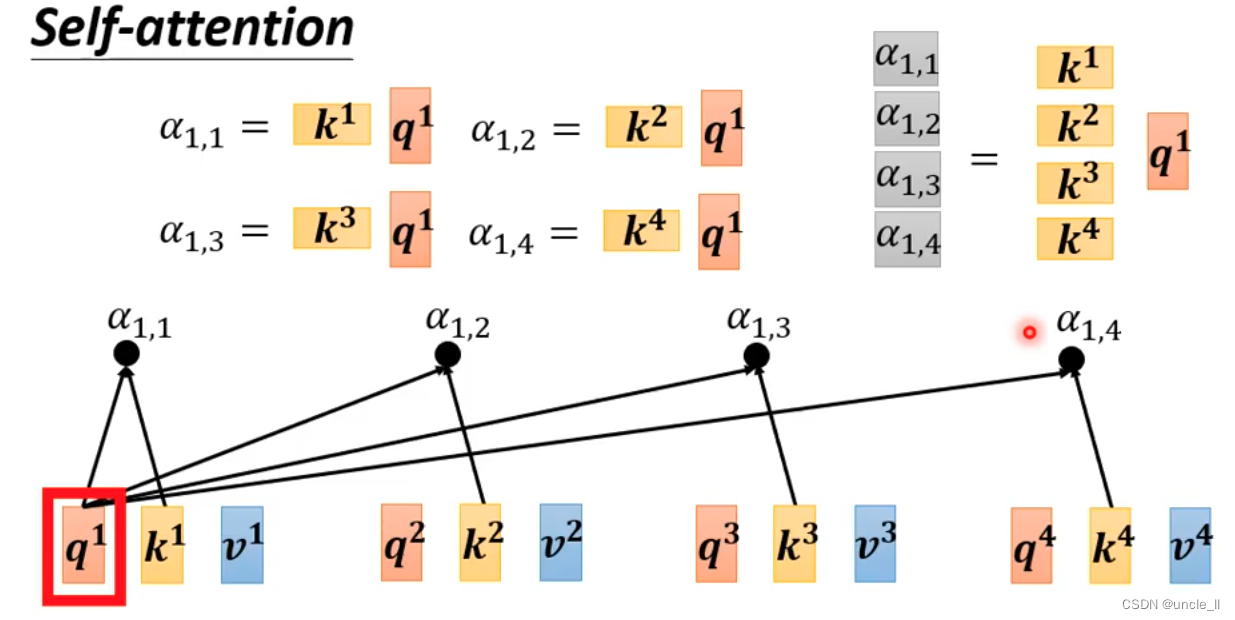
- 第一步:找到与a1相关的向量, a表示两个向量的关联程度
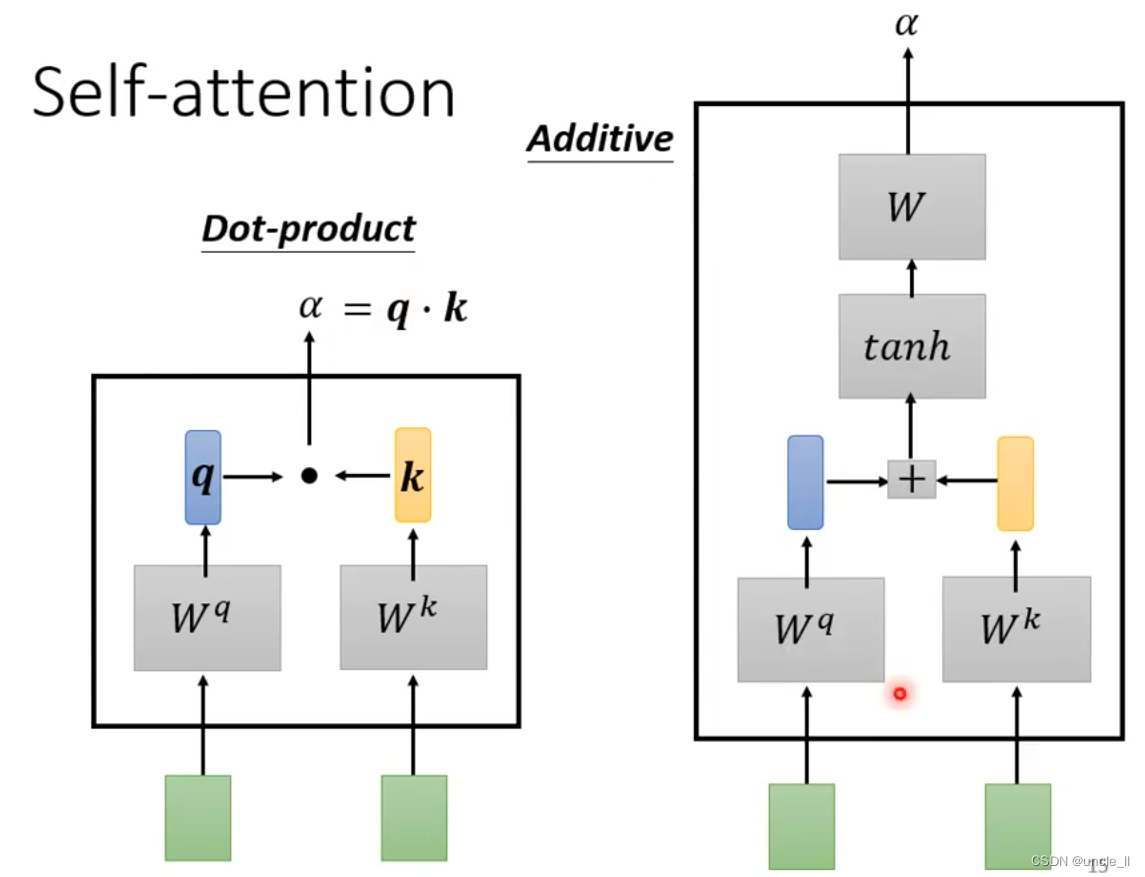
- 计算a:
- dot-product
- additive
自己跟自己也要计算关联度:
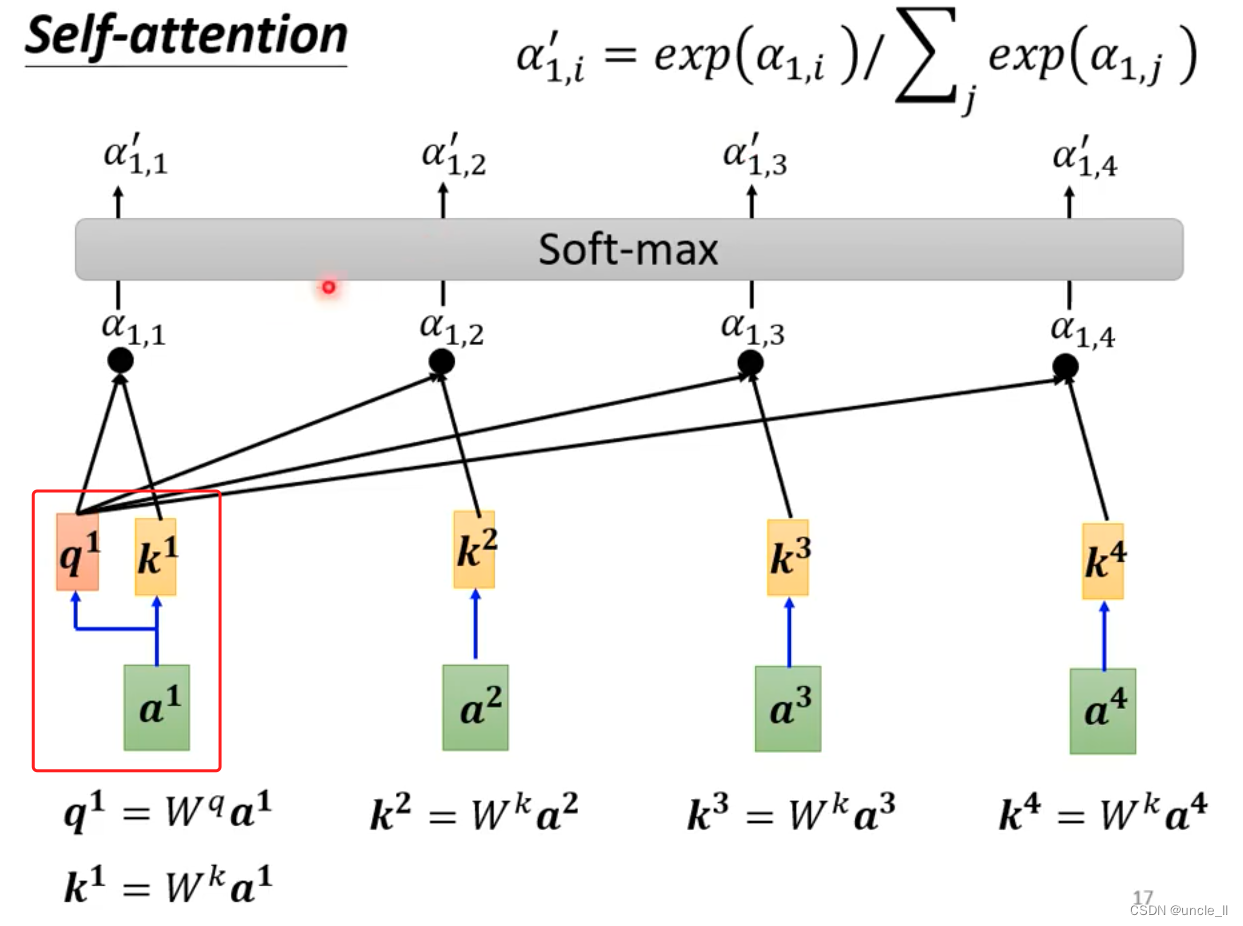
