package com.streamdemo;
import java.util.ArrayList;
import java.util.List;
/**
* 体验Stream流
*
* 创建一个集合,存储多个字符串元素
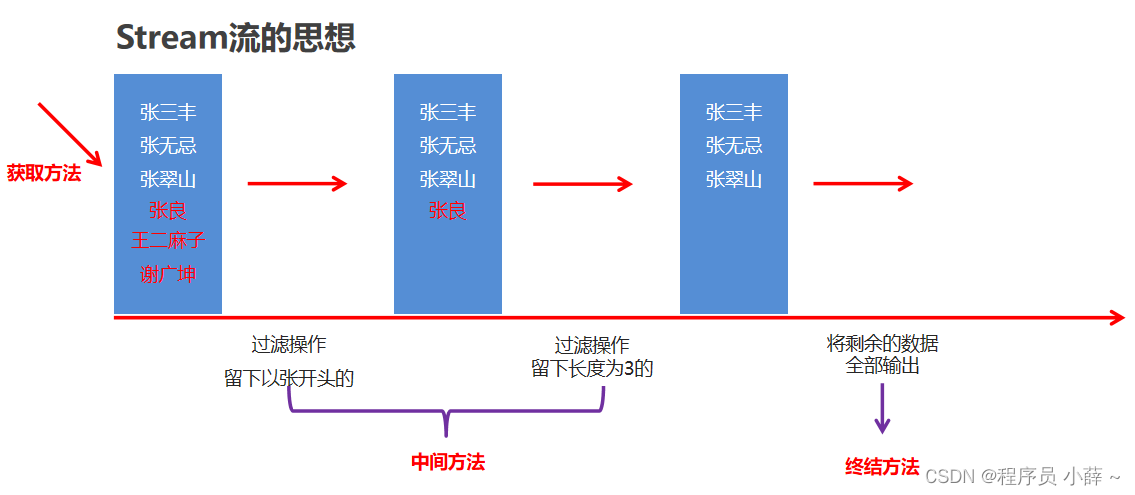
* "张三丰","张无忌","张翠山","王二麻子","张良","谢广坤"
*
* 把集合中所有以"张"开头的元素存储到一个新的集合
*
*
* 把"张"开头的集合中的长度为3的元素存储到一个新的集合
* 遍历上一步得到的集合
*
*/
public class MyStream1 {
public static void main(String[] args) {
//集合的批量添加
ArrayList<String> list1 = new ArrayList<>(List.of("张三丰","张无忌","张翠山","王二麻子","张良","谢广坤"));
//list.add()
//遍历list1把以张开头的元素添加到list2中。
ArrayList<String> list2 = new ArrayList<>();
for (String s : list1) {
if(s.startsWith("张")){
list2.add(s);
}
}
//遍历list2集合,把其中长度为3的元素,再添加到list3中。
ArrayList<String> list3 = new ArrayList<>();
for (String s : list2) {
if(s.length() == 3){
list3.add(s);
}
}
for (String s : list3) {
System.out.println(s);
}
System.out.println("=======================");
//Stream流
list1.stream().filter(s->s.startsWith("张"))
.filter(s->s.length() == 3)
.forEach(s-> System.out.println(s));
}
}张三丰
张无忌
张翠山
=======================
张三丰
张无忌
张翠山
Process finished with exit code 0



 一、list集合:
一、list集合:
private static void method1() {
ArrayList<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
// Stream<String> stream = list.stream();
// stream.forEach(s-> System.out.println(s));
list.stream().forEach(s-> System.out.println(s));
}
}
二、HashMap集合:
private static void method2() {
HashMap<String,Integer> hm = new HashMap<>();
hm.put("zhangsan",23);
hm.put("lisi",24);
hm.put("wangwu",25);
hm.put("zhaoliu",26);
hm.put("qianqi",27);
//双列集合不能直接获取Stream流
//keySet
//先获取到所有的键
//再把这个Set集合中所有的键放到Stream流中
//hm.keySet().stream().forEach(s-> System.out.println(s));
//entrySet
//先获取到所有的键值对对象
//再把这个Set集合中所有的键值对对象放到Stream流中
hm.entrySet().stream().forEach(s-> System.out.println(s));
}lisi=24
qianqi=27
zhaoliu=26
zhangsan=23
wangwu=25
Process finished with exit code 0
private static void method2() {
HashMap<String,Integer> hm = new HashMap<>();
hm.put("zhangsan",23);
hm.put("lisi",24);
hm.put("wangwu",25);
hm.put("zhaoliu",26);
hm.put("qianqi",27);
//双列集合不能直接获取Stream流
//keySet
//先获取到所有的键
//再把这个Set集合中所有的键放到Stream流中
hm.keySet().stream().forEach(s-> System.out.println(s));
//entrySet
//先获取到所有的键值对对象
//再把这个Set集合中所有的键值对对象放到Stream流中
//hm.entrySet().stream().forEach(s-> System.out.println(s));
}
private static void method1() {
ArrayList<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");lisi
qianqi
zhaoliu
zhangsan
wangwu
Process finished with exit code 0
三、数组
private static void method3() {
int [] arr = {1,2,3,4,5};
Arrays.stream(arr).forEach(s-> System.out.println(s));
}
1
2
3
4
5
Process finished with exit code 0
四、同种数据类型的多个数据:
private static void method4() {
Stream.of(1,2,3,4,5,6,7,8).forEach(s-> System.out.println(s));
}1
2
3
4
5
6
7
8
Process finished with exit code 0
package com.streamdemo;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.stream.Stream;
/**
* Stream流的获取
单列集合 : 集合对象.stream();
双列集合 : 不能直接获取,需要间接获取
集合对象.keySet().stream();
集合对象.entrySet().stream();
数组 :
Arrays.stream(数组名);
同种数据类型的多个数据:
Stream.of(数据1,数据2,数据3......);
*/
public class MyStream2 {中间方法-filter:

package com.streamdemo;
import java.util.ArrayList;
/**
* Stream流的中间方法
*/
public class MyStream3 {
public static void main(String[] args) {
// Stream<T> filter(Predicate predicate):过滤
// Predicate接口中的方法 boolean test(T t):对给定的参数进行判断,返回一个布尔值
ArrayList<String> list = new ArrayList<>();
list.add("张三丰");
list.add("张无忌");
list.add("张翠山");
list.add("王二麻子");
list.add("张良");
list.add("谢广坤");
//filter方法获取流中的 每一个数据.
