总第547篇
2022年 第064篇

美团语音交互部针对跨语言结构化情感分析任务中缺少小语种的标注数据、传统方法优化成本高昂的问题,通过利用跨语言预训练语言模型、多任务和数据增强方法在不同语言间实现低成本的迁移,相关方法获得了SemEval 2022结构化情感分析跨语言赛道的冠军。
1. 背景
2. 赛题简介
数据介绍
评估指标
3. 现有方法和问题
4. 我们的方法
5. 方法实现和实验分析
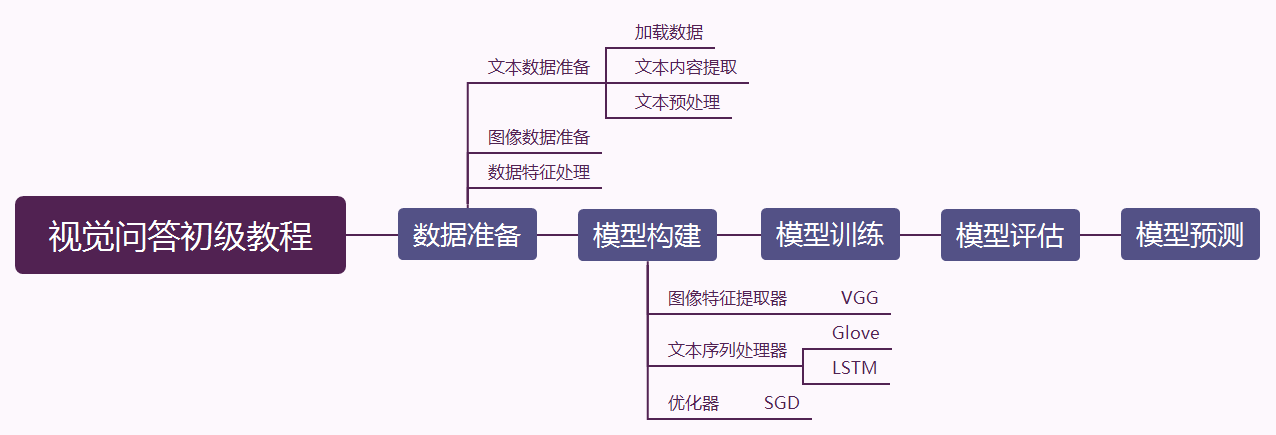
5.1 模型选择
5.2 数据增强
5.3 辅助任务
6. 与其他参赛队伍效果对比
7. 总结
1. 背景
SemEval(International Workshop on Semantic Evaluation)是一系列国际自然语言处理(NLP)研讨会,也是自然语言处理领域的权威国际竞赛,其使命是推进语义分析的研究进展,并帮助一系列日益具有挑战性的自然语言语义问题创建高质量的数据集。本次SemEval-2022(The 16th International Workshop on Semantic Evaluation)包含12个任务,涉及一系列主题,包括习语检测和嵌入、讽刺检测、多语言新闻相似性等任务,吸引了包括特斯拉、阿里巴巴、支付宝、滴滴、华为、字节跳动、斯坦福大学等企业和科研机构参与。
其中Task 10: 结构化情感分析(Structured Sentiment Analysis)属于信息抽取(Information Extraction)领域。该任务包含两个子任务(分别是Monolingual Subtask-1和Zero-shot Crosslingual Subtask-2 ),包含五种语言共7个数据集(包括英语、西班牙语、加泰罗尼亚语、巴斯克语、挪威语),其中子Subtask-1使用全部七个数据集,Subtask-2使用其中的三个数据集(西班牙语、加泰罗尼亚语、巴斯克语)。我们在参与该评测任务的三十多支队伍中取得Subtask-1第二名和Subtask-2 第一名,相关工作已总结为一篇论文MT-Speech at SemEval-2022 Task 10: Incorporating Data Augmentation and Auxiliary Task with Cross-Lingual Pretrained Language Model for Structured Sentiment Analysis,并收录在NAACL 2022 Workshop SemEval。
2. 赛题简介
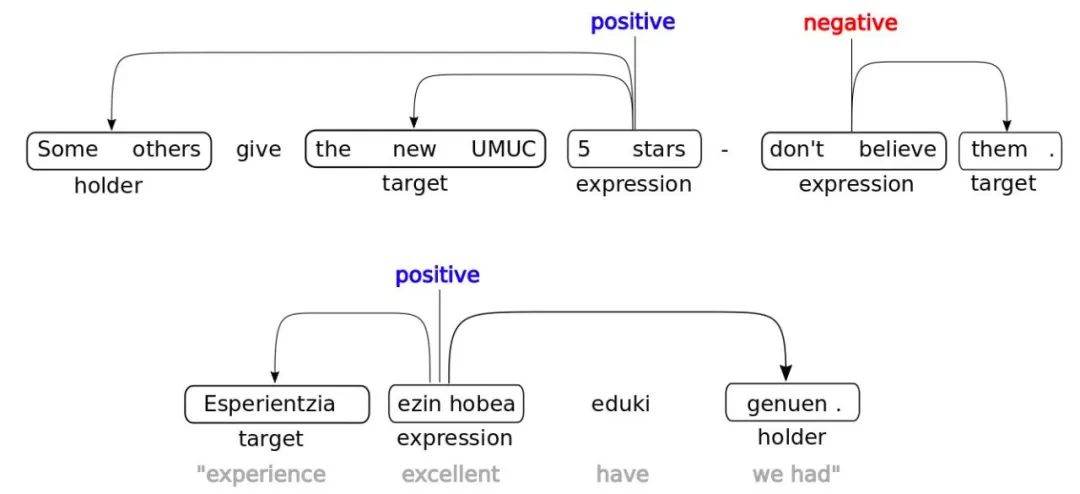