- 再计算softmax,得到每个的重要分数
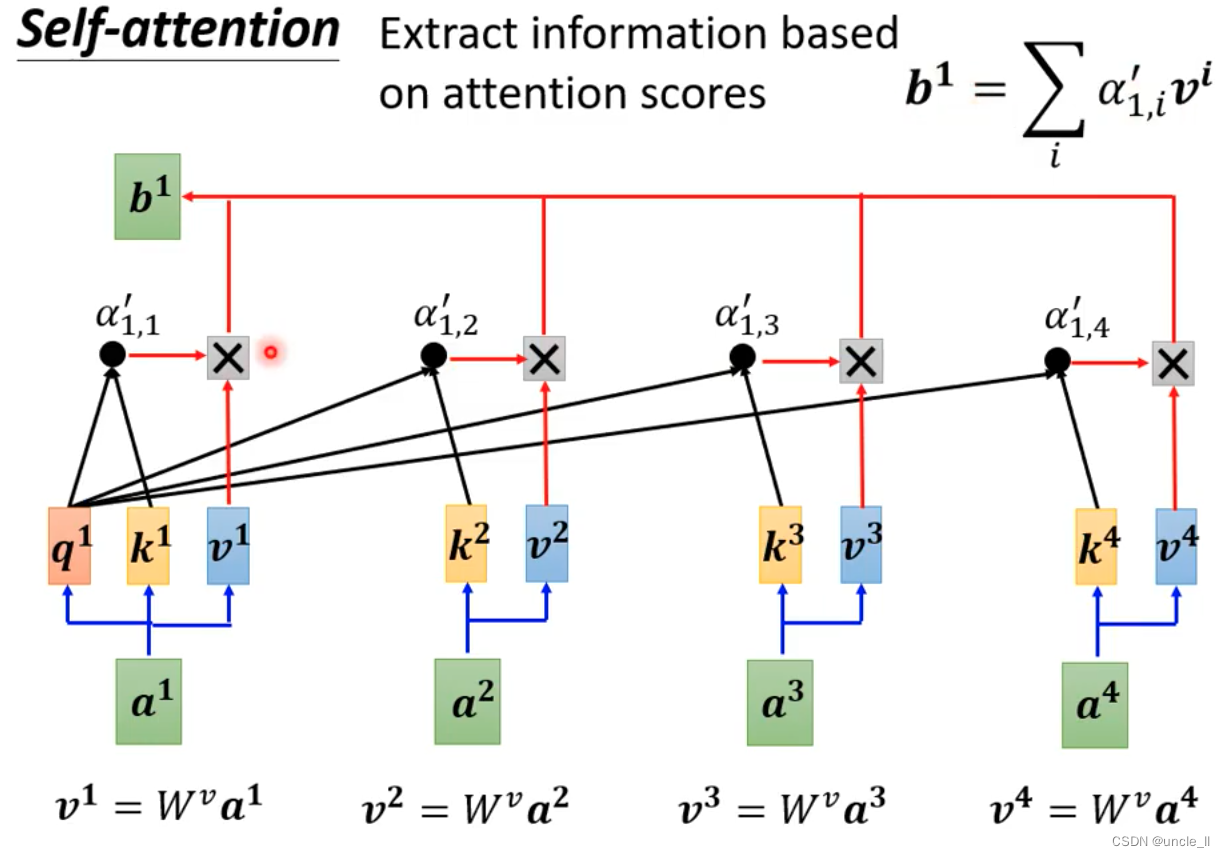
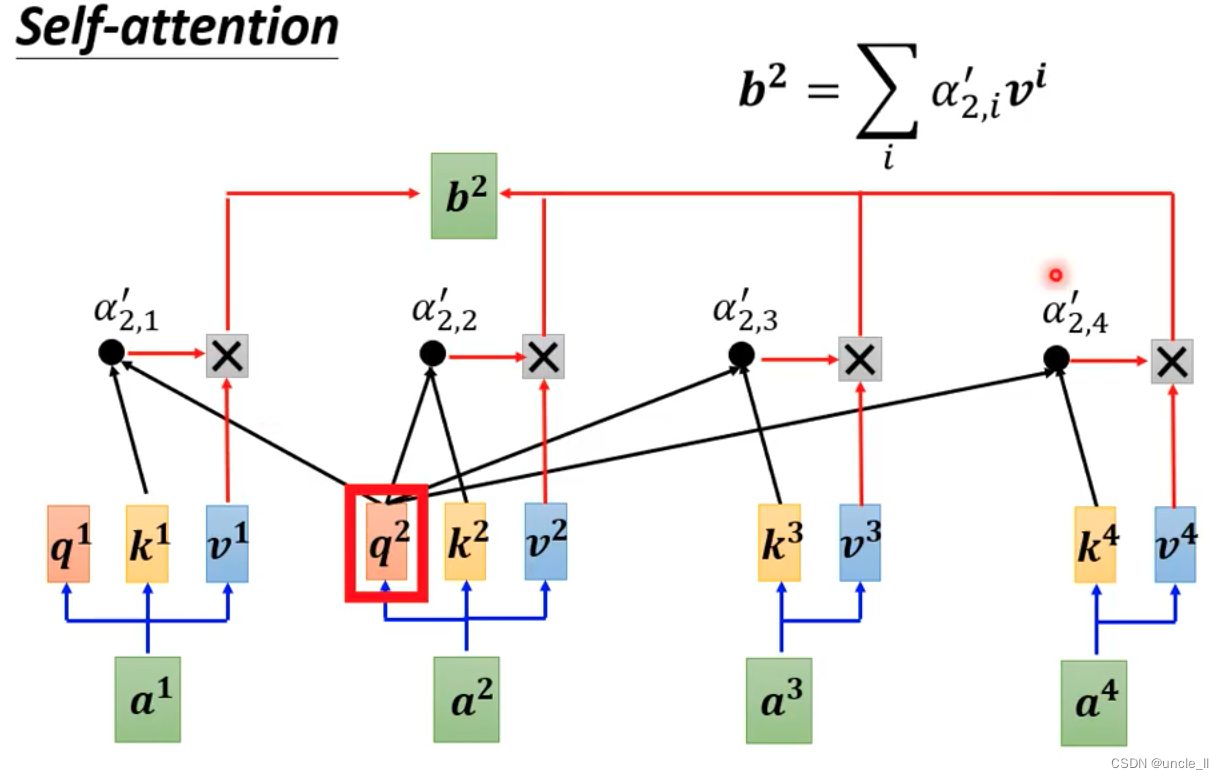
- 最后每个向量生成一个v,每个向量对应的权重与另外的向量v相乘累加作为最终那个向量的输出
用矩阵的形式表示:
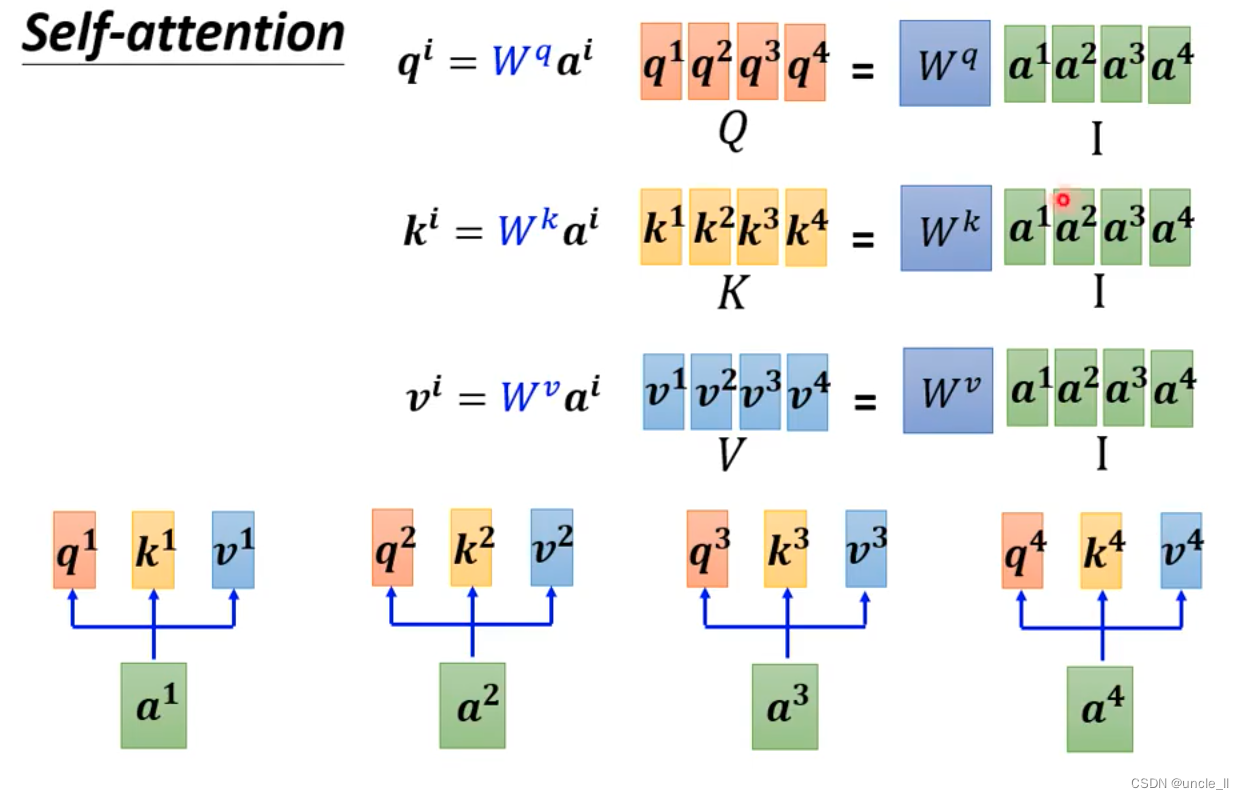