//而test方法中的s,就依次表示流中的每一个数据.
//我们只要在test方法中对s进行判断就可以了.
//如果判断的结果为true,则当前的数据留下
//如果判断的结果为false,则当前数据就不要.
// list.stream().filter(
// new Predicate<String>() {
// @Override
// public boolean test(String s) {
// boolean result = s.startsWith("张");
// return result;
// }
// }
// ).forEach(s-> System.out.println(s));
//因为Predicate接口中只有一个抽象方法test
//所以我们可以使用lambda表达式来简化
// list.stream().filter(
// (String s)->{
// boolean result = s.startsWith("张");
// return result;
// }
// ).forEach(s-> System.out.println(s));
list.stream().filter(s ->s.startsWith("张")).forEach(s-> System.out.println(s));
}
}
张三丰
张无忌
张翠山
张良
Process finished with exit code 0
filter方法:
package com.Teacher.demo02_Stream;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import java.util.stream.Stream;
public class MyStream2 {
public static void main(String[] args) {
// 当使用流对象调用方法大的时候,建议使用链式编程
// 因为每个状态的流对象只能使用1次;
Map<Integer,String> map = new HashMap<>();
map.put(1,"a");
map.put(2,"b");
map.put(3,"c");
map.put(4,"d");
// 获取流对象
Set<Map.Entry<Integer, String>> set = map.entrySet();
Stream<Map.Entry<Integer, String>> s1 = set.stream();
// 过滤出key大于1的数据
Stream<Map.Entry<Integer, String>> s2 = s1.filter(s -> {
// s表示的就是每一个键值对对象
return s.getKey() > 1;
});
/*
// 由于s1状态的流对象,在上面已经调用过一次方法了,不能再次调用方法了,如果需要继续过滤数据
应该使用s1对象过滤之后得出的新的流对象继续调用方法才是正确的;
s1.filter(s->{
// s表示的就是每一个键值对对象
return s.getKey()%2==0;
});
*/
s2.filter(s->{
// s表示的就是每一个键值对对象
return s.getKey()%2==0;
}).forEach(s-> System.out.println(s.getKey()+","+s.getValue()));
}
}
2,b
4,d
Process finished with exit code 0
package com.streamdemo;
import java.util.ArrayList;
import java.util.stream.Stream;
/**
* Stream流的中间方法
*/
public class MyStream4 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("张三丰");
list.add("张无忌");
list.add("张翠山");
list.add("王二麻子");
list.add("张良");
list.add("谢广坤");
list.add("谢广坤");
list.add("谢广坤");
list.add("谢广坤");
list.add("谢广坤");
//method1(list);
//method2(list);
