目录
一、数据加载(keras.datasets)
1.1 MNIST 加载
1.2 CIFAR10/100 加载
1.3 tf.data.Dataset.from_tensor_slices
1.4 .shuffle (对应打散数据)
1.5 .map(数据预处理)
1.6 .batch / .repeat
二、全连接层
三、输出方式
3.1 y ∈ R
3.2 y ∈ [0. 1]
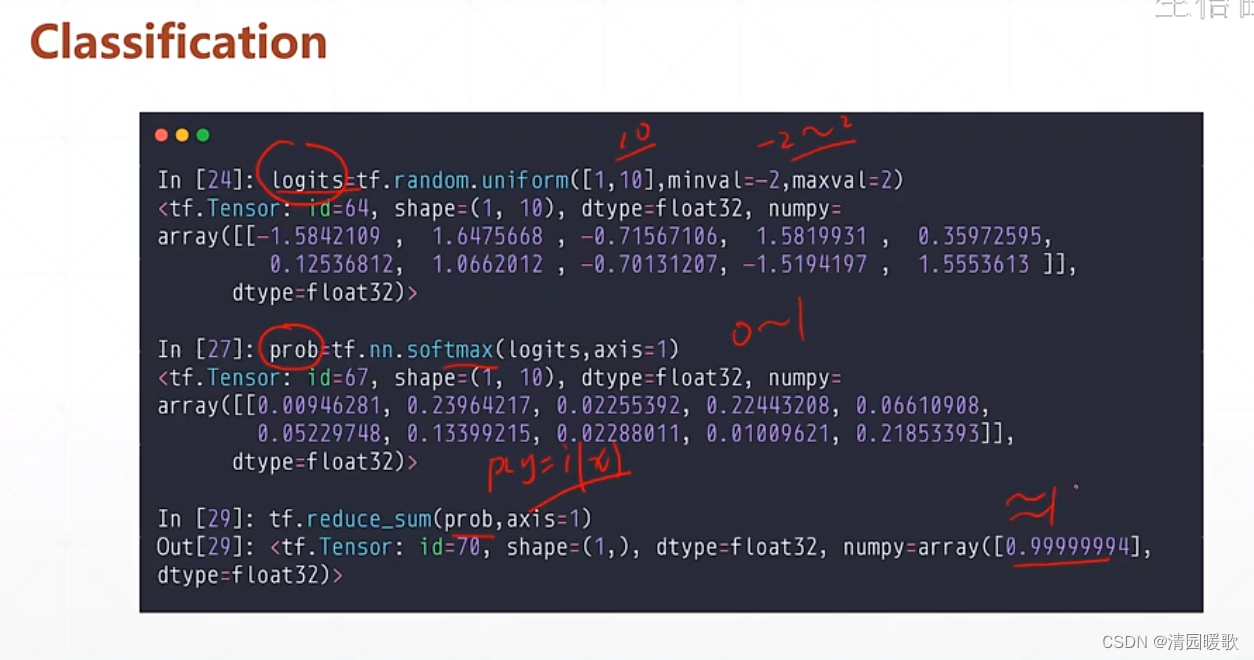
3.3 y ∈ [0, 1],Σ y = 1
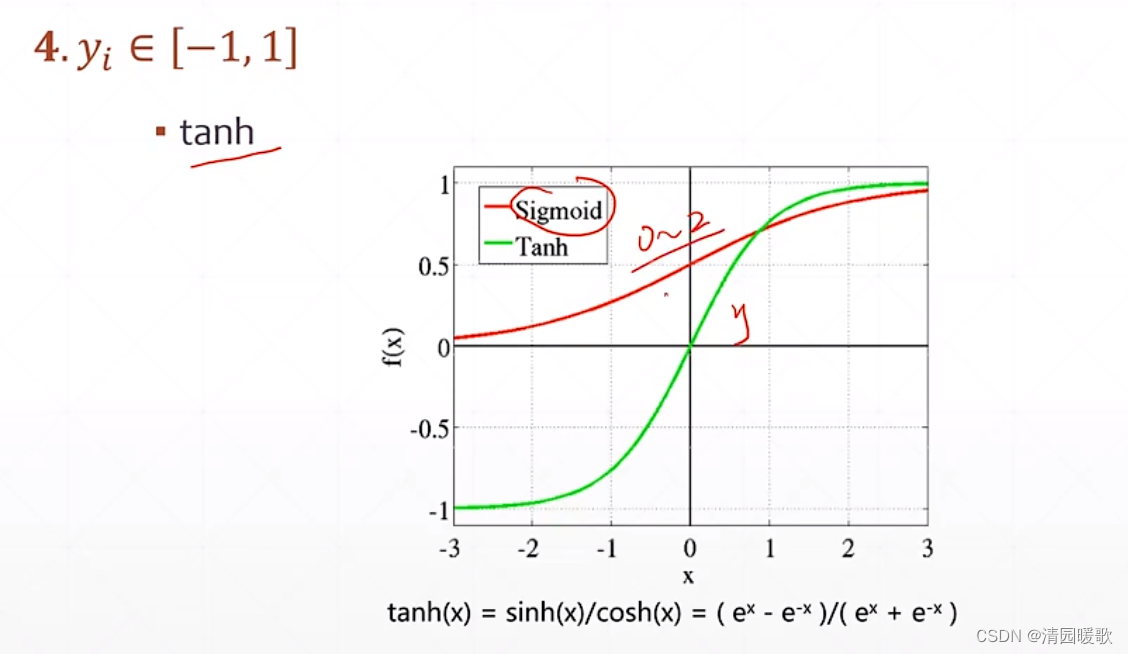
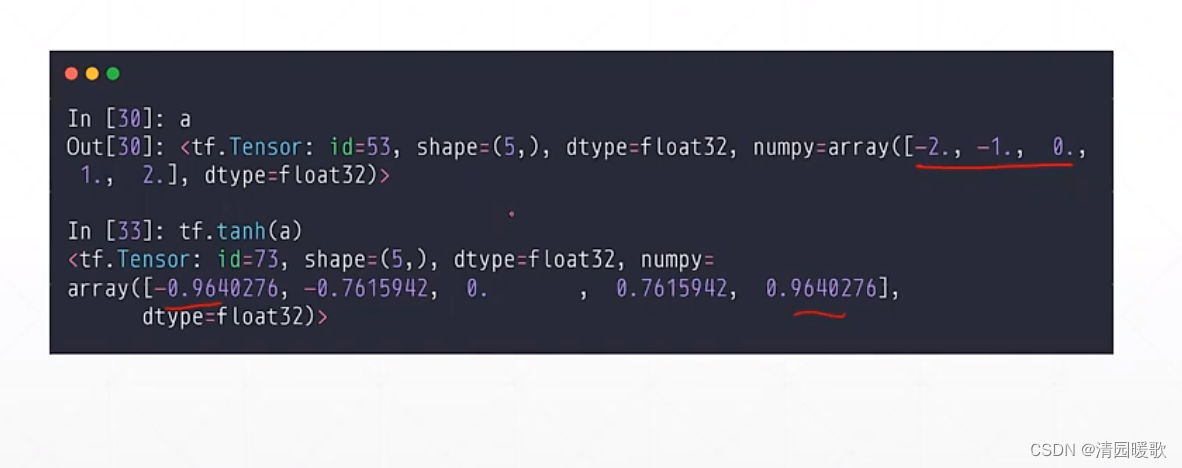
3.4 y ∈ [-1, 1]
四、误差计算
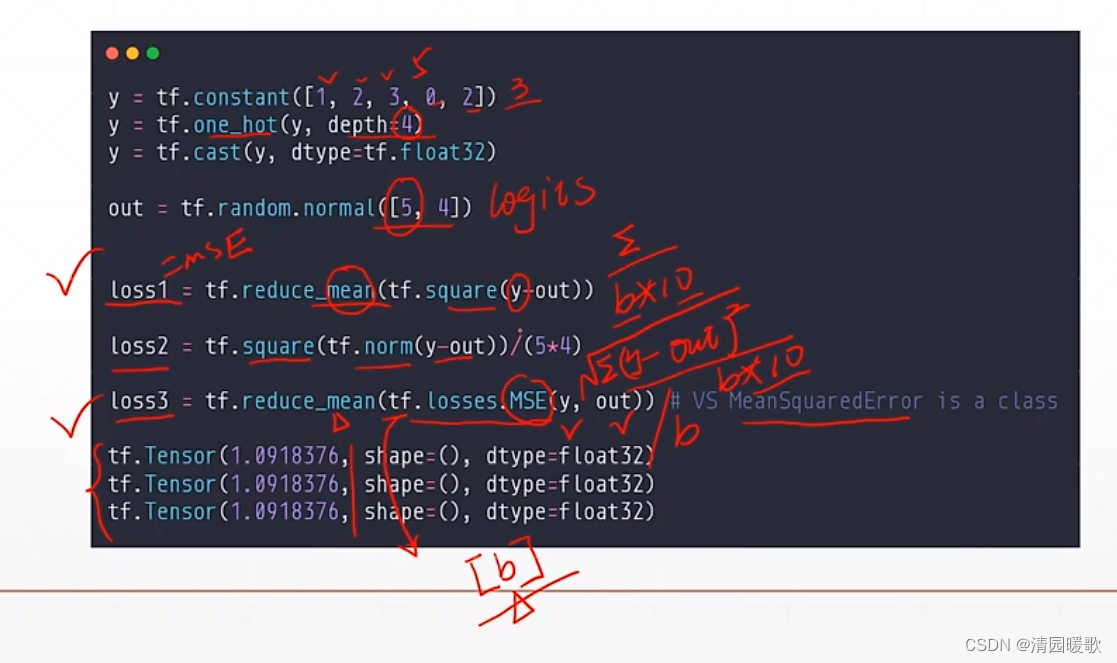
4.1 MSE
4.2 交叉熵(用于分类)
4.2.1 二分类
4.2.3 多分类
一、数据加载(keras.datasets)

数据集列表:
(1)boston housing:波士顿房价
(2)mnist:手写数字集
(3)cifar:另一个小型的图片识别的
(4)imdb:用户评语(100字以内),好评差评

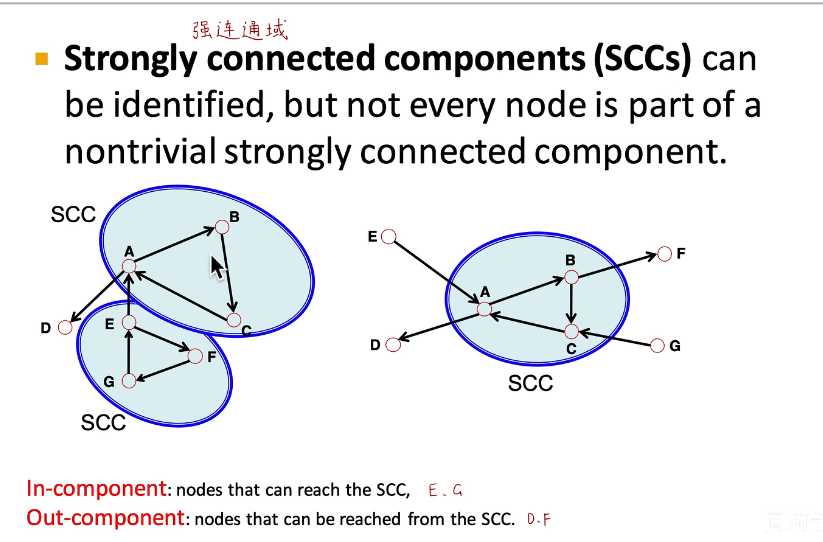
1.1 MNIST 加载
(x,y),(x_test,y_test)
x,y 为训练集:[60k, 28, 28],[60k, ]
x_test,y_test 为测试集:[10k, 28, 28],[10k, ]
因为都是灰度图,所以颜色通道是 1