q与k计算attention分数,可以用矩阵与向量相乘表示:
多个向量的话组成一个矩阵,可以看作是矩阵和矩阵相乘:
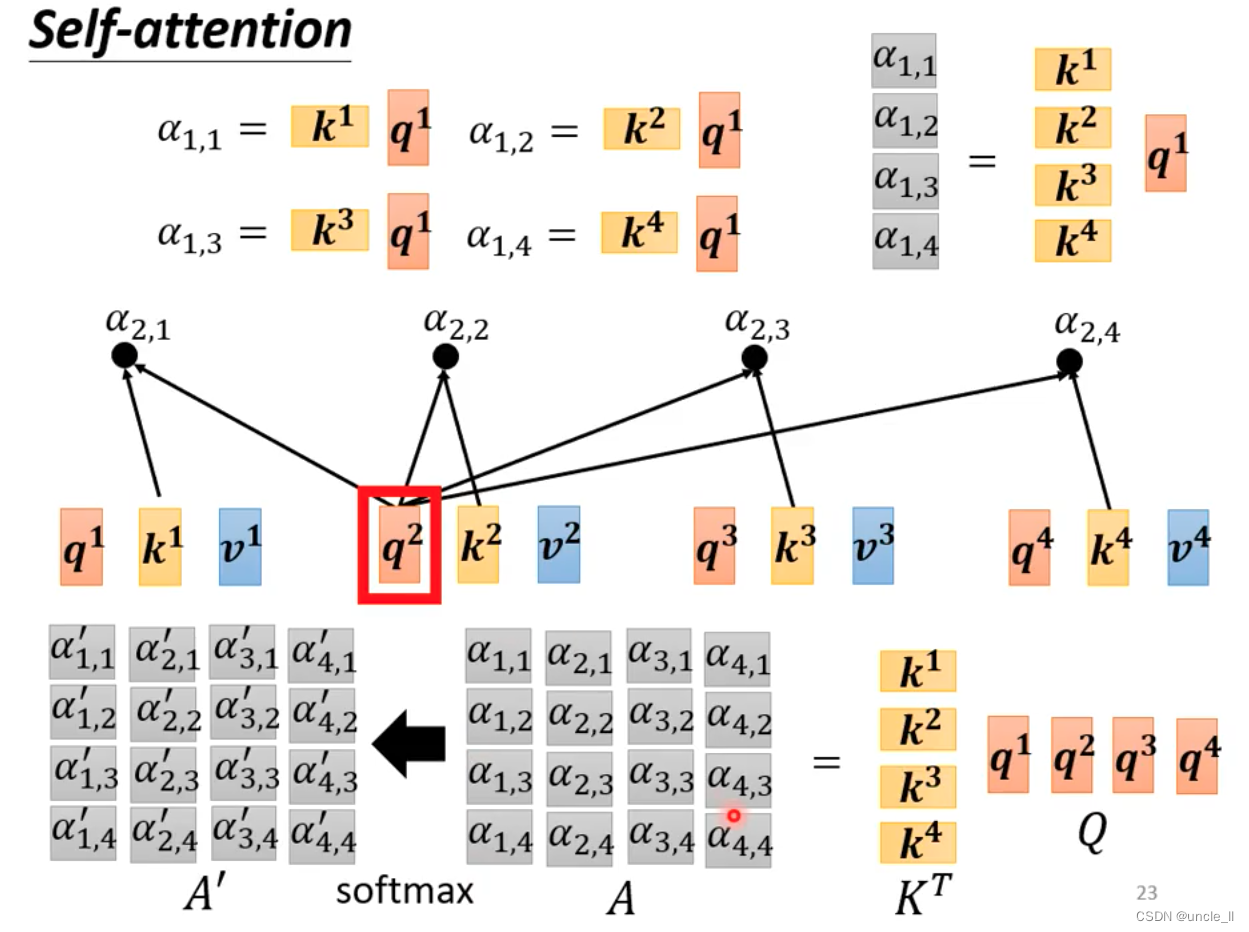
A = K T ∗ Q A = K^T * Q A=KT∗Q
A ′ = s o f t m a x ( A ) A' = softmax(A) A′=softmax(A)
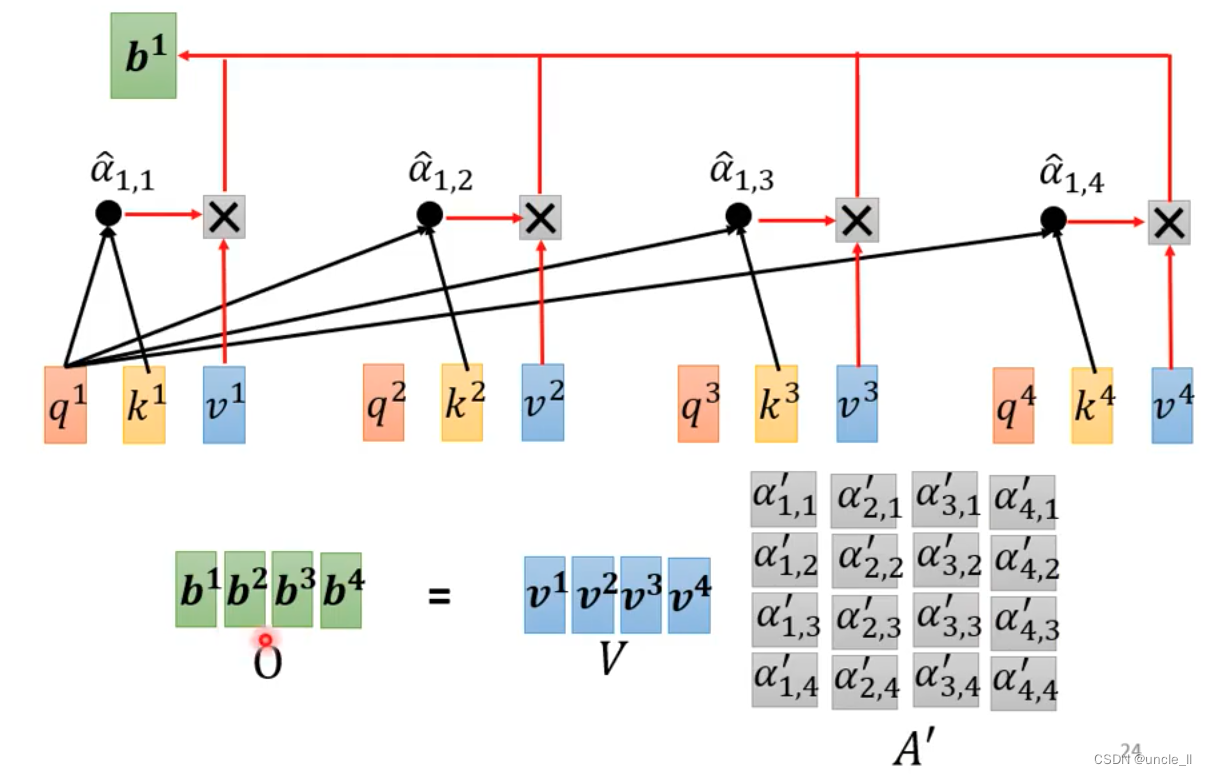