//method3();
//method4(list);
}
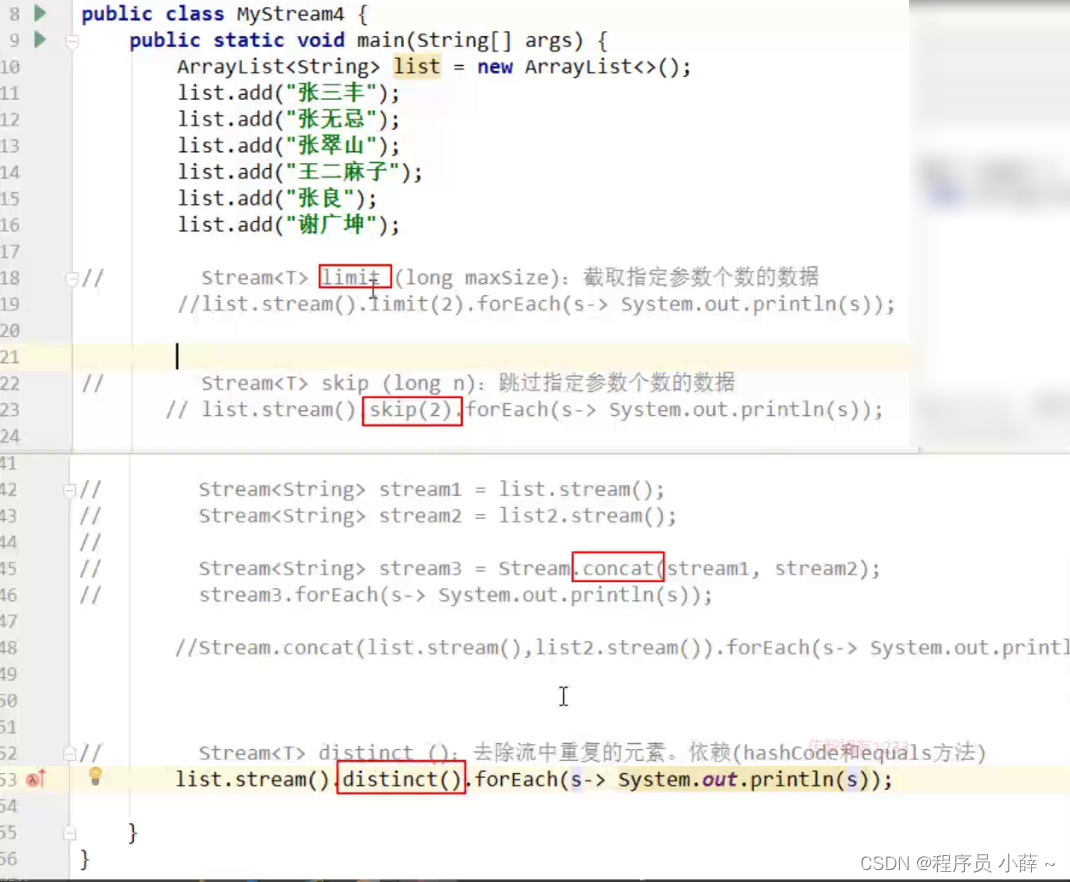
private static void method4(ArrayList<String> list) {
// Stream<T> distinct():去除流中重复的元素。依赖(hashCode和equals方法)
list.stream().distinct().forEach(s-> System.out.println(s));
}
private static void method3() {
//static <T> Stream<T> concat(Stream a, Stream b):合并a和b两个流为一个流
ArrayList<String> list = new ArrayList<>();
list.add("张三丰");
list.add("张无忌");
list.add("张翠山");
list.add("王二麻子");
list.add("张良");
list.add("谢广坤");
list.add("谢广坤");
list.add("谢广坤");
list.add("谢广坤");
list.add("谢广坤");
ArrayList<String> list2 = new ArrayList<>();
list2.add("张三丰");
list2.add("张无忌");
list2.add("张翠山");
list2.add("王二麻子");
list2.add("张良");
list2.add("谢广坤");
// Stream<String> stream1 = list.stream();
// Stream<String> stream2 = list2.stream();
//
// Stream<String> stream3 = Stream.concat(stream1, stream2);
// stream3.forEach(s -> System.out.println(s));
Stream.concat(list.stream(),list2.stream()).forEach(s-> System.out.println(s));
}
private static void method2(ArrayList<String> list) {
// Stream<T> skip(long n):跳过指定参数个数的数据
list.stream().skip(2).forEach(s-> System.out.println(s));
}
private static void method1(ArrayList<String> list) {
// Stream<T> limit(long maxSize):截取指定参数个数的数据
list.stream().limit(2).forEach(s-> System.out.println(s));
}
}

package com.streamdemo;
import java.util.ArrayList;
import java.util.function.Consumer;
/**
* Stream流的终结方法
*/
public class MyStream5 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("张三丰");
list.add("张无忌");
list.add("张翠山");
list.add("王二麻子");
list.add("张良");
list.add("谢广坤");
//method1(list);
// long count():返回此流中的元素数
long count = list.stream().count();
System.out.println(count);
}
private static void method1(ArrayList<String> list) {
// void forEach(Consumer action):对此流的每个元素执行操作
// Consumer接口中的方法 void accept(T t):对给定的参数执行此操作
//在forEach方法的底层,会循环获取到流中的每一个数据.
//并循环调用accept方法,并把每一个数据传递给accept方法
//s就依次表示了流中的每一个数据.