导入的格式是个 numpy 的api,所以可以直接 x.min(),不然 tensor 中是 tf.reduce_min
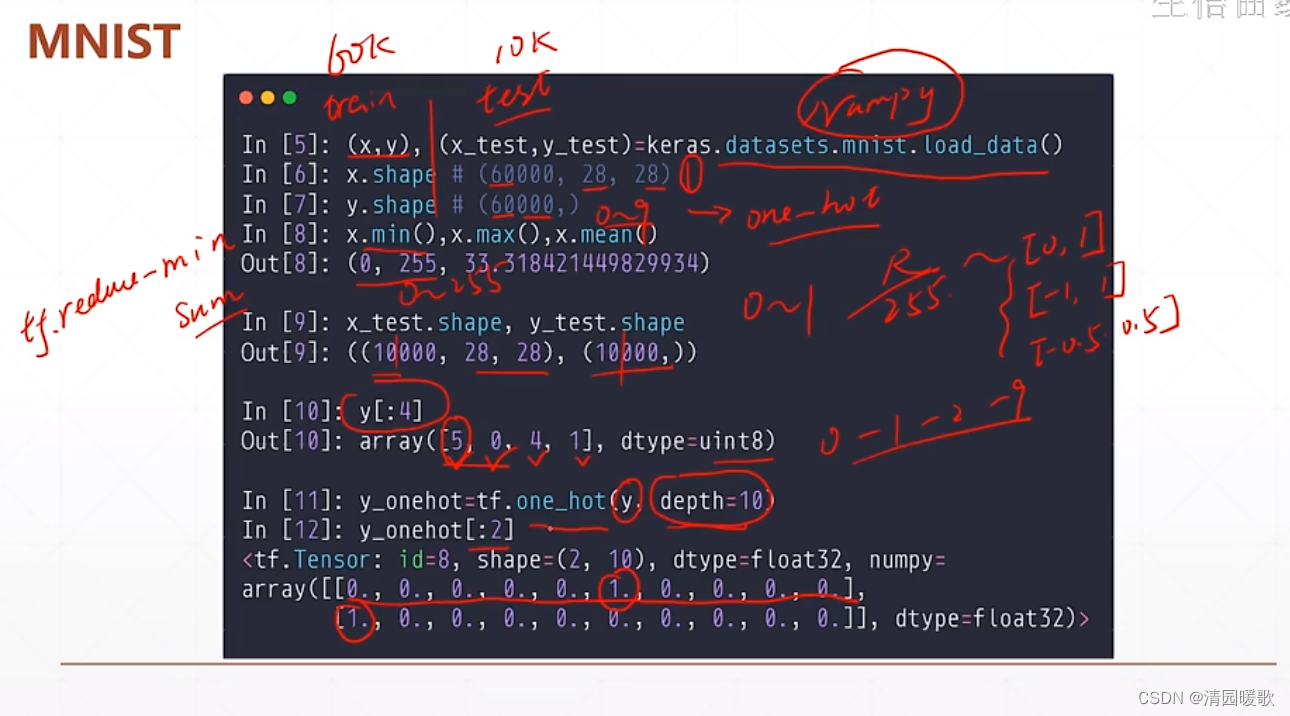
1.2 CIFAR10/100 加载
CIFAR10 就是 10 类,CIFAR100 就是把每一个大类都细分,最后成 100 个小类
因为 cifar 大小非常小,所以图片会模糊,真实大小是 [32, 32, 3]

(x,y),(x_test,y_test)
x,y 为训练集:[50k, 32, 32],[50k, 1]
x_test,y_test 为测试集:[10k, 32, 32],[10k, 1]
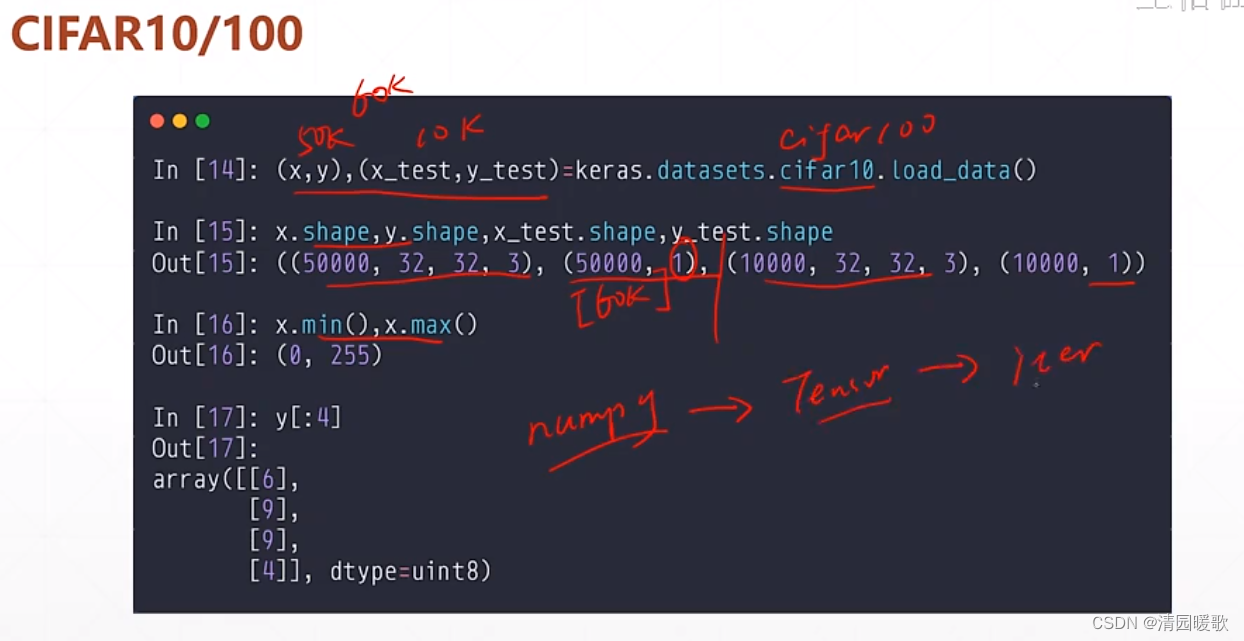
1.3 tf.data.Dataset.from_tensor_slices