输出
O
=
V
∗
A
′
O = V * A'
O=V∗A′
总的过程如下:
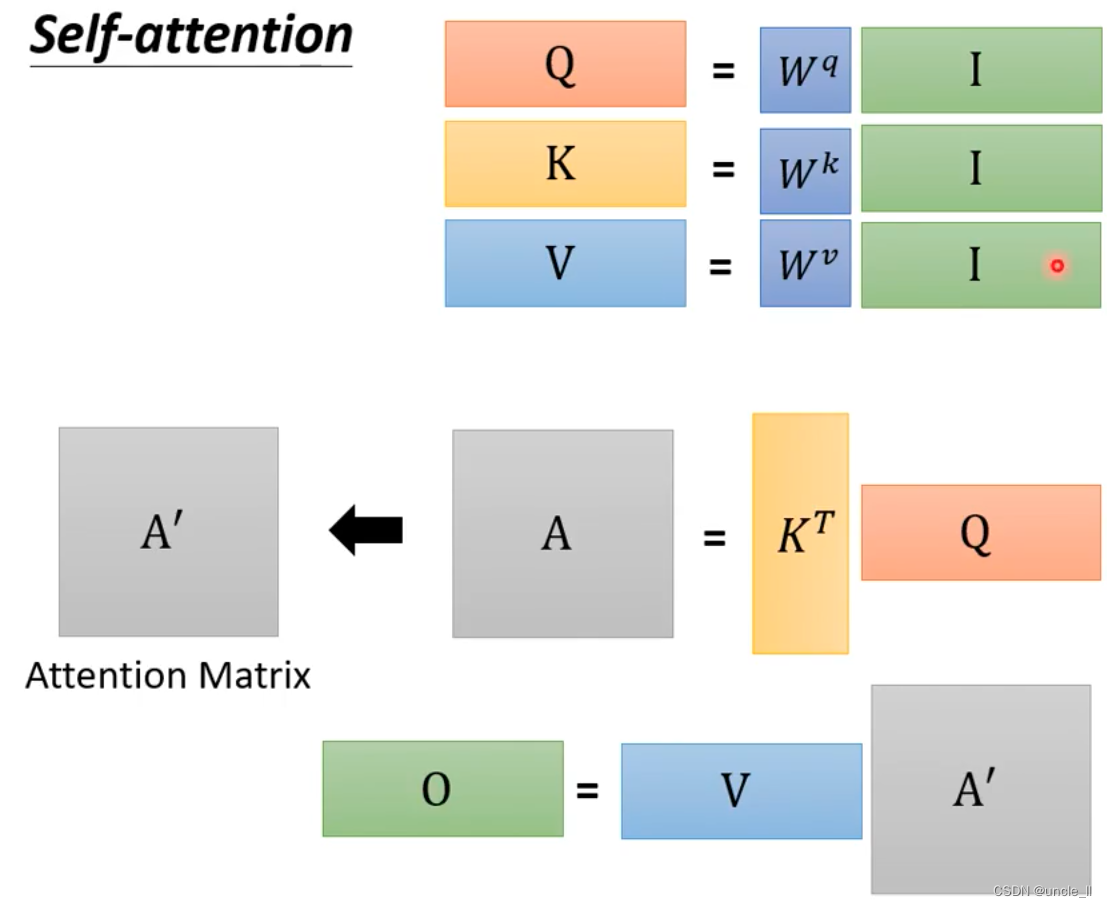
唯一要学习的参数就是
W
q
W^q
Wq,
W
k
W^k
Wk,
W
v
W^v
Wv
不同的变体
- multi-head self-attention
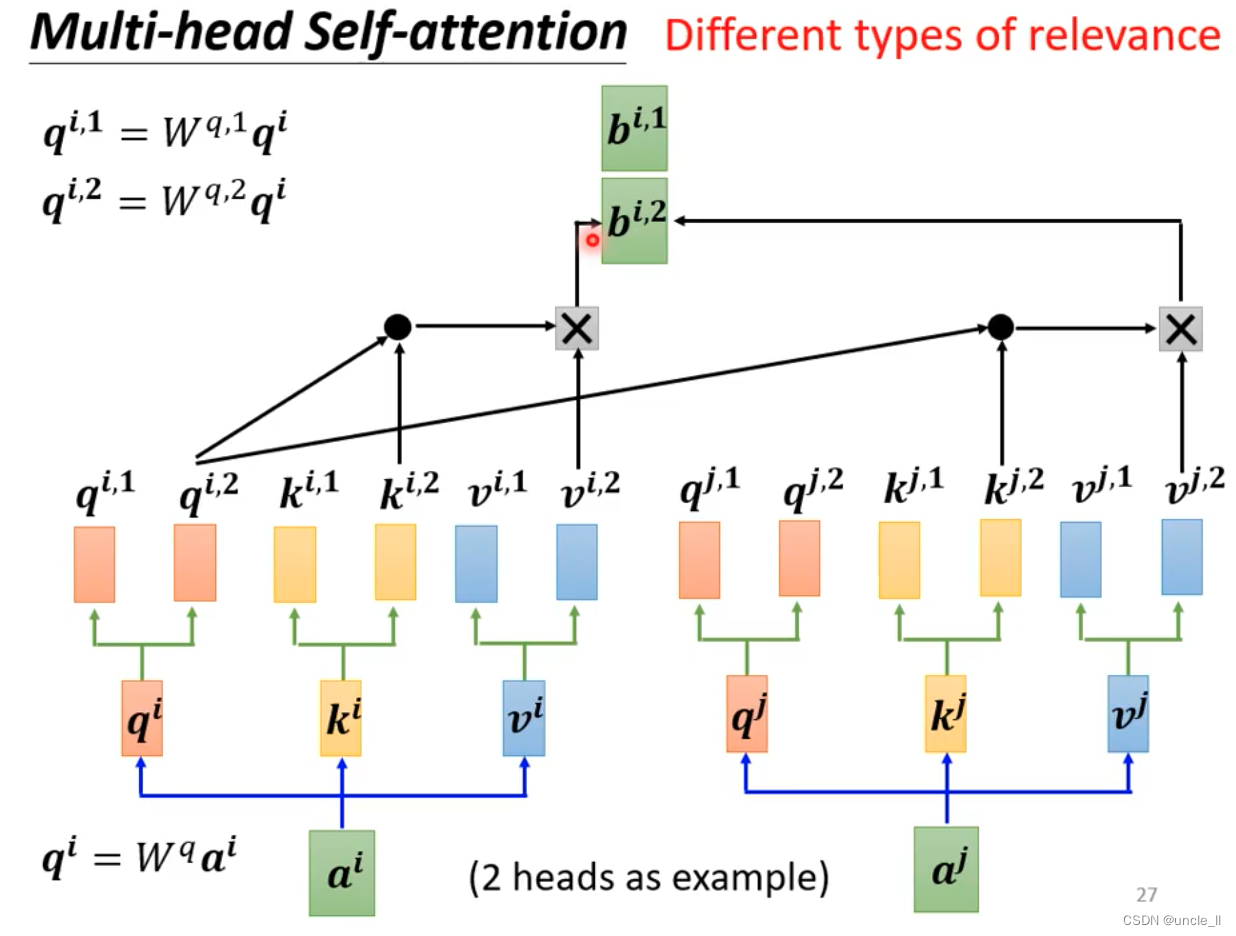