//所以,我们只要在accept方法中,写上处理的业务逻辑就可以了.
list.stream().forEach(
new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
}
);
System.out.println("====================");
//lambda表达式的简化格式
//是因为Consumer接口中,只有一个accept方法
list.stream().forEach(
(String s)->{
System.out.println(s);
}
);
System.out.println("====================");
//lambda表达式还是可以进一步简化的.
list.stream().forEach(s->System.out.println(s));
}
}
Stream流的收集方法:

package com.streamdemo;
import java.util.ArrayList;
import java.util.List;
/**
* Stream流的收集方法
* 练习:
* 定义一个集合,并添加一些整数1,2,3,4,5,6,7,8,9,10
* 将集合中的奇数删除,只保留偶数。
* 遍历集合得到2,4,6,8,10。
*/
public class MyStream6 {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
for (int i = 1; i <= 10; i++) {
list.add(i);
}
// list.stream().filter(
// (Integer i)->{
// return i % 2 == 0;
// }
// )
list.stream().filter(number -> number % 2 == 0).forEach(number -> System.out.println(number));
System.out.println("====================");
for (Integer integer : list) {
System.out.println(integer);
}
}
}
2
4
6
8
10
====================
1
2
3
4
5
6
7
8
9
10
Process finished with exit code 0
package com.streamdemo;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
/**
* Stream流的收集方法
* 练习:
* 定义一个集合,并添加一些整数1,2,3,4,5,6,7,8,9,10
* 将集合中的奇数删除,只保留偶数。
* 遍历集合得到2,4,6,8,10。
*/
public class MyStream7 {
public static void main(String[] args) {
ArrayList<Integer> list1 = new ArrayList<>();
for (int i = 1; i <= 10; i++) {
list1.add(i);
}
list1.add(10);
list1.add(10);
list1.add(10);
list1.add(10);
list1.add(10);
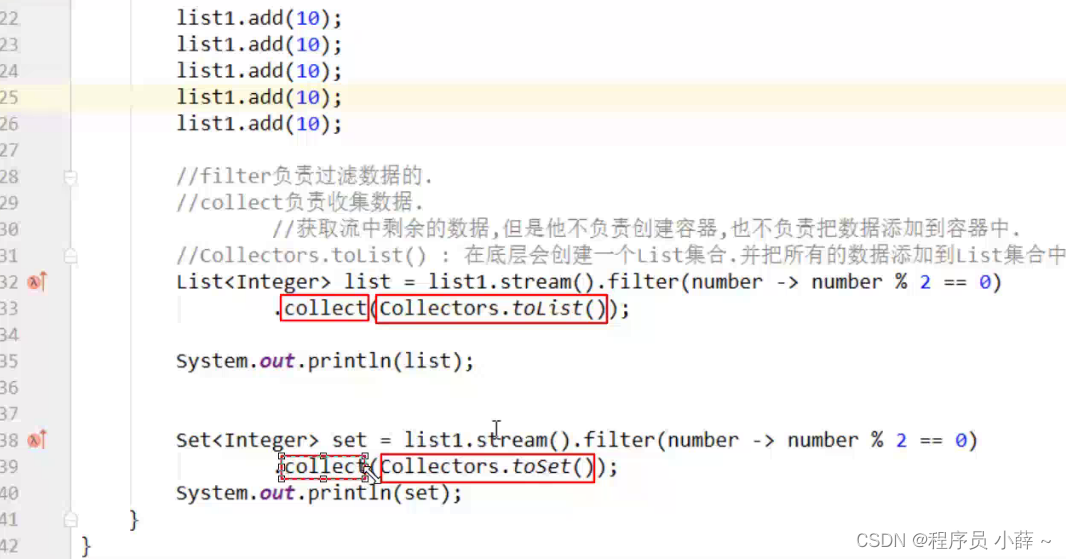
//filter负责过滤数据的.
//collect负责收集数据.
//获取流中剩余的数据,但是他不负责创建容器,也不负责把数据添加到容器中.
//Collectors.toList() : 在底层会创建一个List集合.并把所有的数据添加到List集合中.
List<Integer> list = list1.stream().filter(number -> number % 2 == 0)
.collect(Collectors.toList());//toList
System.out.println(list);
Set<Integer> set = list1.stream().filter(number -> number % 2 == 0)
.collect(Collectors.toSet());//toSet 去重
System.out.println(set);
}
}
[2, 4, 6, 8, 10, 10, 10, 10, 10, 10]
[2, 4, 6, 8, 10]
Process finished with exit code 0
查看API学习其他的


package com.streamdemo;
public class Actor {
private String name;
public Actor() {
}
public Actor(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Actor{" +
"name='" + name + '\'' +
'}';
}
}
package com.streamdemo;
import java.util.ArrayList;
import java.util.stream.Stream;
/**
* 现在有两个ArrayList集合,分别存储6名男演员名称和6名女演员名称,要求完成如下的操作
* 1.男演员只要名字为3个字的前两人
* 2.女演员只要姓杨的,并且不要第一个
* 3.把过滤后的男演员姓名和女演员姓名合并到一起
* 4.把上一步操作后的元素作为构造方法的参数创建演员对象,遍历数据
* 演员类Actor,里面有一个成员变量,一个带参构造方法,以及成员变量对应的get/set方法
*/
public class MyStream9 {
public static void main(String[] args) {
ArrayList<String> manList = new ArrayList<>();
manList.add("张国立");
manList.add("张晋");
manList.add("刘烨");
manList.add("郑伊健");
manList.add("徐峥");
manList.add("王宝强");
ArrayList<String> womanList = new ArrayList<>();
womanList.add("郑爽");
womanList.add("杨紫");
womanList.add("关晓彤");
womanList.add("张天爱");
womanList.add("杨幂");
womanList.add("赵丽颖");
//男演员只要名字为3个字的前两人
Stream<String> stream1 = manList.stream().filter(name -> name.length() == 3).limit(2);
//女演员只要姓杨的,并且不要第一个
Stream<String> stream2 = womanList.stream().filter(name -> name.startsWith("杨")).skip(1);
Stream.concat(stream1,stream2).forEach(name -> {
Actor actor = new Actor(name);
System.out.println(actor);
});
}
}
//将两个流中的数据合并后,将流中的数据从String类型,转成Actor类型
/*Stream.concat(stream1,stream2).forEach(name -> {
Actor actor = new Actor(name);
System.out.println(actor);
});*/
//将两个流中的数据合并后,将流中的数据从String类型,转成Actor类型
// list收集collect
//List<Actor> list = Stream.concat(stream1, stream2).map(s -> new Actor(s)).collect(Collectors.toList());//这是收集
//若不想收集forEach
Stream.concat(stream1, stream2).map(s -> new Actor(s)).forEach(s -> System.out.println(s));Actor{name='张国立'}
Actor{name='郑伊健'}
Actor{name='杨幂'}
Process finished with exit code 0
二、FiLe和IO流:
File:






private static void method1() {
//File(String pathname) 通过将给定的路径名字符串转换为抽象路径名来创建新的File实例
String path = "E:\\wenjian\\a.txt";
File file = new File(path);
//问题:为什么要把字符串表示形式的路径变成File对象?