因为加载的都是 numpy 格式的,都是要转化为 tensor 的,所以就有了一个函数直接使用就是:tf.data.Dataset.from_tensor_slices
但是要先取它的迭代器,再取它,就是 next(iter(db))
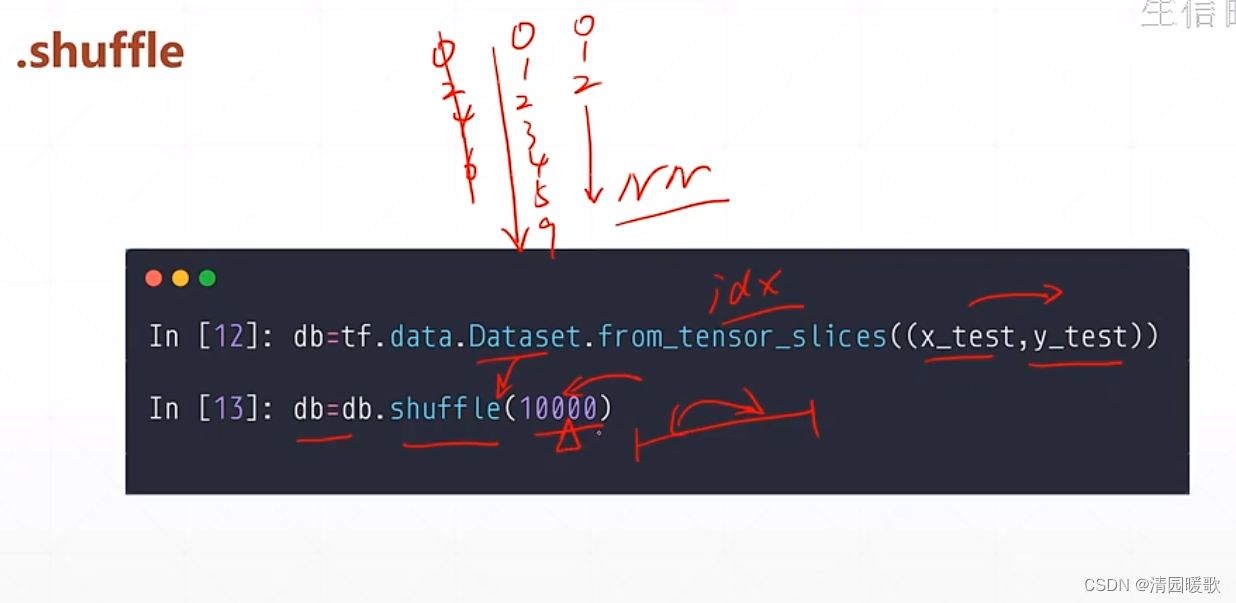
1.4 .shuffle (对应打散数据)
防止数据集排列的规律一致,如y(label)都是0-9这样排列,所以就把数据 x对应y来打散
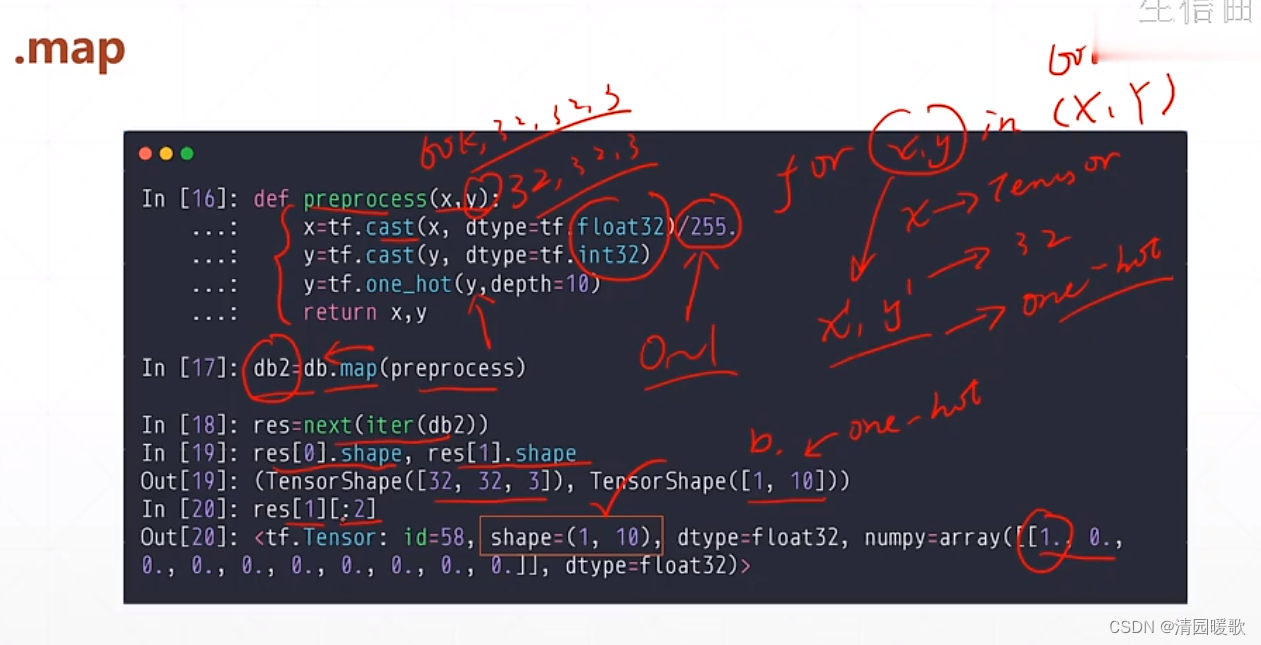
1.5 .map(数据预处理)
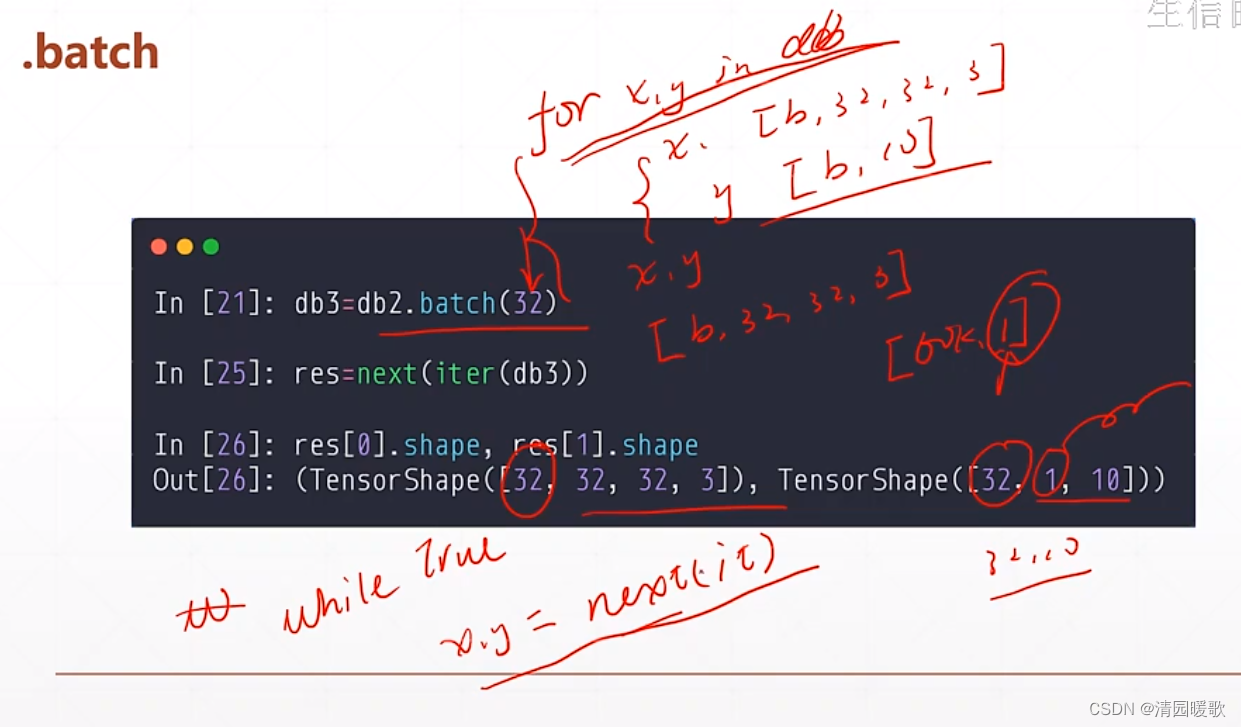
1.6 .batch / .repeat
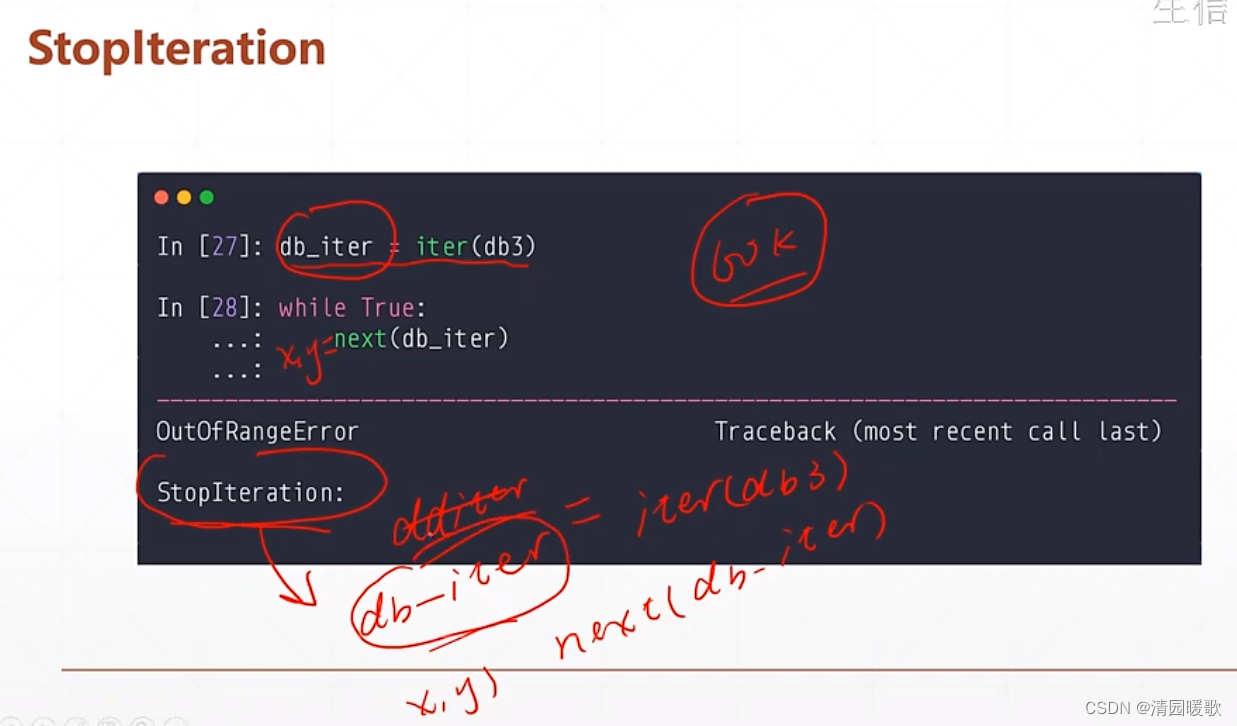
用 while 的话会触发一个异常