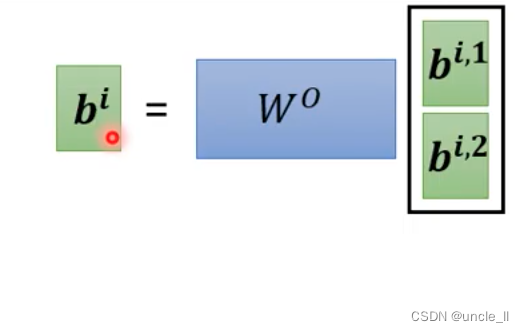
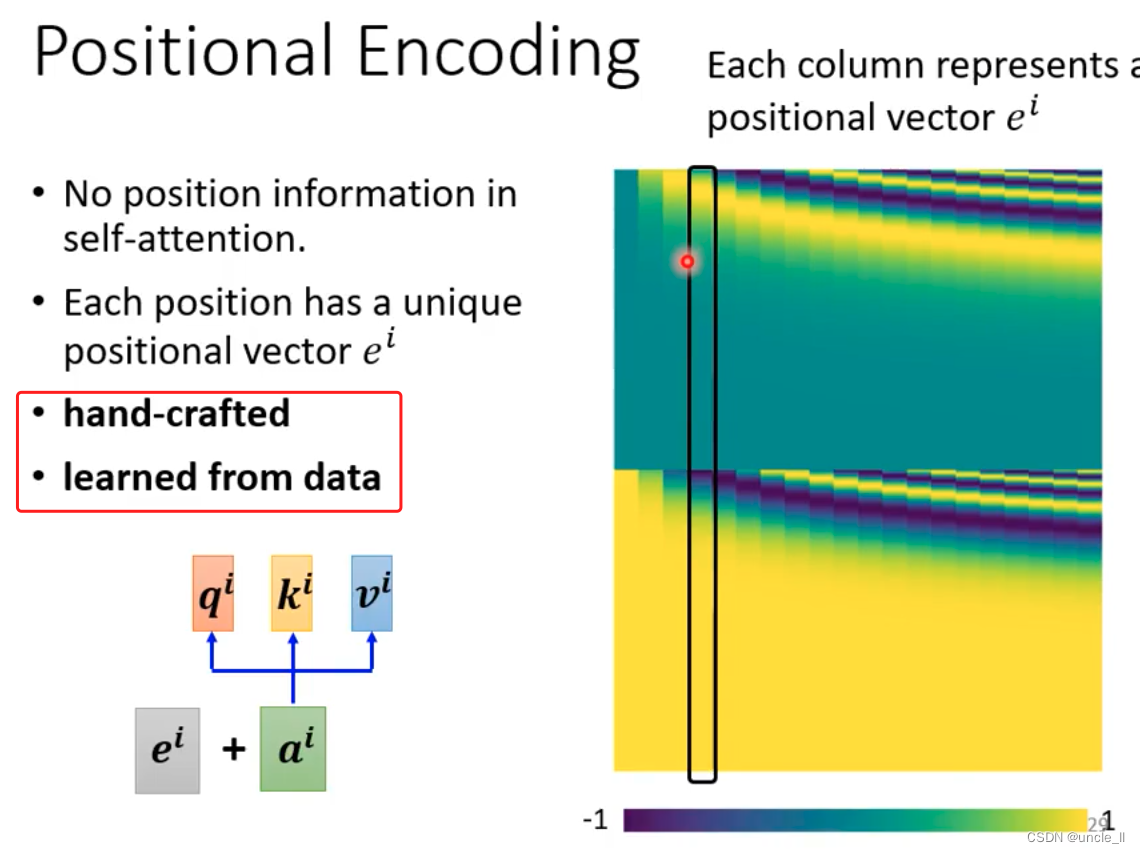
注意到self-attention 没有位置信息。
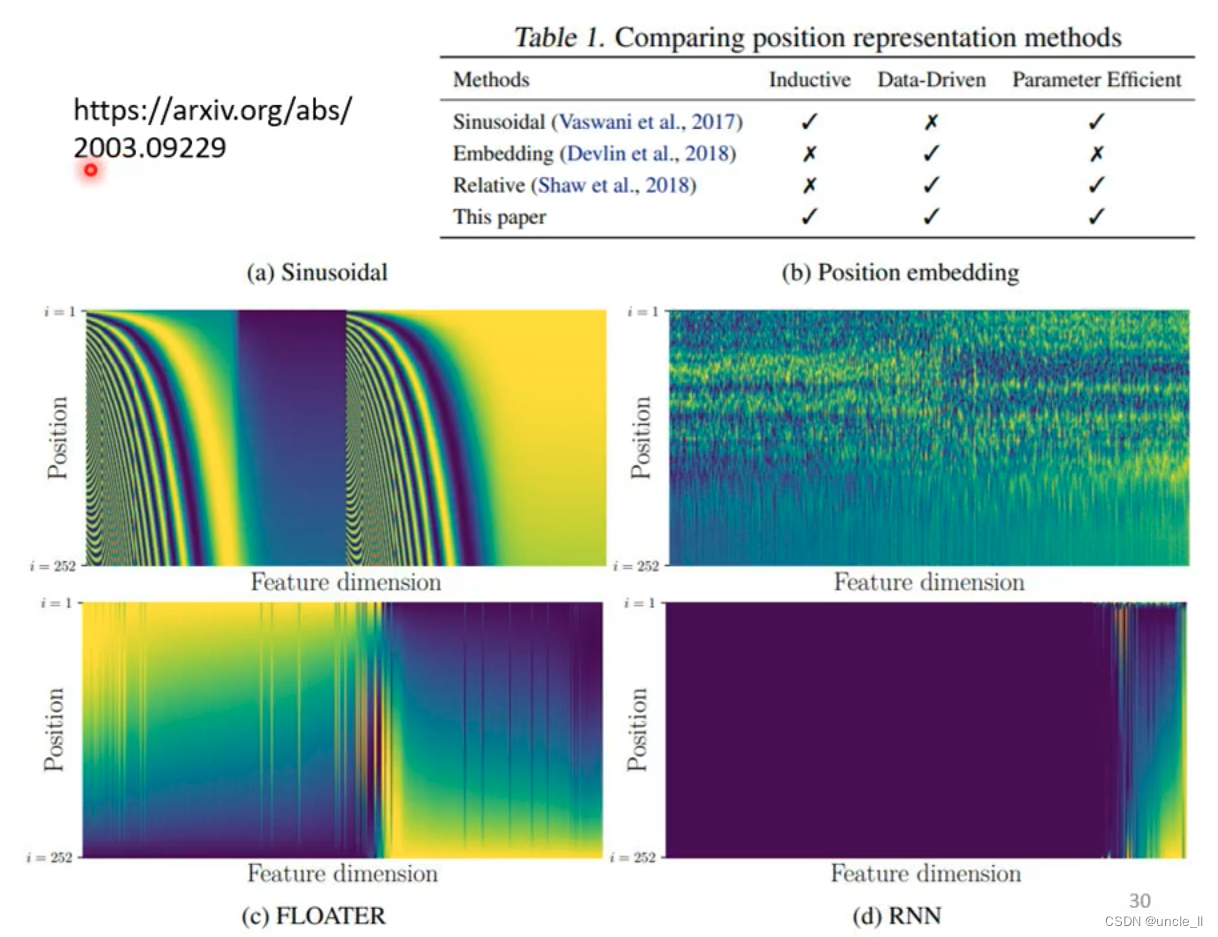
可以加入position编码信息(手工,或者学习得到)

应用
- 语音