结构化情感分析任务(Structured Sentiment Analysis, SSA)的目的是抽取出文本中人们对创意、产品或政策等的看法,并结构化地表达为观点四元组 - Opinion tuple Oi (h, t, e, p),包括Holder(主体)、Target(客体)、情绪表达(Expression)、极性(Polarity)四种要素,表征了Holder(主体)对Target(客体)的情绪表达(Expression),和对应的极性(Polarity)。观点四元组可以用Sentiment Graphs来具象化储存和表示(如下图1所示),图中展示了两个例句,分别用英文和巴斯克语表达了“某些人给the new UMUC大学评五分是不可信的”这个意思。第一句英文示例包含了两个观点四元组,分别是O1 (h, t, e, p) = (Some others, the new UMUC, 5 stars, positive),以及O2 (h, t, e, p) = (, them, don't believe, negative)。
比赛任务有两个:
Monolingual任务:已知测试集的语种,允许使用相同语种的有标签数据进行训练。总分取七个数据集的宏平均 Sentiment F1 。
Crosslingual任务:不允许使用和测试集语种相同语言的有标签数据进行训练(测评数据集是其中的三个小语种数据集 - 西班牙语,加泰罗尼亚语,巴斯克语)。
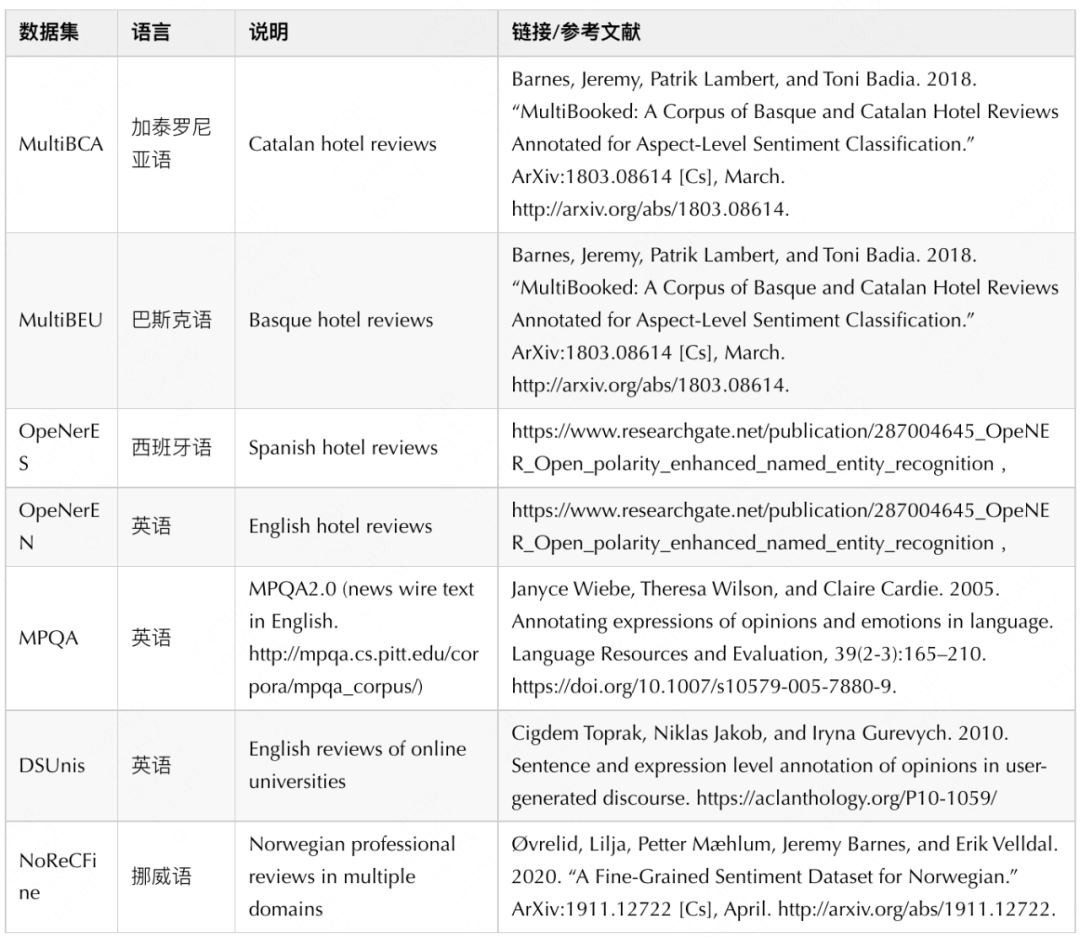
数据介绍
评估指标
比赛的评估指标是 Sentiment Graph F1 (SF1, 缩写沿用论文[5]的写法),评价预测四元组和标签四元组的重合度。除了需要使用传统的真阳性(True Positive, TP)、假阳性(False Positive, FP),假阴性(False Negative, FN)、真阴性(True Negative, TN)参与指标计算,还额外定义了加权真阳性(Weighted True Positive, WTP)[5]为观点元组级别的精确匹配 - 即观点元组的极性判断正确时,三个元素(Holder,Target,Expression)的预测片段和真实标签片段的平均重合程度(若有多个匹配的观点元组,则取平均重合度最大的元组)为WTP的值(具体可进一步参考[5]),如果WTP大于0,则TP为1,否则TP为0。若极性判断错误,则WTP和TP都为0。观点元组标签的Holder或者Target片段可以为空,此时,相应的要求预测的Holders或者Targets片段也要为空,否则不算成功匹配。可见观点元组的精确匹配要求是非常高的。
计算观点元组精准率时,
计算观点元组召回率时,
最终的Sentiment Graph F1 (SF1)为
3. 现有方法和问题
结构化情感分析任务的主流方法是采用流水线的方式,分别进行Holder、Target和Expression的信息抽取等子任务,再进行情感分类。然而,这样的方法不能捕获多个子任务之间的依赖关系,且存在任务的误差传播。
为了解决这个问题,Barnes et al. (2021) [5]利用基于图的依存分析(Dependency Parsing)来捕获观点四元组内各要素之间的依赖关系,其中情感主体、客体和情绪表达都是节点,它们之间的关系则是弧。该模型当时在 SSA 任务上获得了最佳效果。然而,上述Barnes et al. (2021) [5] 的方法仍然存在一些问题。首先,预训练语言模型(PLM)的知识没有得到充分利用,因为Barnes et al. (2021)[5] 没有很好解决图关系和字Tokens间的映射,导致其只能用PLM来生成字符Embedding,且无法跟模型一起训练。