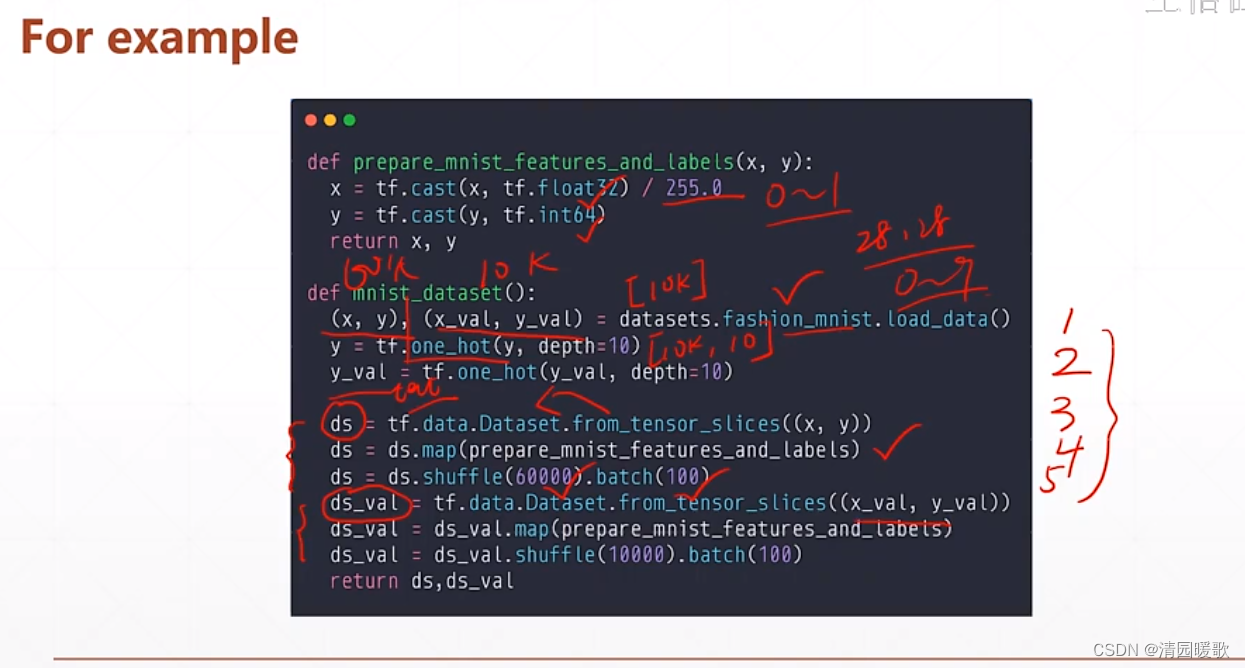
代码:新的 TF06 forward.py
二、全连接层
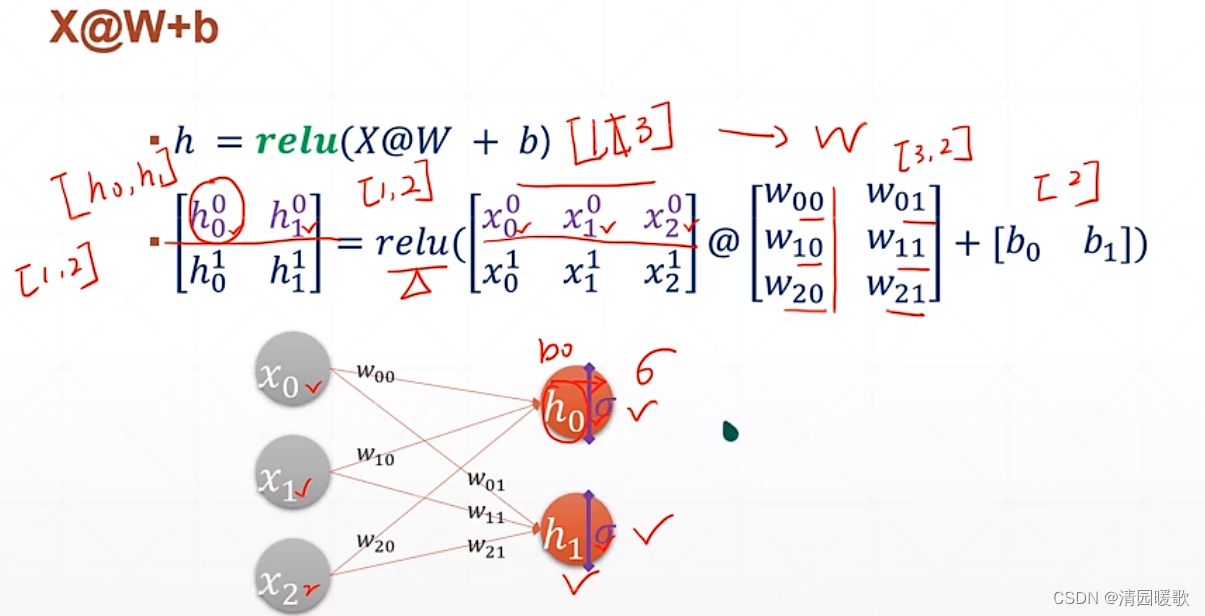
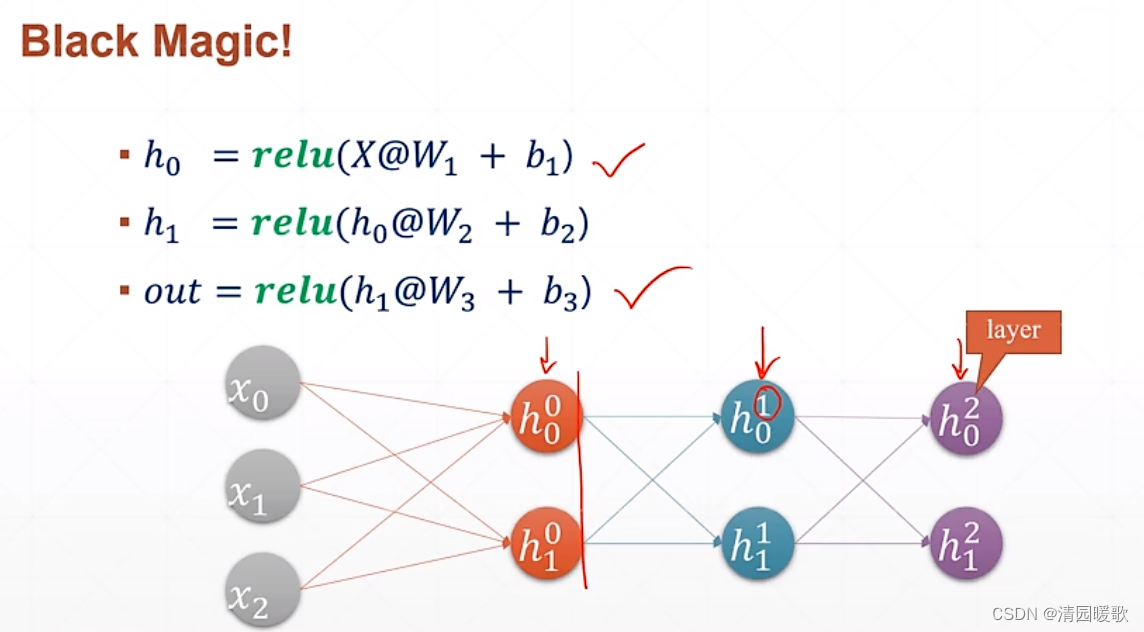
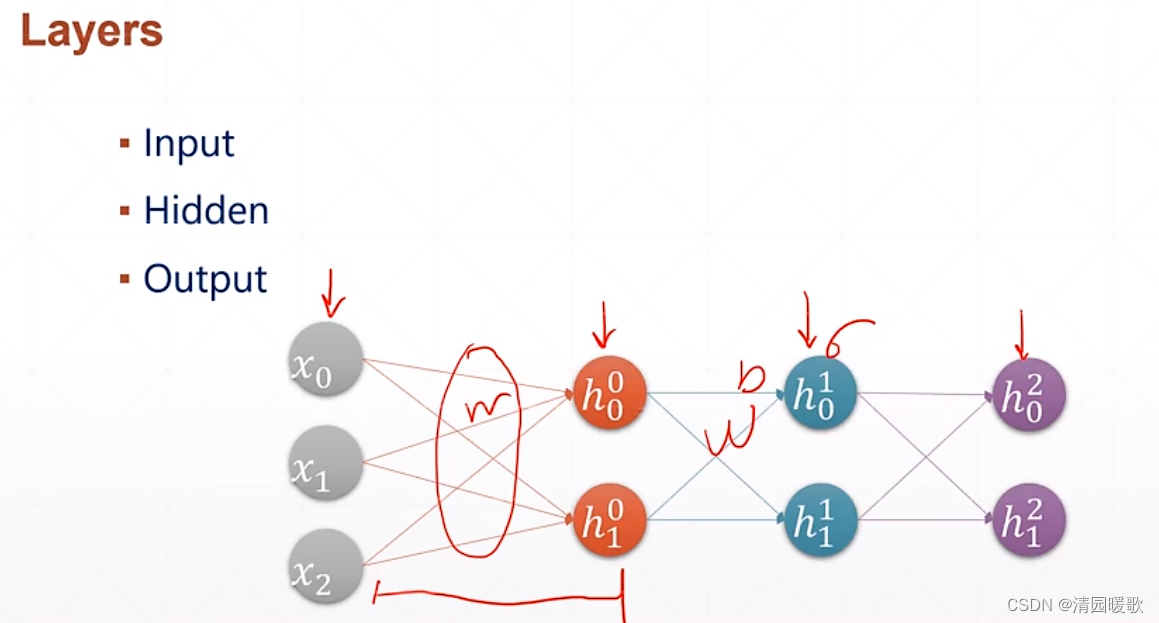
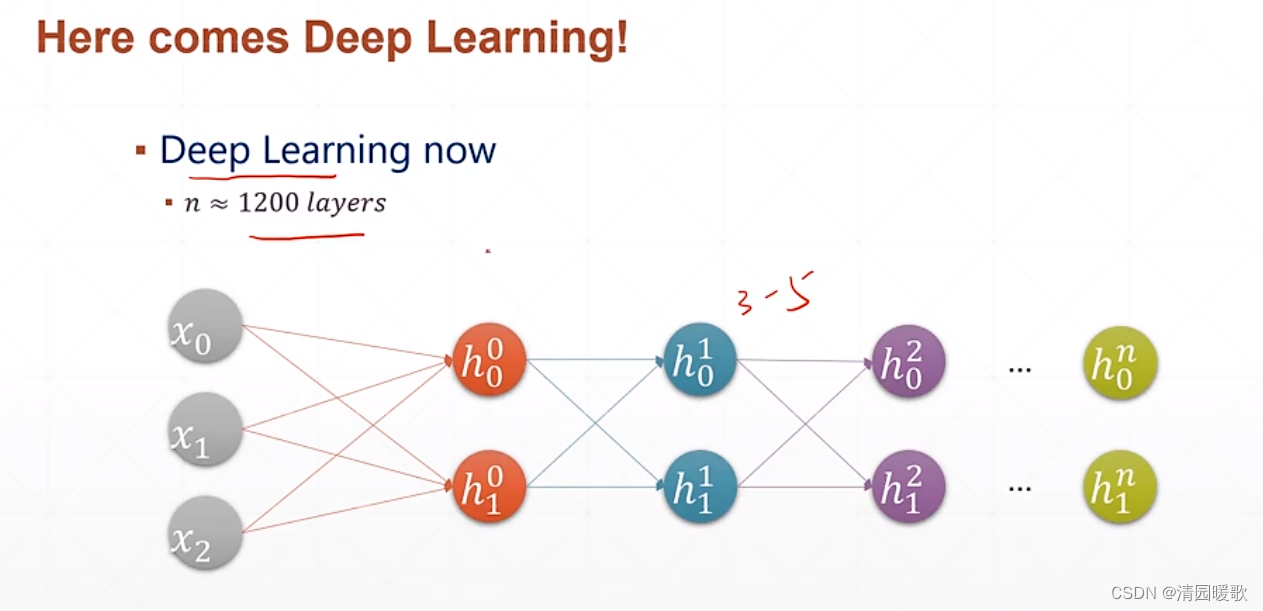