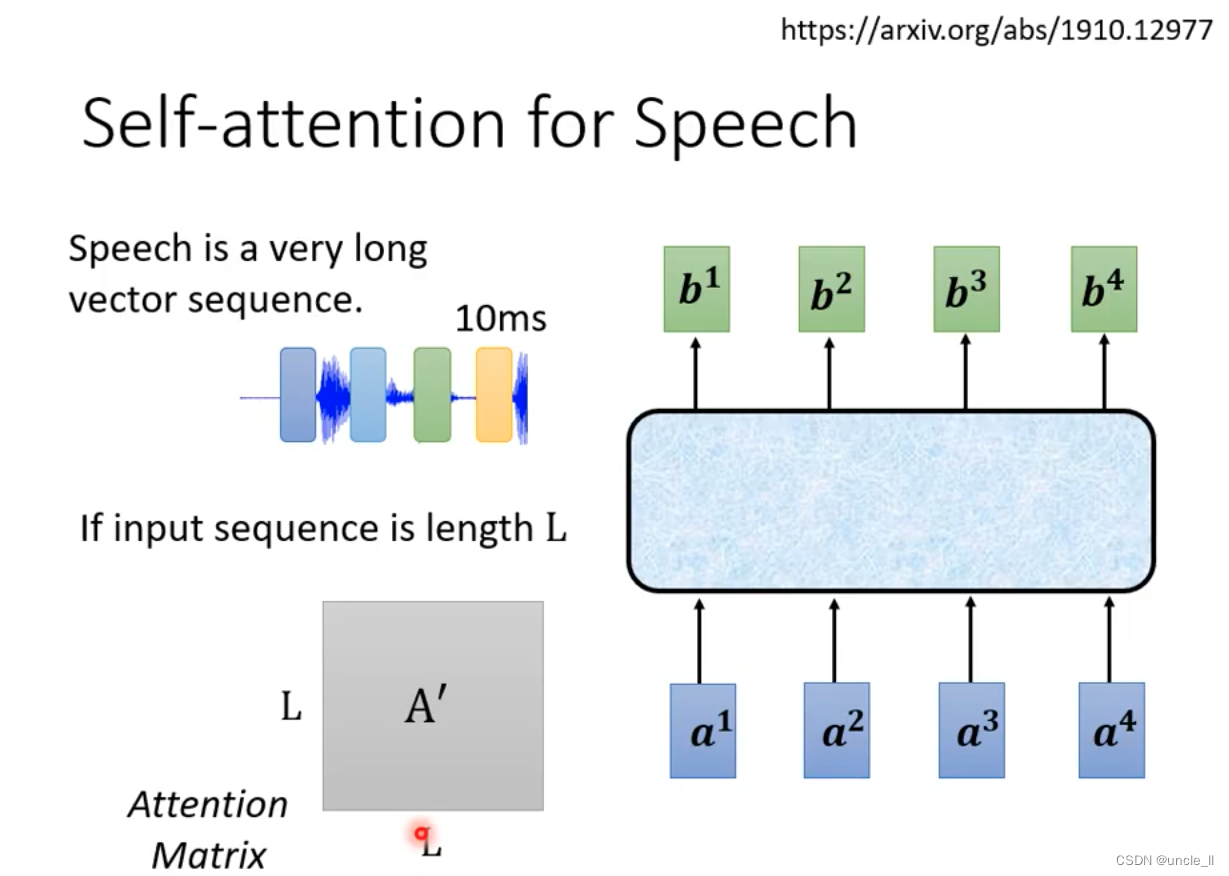
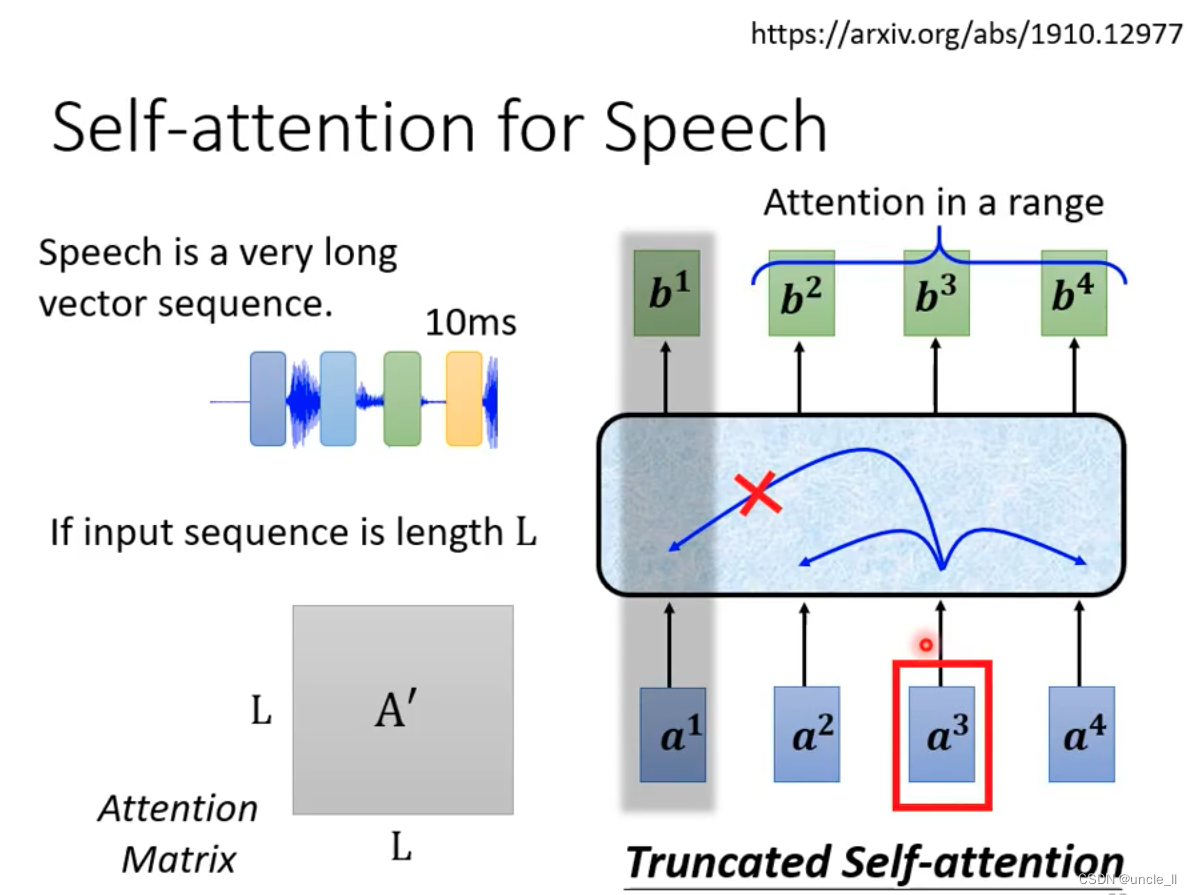
由于语音数据非常大,可以采用truncated方式只看很小的一个范围,一定范围之内的数据就能完成
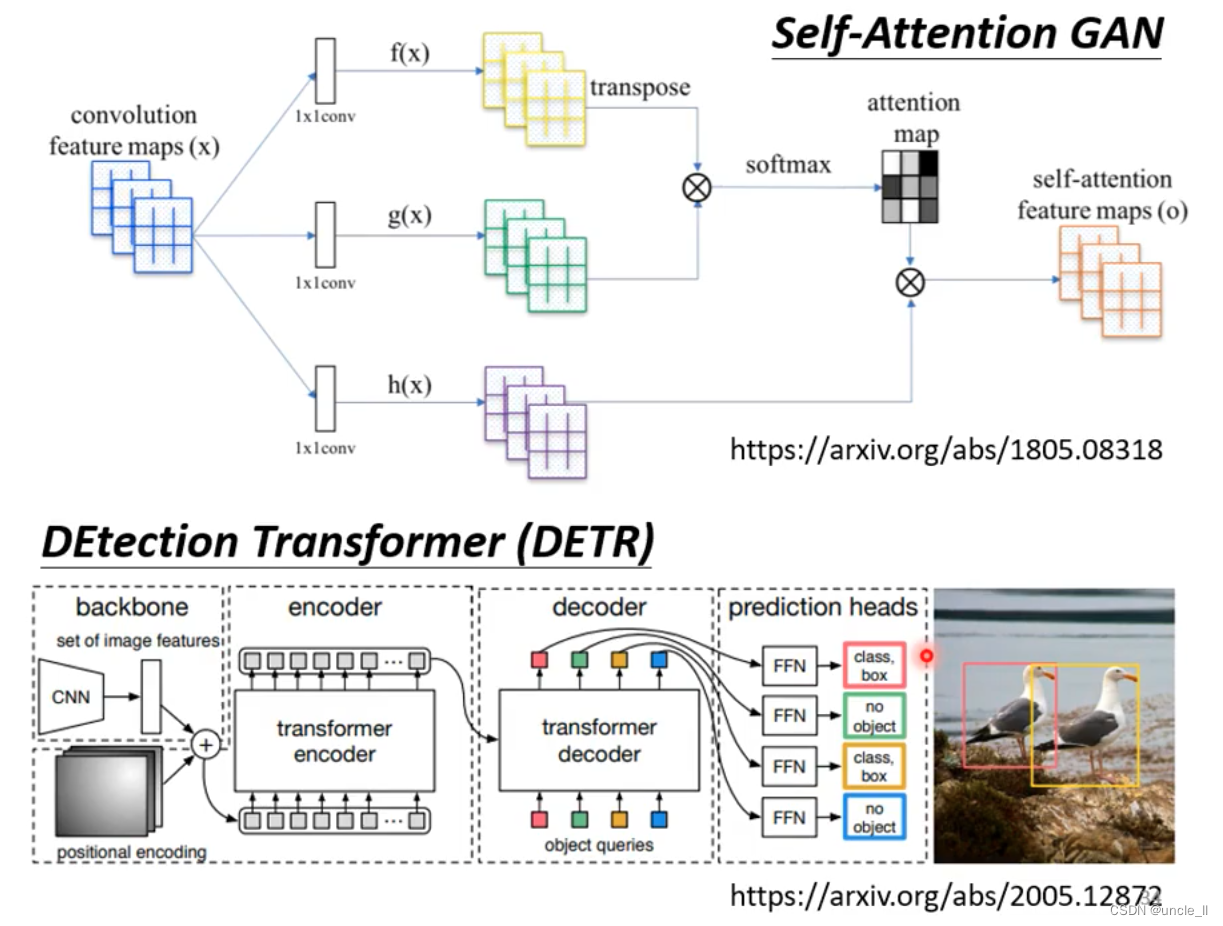
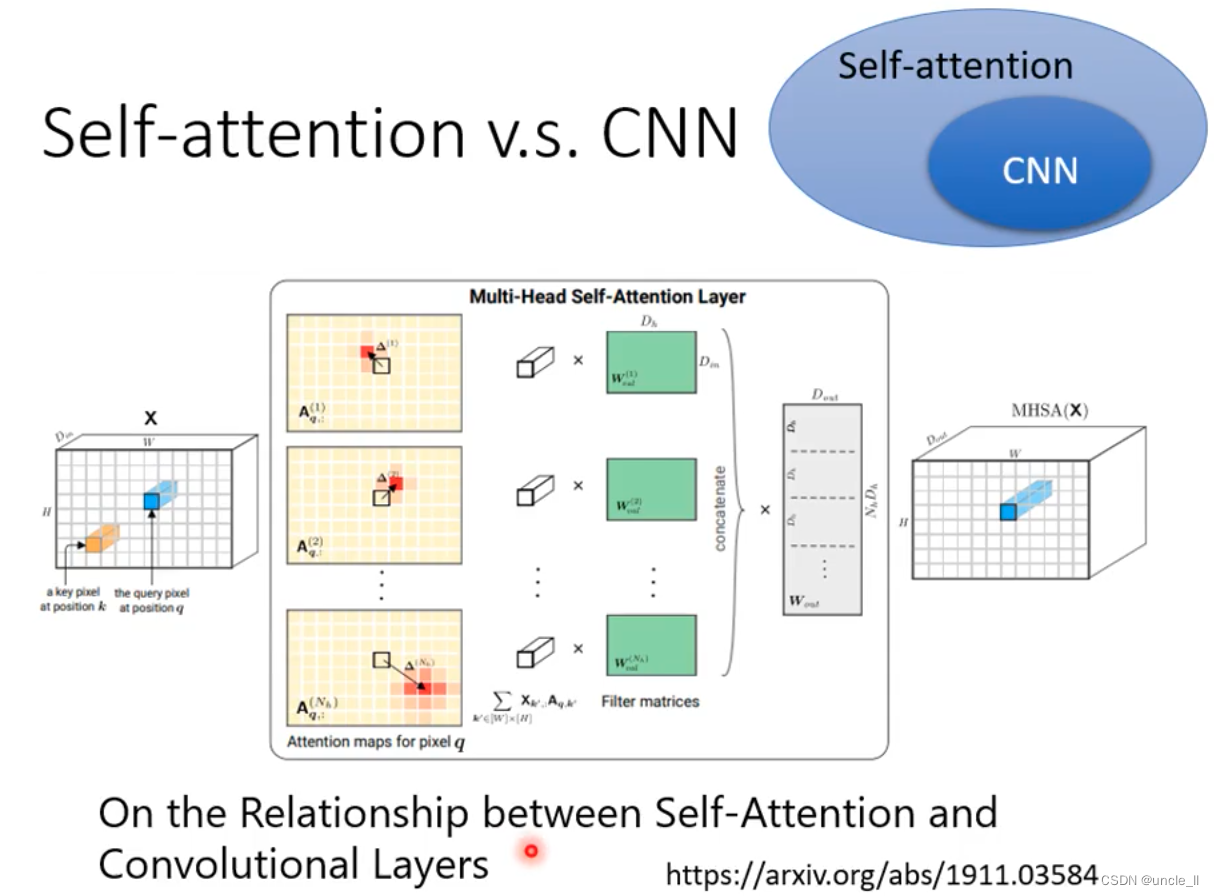