//就是为了使用File类里面的方法.
} private static void method2() {
//File(String parent, String child) 从父路径名字符串和子路径名字符串创建新的File实例
String path1 = "E:\\wenjian";
String path2 = "a.txt";
File file = new File(path1,path2);//把两个路径拼接.
System.out.println(file);//C:\itheima\a.txt
}
--------------------------------------------
打印结果:
E:\wenjian\a.txt
Process finished with exit code 0 private static void method3() {
//File(File parent, String child) 从父抽象路径名和子路径名字符串创建新的File实例
File file1 = new File("E:\\wenjian");
String path = "a.txt";
File file = new File(file1,path);
System.out.println(file);//C:\itheima\a.txt
}
----------------------------------------
控制台打印结果:
E:\wenjian\a.txt
Process finished with exit code 0
package com.filemodule.filedemo;
import java.io.File;
public class FileDemo2 {
public static void main(String[] args) {
//这个路径固定不变了.
File file = new File("D:\\it\\a.txt");
//当前项目下的a.txt
File file2 = new File("a.txt");
//当前项目下 --- 指定模块下的 a.txt
File file3 = new File("filemodule\\a.txt");
}
}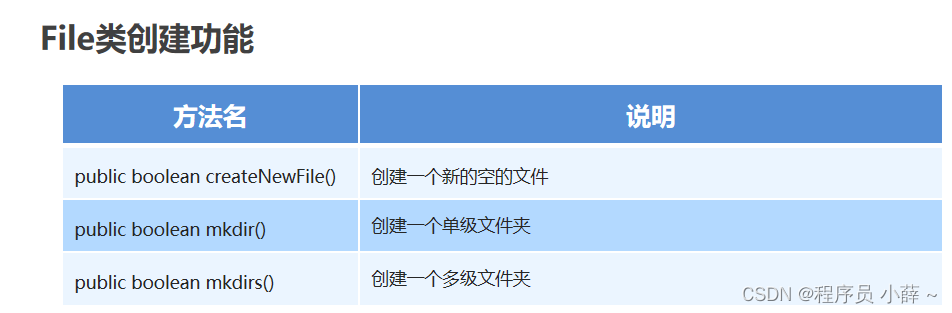
//public boolean createNewFile() 创建一个新的空的文件
//注意点:
//1.如果文件存在,那么创建失败,返回false
//2.如果文件不存在,那么创建成功,返回true
//3.createNewFile方法不管调用者有没有后缀名,只能创建文件.
private static void method1() throws IOException {
File file1 = new File("C:\\it\\aaa");
boolean result1 = file1.createNewFile();
System.out.println(result1);
} //public boolean mkdir() 创建一个单级文件夹
//注意点:
//1.只能创建单级文件夹,不能创建多级文件夹
//2.不管调用者有没有后缀名,只能创建单级文件夹
private static void method2() {
File file = new File("C:\\it\\aaa.txt");
boolean result = file.mkdir();
System.out.println(result);
}
//public boolean mkdirs() 创建一个多级文件夹
//注意点:
//1,可以创建单级文件夹,也可以创建多级文件夹
//2.不管调用者有没有后缀名,只能创建文件夹
//疑问:
//既然mkdirs能创建单级,也能创建多级.那么mkdir还有什么用啊? 是的
File file = new File("C:\\it\\aaa.txt");
boolean result = file.mkdirs();
System.out.println(result);
import java.io.File;
public class FileDemo4 {
//注意点:
//1.不走回收站的.