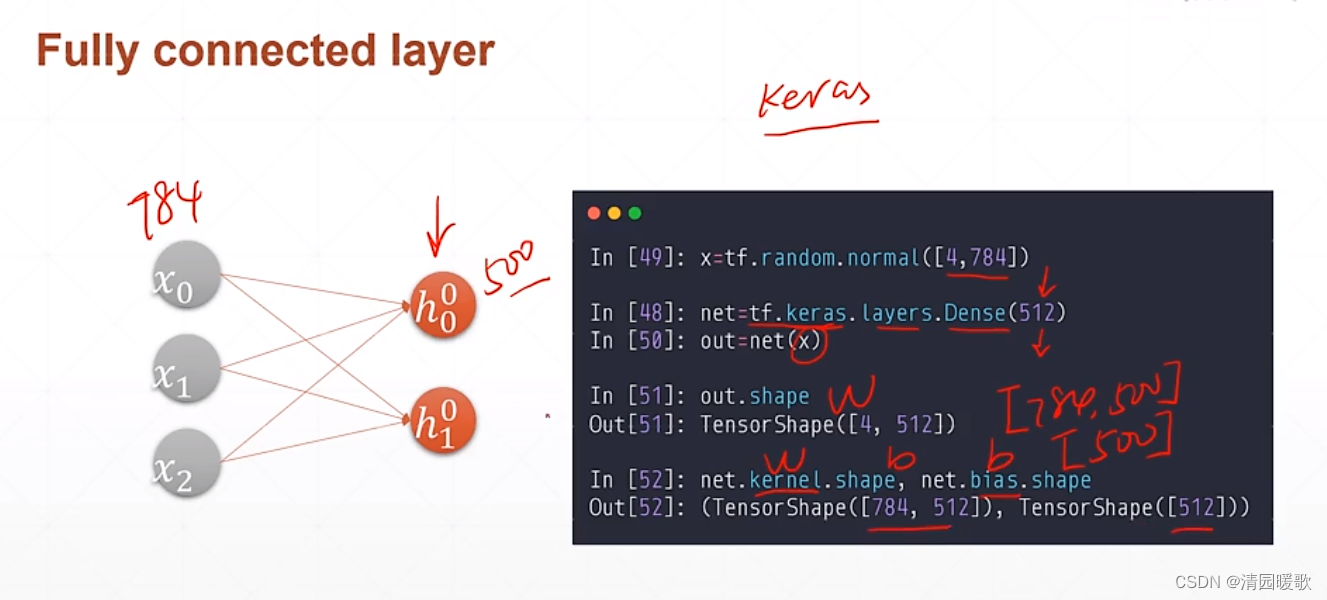

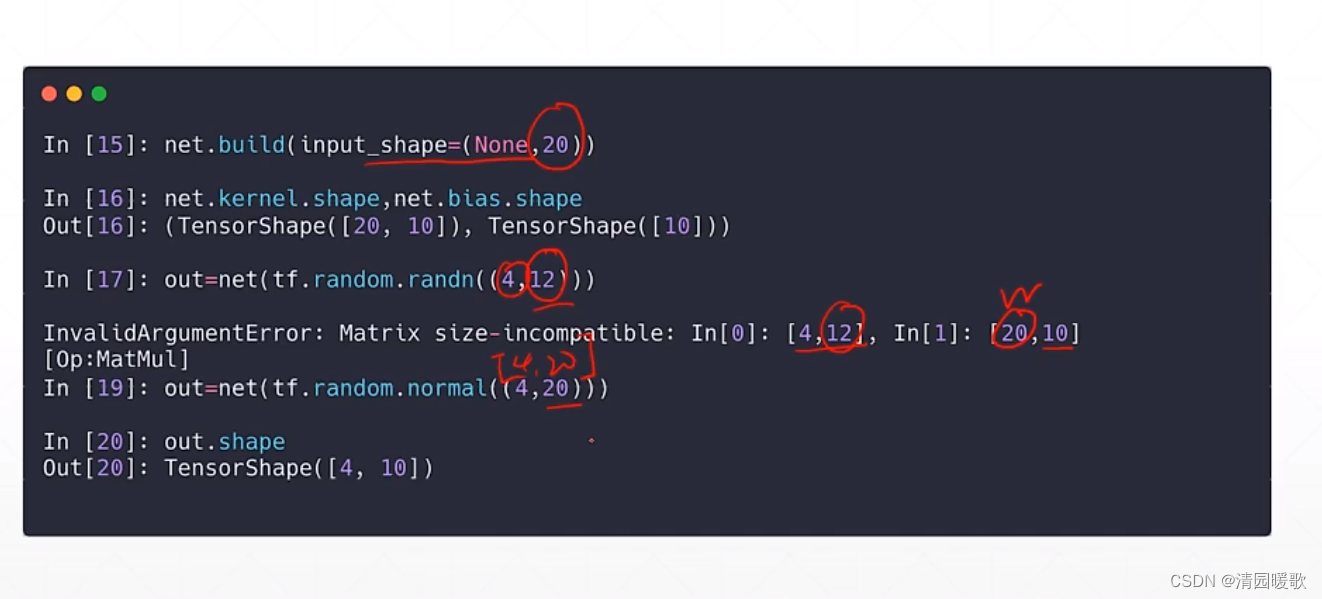
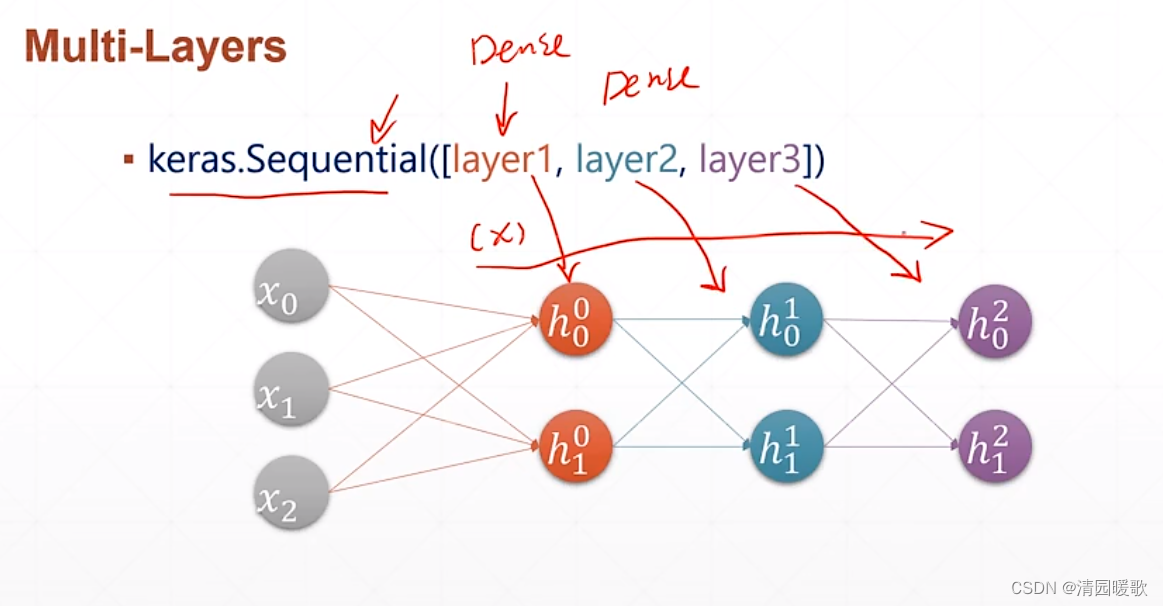
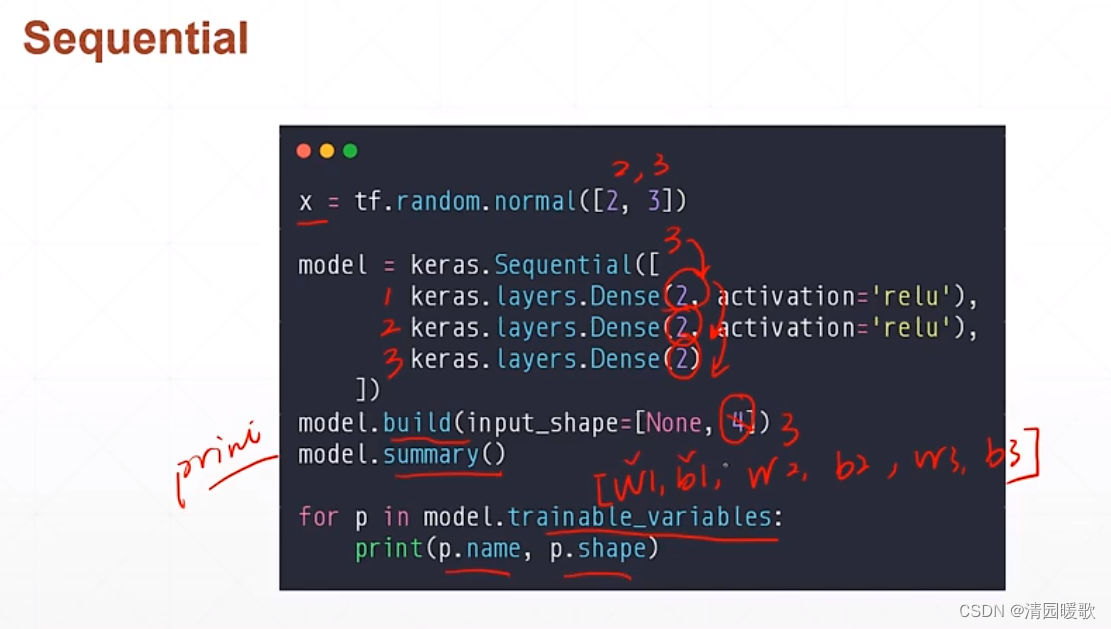
代码: mlp.py



三、输出方式
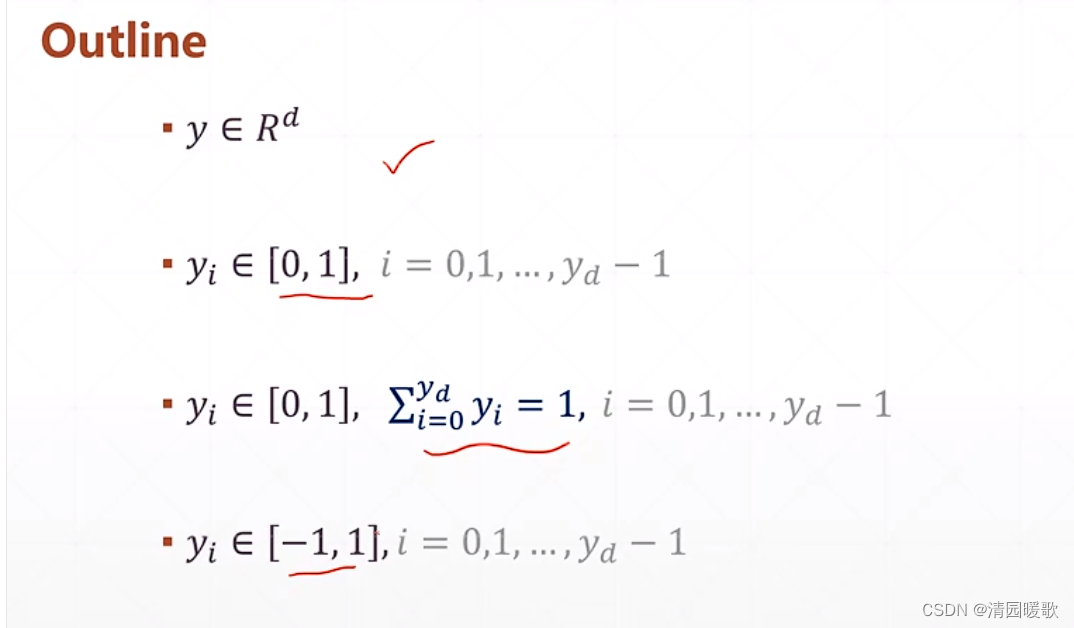
3.1 y ∈ R

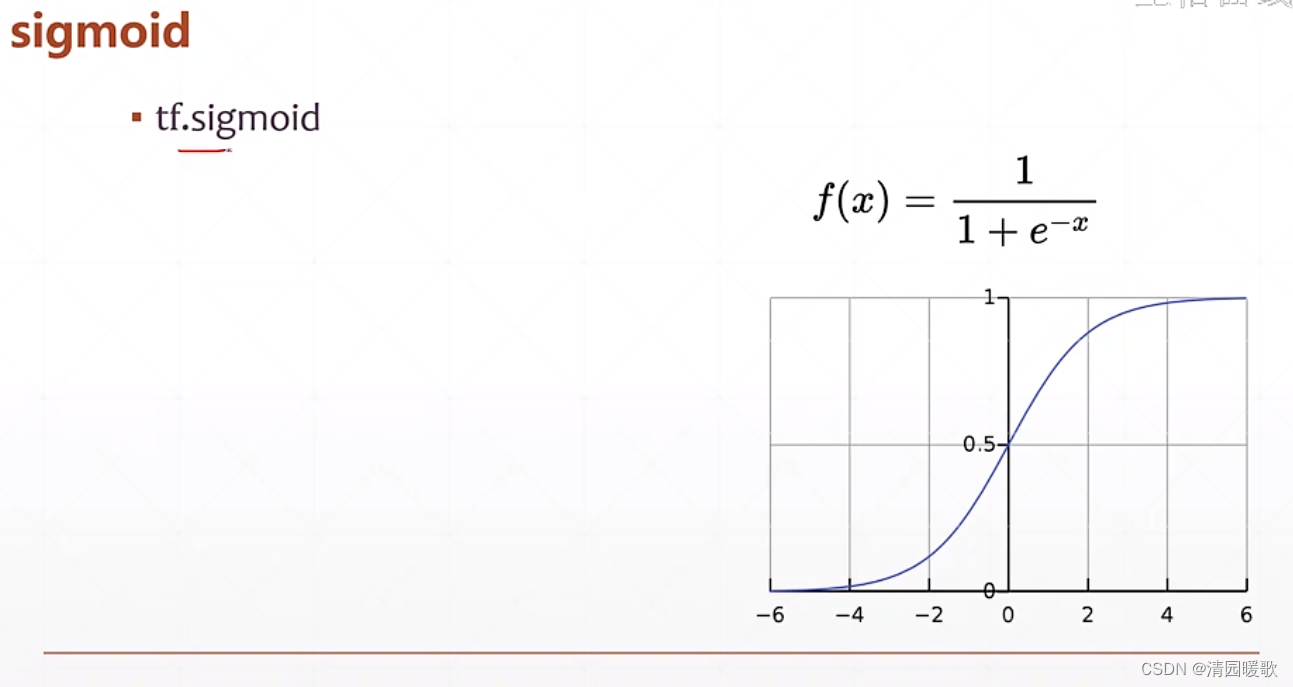
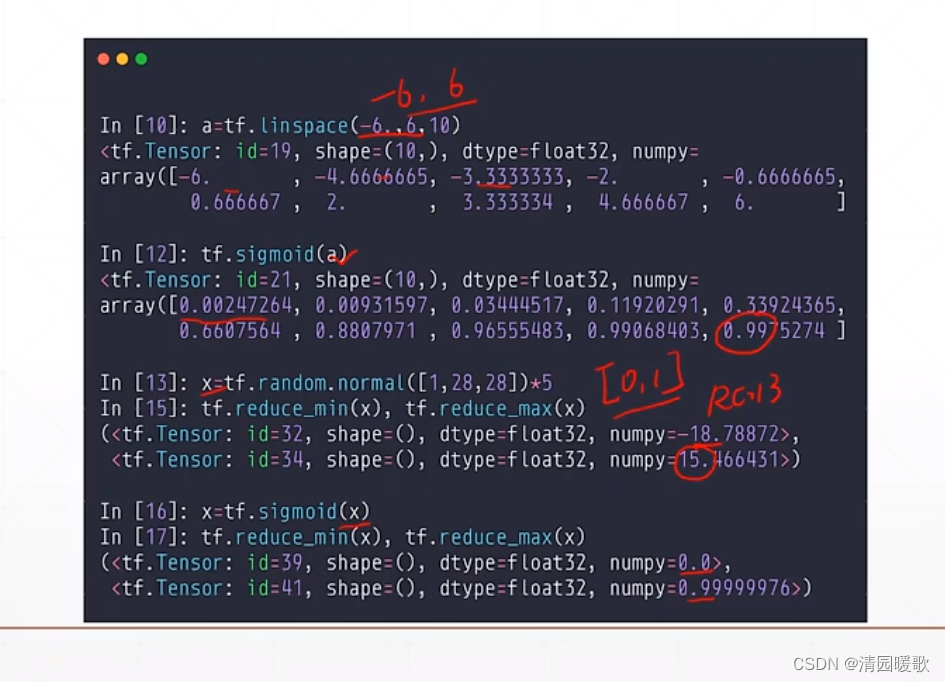
3.2 y ∈ [0. 1]