事实上,跨语言的 PLM 包含关于不同语言之间交互的丰富信息。其次,上述数据驱动的模型依赖于大量标注数据,但在真实场景中往往是标注数据不足或者甚至没有标注数据。例如,在本次任务中,MultiBEU (Barnes et al., 2018)[4] 的训练集只有 1063 个样本,类似的 MultiBCA (Barnes et al., 2018)[4] 的训练集只有 1174 个样本。本次任务的跨语言子任务要求不能使用目标语言的训练数据,也严重制约了该方法的性能。
4. 我们的方法
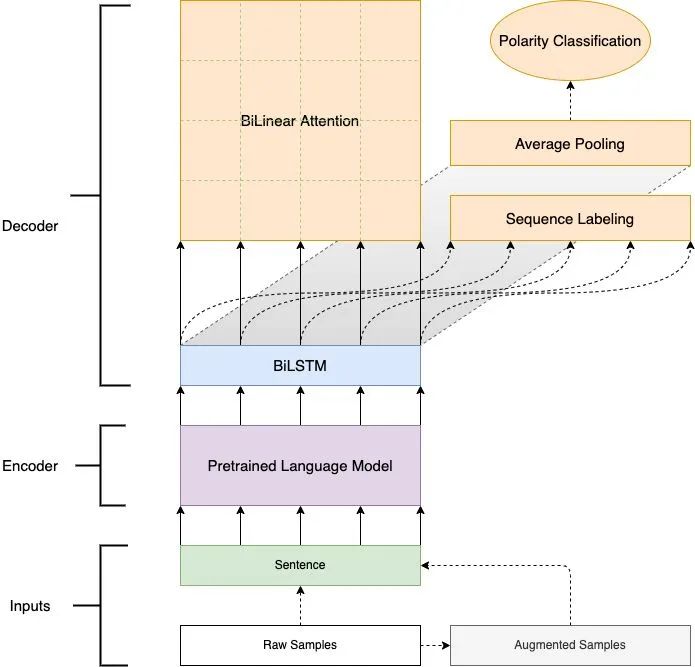
为了解决上述提到的问题,我们提出了一个统一的端到端 SSA 模型(图2),把PLM作为模型主干(Backbone)参与到整个端到端的训练中,并且利用数据增强方法和辅助任务来大幅提升跨语言zero-shot场景的效果。
具体地,我们采用 XLM-RoBERTa (Conneau and Lample, 2019; Conneau et al., 2019)[10,11] 作为模型的主干编码器(Backbone Encoder),以充分利用其已有的多语言/跨语言知识;使用BiLSTM[12]加强序列解码能力;最后一个双线性注意力矩阵(Bilinear Attention)建模依存图,解码出观点四元组。为了缓解缺乏标注数据的问题,我们采用了两种数据增强方法:一种是在训练阶段添加相同任务的相同领域(In-Domain)的标注数据,另一种是利用XLM-RoBERTa通过掩码语言模型(MLM) (Devlin et al., 2018)[13] 生成增强样本(Augmented Samples)。
此外,我们还添加了两个辅助任务:1)序列标注任务(Sequence Labeling)以预测文本中Holder/Target/Expression的片段,以及 2)情感极性分类(Polarity Classification)。这些辅助任务都不需要额外的标注。
5. 方法实现和实验分析
5.1 模型选择
当前有很多种预训练模型可作为模型主干,例如Multilingual BERT (mBERT) (Devlin et al., 2018)[13]、XLM-RoBERTa (Conneau et al., 2019)[10] 和 infoXLM(Chi et al., 2021)[9]。我们选择 XLM-RoBERTa。因为Monolingual任务涉及五种语言的预料,Crosslingual任务是一个跨语言零样本问题,这两个任务都受益于 XLM-RoBERTa 的多语言训练文本和翻译语言建模(Translation Language Model, TLM)训练目标。
XLM 系列模型中的 TLM 和 Masked Language Modeling (MLM) 目标的性能优于 mBERT,后者仅使用 MLM 目标在多语言语料库上进行训练。此外,XLM-RoBERTa提供了Large版本,模型更大,训练数据更多,这使其在下游任务的性能更好。我们没有使用 infoXLM,因为它着重于句子级的分类目标,不适合本次结构化预测的任务。