- 图像
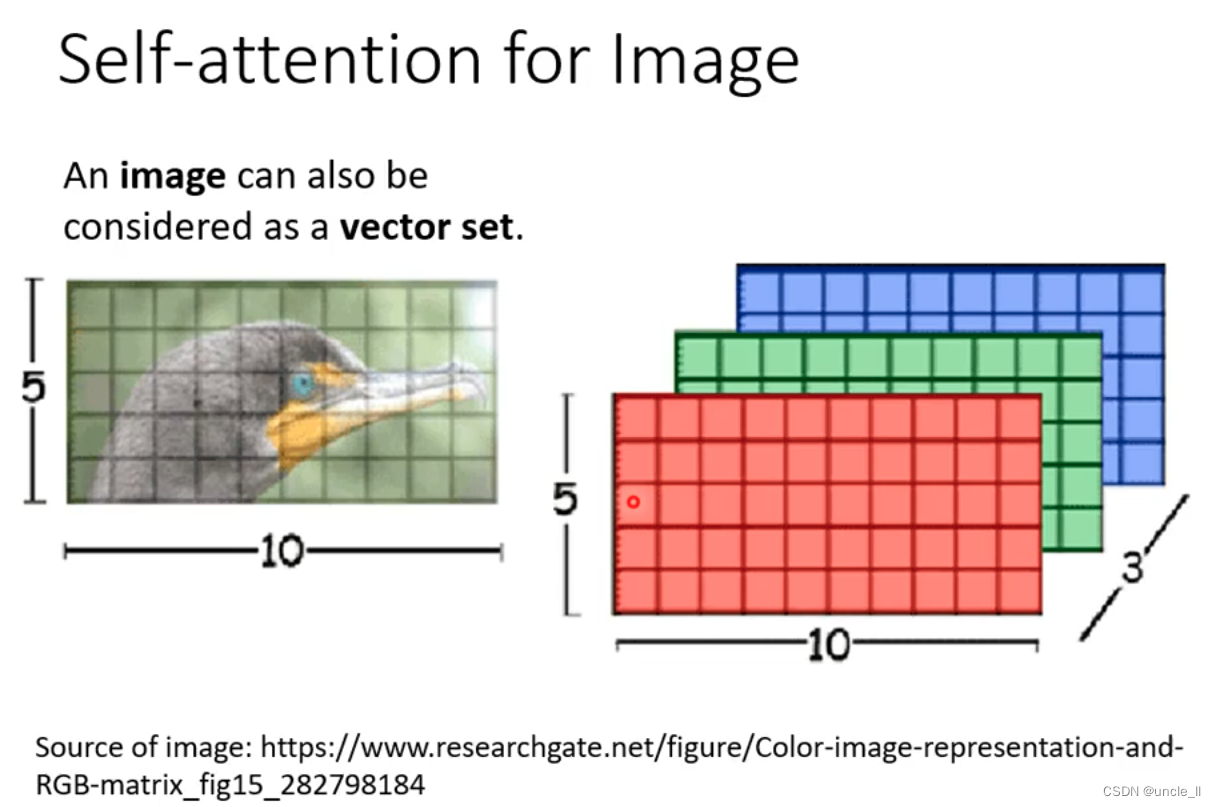
整张图片5103, 每个位置的pixel看作是一个三维向量,每张图看做是一个5*10的向量

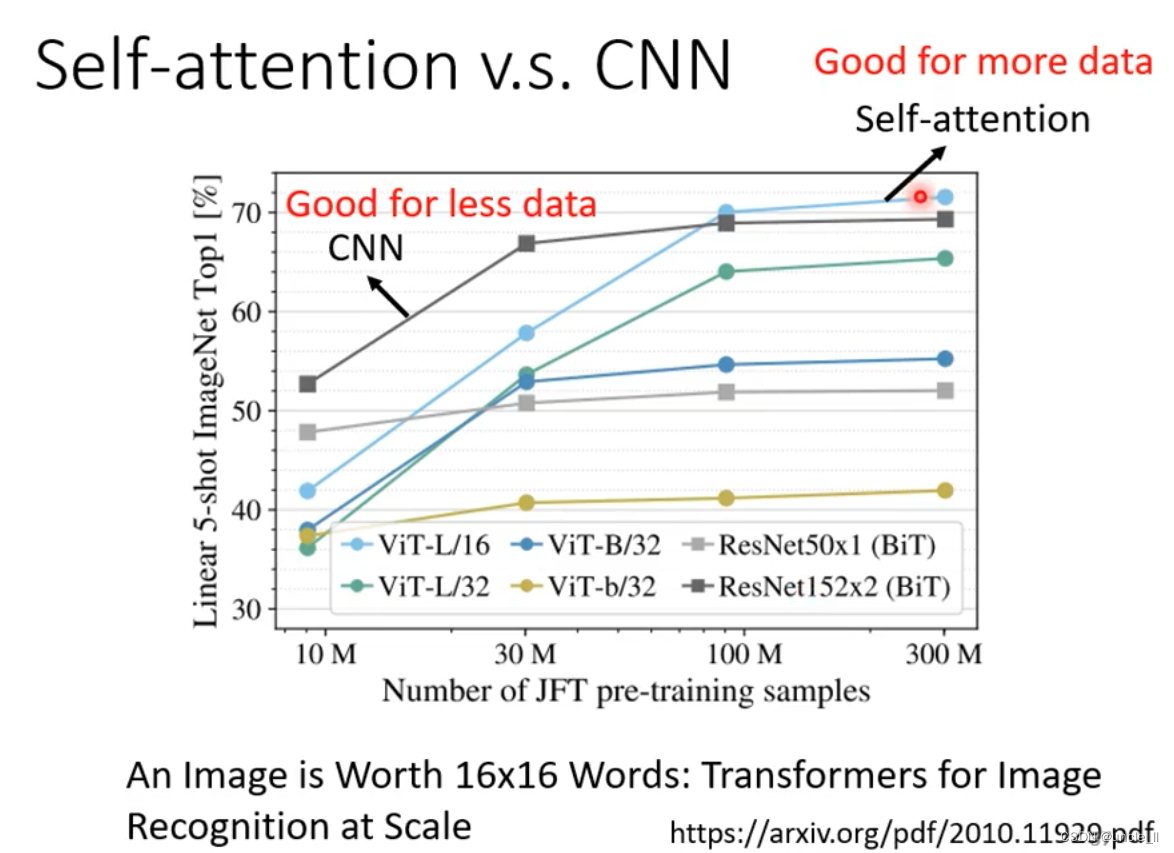
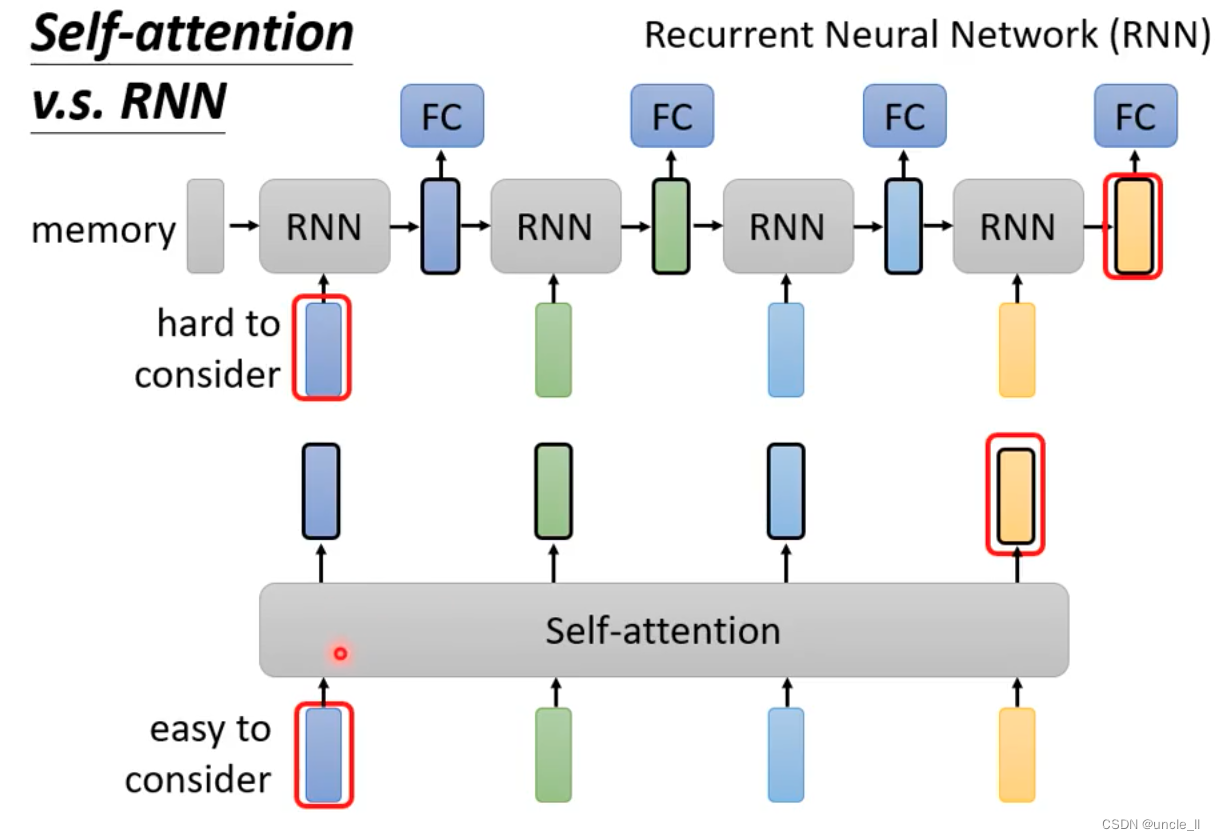
- rnn如果需要记得之前的信息的话需要一直保存到memory