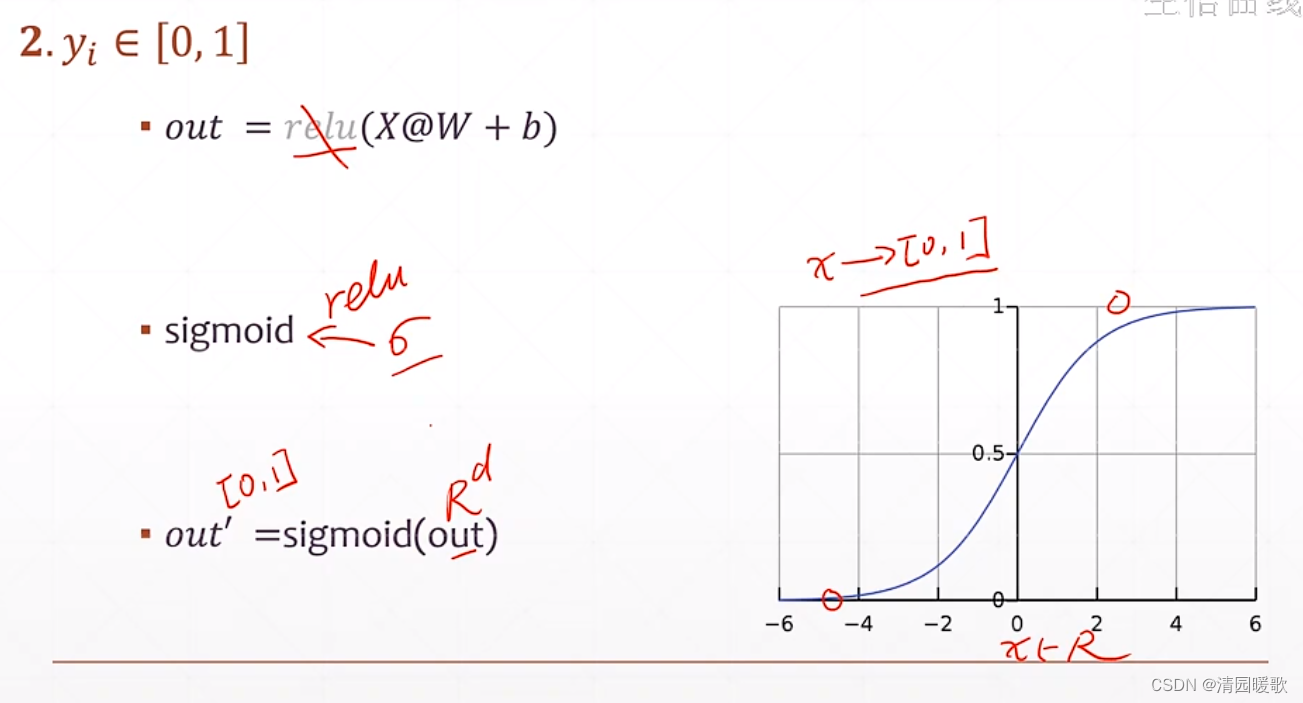
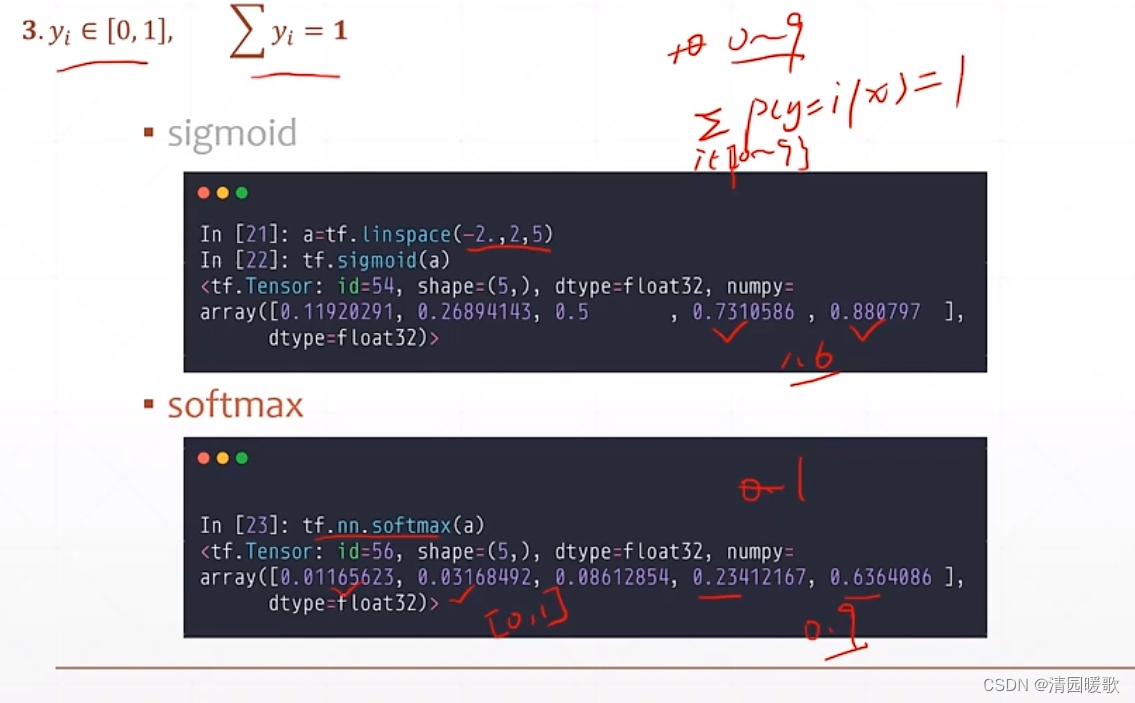
3.3 y ∈ [0, 1],Σ y = 1
sigmoid 不能保证所有概率之和为1
softmax 可以
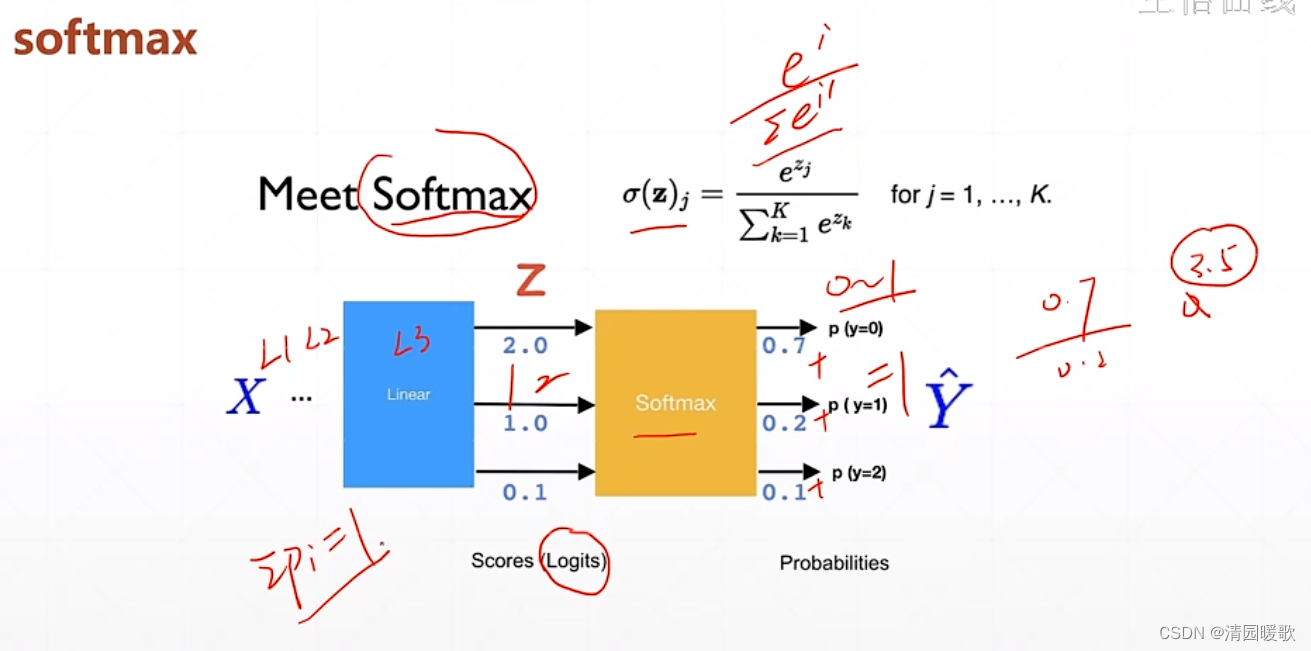
3.4 y ∈ [-1, 1]
四、误差计算