为了证明跨语言预训练语言模型 XLM-RoBERTa 的有效性,我们将其与以下基线进行了比较:1)w2v + BiLSTM,word2vec(Mikolov et al., 2013)[20] 词嵌入和BiLSTMs;2) mBERT,多语言 BERT (Devlin et al., 2018)[13];3)mBERT + BiLSTM;4) XLM-RoBERTa + BiLSTM。表 1 表明 XLM-RoBERTa + BiLSTM 在所有基准测试中获得了最佳性能,平均得分比最强基线 (mBERT + BiLSTM) 高 6.7%。BiLSTM 可以提高 3.7% 的性能,这表明 BiLSTM 层可以捕获序列信息,这有利于序列化的信息编码 (Cross and Huang, 2016)[12]。
我们使用官方发布的开发集作为测试集,将原始训练集随机拆分为训练集和开发集。并保持拆分开发集的大小与官方发布的开发集相同。
5.2 数据增强
数据增强(DA1)- 同领域数据合并
不同语种的M个数据集如果属于相同的领域,可以合并作为一个大训练集以提升各个子数据集的效果。本次评测有四个同属于酒店评论的数据集MultiBEU、MultiBCA、OpeNerES、OpeNerEN (Agerri et al., 2013)[1],我们在训练阶段组合了这些属于同一领域的不同数据集,可以提高各个数据集的效果。我们还额外添加了葡萄牙语的酒店评论数据集 (BOTE-rehol) (Barros and Bona, 2021)[7]。我们观察到这些数据集虽然语种不同,但共享一些相似特征。
具体地说,这些数据集所属的语言对一些相同的对象或概念共享相近的词(从拉丁字母相似性的角度看)。例如,加泰罗尼亚语和西班牙语对“酒店”的表示跟英文一样都是“hotel”;在巴斯克语中“酒店”则是一个相似的词“hotela”。此外,人们在酒店评论领域具有相同的情感极性倾向,比如对“优质的服务”和“干净整洁的空间”表示赞赏。其中MultiBEU数据集是数据量最少的数据集,能够通过更多的数据增强获得更多提升。


数据增强(DA2)- 通过掩码语言模型生成新样本
掩码语言模型(Mask Language Model)在预训练阶段使用 [MASK] 标记随机替换原始文本tokens,训练目标就是在 [MASK] 位置预测原始tokens。对于每个具有有效观点四元组的样本,我们随机掩码训练集文本中的一小部分tokens,并使用在任务数据集上预训练过的XLM-RoBERTa在这些掩码过的样本上生成新的tokens,这样我们就获得了带标签的新样本。但要注意不能在Express片段上进行掩码生成,因为模型可能会生成与原始标签极性不同的词。