//2.如果删除的是文件,那么直接删除.如果删除的是文件夹,那么能删除空文件夹
//3.如果要删除一个有内容的文件夹,只能先进入到这个文件夹,把里面的内容全部删除完毕,才能再次删除这个文件夹
//简单来说:
//只能删除文件和空文件夹.
public static void main(String[] args) {
//method1();
File file = new File("C:\\it");
boolean result = file.delete();
System.out.println(result);
}
private static void method1() {
File file = new File("C:\\it\\a.txt");
boolean result = file.delete();
System.out.println(result);
}
}
-
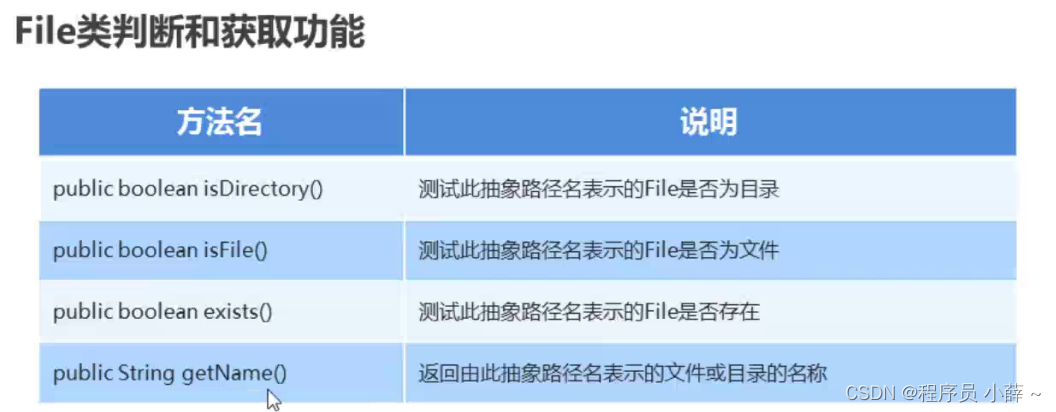
判断功能
方法名 说明 public boolean isDirectory() 测试此抽象路径名表示的File是否为目录 public boolean isFile() 测试此抽象路径名表示的File是否为文件 public boolean exists() 测试此抽象路径名表示的File是否存在 -
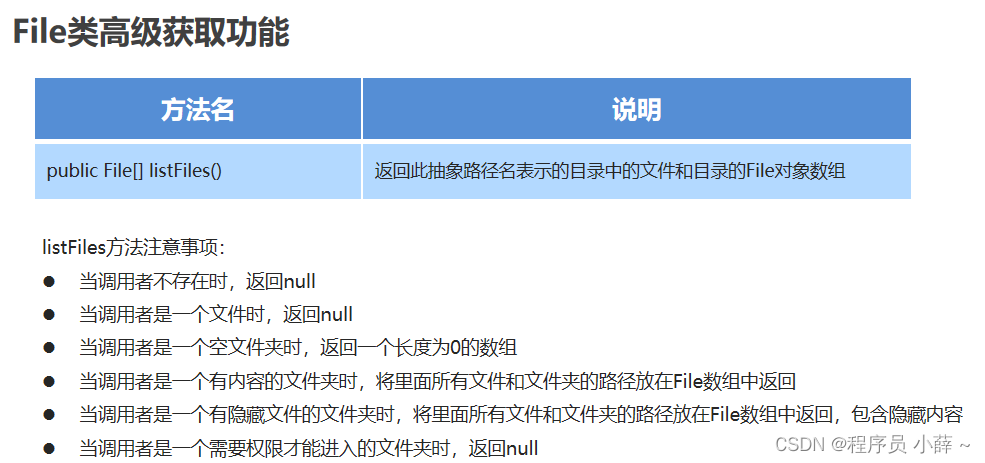
获取功能
方法名 说明 public String getAbsolutePath() 返回此抽象路径名的绝对路径名字符串 public String getPath() 将此抽象路径名转换为路径名字符串 public String getName() 返回由此抽象路径名表示的文件或目录的名称 public File[] listFiles() 返回此抽象路径名表示的目录中的文件和目录的File对象数组
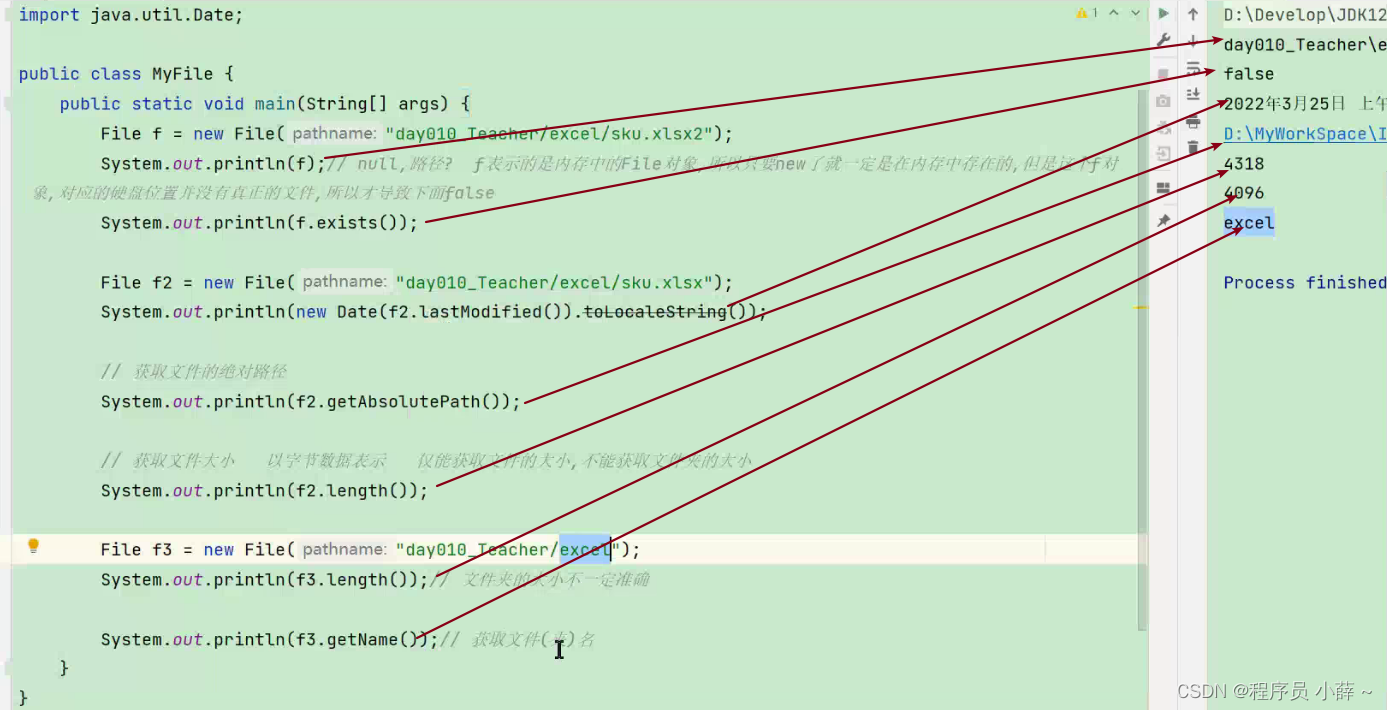
private static void method1() {
File file = new File("C:\\it\\a.txt");
//public boolean isFile() 测试此抽象路径名表示的File是否为文件
boolean result1 = file.isFile();
//public boolean isDirectory() 测试此抽象路径名表示的File是否为目录
boolean result2 = file.isDirectory();
System.out.println(result1);//true
System.out.println(result2);//false
} private static void method2() {
File file = new File("C:\\it");
boolean result1 = file.isFile();//是否为文件
boolean result2 = file.isDirectory();//是否为目录
System.out.println(result1);//false
System.out.println(result2);//true
} private static void method3() {
File file = new File("a.txt");
//public boolean exists() 测试此抽象路径名表示的File是否存在