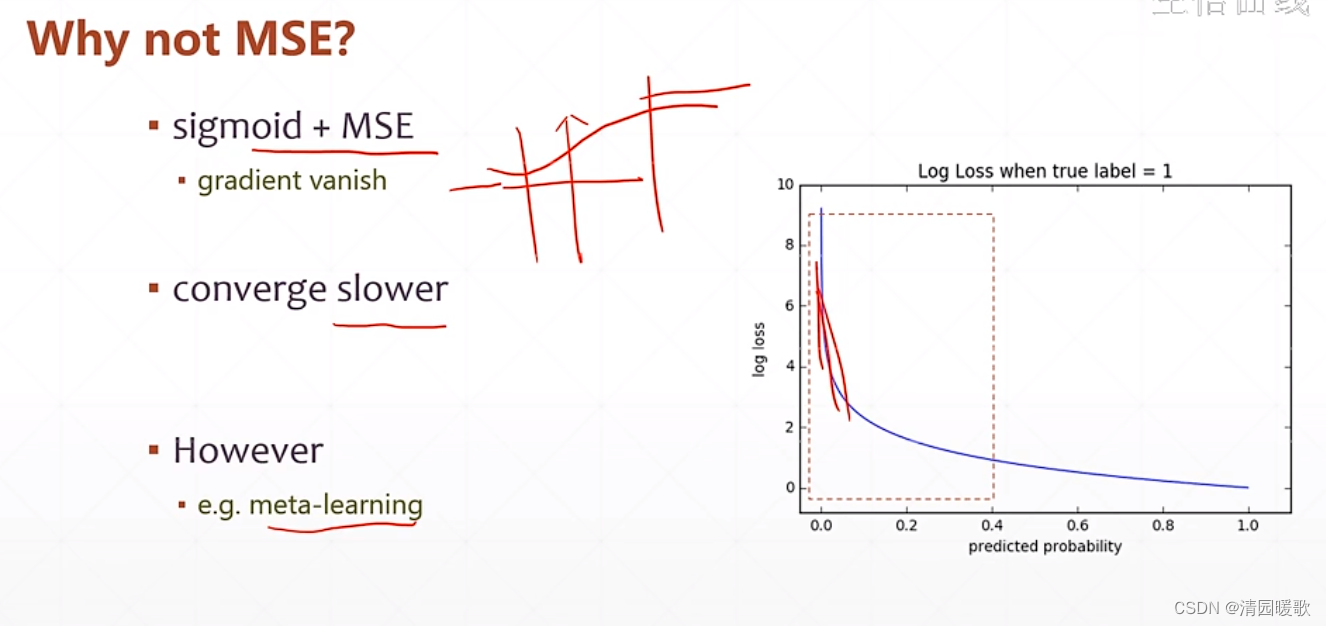
4.1 MSE
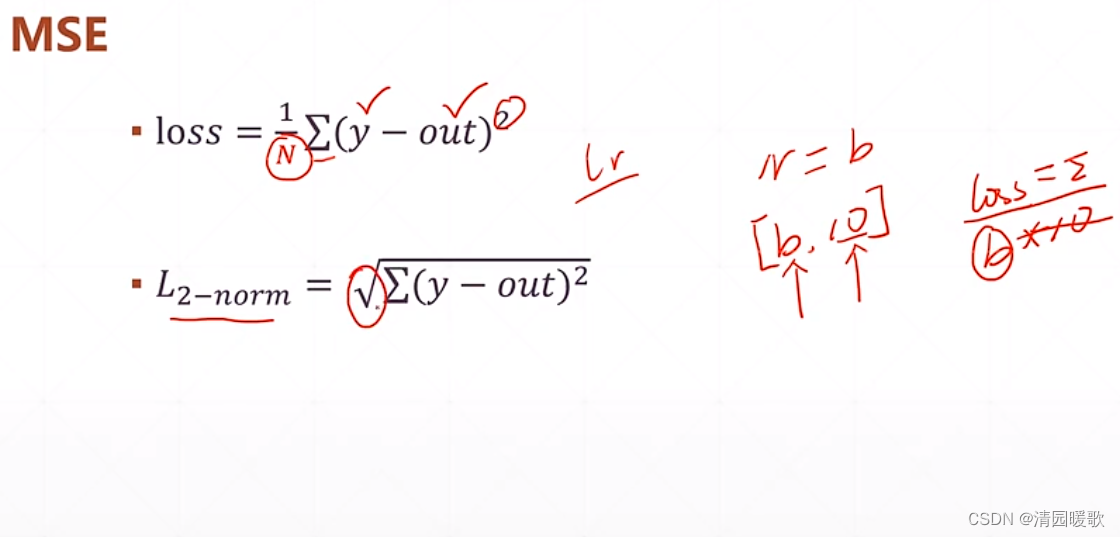
4.2 交叉熵(用于分类)
熵(Entropy)的概念

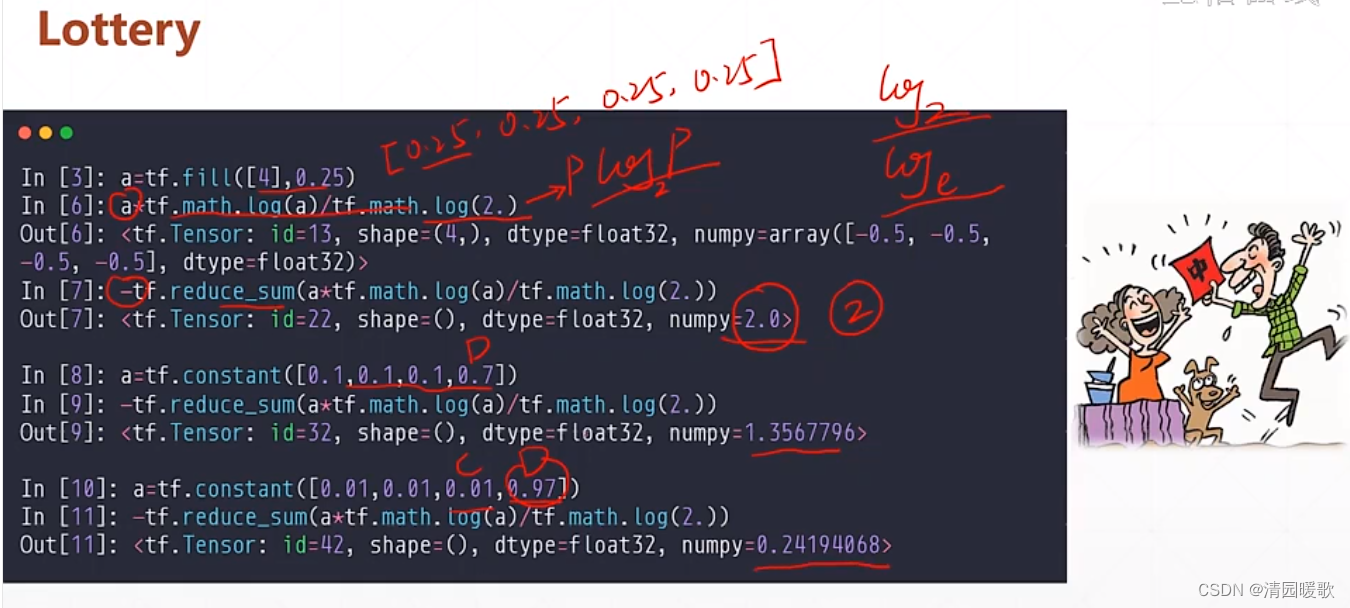
交叉熵(Cross Entropy):

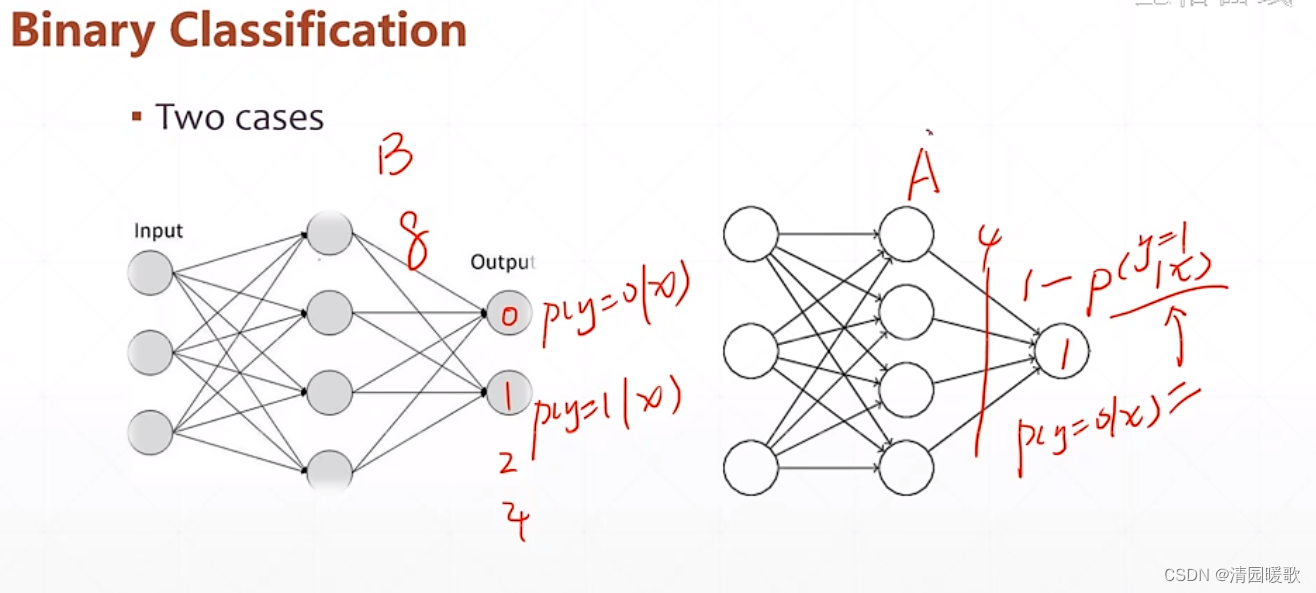
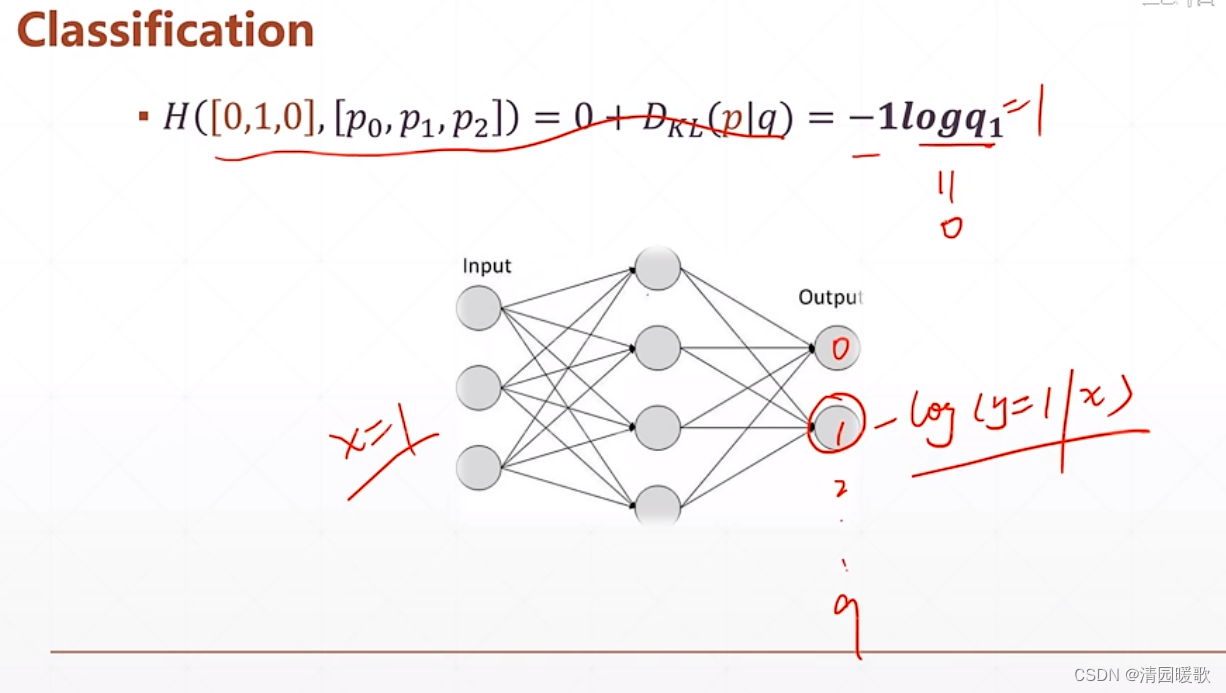
4.2.1 二分类
二分类有两种格式,但是现在来说这两种并没有什么影响
qi 为在 i 结点输出的 概率
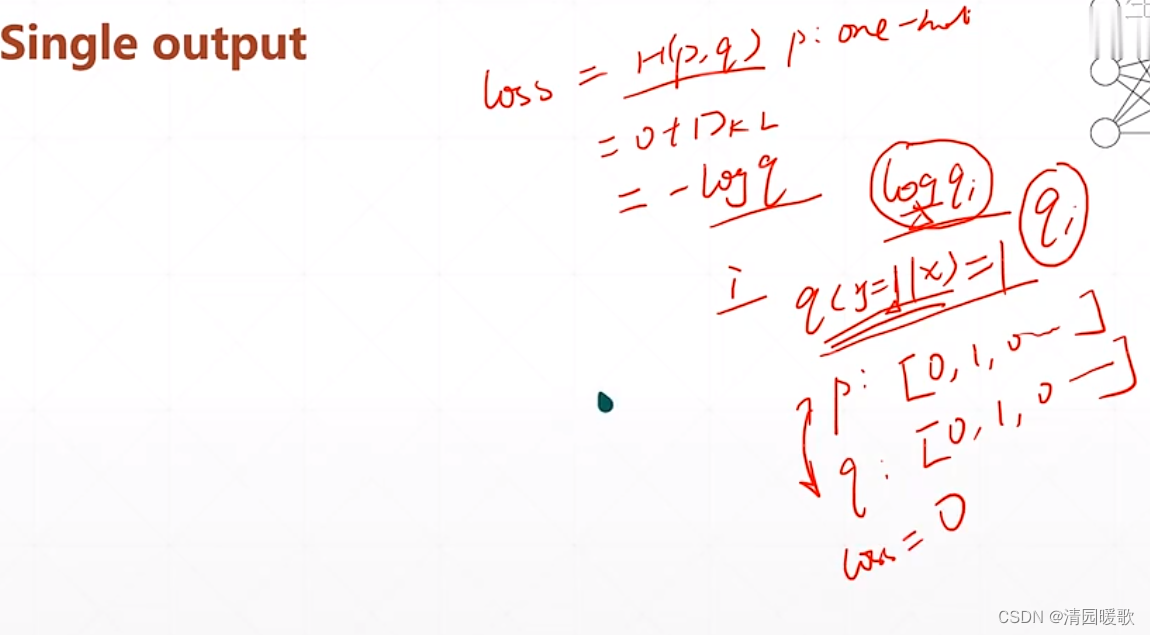