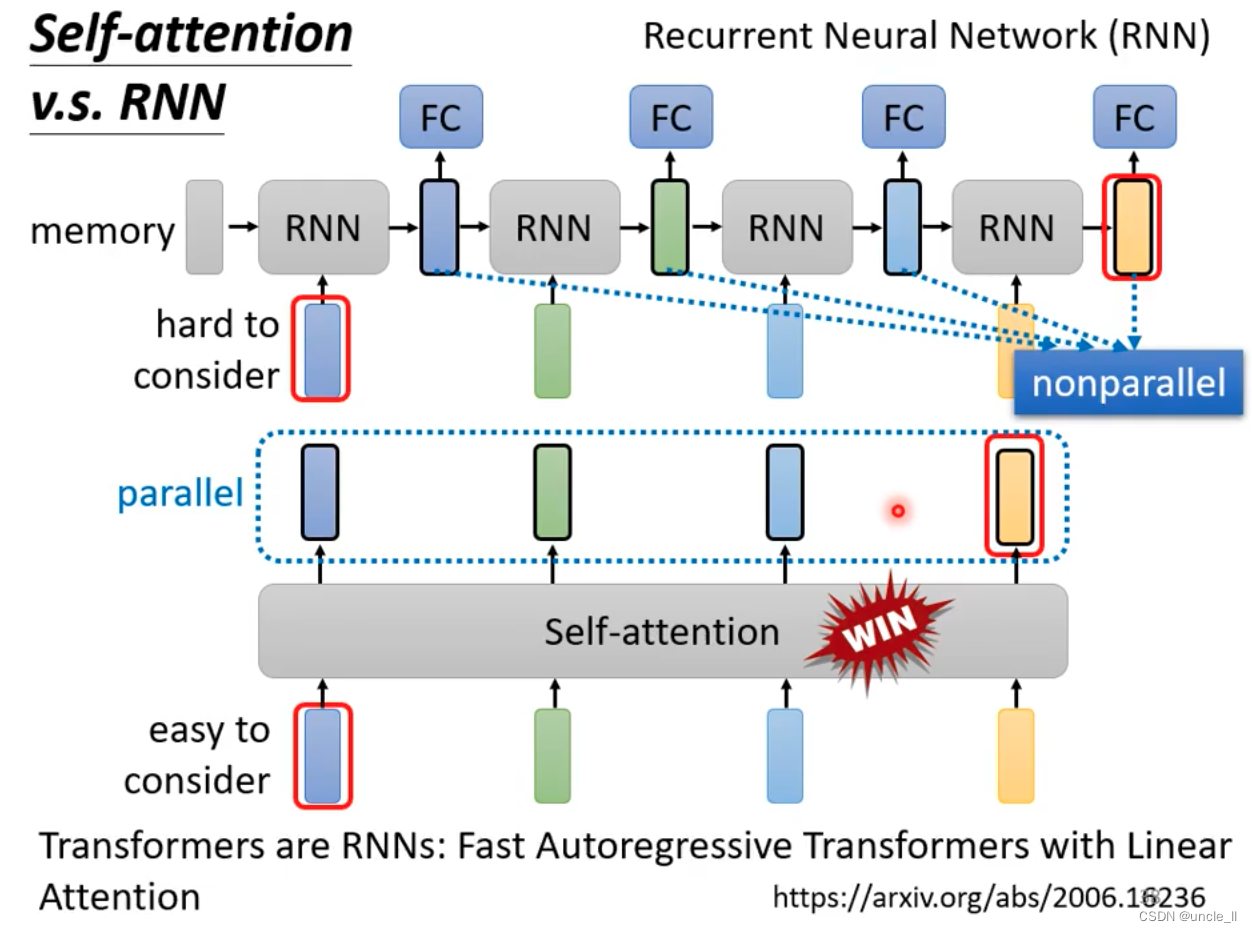
- rnn不能并行
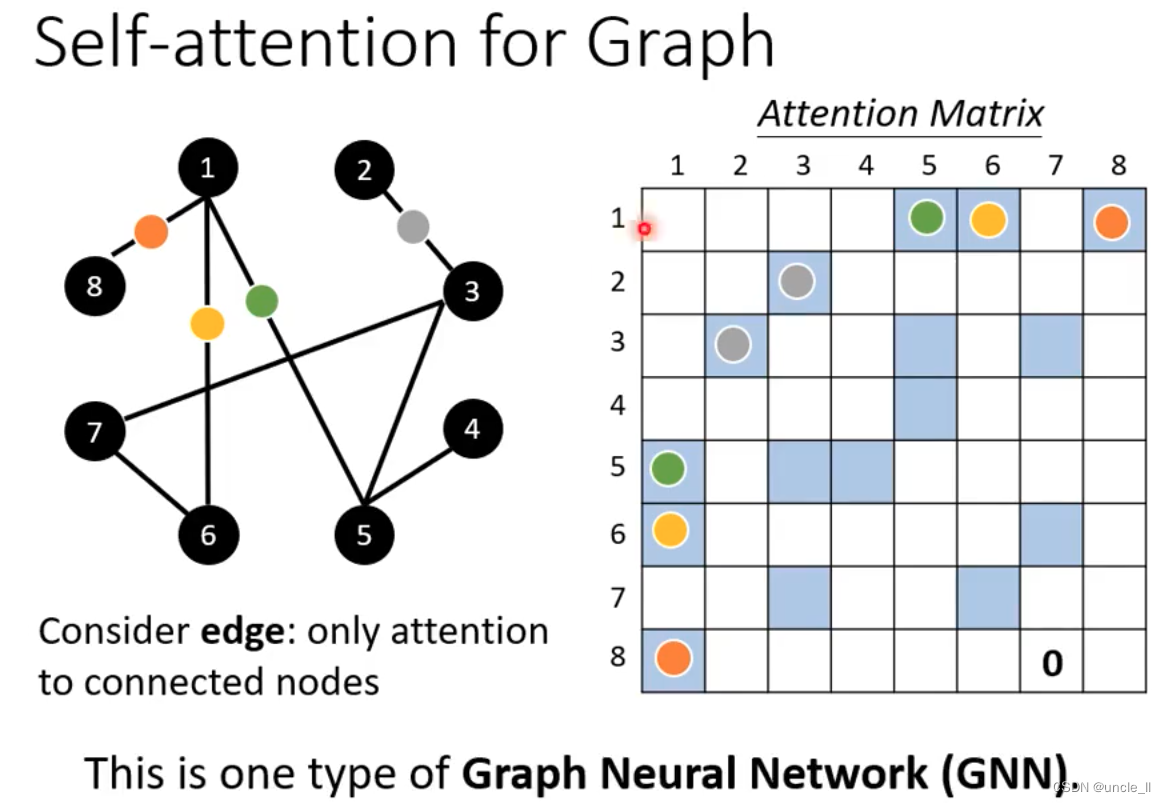
- 图









![[2023]自动化测试框架完整指南](https://img-blog.csdnimg.cn/775fd52423fd40afab66dc446f77ae89.png)