boolean result = file.exists();//File是否存在
System.out.println(result);//false
} private static void method4() { //注意点:
File file = new File("a.txt"); //1.如果调用者是文件,那么获取的是文件名和后缀名
//public String getName() 返回由此抽象路径名表示的文件或目录的名称
String name = file.getName();
System.out.println(name);
//注意点:
File file1 = new File("C:\\it");//2.如果调用者是一个文件夹,那么获取的是文件夹的名字
//public String getName() 返回由此抽象路径名表示的文件或目录的名称
String name2 = file1.getName();
System.out.println(name2);
}

package com.filemodule.filedemo;
import java.io.File;
public class FileDemo6 {
public static void main(String[] args) {
File file = new File("D:\\aaa");
File[] files = file.listFiles();//返回值是一个File类型的数组
System.out.println(files.length);
for (File path : files) {
System.out.println(path);
}
//进入文件夹,获取这个文件夹里面所有的文件和文件夹的File对象,并把这些File对象都放在一个数组中返回.
//包括隐藏文件和隐藏文件夹都可以获取.
//注意事项:
//1.当调用者是一个文件时
//2,当调用者是一个空文件夹时
//3.当调用者是一个有内容的文件夹时
//4.当调用者是一个有权限才能进入的文件夹时
}
} 

package com.filemodule.filetest;
import java.io.File;
import java.io.IOException;
public class Test1 {
public static void main(String[] args) throws IOException {
//练习一:在当前模块下的aaa文件夹中创建一个a.txt文件
/* File file = new File("filemodule\\aaa\\a.txt");
file.createNewFile();*/
//注意点:文件所在的文件夹必须要存在.
File file = new File("filemodule\\aaa");
if(!file.exists()){
//如果文件夹不存在,就创建出来
file.mkdirs();
}
File newFile = new File(file,"a.txt");
newFile.createNewFile();
}
}package com.filemodule.filetest;
import java.io.File;
public class Test2 {
public static void main(String[] args) {
//练习二:删除一个多级文件夹
//delete方法
//只能删除文件和空文件夹.
//如果现在要删除一个有内容的文件夹?
//先删掉这个文件夹里面所有的内容.