4.2.3 多分类

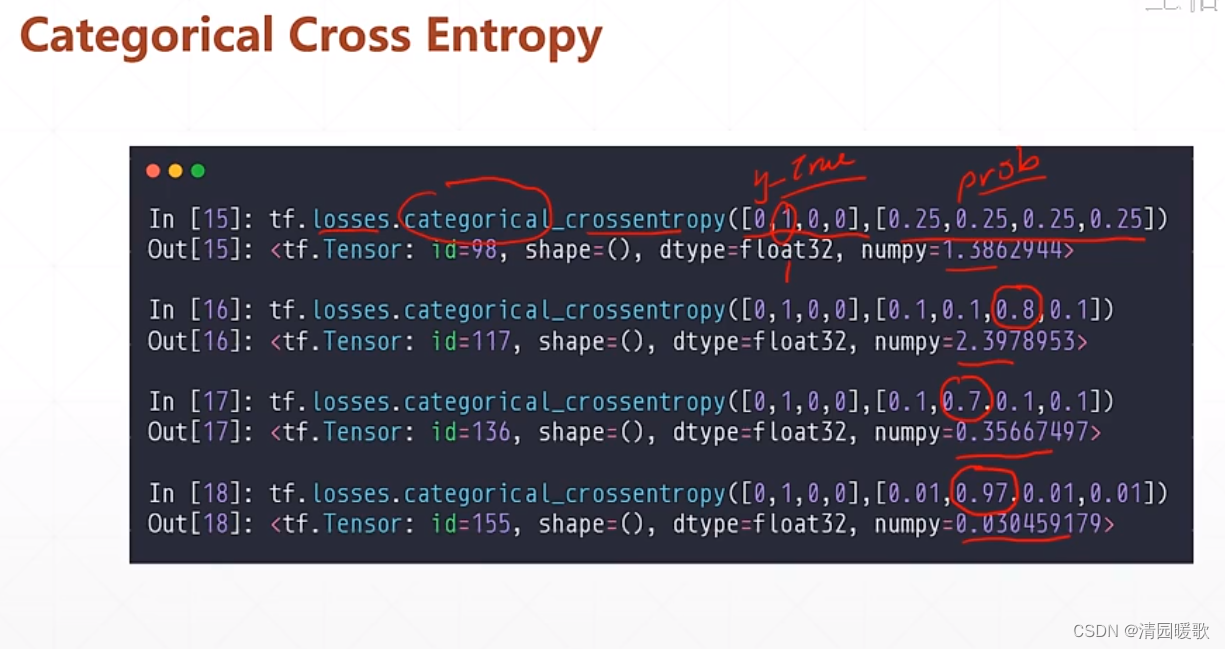
categorical_crossentropy 小写形式是一个函数,大写形式是一个类,调用方式不一样
binary_crossentropy 和 BinaryCrossentropy 也是
BinaryCrossentropy()([1], [0.1]) 前一个括号是建立这个类,可以命名为 criteon

具体使用需要我们自己总结经验
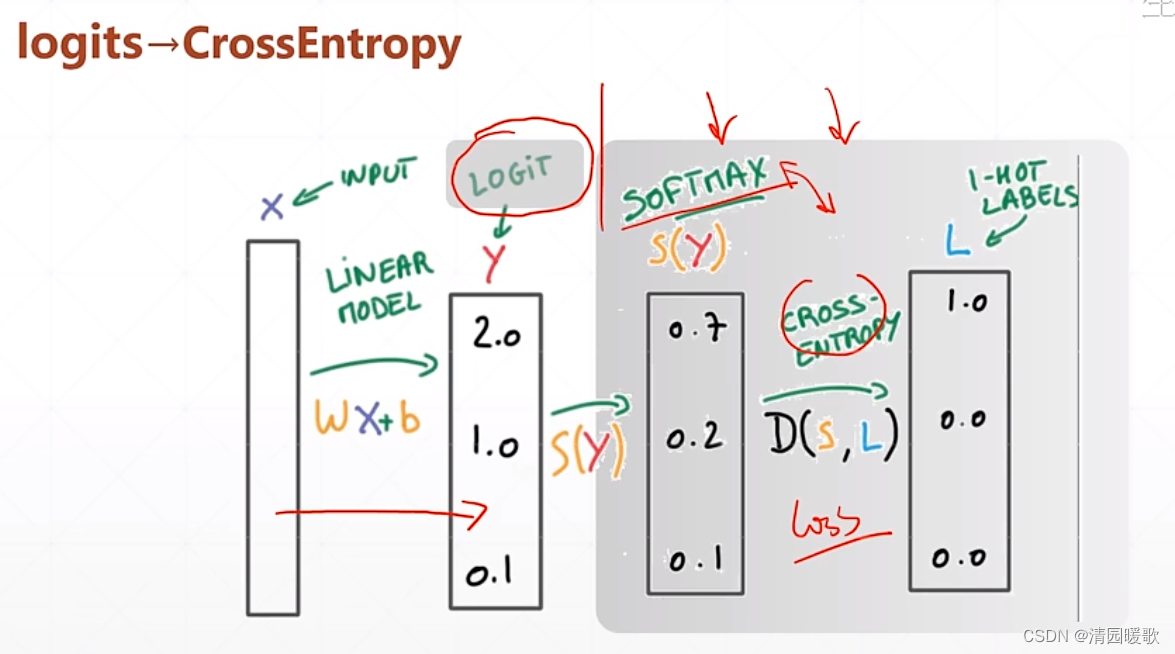
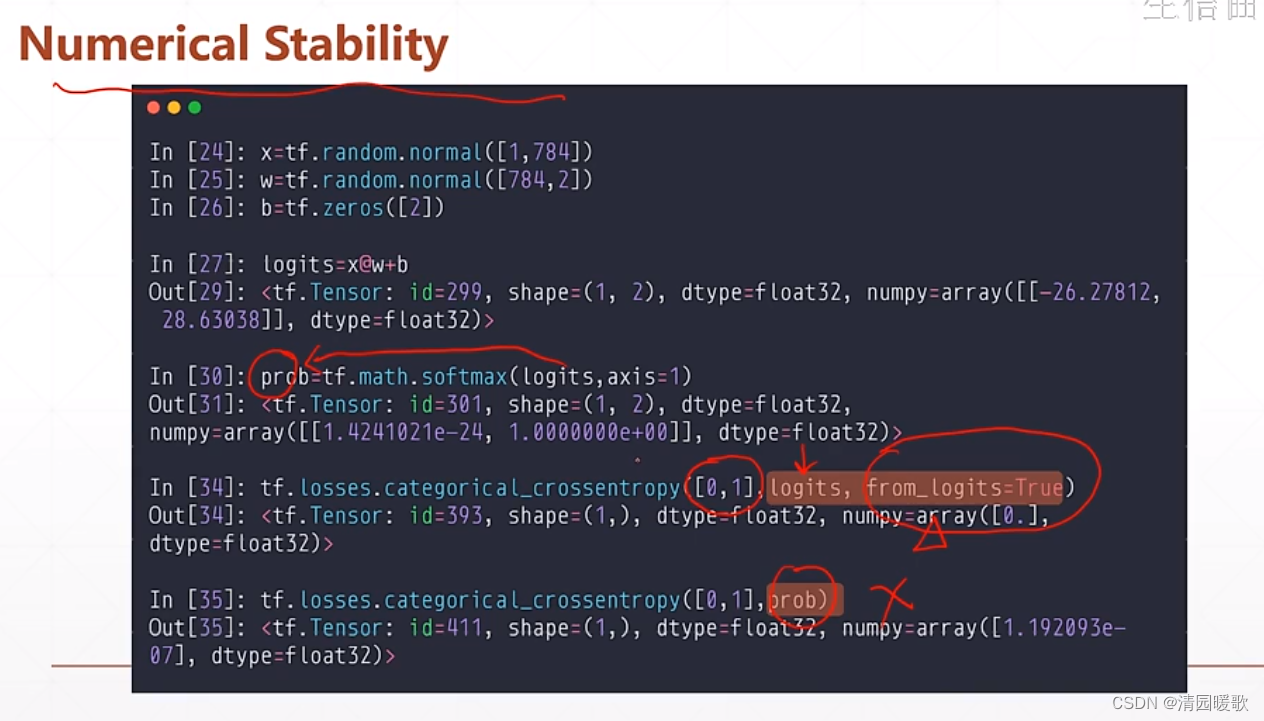
最好设置 from_logits=True 不然会出现数值不稳定的情况,tensorflow 默认是 False