从表3和表4可以看到两种数据增强方法都有助于提高性能,几乎每个基准测试的性能都有所提高。特别是对Crosslingual任务的性能有显着提高,推测是因为Zero-shot任务没有机会在训练阶段看过同数据集的训练样本的文本和标签。DA2方法能提升Crosslingual任务的效果,但是对Monolingual任务的作用不大,推测是因为Monolingual任务的已经在训练阶段看过同数据集的训练样本了。
5.3 辅助任务
SSA任务同时包含结构化预测和情感极性分类,让模型端到端地解决这两个任务并非易事。我们提出了两个辅助任务来为模型提供更多的训练信号,以更好地处理结构化预测和极性分类。对于结构化预测,我们添加了一个序列标注任务(如下图3),让模型预测每个token的类型(Holder、Target或者Expression),得到辅助损失。

针对极性分类任务,我们把评测的训练数据转换为句子级的极性分类任务,具体实现是把只有一种极性的观点元组的句子设置为对应的极性类别,把包含多种极性的观点元组的句子设置为中性(Neutral)类别。除此之外,针对不同语种的数据集,我们还添加了相关的开源句子级情感极性分类数据集,为各个数据集额外配置一个多层感知器(MLP)作为分类器。我们把模型的 BiLSTM 隐藏状态(Hidden States)的平均池化(Average Pooling)作为文本句子级的向量表达,并输入到对应的分类器进行句子级情感极性分类,得到辅助损失()。总的训练损失(Loss)是主损失()和两个辅助损失的加权和:

6. 与其他参赛队伍效果对比
和其他团队的结果相比,我们在平均分以及多个子数据集上有优势。在Subtask-2(表7)的Zero-shot数据集上,相比第二名平均分高了5.2pp。在Subtask-1(表6)上多个数据集(MultiBEU , MultiBCA, OpeNerES, 和 OpeNerEN)排名第一,平均分相比第一名仅有0.3pp的差距。


7. 总结
本次评测,我们主要探索了结构化情感分析的任务。针对不同语言数据间缺乏交互、以及标注资源缺乏的问题,我们应用了跨语言预训练语言模型,并采用了两种数据增强方法和两种辅助任务。实验证明了我们的方法和模型的有效性,并在 SemEval-2022 任务 10 结构化情感分析(Structured Sentiment Analysis)取得Subtask-1第二名(表6)和Subtask-2第一名(表7)的成绩。
后续,我们将继续探索其他更有效的多语言/跨语言资源和跨语言预训练模型的应用方法。我们正在尝试将比赛中的技术应用到美团具体业务中,如语音交互部的智能客服、智能外呼机器人中,为优化智能解决能力、提升用户满意度提供参考。
8. 本文作者
陈聪、见耸、刘操、杨帆、广鲁、今雄等,均来自美团平台/语音交互部。
9. 参考文献
[1] Rodrigo Agerri, Montse Cuadros, Sean Gaines, and German Rigau. 2013. OpeNER: Open polarity enhanced named entity recognition. In Sociedad Española para el Procesamiento del Lenguaje Natural, volume 51, pages 215–218.
