TransE
该模型将关系和实体表示为同一空间中的向量,给定事实 ( h , r , s ) (h,r,s) (h,r,s)关系 r r r 的向量 r r r被解释为头实体向量 h h h与尾实体向量 t t t之间的平移,因此嵌入实体 h h h和 t t t可以通过平移向量 r r r以低误差链接,即满足 h + r ≈ t h + r \approx t h+r≈t。
- TransE (Translating Embedding), an energy-based model for learning low-dimensional embeddings of entities.
- 核心思想:将 relationship 视为一个在 embedding space 的 translation。如果
(
h
,
r
,
t
)
(h, r, t)
(h,r,t) 存在,那么
h
+
r
≈
t
h + r \approx t
h+r≈t
Motivation:一是在Knowledge Base中,层次化关系是非常常见的,translation是一种很自然表示它们之间变换。二是近期一些从 text 中学习 word embedding 的研究发现,一些不同类型的实体之间的 1-to-1 的 relationship 可以被 model 表示为在 embedding space 中的一种 translation
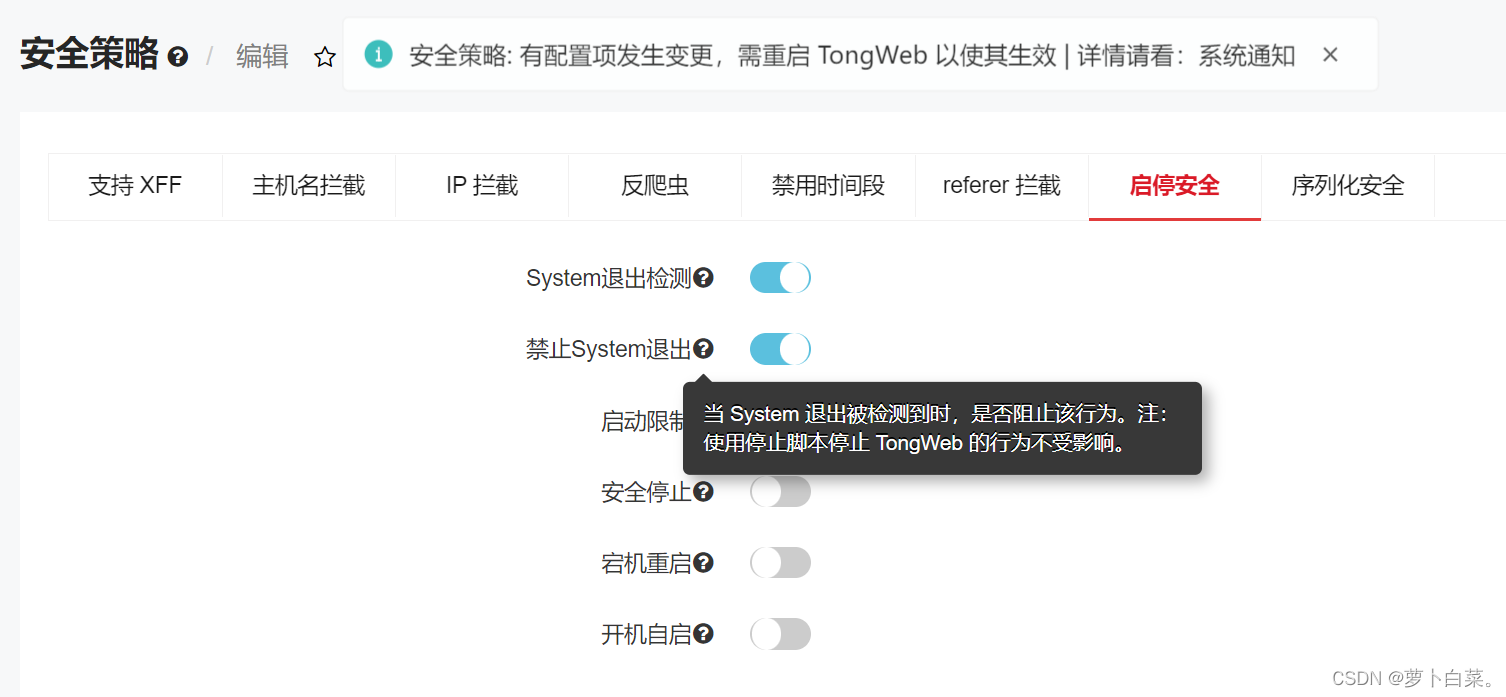
TransE训练算法如下:

输入参数
training set S: 用于训练的三元组集合,entity的集合为E,relationship的集合为L。
margin γ \gamma γ:损失函数中的间隔
每个entity或relationship中的embedding dim k。
训练过程
初始化:对于每个entity和relationship的embedding vector,用xavier_uniform 分布来初始化,然后对其实现l1 l2正则化。
loop:
-
在 entity embedding 被更新前进行一次归一化,这是通过人为增加 embedding 的 norm 来防止 loss 在训练过程中极小化
-
Sample 出一个mini-batch的正样本集合 S b a t c h S_{batch} Sbatch
-
将 T b a t c h T_{batch} Tbatch初始化为空集**,它表示本次 loop 用于训练 model 的数据集**
-
for ( h , l , t ) ∈ S b a t c h (h,l,t) \in S_{batch} (h,l,t)∈Sbatchdo:
- 根据构造的 ( h , l , t ) (h,l,t) (h,l,t)构造一个错误的三元组 ( h ′ , l , t ′ ) ( h^′ , l , t^′ ) (h′,l,t′)
- 将positive sample ( h , l , t ) (h,l,t) (h,l,t)和negative sample ( h ′ , l , t ′ ) ( h^′ , l , t^′ ) (h′,l,t′)加入到 T b a t c h T_{batch} Tbatch中。
-
计算 T b a t c h T_{batch} Tbatch每一对的positive sample和negative sample的loss,然后累加起来用于更新embedding matrix.每一对的loss计算方式为:

关于margin γ \gamma γ的含义
其相当于是一个正确的triple和一个错误的triple的间隔修正,margin越大,则两个triple之前被修正的间隔就越大。则对embedding的修正就越严格。

错误三元组的构造方法
将 ( h , l , t ) (h,l,t) (h,l,t)中的头实体、尾实体和关系其中之一随机替换为其他实体或关系来得到。
评价指标


TransE的优缺点
与以往模型相比,其模型参数较少,计算复杂度低,却能直接建立实体和关系之间的复杂语义联系。在 WordNet 和 Freebase 等 dataset 上较以往模型的 performance 有了显著提升,特别是在大规模稀疏 KG 上,TransE 的性能尤其惊人
缺点
在处理复杂关系
(
1
−
N
、
N
−
1
和
N
−
N
)
(1-N、N-1 和 N-N)
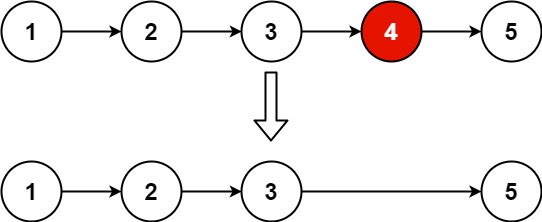
(1−N、N−1和N−N)时,性能显著降低,这与 TransE 的模型假设有密切关系。假设有 (美国,总统,奥巴马)和(美国,总统,布什),这里的“总统”关系是典型的 1-N 的复杂关系,如果用 TransE 对其进行学习,则会有:
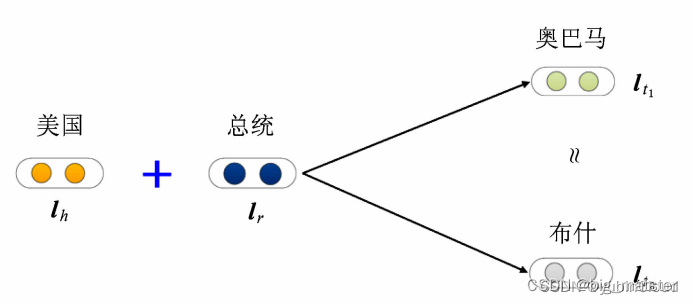
那么这将会使奥巴马和布什的 vector 变得相同。所以由于这些复杂关系的存在,导致 TransE 学习得到的实体表示区分性较低。