//最后再删除这个文件夹
File src = new File("C:\\Users\\apple\\Desktop\\src");
deleteDir(src);
}
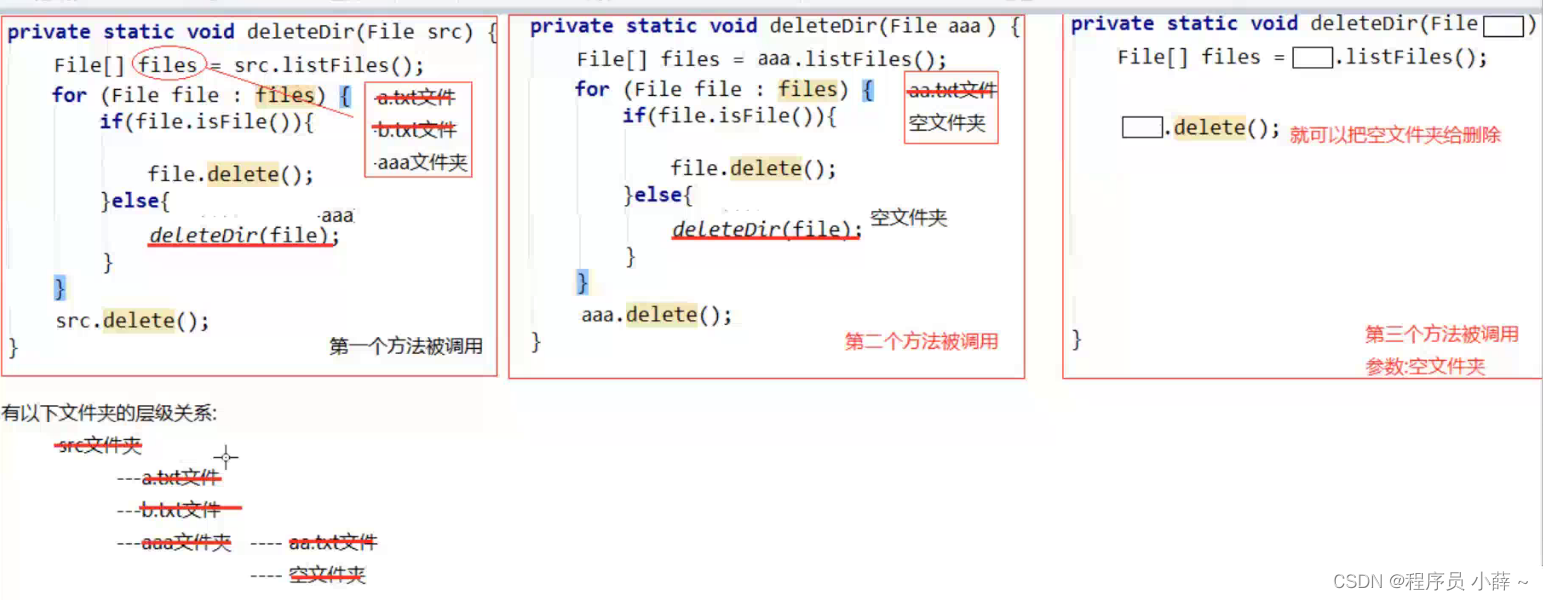
private static void deleteDir(File src) {
//先删掉这个文件夹里面所有的内容.
//递归 方法在方法体中自己调用自己.
//注意: 可以解决所有文件夹和递归相结合的题目
//1.进入 --- 得到src文件夹里面所有内容的File对象.
File[] files = src.listFiles();
//2.遍历 --- 因为我想得到src文件夹里面每一个文件和文件夹的File对象.
for (File file : files) {
if(file.isFile()){
//3.判断 --- 如果遍历到的File对象是一个文件,那么直接删除
file.delete();
}else{
//4.判断
//递归
deleteDir(file);//参数一定要是src文件夹里面的文件夹File对象
}
}
//最后再删除这个文件夹
src.delete();
}
}
package com.filemodule.filetest;
import java.io.File;
import java.util.HashMap;
public class Test3 {
public static void main(String[] args) {
//统计一个文件夹中,每种文件出现的次数.
//统计 --- 定义一个变量用来统计. ---- 弊端:同时只能统计一种文件
//利用map集合进行数据统计,键 --- 文件后缀名 值 ---- 次数
File file = new File("filemodule");
HashMap<String, Integer> hm = new HashMap<>();
getCount(hm, file);
System.out.println(hm);
}
private static void getCount(HashMap<String, Integer> hm, File file) {
File[] files = file.listFiles();
for (File f : files) {
if(f.isFile()){
String fileName = f.getName();
String[] fileNameArr = fileName.split("\\.");
if(fileNameArr.length == 2){
String fileEndName = fileNameArr[1];
if(hm.containsKey(fileEndName)){
//已经存在
//将已经出现的次数获取出来
Integer count = hm.get(fileEndName);
//这种文件又出现了一次.
count++;
//把已经出现的次数给覆盖掉.
hm.put(fileEndName,count);
}else{
//不存在
//表示当前文件是第一次出现
hm.put(fileEndName,1);
}
}
}else{
getCount(hm,f);
}
}
}
}