[2] Rodrigo Agerri, Iñaki San Vicente, Jon Ander Campos, Ander Barrena, Xabier Saralegi, Aitor Soroa, and Eneko Agirre. 2020. Give your text representation models some love: the case for basque. In Proceedings of the 12th International Conference on Language Resources and Evaluation.
[3] Jordi Armengol-Estapé, Casimiro Pio Carrino, Carlos Rodriguez-Penagos, Ona de Gibert Bonet, Carme Armentano-Oller, Aitor Gonzalez-Agirre, Maite Melero, and Marta Villegas. 2021. Are multilingual models the best choice for moderately underresourced languages? A comprehensive assessment for Catalan. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 4933–4946, Online. Association for Computational Linguistics.
[4] Jeremy Barnes, Toni Badia, and Patrik Lambert. 2018. MultiBooked: A corpus of Basque and Catalan hotel reviews annotated for aspect-level sentiment classification. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation(LREC 2018), Miyazaki, Japan. European Language Resources Association (ELRA).
[5] Jeremy Barnes, Robin Kurtz, Stephan Oepen, Lilja Øvrelid, and Erik Velldal. 2021. Structured sentiment analysis as dependency graph parsing. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 3387–3402, Online. Association for Computational Linguistics.
[6] Jeremy Barnes, Oberländer Laura Ana Maria Kutuzov, Andrey and, Enrica Troiano, Jan Buchmann, Rodrigo Agerri, Lilja Øvrelid, Erik Velldal, and Stephan Oepen. 2022. SemEval-2022 task 10: Structured sentiment analysis. In Proceedings of the 16th International Workshop on Semantic Evaluation (SemEval2022), Seattle. Association for Computational Linguistics.
[7] José Meléndez Barros and Glauber De Bona. 2021. A deep learning approach for aspect sentiment triplet extraction in portuguese. In Brazilian Conference on Intelligent Systems, pages 343–358. Springer.
[8] José Cañete, Gabriel Chaperon, Rodrigo Fuentes, JouHui Ho, Hojin Kang, and Jorge Pérez. 2020. Spanish pre-trained bert model and evaluation data. In PML4DC at ICLR 2020.
[9] Zewen Chi, Li Dong, Furu Wei, Nan Yang, Saksham Singhal, Wenhui Wang, Xia Song, Xian-Ling Mao, Heyan Huang, and M. Zhou. 2021. Infoxlm: An information-theoretic framework for cross-lingual language model pre-training. In NAACL.
[10] Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Unsupervised cross-lingual representation learning at scale. arXiv preprint arXiv:1911.02116.
[11] Alexis Conneau and Guillaume Lample. 2019. Crosslingual language model pretraining. Advances in neural information processing systems, 32.
[12] James Cross and Liang Huang. 2016. Incremental parsing with minimal features using bi-directional lstm. ArXiv, abs/1606.06406.
[13] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[14] Timothy Dozat and Christopher D Manning. 2016. Deep biaffine attention for neural dependency parsing. arXiv preprint arXiv:1611.01734.
[15] E. Kiperwasser and Yoav Goldberg. 2016. Simple and accurate dependency parsing using bidirectional lstm feature representations. Transactions of the Association for Computational Linguistics, 4:313–327.
[16] Robin Kurtz, Stephan Oepen, and Marco Kuhlmann. 2020. End-to-end negation resolution as graph parsing. In IWPT.
[17] Xin Li, Lidong Bing, Piji Li, and Wai Lam. 2019. A unified model for opinion target extraction and target sentiment prediction. ArXiv, abs/1811.05082.
[18] Bing Liu. 2012. Sentiment analysis and opinion mining. Synthesis lectures on human language technologies, 5(1):1–167.
[19] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
[20] Tomas Mikolov, Kai Chen, Gregory S. Corrado, and Jeffrey Dean. 2013. Efficient estimation of word representations in vector space. In ICLR.
[21] Margaret Mitchell, Jacqui Aguilar, Theresa Wilson, and Benjamin Van Durme. 2013. Open domain targeted sentiment. In EMNLP.
[22] Stephan Oepen, Omri Abend, Lasha Abzianidze, Johan Bos, Jan Hajic, Daniel Hershcovich, Bin Li, Timothy J. O’Gorman, Nianwen Xue, and Daniel Zeman. 2020. Mrp 2020: The second shared task on crossframework and cross-lingual meaning representation parsing. In CONLL.
[23] Lilja Ovrelid, Petter Maehlum, Jeremy Barnes, and Erik Velldal. 2020. A fine-grained sentiment dataset for norwegian. In LREC.
[24] Lilja Øvrelid, Petter Mæhlum, Jeremy Barnes, and Erik Velldal. 2020. A fine-grained sentiment dataset for Norwegian. In Proceedings of the 12th Language Resources and Evaluation Conference, pages 5025– 5033, Marseille, France. European Language Resources Association.
[25] Bo Pang, Lillian Lee, et al. 2008. Opinion mining and sentiment analysis. Foundations and Trends® in information retrieval, 2(1–2):1–135.
[26] Maria Pontiki, Dimitris Galanis, John Pavlopoulos, Haris Papageorgiou, Ion Androutsopoulos, and Suresh Manandhar. 2014. Semeval-2014 task 4: Aspect based sentiment analysis. In COLING 2014.
[27] Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners.
[28] Colin Raffel, Noam M. Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. ArXiv, abs/1910.10683.
[29] Mike Schuster and Kuldip K Paliwal. 1997. Bidirectional recurrent neural networks. IEEE transactions on Signal Processing, 45(11):2673–2681.
[30] Cigdem Toprak, Niklas Jakob, and Iryna Gurevych. 2010. Sentence and expression level annotation of opinions in user-generated discourse. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, pages 575–584, Uppsala, Sweden. Association for Computational Linguistics.
[31] Ashish Vaswani, Noam M. Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. ArXiv, abs/1706.03762.
[32] Janyce Wiebe, Theresa Wilson, and Claire Cardie. 2005. Annotating expressions of opinions and emotions in language. Language Resources and Evaluation, 39(2-3):165–210.
[33] Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, and Jamie Brew. 2019. Huggingface’s transformers: State-of-the-art natural language processing. ArXiv, abs/1910.03771.
[34] Lu Xu, Hao Li, Wei Lu, and Lidong Bing. 2020. Position-aware tagging for aspect sentiment triplet extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2339–2349, Online. Association for Computational Linguistics.
[35] Zhilin Yang, Zihang Dai, Yiming Yang, Jaime G. Carbonell, Ruslan Salakhutdinov, and Quoc V. Le. 2019. Xlnet: Generalized autoregressive pretraining for language understanding. In NeurIPS.
[36] Elena Zotova, Rodrigo Agerri, Manuel Nunez, and German Rigau. 2020. Multilingual stance detection: The catalonia independence corpus. arXiv preprint arXiv:2004.00050.
---------- END ----------
招聘信息
语音交互部负责美团语音和对话技术研发,面向美团业务及生态系统内B端、C端合作伙伴,提供语音技术与对话交互技术能力支持和产品应用。经过多年研发积累,团队在语音识别、合成、口语理解、智能问答和多轮交互等技术上已建成大规模的技术平台服务,并研发包括外呼机器人、智能客服、语音内容分析等解决方案和产品,在美团丰富的业务场景中广泛落地。语音交互部长期招聘自然语言处理算法工程师、算法专家,感兴趣的同学可以将简历发送至chenjiansong@meituan.com。
美团科研合作
美团科研合作致力于搭建美团技术团队与高校、科研机构、智库的合作桥梁和平台,依托美团丰富的业务场景、数据资源和真实的产业问题,开放创新,汇聚向上的力量,围绕机器人、人工智能、大数据、物联网、无人驾驶、运筹优化等领域,共同探索前沿科技和产业焦点宏观问题,促进产学研合作交流和成果转化,推动优秀人才培养。面向未来,我们期待能与更多高校和科研院所的老师和同学们进行合作。欢迎老师和同学们发送邮件至:meituan.oi@meituan.com。
也许你还想看
| DSTC10开放领域对话评估比赛冠军方法总结
前端 | 算法 | 后端 | 数据
安全 | Android | iOS | 运维 | 测试